
深度學習中Attention Mechanism詳細介紹:原理、分類及應用
Attention是一種用於提升基於RNN(LSTM或GRU)的Encoder + Decoder模型的效果的的機制(Mechanism),一般稱為Attention Mechanism。Attention Mechanism目前非常流行,廣泛應用於機器翻譯、語音識別、影象標註(Image Caption)等很多領域,之所以它這麼受歡迎,是因為Attention給模型賦予了區分辨別的能力,例如,在機器翻譯、語音識別應用中,為句子中的每個詞賦予不同的權重,使神經網路模型的學習變得更加靈活(soft),同時Attention本身可以做為一種對齊關係,解釋翻譯輸入/輸出句子之間的對齊關係,解釋模型到底學到了什麼知識,為我們開啟深度學習的黑箱,提供了一個視窗,如圖1所示。
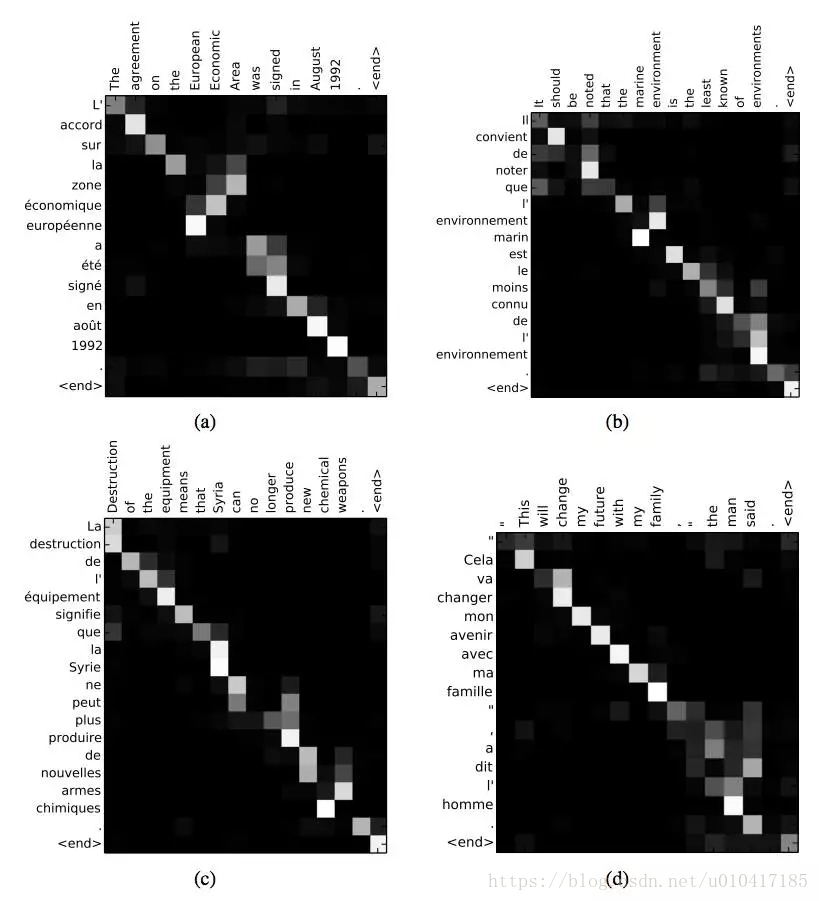
圖1 NLP中的attention視覺化
又比如在影象標註應用中,可以解釋圖片不同的區域對於輸出Text序列的影響程度。

圖2 影象標註中的attention視覺化
通過上述Attention Mechanism在影象標註應用的case可以發現,Attention Mechanism與人類對外界事物的觀察機制很類似,當人類觀察外界事物的時候,一般不會把事物當成一個整體去看,往往傾向於根據需要選擇性的去獲取被觀察事物的某些重要部分,比如我們看到一個人時,往往先Attention到這個人的臉,然後再把不同區域的資訊組合起來,形成一個對被觀察事物的整體印象。
|
有了這些背景知識的鋪墊,接下來就一一介紹下Attention Mechanism其他細節,在接寫來的內容裡,我會主要介紹以下一些知識: 1. Attention Mechanism原理 1.1 Attention Mechanism主要需要解決的問題 1.2 Attention Mechanism原理 2. Attention Mechanism分類 基本attention結構 2.1 soft Attention 與Hard Attention 2.2 Global Attention 和 Local Attention 2.3 Self Attention 組合的attention結構 2.4 Hierarchical Attention 2.5 Attention in Attention 2.3 Multi-Step Attention 3. Attention的應用場景 3.1 機器翻譯(Machine Translation) 3.2 影象標註(Image Captain) 3.3 關係抽取(EntailMent Extraction) 3.4 語音識別(Speech Recognition) 3.5 自動摘要生成(Text Summarization) |
1. Attention Mechanism原理
1.1 Attention Mechanism主要需要解決的問題
《Sequence to Sequence Learning with Neural Networks》介紹了一種基於RNN的Seq2Seq模型,基於一個Encoder和一個Decoder來構建基於神經網路的End-to-End的機器翻譯模型,其中,Encoder把輸入X編碼成一個固定長度的隱向量Z,Decoder基於隱向量Z解碼出目標輸出Y。這是一個非常經典的序列到序列的模型,但是卻存在兩個明顯的問題:
1、把輸入X的所有資訊有壓縮到一個固定長度的隱向量Z,忽略了輸入輸入X的長度,當輸入句子長度很長,特別是比訓練集中最初的句子長度還長時,模型的效能急劇下降。
2、把輸入X編碼成一個固定的長度,對於句子中每個詞都賦予相同的權重,這樣做是不合理的,比如,在機器翻譯裡,輸入的句子與輸出句子之間,往往是輸入一個或幾個詞對應於輸出的一個或幾個詞。因此,對輸入的每個詞賦予相同權重,這樣做沒有區分度,往往是模型效能下降。
同樣的問題也存在於影象識別領域,卷積神經網路CNN對輸入的影象每個區域做相同的處理,這樣做沒有區分度,特別是當處理的影象尺寸非常大時,問題更明顯。因此,2015年,Dzmitry Bahdanau等人在《Neural machine translation by jointly learning to align and translate》提出了Attention Mechanism,用於對輸入X的不同部分賦予不同的權重,進而實現軟區分的目的。
1.2 Attention Mechanism原理
要介紹Attention Mechanism結構和原理,首先需要介紹下Seq2Seq模型的結構。基於RNN的Seq2Seq模型主要由兩篇論文介紹,只是採用了不同的RNN模型。Ilya Sutskever等人與2014年在論文《Sequence to Sequence Learning with Neural Networks》中使用LSTM來搭建Seq2Seq模型。隨後,2015年,Kyunghyun Cho等人在論文《Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation》提出了基於GRU的Seq2Seq模型。兩篇文章所提出的Seq2Seq模型,想要解決的主要問題是,如何把機器翻譯中,變長的輸入X對映到一個變長輸出Y的問題,其主要結構如圖3所示。
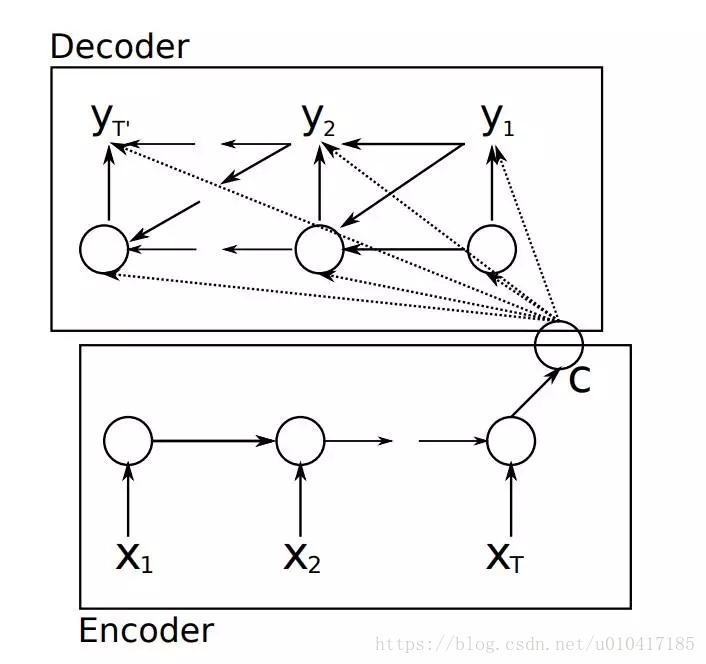
圖3 傳統的Seq2Seq結構
其中,Encoder把一個變成的輸入序列x1,x2,x3....xt編碼成一個固定長度隱向量(背景向量,或上下文向量context)c,c有兩個作用:1、做為初始向量初始化Decoder的模型,做為decoder模型預測y1的初始向量。2、做為背景向量,指導y序列中每一個step的y的產出。Decoder主要基於背景向量c和上一步的輸出yt-1解碼得到該時刻t的輸出yt,直到碰到結束標誌(<EOS>)為止。
如上文所述,傳統的Seq2Seq模型對輸入序列X缺乏區分度,因此,2015年,Kyunghyun Cho等人在論文《Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation》中,引入了Attention Mechanism來解決這個問題,他們提出的模型結構如圖4所示。
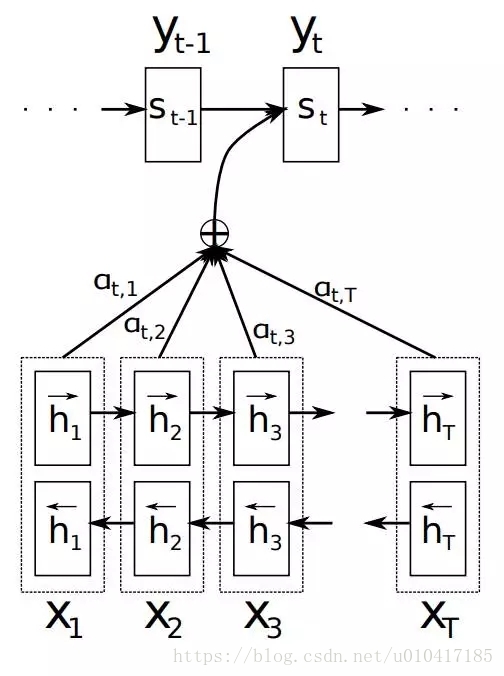
圖4 Attention Mechanism模組圖解
在該模型中,定義了一個條件概率:
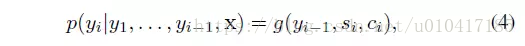
其中,si是decoder中RNN在在i時刻的隱狀態,如圖4中所示,其計算公式為:
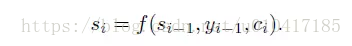
這裡的背景向量ci的計算方式,與傳統的Seq2Seq模型直接累加的計算方式不一樣,這裡的ci是一個權重化(Weighted)之後的值,其表示式如公式5所示:
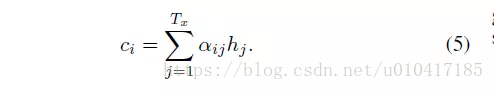
其中,i表示encoder端的第i個詞,hj表示encoder端的第j和詞的隱向量,aij表示encoder端的第j個詞與decoder端的第i個詞之間的權值,表示源端第j個詞對目標端第i個詞的影響程度,aij的計算公式如公式6所示:
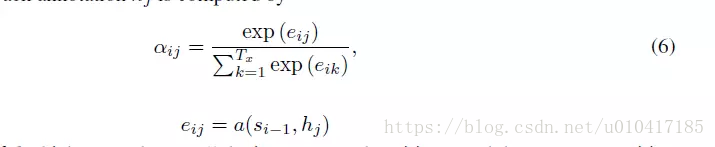
在公式6中,aij是一個softmax模型輸出,概率值的和為1。eij表示一個對齊模型,用於衡量encoder端的位置j個詞,對於decoder端的位置i個詞的對齊程度(影響程度),換句話說:decoder端生成位置i的詞時,有多少程度受encoder端的位置j的詞影響。對齊模型eij的計算方式有很多種,不同的計算方式,代表不同的Attention模型,最簡單且最常用的的對齊模型是dot product乘積矩陣,即把target端的輸出隱狀態ht與source端的輸出隱狀態進行矩陣乘。常見的對齊計算方式如下:
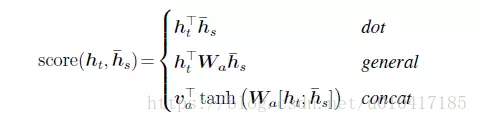
其中,Score(ht,hs) = aij表示源端與目標單單詞對齊程度。可見,常見的對齊關係計算方式有,點乘(Dot product),權值網路對映(General)和concat對映幾種方式。
2. Attention Mechanism分類
2.1 soft Attention 和Hard Attention
Kelvin Xu等人與2015年發表論文《Show, Attend and Tell: Neural Image Caption Generation with Visual Attention》,在Image Caption中引入了Attention,當生成第i個關於圖片內容描述的詞時,用Attention來關聯與i個詞相關的圖片的區域。Kelvin Xu等人在論文中使用了兩種Attention Mechanism,即Soft Attention和Hard Attention。我們之前所描述的傳統的Attention Mechanism就是Soft Attention。Soft Attention是引數化的(Parameterization),因此可導,可以被嵌入到模型中去,直接訓練。梯度可以經過Attention Mechanism模組,反向傳播到模型其他部分。
相反,Hard Attention是一個隨機的過程。Hard Attention不會選擇整個encoder的輸出做為其輸入,Hard Attention會依概率Si來取樣輸入端的隱狀態一部分來進行計算,而不是整個encoder的隱狀態。為了實現梯度的反向傳播,需要採用蒙特卡洛取樣的方法來估計模組的梯度。
兩種Attention Mechanism都有各自的優勢,但目前更多的研究和應用還是更傾向於使用Soft Attention,因為其可以直接求導,進行梯度反向傳播。
2.2 Global Attention 和 Local Attention
Global Attention:傳統的Attention model一樣。所有的hidden state都被用於計算Context vector 的權重,即變長的對齊向量at,其長度等於encoder端輸入句子的長度。結構如圖5所示。
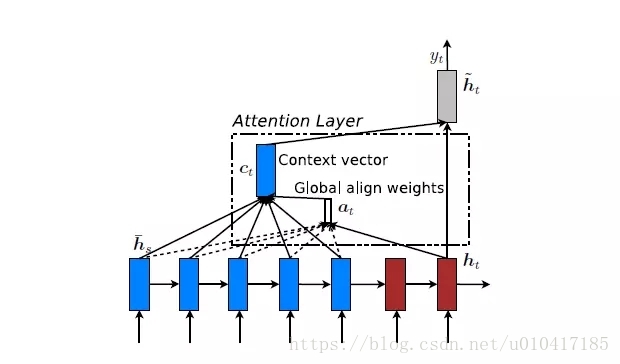
圖5 Global Attention模型示意圖
在t時刻,首先基於decoder的隱狀態ht和源端的隱狀態hs,計算一個變長的隱對齊權值向量at,其計算公式如下:

其中,score是一個用於評價ht與hs之間關係的函式,即對齊函式,一般有三種計算方式,我們在上文中已經提到了。公式如下:
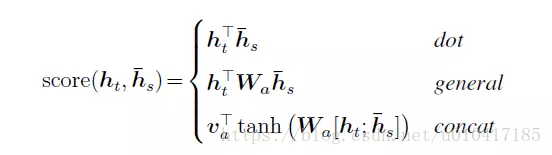
得到對齊向量at之後,就可以通過加權平均的方式,得到上下文向量ct。
Local Attention:Global Attention有一個明顯的缺點就是,每一次,encoder端的所有hidden state都要參與計算,這樣做計算開銷會比較大,特別是當encoder的句子偏長,比如,一段話或者一篇文章,效率偏低。因此,為了提高效率,Local Attention應運而生。
Local Attention是一種介於Kelvin Xu所提出的Soft Attention和Hard Attention之間的一種Attention方式,即把兩種方式結合起來。其結構如圖6所示。
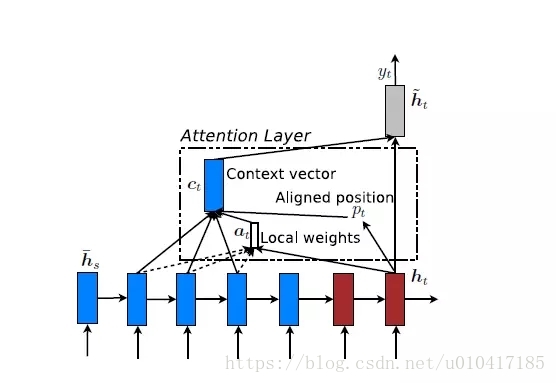
圖6 Local Attention模型示意圖
Local Attention首先會為decoder端當前的詞,預測一個source端對齊位置(aligned position)pt,然後基於pt選擇一個視窗,用於計算背景向量ct。Position pt的計算公式如下:
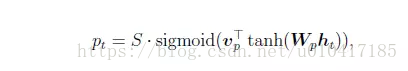
其中,S是encoder端句子長度,vp和wp是模型引數。此時,對齊向量at的計算公式如下:
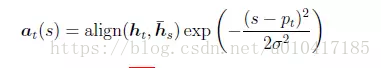
總之,Global Attention和Local Attention各有優劣,在實際應用中,Global Attention應用更普遍,因為local Attention需要預測一個位置向量p,這就帶來兩個問題:1、當encoder句子不是很長時,相對Global Attention,計算量並沒有明顯減小。2、位置向量pt的預測並不非常準確,這就直接計算的到的local Attention的準確率。
2.3 Self Attention
Self Attention與傳統的Attention機制非常的不同:傳統的Attention是基於source端和target端的隱變數(hidden state)計算Attention的,得到的結果是源端的每個詞與目標端每個詞之間的依賴關係。但Self Attention不同,它分別在source端和target端進行,僅與source input或者target input自身相關的Self Attention,捕捉source端或target端自身的詞與詞之間的依賴關係;然後再把source端的得到的self Attention加入到target端得到的Attention中,捕捉source端和target端詞與詞之間的依賴關係。因此,self Attention Attention比傳統的Attention mechanism效果要好,主要原因之一是,傳統的Attention機制忽略了源端或目標端句子中詞與詞之間的依賴關係,相對比,self Attention可以不僅可以得到源端與目標端詞與詞之間的依賴關係,同時還可以有效獲取源端或目標端自身詞與詞之間的依賴關係,如圖7所示。
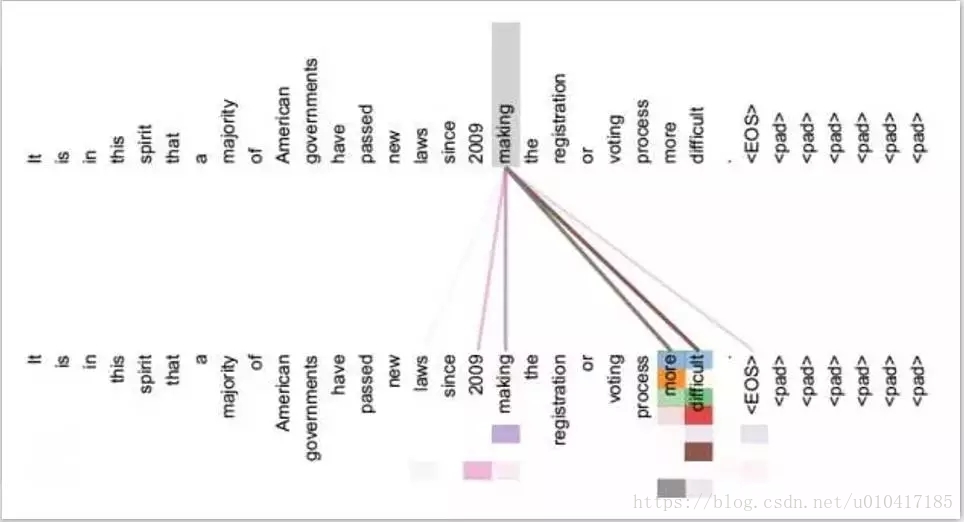
圖7 self attention視覺化例項,圖片摘自《深度學習中的注意力機制》,張俊林
Self Attention的具體計算方式如圖8所示:
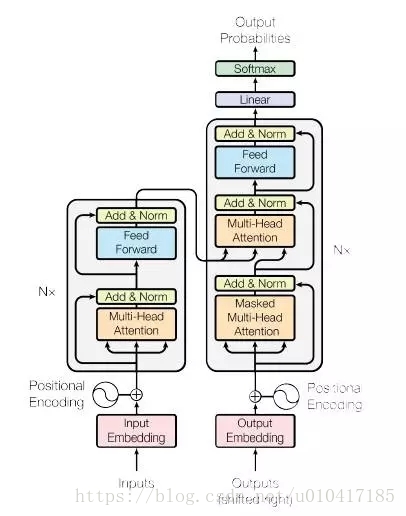
圖8 All Attention模型結構示意圖
Encoder的輸入inputs和decoder的輸入outputs,加上position embedding,做為各自的最初的輸入,那麼問題來了,self Attention具體是怎麼實現的呢?從All Attention的結構示意圖可以發現,Encoder和decoder是層疊多了類似的Multi-Head Attention單元構成,而每一個Multi-Head Attention單元由多個結構相似的Scaled Dot-Product Attention單元組成,結構如圖9所示。
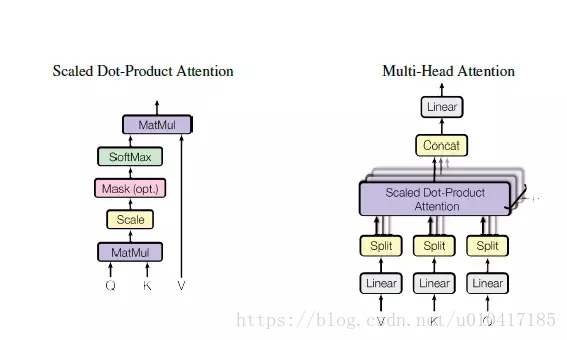
圖9 Multi-Head Attention結構示意圖
Self Attention也是在Scaled Dot-Product Attention單元裡面實現的,如上圖左圖所示,首先把輸入Input經過線性變換分別得到Q、K、V,注意,Q、K、V都來自於Input,只不過是線性變換的矩陣的權值不同而已。然後把Q和K做dot Product相乘,得到輸入Input詞與詞之間的依賴關係,然後經過尺度變換(scale)、掩碼(mask)和softmax操作,得到最終的Self Attention矩陣。尺度變換是為了防止輸入值過大導致訓練不穩定,mask則是為了保證時間的先後關係。
最後,把encoder端self Attention計算的結果加入到decoder做為k和V,結合decoder自身的輸出做為q,得到encoder端的attention與decoder端attention之間的依賴關係。
Attention其他一些組合使用
2.4 Hierarchical Attention
Zichao Yang等人在論文《Hierarchical Attention Networks for Document Classification》提出了Hierarchical Attention用於文件分類。Hierarchical Attention構建了兩個層次的Attention Mechanism,第一個層次是對句子中每個詞的attention,即word attention;第二個層次是針對文件中每個句子的attention,即sentence attention。網路結構如圖10所示。
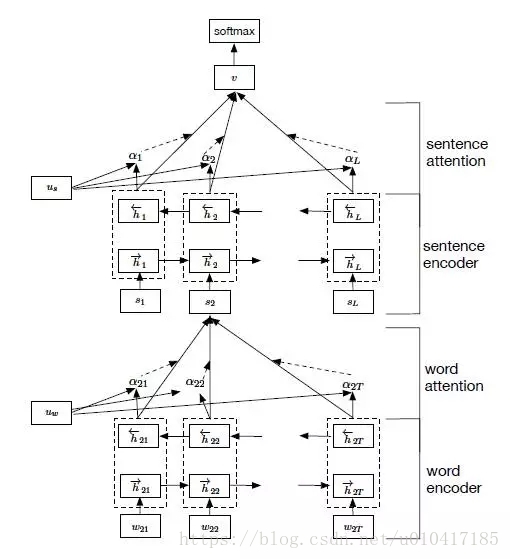
整個網路結構由四個部分組成:一個由雙向RNN(GRU)構成的word sequence encoder,然後是一個關於詞的word-level的attention layer;基於word attention layar之上,是一個由雙向RNN構成的sentence encoder,最後的輸出層是一個sentence-level的attention layer。
2.5 Attention over Attention
Yiming Cui與2017年在論文《Attention-over-Attention Neural Networks for Reading Comprehension》中提出了Attention Over Attention的Attention機制,結構如圖11所示。
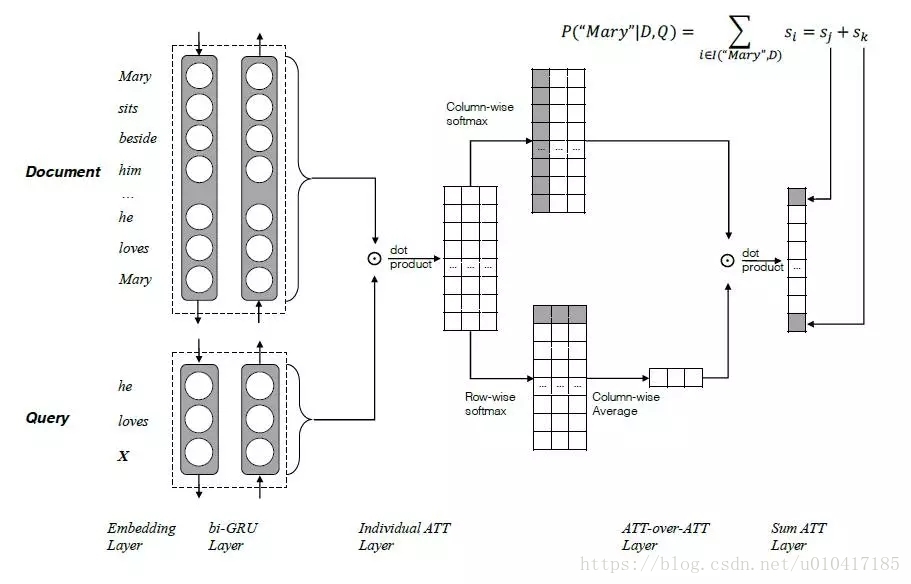
圖11 Attention over Attention結構示意圖
兩個輸入,一個Document和一個Query,分別用一個雙向的RNN進行特徵抽取,得到各自的隱狀態h(doc)和h(query),然後基於query和doc的隱狀態進行dot product,得到query和doc的attention關聯矩陣。然後按列(colum)方向進行softmax操作,得到query-to-document的attention 值a(t);按照行(row)方向進行softmax操作,得到document-to-query的attention值b(t),再按照列方向進行累加求平均得到平均後的attention值b(t)。最後再基於上一步attention操作得到a(t)和b(t),再進行attention操作,即attention over attention得到最終query與document的關聯矩陣。
2.6 Multi-step Attention
2017年,FaceBook 人工智慧實驗室的Jonas Gehring等人在論文《Convolutional Sequence to Sequence Learning》提出了完全基於CNN來構建Seq2Seq模型,除了這一最大的特色之外,論文中還採用了多層Attention Mechanism,來獲取encoder和decoder中輸入句子之間的關係,結構如圖12所示。
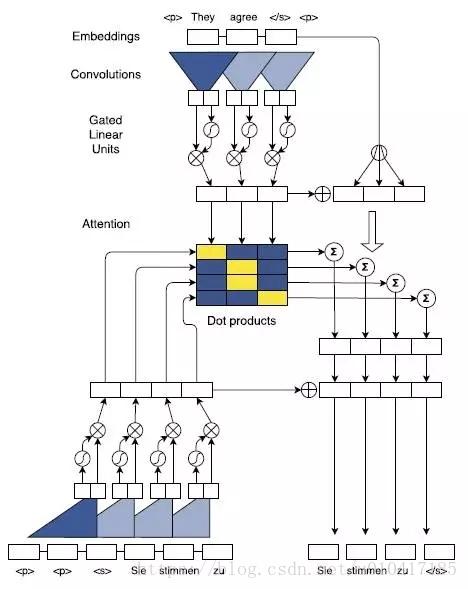
圖12 Multi-step Attention結構示意圖
完全基於CNN的Seq2Seq模型需要通過層疊多層來獲取輸入句子中詞與詞之間的依賴關係,特別是當句子非常長的時候,我曾經實驗證明,層疊的層數往往達到10層以上才能取得比較理想的結果。針對每一個卷記得step(輸入一個詞)都對encoder的hidden state和decoder的hidden state進行dot product計算得到最終的Attention 矩陣,並且基於最終的attention矩陣去指導decoder的解碼操作。
3. Attention的應用場景
本節主要給出一些基於Attention去處理序列預測問題的例子,以下內容整理翻譯自:https://machinelearningmastery.com/attention-long-short-term-memory-recurrent-neural-networks/
1.機器翻譯
給定一個法語句子做為輸入序列,翻譯並輸出一個英文句子做為輸出序列。Attention用於關聯輸出序列中每個單詞與輸入序列中的某個特定單詞的關聯程度。
“我們擴充套件了傳統的編碼器-解碼器結構,賦予decoder,在生成目標端(target)的詞時,可以自動(軟)搜尋一組與之相關的輸入序列的能力。這使得模型不必將整個源句子編碼成一個固定長度的向量,並且還使模型只關注源端與下一個目標詞的生成有關的資訊。”
- Dzmitry Bahdanau等人,《Neural machine translation by jointly learning to align and translate》,2015。
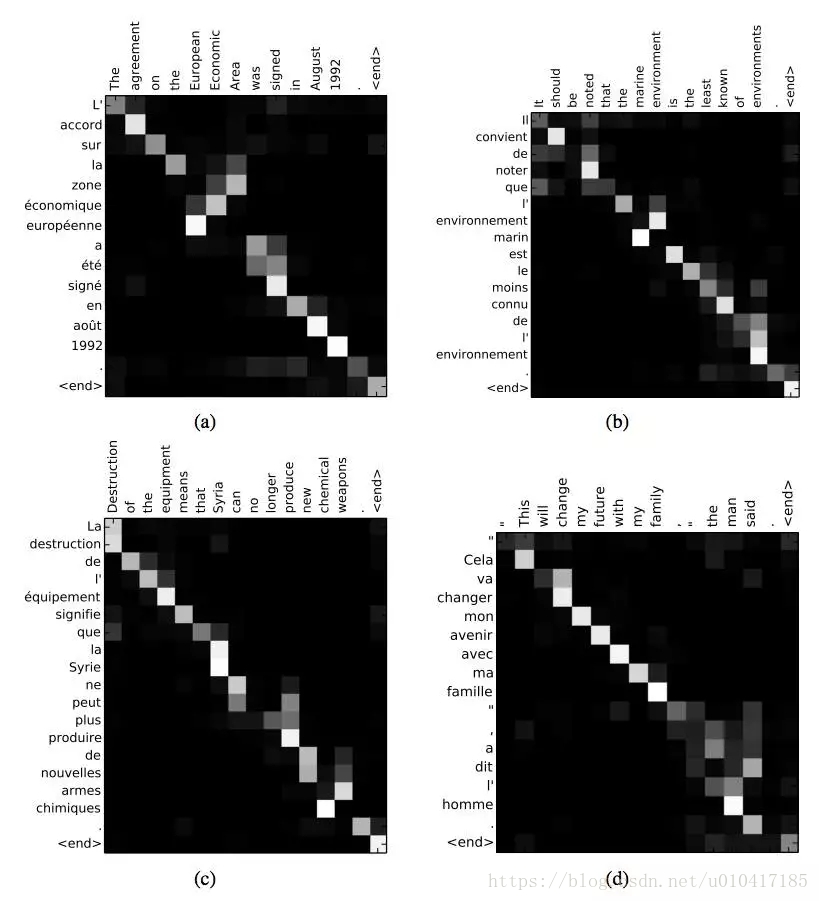
通過Attention來解釋法語到英語單詞之間的對應關係。摘自Dzmitry Bahdanau的論文
2.影象標註(Image Caption)
基於序列的Attention Mechanism可以應用於計算機視覺問題,以幫助理解如何最好地利用卷積神經網路來省長一段關於圖片內容的描述,也稱為Caption。
給定輸入影象,輸出影象的英文描述。使用Attention是為輸出序列中的每個單詞關注影象中不同部分。
“我們提出了一種基於Attention mechanism的方法,並在在三個標準資料集上都取得了最好的成績...我們還展示瞭如何利用學到的Attention來提供更多對模型生成過程的解釋,並且證明Attention學習到的對齊與人類視覺感知非常一致。”
Kelvin Xu等人,《Attend and Tell: Neural Image Caption Generation with Visual Attention》, 2016

基於Attention來解釋,生成英文描述中某一個詞時,與圖片中某一區域的高度依賴關係。
3. 蘊含關係推理(Entailment Reasoning)
給定一個用英語描述前景描述(premise scenario)和假設(hypothesis),判讀假設(premise)與假設(hypothesis)的關係:矛盾,相關或包含。
例如:
前提:“一場婚禮中拍照”
假設:“有人結婚”
Attention被用來把假設中的每個單詞與前提中的單詞聯絡起來,反之亦然。
“我們提出了一個基於LSTM的神經模型,它一次讀取兩個句子來確定兩個句子之間的蘊含關係,而不是將每個句子獨立對映到一個語義空間。我們引入逐字的(word-by-word)Attention Mechanism來擴充套件這個模型,來強化模型對單詞或短語對的關係推理能力。該模型比傳統的僅基於LSTM的模型高2.6個百分點,取得了一個最高成就”
-Tim Rocktäschel,《Reasoning about Entailment with Neural Attention》, 2016
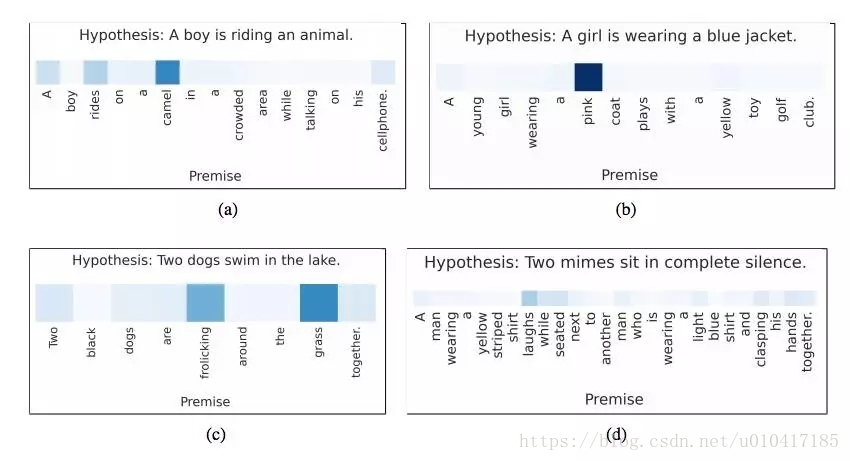
基於Attention來解釋前提和假設中詞與詞之間的對應關係
4. 語音識別
給定一段英語語音片段做為輸入序列,輸出對應的音素序列。
Attention被用聯將輸出序列中的每個音素與輸入序列中的特定音訊幀相關聯。
“基於混合Attention機制的新型端到端可訓練語音識別體系結構,其結合內容和位置資訊幫助選擇輸入序列中的下一個位置用於解碼。所提出的模型的一個理想特性就是它可以識別比訓練集中句子的更長的句子。”
-Jan Chorowski,《Attention-Based Models for Speech Recognition》, 2015.。
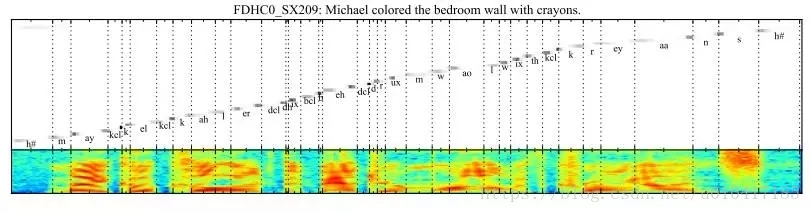
基於Attention來解釋輸出音素與輸入端的聲音片段的對應關係
5.文字摘要生成
給定一篇英文文章做為輸入順序,輸出一個總結英文文章注意內容的摘要句子。
Attention用於將輸出摘要中的每個單詞與輸入文件中的特定單詞相關聯。
“將基於Attention的神經網路用語摘要抽取。我們將這個概率模型與可以產生準確的摘要的生成演算法相結合。”
-Alexander M. Rush,《A Neural Attention Model for Abstractive Sentence Summarization》, 2015
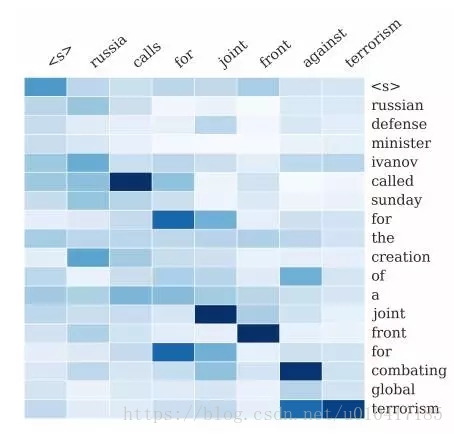
基於Attention來解釋輸入Sentence與輸出Summary之間單詞的對應關係
Attention Mechanism現在應用非常廣泛,這裡就列出這幾個case供大家參考。