
深度學習中的attention機制
最近兩年,注意力模型(Attention Model)被廣泛使用在自然語言處理、影象識別及語音識別等各種不同型別的深度學習任務中,是深度學習技術中最值得關注與深入瞭解的核心技術之一。本文以機器翻譯為例,深入淺出地介紹了深度學習中注意力機制的原理及關鍵計算機制,同時也抽象出其本質思想,並介紹了注意力模型在影象及語音等領域的典型應用場景。
注意力模型最近幾年在深度學習各個領域被廣泛使用,無論是影象處理、語音識別還是自然語言處理的各種不同型別的任務中,都很容易遇到注意力模型的身影。所以,瞭解注意力機制的工作原理對於關注深度學習技術發展的技術人員來說有很大的必要。
人類的視覺注意力
從注意力模型的命名方式看,很明顯其借鑑了人類的注意力機制,因此,我們首先簡單介紹人類視覺的選擇性注意力機制。

圖1 人類的視覺注意力
視覺注意力機制是人類視覺所特有的大腦訊號處理機制。人類視覺通過快速掃描全域性影象,獲得需要重點關注的目標區域,也就是一般所說的注意力焦點,而後對這一區域投入更多注意力資源,以獲取更多所需要關注目標的細節資訊,而抑制其他無用資訊。這是人類利用有限的注意力資源從大量資訊中快速篩選出高價值資訊的手段,是人類在長期進化中形成的一種生存機制,人類視覺注意力機制極大地提高了視覺資訊處理的效率與準確性。
圖1形象化展示了人類在看到一副影象時是如何高效分配有限的注意力資源的,其中紅色區域表明視覺系統更關注的目標,很明顯對於圖1所示的場景,人們會把注意力更多投入到人的臉部,文字的標題以及文章首句等位置。
深度學習中的注意力機制從本質上講和人類的選擇性視覺注意力機制類似,核心目標也是從眾多資訊中選擇出對當前任務目標更關鍵的資訊。
Encoder-Decoder框架
要了解深度學習中的注意力模型,就不得不先談Encoder-Decoder框架,因為目前大多數注意力模型附著在Encoder-Decoder框架下,當然,其實注意力模型可以看作一種通用的思想,本身並不依賴於特定框架,這點需要注意。
Encoder-Decoder框架可以看作是一種深度學習領域的研究模式,應用場景異常廣泛。圖2是文字處理領域裡常用的Encoder-Decoder框架最抽象的一種表示。
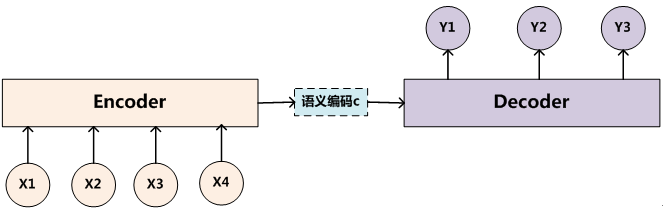
圖2 抽象的文字處理領域的Encoder-Decoder框架
文字處理領域的Encoder-Decoder框架可以這麼直觀地去理解:可以把它看作適合處理由一個句子(或篇章)生成另外一個句子(或篇章)的通用處理模型。對於句子對< Source,Target >,我們的目標是給定輸入句子Source,期待通過Encoder-Decoder框架來生成目標句子Target。Source和Target可以是同一種語言,也可以是兩種不同的語言。而Source和Target分別由各自的單詞序列構成:
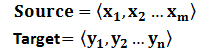
Encoder顧名思義就是對輸入句子Source進行編碼,將輸入句子通過非線性變換轉化為中間語義表示C:
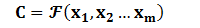
對於解碼器Decoder來說,其任務是根據句子Source的中間語義表示C和之前已經生成的歷史資訊y1,y2……yi-1來生成i時刻要生成的單詞yi:
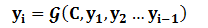
每個yi都依次這麼產生,那麼看起來就是整個系統根據輸入句子Source生成了目標句子Target。如果Source是中文句子,Target是英文句子,那麼這就是解決機器翻譯問題的Encoder-Decoder框架;如果Source是一篇文章,Target是概括性的幾句描述語句,那麼這是文字摘要的Encoder-Decoder框架;如果Source是一句問句,Target是一句回答,那麼這是問答系統或者對話機器人的Encoder-Decoder框架。由此可見,在文字處理領域,Encoder-Decoder的應用領域相當廣泛。
Encoder-Decoder框架不僅僅在文字領域廣泛使用,在語音識別、影象處理等領域也經常使用。比如對於語音識別來說,圖2所示的框架完全適用,區別無非是Encoder部分的輸入是語音流,輸出是對應的文字資訊;而對於“影象描述”任務來說,Encoder部分的輸入是一副圖片,Decoder的輸出是能夠描述圖片語義內容的一句描述語。一般而言,文字處理和語音識別的Encoder部分通常採用RNN模型,影象處理的Encoder一般採用CNN模型。
Attention模型
本節先以機器翻譯作為例子講解最常見的Soft Attention模型的基本原理,之後拋離Encoder-Decoder框架抽象出了注意力機制的本質思想,然後簡單介紹最近廣為使用的Self Attention的基本思路。
Soft Attention模型
圖2中展示的Encoder-Decoder框架是沒有體現出“注意力模型”的,所以可以把它看作是注意力不集中的分心模型。為什麼說它注意力不集中呢?請觀察下目標句子Target中每個單詞的生成過程如下:
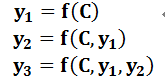
其中f是Decoder的非線性變換函式。從這裡可以看出,在生成目標句子的單詞時,不論生成哪個單詞,它們使用的輸入句子Source的語義編碼C都是一樣的,沒有任何區別。而語義編碼C是由句子Source的每個單詞經過Encoder 編碼產生的,這意味著不論是生成哪個單詞,y1,y2還是y3,其實句子Source中任意單詞對生成某個目標單詞yi來說影響力都是相同的,這是為何說這個模型沒有體現出注意力的緣由。這類似於人類看到眼前的畫面,但是眼中卻沒有注意焦點一樣。
如果拿機器翻譯來解釋這個分心模型的Encoder-Decoder框架更好理解,比如輸入的是英文句子:Tom chase Jerry,Encoder-Decoder框架逐步生成中文單詞:“湯姆”,“追逐”,“傑瑞”。在翻譯“傑瑞”這個中文單詞的時候,分心模型裡面的每個英文單詞對於翻譯目標單詞“傑瑞”貢獻是相同的,很明顯這裡不太合理,顯然“Jerry”對於翻譯成“傑瑞”更重要,但是分心模型是無法體現這一點的,這就是為何說它沒有引入注意力的原因。沒有引入注意力的模型在輸入句子比較短的時候問題不大,但是如果輸入句子比較長,此時所有語義完全通過一箇中間語義向量來表示,單詞自身的資訊已經消失,可想而知會丟失很多細節資訊,這也是為何要引入注意力模型的重要原因。
上面的例子中,如果引入Attention模型的話,應該在翻譯“傑瑞”的時候,體現出英文單詞對於翻譯當前中文單詞不同的影響程度,比如給出類似下面一個概率分佈值:
(Tom,0.3)(Chase,0.2) (Jerry,0.5)
每個英文單詞的概率代表了翻譯當前單詞“傑瑞”時,注意力分配模型分配給不同英文單詞的注意力大小。這對於正確翻譯目標語單詞肯定是有幫助的,因為引入了新的資訊。同理,目標句子中的每個單詞都應該學會其對應的源語句子中單詞的注意力分配概率資訊。這意味著在生成每個單詞yi的時候,原先都是相同的中間語義表示C會被替換成根據當前生成單詞而不斷變化的Ci。理解Attention模型的關鍵就是這裡,即由固定的中間語義表示C換成了根據當前輸出單詞來調整成加入注意力模型的變化的Ci。增加了注意力模型的Encoder-Decoder框架理解起來如圖3所示。
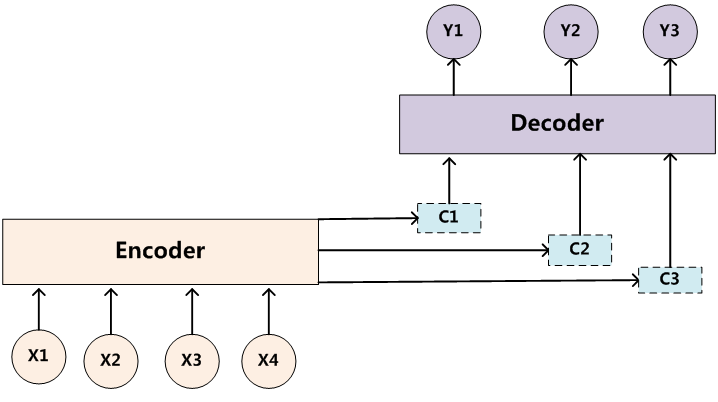
圖3 引入注意力模型的Encoder-Decoder框架
即生成目標句子單詞的過程成了下面的形式:
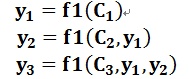
而每個Ci可能對應著不同的源語句子單詞的注意力分配概率分佈,比如對於上面的英漢翻譯來說,其對應的資訊可能如下:

其中,f2函式代表Encoder對輸入英文單詞的某種變換函式,比如如果Encoder是用的RNN模型的話,這個f2函式的結果往往是某個時刻輸入xi後隱層節點的狀態值;g代表Encoder根據單詞的中間表示合成整個句子中間語義表示的變換函式,一般的做法中,g函式就是對構成元素加權求和,即下列公式:
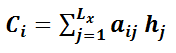
其中,Lx代表輸入句子Source的長度,aij代表在Target輸出第i個單詞時Source輸入句子中第j個單詞的注意力分配係數,而hj則是Source輸入句子中第j個單詞的語義編碼。假設Ci下標i就是上面例子所說的“ 湯姆” ,那麼Lx就是3,h1=f(“Tom”),h2=f(“Chase”),h3=f(“Jerry”)分別是輸入句子每個單詞的語義編碼,對應的注意力模型權值則分別是0.6,0.2,0.2,所以g函式本質上就是個加權求和函式。如果形象表示的話,翻譯中文單詞“湯姆”的時候,數學公式對應的中間語義表示Ci的形成過程類似圖4。
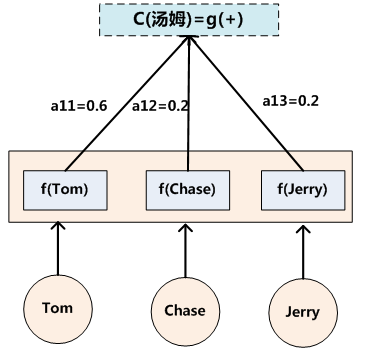
圖4 Attention的形成過程
這裡還有一個問題:生成目標句子某個單詞,比如“湯姆”的時候,如何知道Attention模型所需要的輸入句子單詞注意力分配概率分佈值呢?就是說“湯姆”對應的輸入句子Source中各個單詞的概率分佈:(Tom,0.6)(Chase,0.2) (Jerry,0.2) 是如何得到的呢?
為了便於說明,我們假設對圖2的非Attention模型的Encoder-Decoder框架進行細化,Encoder採用RNN模型,Decoder也採用RNN模型,這是比較常見的一種模型配置,則圖2的框架轉換為圖5。
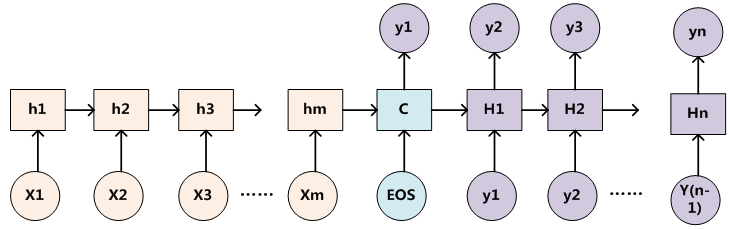
圖5 RNN作為具體模型的Encoder-Decoder框架
那麼用圖6可以較為便捷地說明注意力分配概率分佈值的通用計算過程。
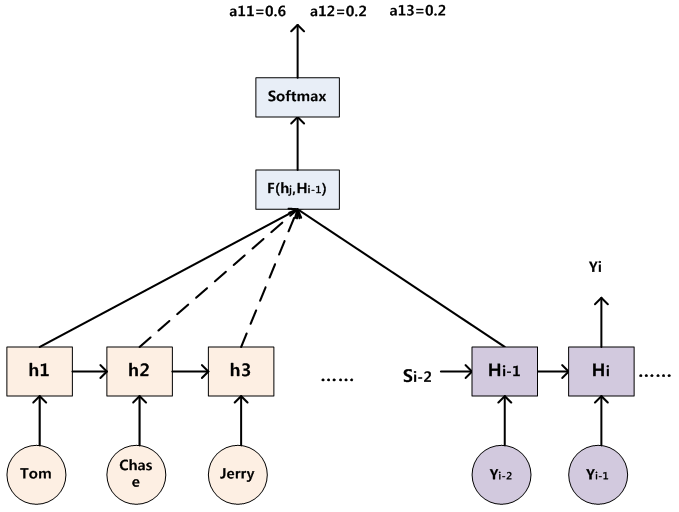
圖6 注意力分配概率計算
對於採用RNN的Decoder來說,在時刻i,如果要生成yi單詞,我們是可以知道Target在生成yi之前的時刻i-1時,隱層節點i-1時刻的輸出值Hi-1的,而我們的目的是要計算生成yi時輸入句子中的單詞“Tom”、“Chase”、“Jerry”對yi來說的注意力分配概率分佈,那麼可以用Target輸出句子i-1時刻的隱層節點狀態Hi-1去一一和輸入句子Source中每個單詞對應的RNN隱層節點狀態hj進行對比,即通過函式F(hj,Hi-1)來獲得目標單詞yi和每個輸入單詞對應的對齊可能性,這個F函式在不同論文裡可能會採取不同的方法,然後函式F的輸出經過Softmax進行歸一化就得到了符合概率分佈取值區間的注意力分配概率分佈數值。絕大多數Attention模型都是採取上述的計算框架來計算注意力分配概率分佈資訊,區別只是在F的定義上可能有所不同。圖7視覺化地展示了在英語-德語翻譯系統中加入Attention機制後,Source和Target兩個句子每個單詞對應的注意力分配概率分佈。
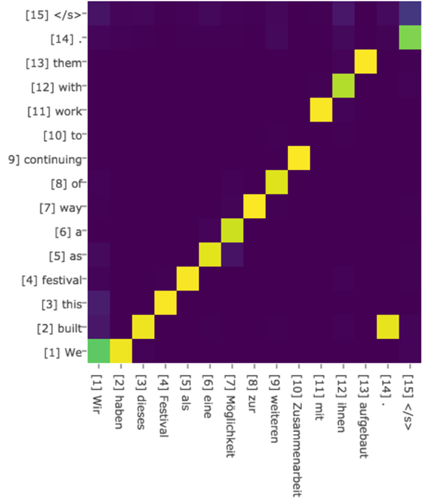
圖7 英語-德語翻譯的注意力概率分佈
上述內容就是經典的Soft Attention模型的基本思想,那麼怎麼理解Attention模型的物理含義呢?一般在自然語言處理應用裡會把Attention模型看作是輸出Target句子中某個單詞和輸入Source句子每個單詞的對齊模型,這是非常有道理的。目標句子生成的每個單詞對應輸入句子單詞的概率分佈可以理解為輸入句子單詞和這個目標生成單詞的對齊概率,這在機器翻譯語境下是非常直觀的:傳統的統計機器翻譯一般在做的過程中會專門有一個短語對齊的步驟,而注意力模型其實起的是相同的作用。
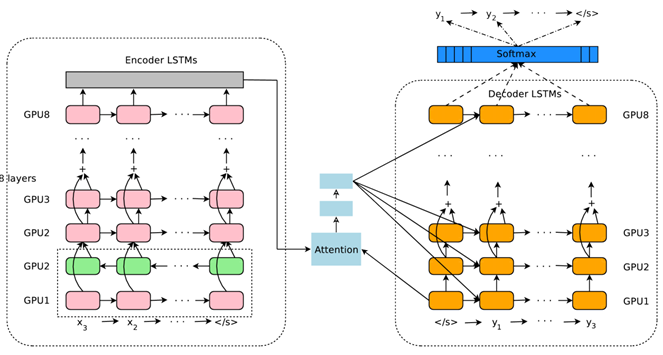
圖8 Google 神經網路機器翻譯系統結構圖
圖8所示即為Google於2016年部署到線上的基於神經網路的機器翻譯系統,相對傳統模型翻譯效果有大幅提升,翻譯錯誤率降低了60%,其架構就是上文所述的加上Attention機制的Encoder-Decoder框架,主要區別無非是其Encoder和Decoder使用了8層疊加的LSTM模型。
Attention機制的本質思想
如果把Attention機制從上文講述例子中的Encoder-Decoder框架中剝離,並進一步做抽象,可以更容易看懂Attention機制的本質思想。
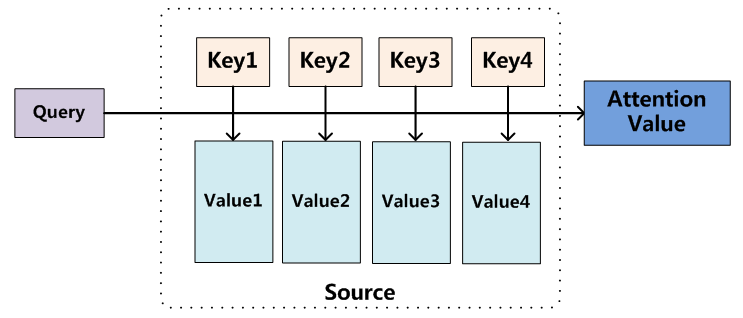
圖9 Attention機制的本質思想
我們可以這樣來看待Attention機制(參考圖9):將Source中的構成元素想象成是由一系列的< Key,Value >資料對構成,此時給定Target中的某個元素Query,通過計算Query和各個Key的相似性或者相關性,得到每個Key對應Value的權重係數,然後對Value進行加權求和,即得到了最終的Attention數值。所以本質上Attention機制是對Source中元素的Value值進行加權求和,而Query和Key用來計算對應Value的權重係數。即可以將其本質思想改寫為如下公式:
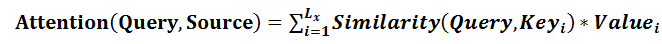
其中, Lx=||Source||代表Source的長度,公式含義即如上所述。上文所舉的機器翻譯的例子裡,因為在計算Attention的過程中,Source中的Key和Value合二為一,指向的是同一個東西,也即輸入句子中每個單詞對應的語義編碼,所以可能不容易看出這種能夠體現本質思想的結構。
當然,從概念上理解,把Attention仍然理解為從大量資訊中有選擇地篩選出少量重要資訊並聚焦到這些重要資訊上,忽略大多不重要的資訊,這種思路仍然成立。聚焦的過程體現在權重係數的計算上,權重越大越聚焦於其對應的Value值上,即權重代表了資訊的重要性,而Value是其對應的資訊。從圖9可以引出另外一種理解,也可以將Attention機制看作一種軟定址(Soft Addressing):Source可以看作儲存器記憶體儲的內容,元素由地址Key和值Value組成,當前有個Key=Query的查詢,目的是取出儲存器中對應的Value值,即Attention數值。通過Query和儲存器內元素Key的地址進行相似性比較來定址,之所以說是軟定址,指的不像一般定址只從儲存內容裡面找出一條內容,而是可能從每個Key地址都會取出內容,取出內容的重要性根據Query和Key的相似性來決定,之後對Value進行加權求和,這樣就可以取出最終的Value值,也即Attention值。所以不少研究人員將Attention機制看作軟定址的一種特例,這也是非常有道理的。
至於Attention機制的具體計算過程,如果對目前大多數方法進行抽象的話,可以將其歸納為兩個過程:第一個過程是根據Query和Key計算權重係數,第二個過程根據權重係數對Value進行加權求和。而第一個過程又可以細分為兩個階段:第一個階段根據Query和Key計算兩者的相似性或者相關性;第二個階段對第一階段的原始分值進行歸一化處理;這樣,可以將Attention的計算過程抽象為如圖10展示的三個階段。
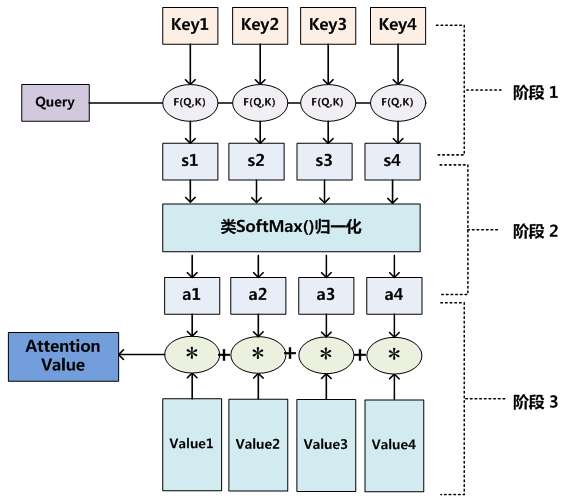
圖10 三階段計算Attention過程
在第一個階段,可以引入不同的函式和計算機制,根據Query和某個Keyi,計算兩者的相似性或者相關性,最常見的方法包括:求兩者的向量點積、求兩者的向量Cosine相似性或者通過再引入額外的神經網路來求值,即如下方式:

第一階段產生的分值根據具體產生的方法不同其數值取值範圍也不一樣,第二階段引入類似SoftMax的計算方式對第一階段的得分進行數值轉換,一方面可以進行歸一化,將原始計算分值整理成所有元素權重之和為1的概率分佈;另一方面也可以通過SoftMax的內在機制更加突出重要元素的權重。即一般採用如下公式計算:
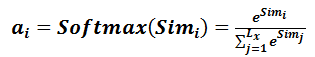
第二階段的計算結果ai即為Valuei對應的權重係數,然後進行加權求和即可得到Attention數值:

通過如上三個階段的計算,即可求出針對Query的Attention數值,目前絕大多數具體的注意力機制計算方法都符合上述的三階段抽象計算過程。
Self Attention模型
通過上述對Attention本質思想的梳理,我們可以更容易理解本節介紹的Self Attention模型。Self Attention也經常被稱為intra Attention(內部Attention),最近一年也獲得了比較廣泛的使用,比如Google最新的機器翻譯模型內部大量採用了Self Attention模型。在一般任務的Encoder-Decoder框架中,輸入Source和輸出Target內容是不一樣的,比如對於英-中機器翻譯來說,Source是英文句子,Target是對應的翻譯出的中文句子,Attention機制發生在Target的元素Query和Source中的所有元素之間。而Self Attention顧名思義,指的不是Target和Source之間的Attention機制,而是Source內部元素之間或者Target內部元素之間發生的Attention機制,也可以理解為Target=Source這種特殊情況下的注意力計算機制。其具體計算過程是一樣的,只是計算物件發生了變化而已,所以此處不再贅述其計算過程細節。
如果是常規的Target不等於Source情形下的注意力計算,其物理含義正如上文所講,比如對於機器翻譯來說,本質上是目標語單詞和源語單詞之間的一種單詞對齊機制。那麼如果是Self Attention機制,一個很自然的問題是:通過Self Attention到底學到了哪些規律或者抽取出了哪些特徵呢?或者說引入Self Attention有什麼增益或者好處呢?我們仍然以機器翻譯中的Self Attention來說明,圖11和圖12是視覺化地表示Self Attention在同一個英語句子內單詞間產生的聯絡。
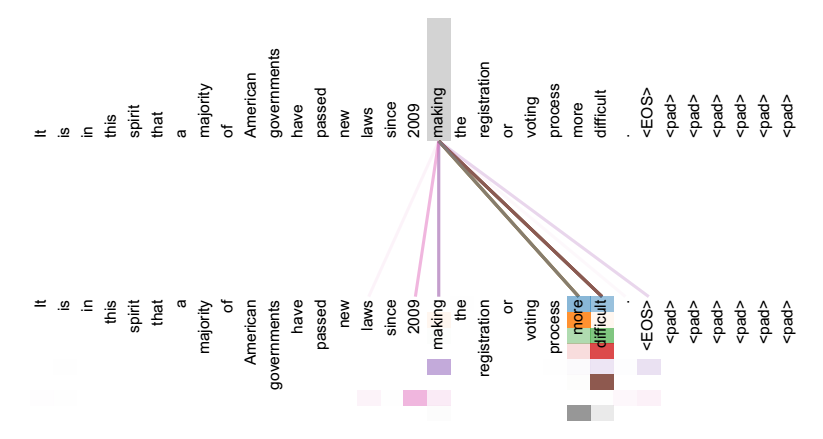
圖11 視覺化Self Attention例項
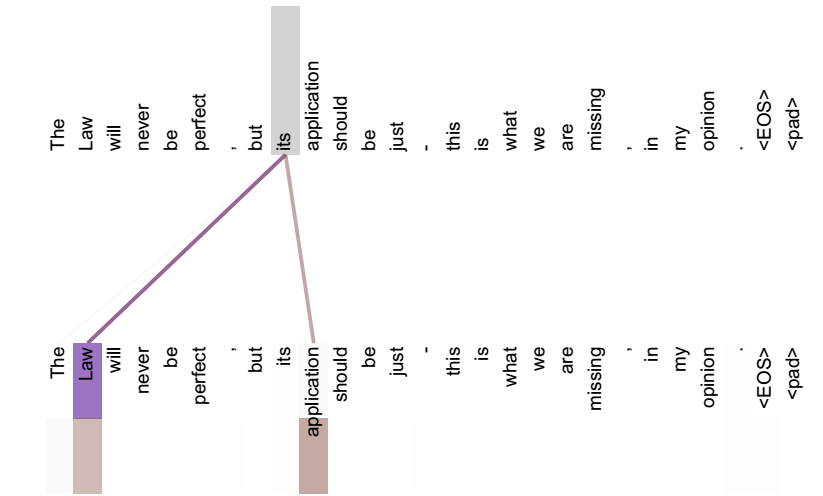
圖12 視覺化Self Attention例項
從兩張圖(圖11、圖12)可以看出,Self Attention可以捕獲同一個句子中單詞之間的一些句法特徵(比如圖11展示的有一定距離的短語結構)或者語義特徵(比如圖12展示的its的指代物件Law)。很明顯,引入Self Attention後會更容易捕獲句子中長距離的相互依賴的特徵,因為如果是RNN或者LSTM,需要依次序序列計算,對於遠距離的相互依賴的特徵,要經過若干時間步步驟的資訊累積才能將兩者聯絡起來,而距離越遠,有效捕獲的可能性越小。但是Self Attention在計算過程中會直接將句子中任意兩個單詞的聯絡通過一個計算步驟直接聯絡起來,所以遠距離依賴特徵之間的距離被極大縮短,有利於有效地利用這些特徵。除此外,Self Attention對於增加計算的並行性也有直接幫助作用。這是為何Self Attention逐漸被廣泛使用的主要原因。
Attention機制的應用
前文有述,Attention機制在深度學習的各種應用領域都有廣泛的使用場景。上文在介紹過程中我們主要以自然語言處理中的機器翻譯任務作為例子,下面分別再從影象處理領域和語音識別選擇典型應用例項來對其應用做簡單說明。
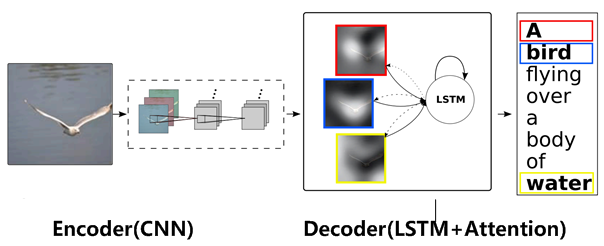
圖13 圖片-描述任務的Encoder-Decoder框架
圖片描述(Image-Caption)是一種典型的圖文結合的深度學習應用,輸入一張圖片,人工智慧系統輸出一句描述句子,語義等價地描述圖片所示內容。很明顯這種應用場景也可以使用Encoder-Decoder框架來解決任務目標,此時Encoder輸入部分是一張圖片,一般會用CNN來對圖片進行特徵抽取,Decoder部分使用RNN或者LSTM來輸出自然語言句子(參考圖13)。此時如果加入Attention機制能夠明顯改善系統輸出效果,Attention模型在這裡起到了類似人類視覺選擇性注意的機制,在輸出某個實體單詞的時候會將注意力焦點聚焦在圖片中相應的區域上。圖14給出了根據給定圖片生成句子“A person is standing on a beach with a surfboard.”過程時每個單詞對應圖片中的注意力聚焦區域。

圖14 圖片生成句子中每個單詞時的注意力聚焦區域
圖15給出了另外四個例子形象地展示了這種過程,每個例子上方左側是輸入的原圖,下方句子是人工智慧系統自動產生的描述語句,上方右側圖展示了當AI系統產生語句中劃橫線單詞的時候,對應圖片中聚焦的位置區域。比如當輸出單詞dog的時候,AI系統會將注意力更多地分配給圖片中小狗對應的位置。

圖15 影象描述任務中Attention機制的聚焦作用
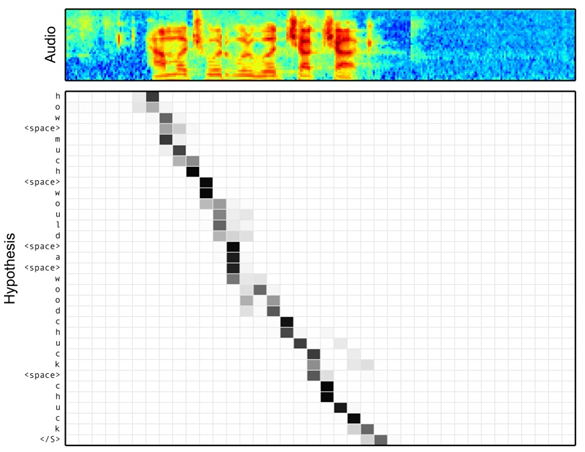
圖16 語音識別中音訊序列和輸出字元之間的Attention
語音識別的任務目標是將語音流訊號轉換成文字,所以也是Encoder-Decoder的典型應用場景。Encoder部分的Source輸入是語音流訊號,Decoder部分輸出語音對應的字串流。圖16視覺化地展示了在Encoder-Decoder框架中加入Attention機制後,當用戶用語音說句子 how much would a woodchuck chuck 時,輸入部分的聲音特徵訊號和輸出字元之間的注意力分配概率分佈情況,顏色越深代表分配到的注意力概率越高。從圖中可以看出,在這個場景下,Attention機制起到了將輸出字元和輸入語音訊號進行對齊的功能。
上述內容僅僅選取了不同AI領域的幾個典型Attention機制應用例項,Encoder-Decoder加Attention架構由於其卓越的實際效果,目前在深度學習領域裡得到了廣泛的使用,瞭解並熟練使用這一架構對於解決實際問題會有極大幫助。