
Python實現mapreduce程式
一:目的
之前面試曾遇到面試官讓用python程式碼實現mapreduce中最簡單的demo WordCount,由於之前一直用java來寫hadoop程式,突然轉到python,是我產生了質疑,python與hadoop應該是不相容的,即使寫出來程式,到時候怎麼執行?一頭霧水最後導致面試失敗。後來通過查閱資料,研究mapreduce的底層實現,發現儘管Hadoop框架是用Java編寫的,但是為Hadoop編寫的程式不必非要Java寫,還可以使用其他語言開發,比如Python或C++(Haoop在0.14.1版本提供C++ API),而mapreduce只是一種思想,跟語言無關。$HADOOP_HOME/src/examples/python/WordCount.py,你就可以明白我的意思了。
現在將會採用python語言實現wordcount並在hadoop上執行實現。
二:Python程式碼
map實現:
下面Python程式碼的一個“竅門”是我們將使用Hadoop流API(可以看下相關的維基條目)來幫助我們通過STDIN(標準輸入)和STDOUT(標準輸出)在Map和Reduce程式碼間傳遞資料。我們只是使用Python的sys.stdin讀取輸入資料和列印輸出到sys.stdout。這就是我們需要做的,因為Hadoop流將處理好一切。將下面的程式碼儲存在檔案 /home/hduser/mapper.py 中。它將從STDIN讀取資料,拆分為單詞並輸出一組對映單詞和它們數量(中間值)的行到STDOUT。儘管這個Map指令碼不會計算出單詞出現次數的總和(中間值)。相反,它會立即輸出( 1)元組的形式——即使某個特定的單詞可能會在輸入中出現多次。在我們的例子中,我們讓後續的Reduce做最終的總和計數。當然,你可以按照你的想法在你自己的指令碼中修改這段程式碼,但是,由於教學原因,我們在本教程中就先這樣做。:-)
請確保該檔案具有可執行許可權(chmod +x /home/hduser/mapper.py ),否則你會遇到問題。
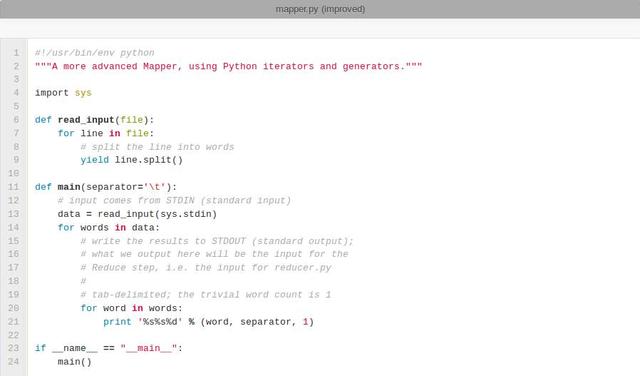
reduce實現:
將下面的程式碼儲存在檔案 /home/hduser/reducer.py 中。它將從STDIN讀取mapper.py的結果(因此mapper.py的輸出格式和reducer.py預期的輸入格式必須匹配),然後統計每個單詞出現的次數,最後將結果輸出到STDOUT中。
請確保該檔案具有可執行許可權(chmod +x /home/hduser/reducer.py ),否則你會遇到問題。
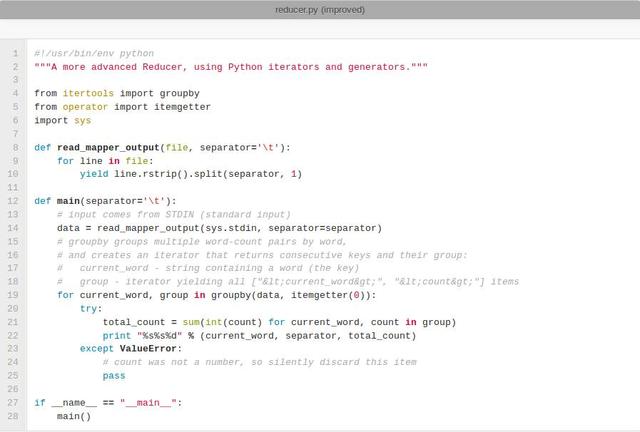
程式碼測試(cat data | map | sort | reduce):
在MapReduce作業中使用它們之前,我建議先在本地測試你的mapper.py和reducer.py指令碼。否則,你的作業可能成功完成了但沒有作業結果資料或得到了不是你想要的結果。如果發生這種情況,很有可能是你(或我)搞砸了。這裡有一些想法,關於如何測試這個Map和Reduce指令碼的功能。

執行程式碼:
下載示例輸入資料
下載每個檔案為純文字檔案,以UTF-8編譯並且將這些檔案儲存在一個臨時目錄中,如/tmp/gutenberg。
說明:你將需要在你的Cloudera虛擬機器中開啟瀏覽器。選擇適當的檔案下載(UTF-8 版本),它將顯示在你的瀏覽器中。點選滑鼠右鍵按鈕來儲存該檔案。給它一個合適的名稱(如”Ulysses”),並注意它將儲存在下載目錄中。

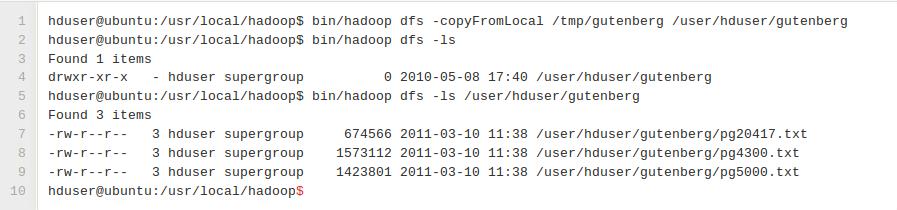
將本地示例資料拷貝到HDFS
在我們執行實際的MapReduce作業前,我們首先必須從我們本地檔案系統中拷貝檔案到Hadoop的HDFS內。
*說明:
我們假設你是在你的下載目錄中。我們必須在HDFS中建立一個子目錄,然後拷貝檔案過來。最後,我們驗證拷貝檔案成功。
首先,我們在HDFS中建立子目錄MyFirst:
[[email protected] Downloads]$ hadoop fs -mkdir MyFirst
然後,我們拷貝檔案。注意,三個檔案以.txt結尾:
[[email protected] Downloads]$ hadoop fs -copyFromLocal *.txt MyFirst
最後,我們驗證拷貝成功:
[[email protected] Downloads]$ hadoop fs -ls MyFirst
Found 3 items
-rw-r–r– 1 cloudera cloudera 1423803 2014-11-30 08:02 MyFirst/Leonardo.txt
-rw-r–r– 1 cloudera cloudera 674570 2014-11-30 08:02 MyFirst/OutlineOfScience.txt
-rw-r–r– 1 cloudera cloudera 1573150 2014-11-30 08:02 MyFirst/Ulysses.txt
執行MapReduce作業
*說明:
執行MapReduce作業,敲入如下命令:
[[email protected] ~]$ hadoop jar /usr/lib/hadoop-0.20-mapreduce/contrib/streaming/hadoop-streaming.jar -file mapper.py -mapper mapper.py
-file reducer.py -reducer reducer.py -input MyFirst/* -output MyFirst4-output
你會收到有關檔案被棄用的警告,不用擔心。重要的是:當你發出這條命令時,輸出目錄(在這個示例中是MyFirst-output)不存在。
驗證這個程式工作正常。首先,輸入命令:hadoop fs -ls MyFirst4-output
[[email protected] ~]$ hadoop fs -ls MyFirst4-output
Found 2 items
-rw-r–r– 1 cloudera cloudera 0 2014-11-30 09:23 MyFirst4-output/_SUCCESS
-rw-r–r– 1 cloudera cloudera 880829 2014-11-30 09:23 MyFirst4-output/part-00000
然後,檢視輸出檔案:
[[email protected] ~]$ hadoop fs -cat MyFirst4-output/part-00000
將檔案從HDFS中拷入到你本地檔案系統中:
[[email protected] ~]$ hadoop fs -copyToLocal MyFirst4-output/part-00000
MyFirstOutputLocal.txt
現在,一切都準備好了,我們終於可以在Hadoop叢集上執行我們的Python MapReduce作業了。如上所述,我們使用Hadoop流API通過STDIN和STDOUT在Map和Reduce間傳遞資料。

如果你想要在執行的時候修改Hadoop引數,如增加Reduce任務的數量,你可以使用-D選項:
[email protected]:/usr/local/hadoop$ bin/hadoop jar contrib/streaming/hadoop-streaming.jar -D mapred.reduce.tasks=16 …
關於mapred.map.tasks說明:Hadoop does not honor mapred.map.tasks beyond considering it a hint。但是,Hadoop接受使用者指定mapred.reduce.tasks並且不操作。你不能強制指定mapred.map.tasks,但可以指定mapred.reduce.tasks。
這個任務將讀取HDFS目錄/user/hduser/gutenberg中的所有檔案,處理它們,並將結果儲存在HDFS目錄/user/hduser/gutenberg-output中。一般情況下,Hadoop對每個reducer產生一個輸出檔案;在我們的示例中,然而它將只建立單個檔案因為輸入的檔案都很小。
在終端中前一個命令的輸出示例︰
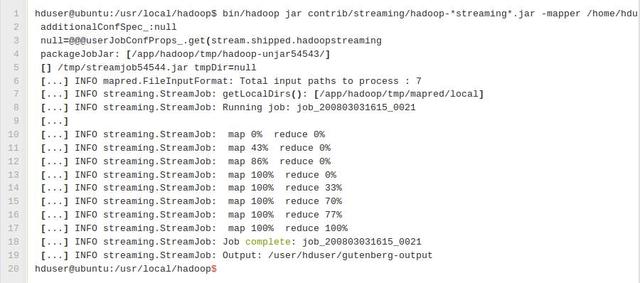
使用Python語言寫Hadoop MapReduce程式
**譯者說明:截圖中的命令不完整,完整命令如下:
[email protected]:/usr/local/hadoop$ bin/hadoop jar contrib/streaming/hadoop-streaming.jar -mapper /home/hduser/mapper.py -reducer /home/hduser/reducer.py -input /user/hduser/gutenberg/* -output /user/hduser/gutenberg-output
相關推薦
Python實現mapreduce程式
一:目的 之前面試曾遇到面試官讓用python程式碼實現mapreduce中最簡單的demo WordCount,由於之前一直用java來寫hadoop程式,突然轉到python,是我產生了質疑,python與hadoop應該是不相容的,即使寫出來程式,到時候
python實現小程式
1、楊輝三角形Python實現: 1 / \ 1 1 / \ / \ 1 2 1 / \ / \ / \ 1 3 3 1 / \ / \ / \ / \
python實現UDP程式通訊
一 程式碼 1、接收端 import socket #使用IPV4協議,使用UDP協議傳輸資料 s=socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
用python實現抽獎小程式的自動抽獎!公司抽獎必背技能!
不知道你們有沒有玩過無碼科技的小程式抽獎助手,沒有玩過的可以在微信小程式入門搜尋抽獎助手,首頁有很多獎品進行抽獎的,我前幾天發現了之後就把那裡的所有獎品都點了一次,就突發萌想,能不能用 python 來實現自動抽獎啊?這樣就不用我每天都點進去看了,我只需要關心是否中獎就可以了。答案是肯定的,今天就為
python實現Excel檔案讀取的程式(附原始碼)
python實現Excel檔案讀取的程式 前一段時間幫一個朋友用python寫了一個讀Excel程式操作的程式,具體要求為:讀取兩個Excel檔案,根據其中某個特徵的特徵值對這兩個檔案進行取交集操作,生成三個Excel檔案,第一個Excel檔案為這兩個檔案的公
python實現一個簡單的ftp程式
客戶端可以向伺服器端下載,上傳檔案 下載檔案指令:get_filename 上傳檔案指令:put_filename ftp工程目錄: ftp工作原理: put指令工作原理圖: put指令工作原理圖: 程式碼: 客戶端: impo
Python實現一個最簡單的MapReduce程式設計模型WordCount
MapReduce程式設計模型: Map:對映過程 Reduce:合併過程 import operator from functools import reduce # 需要處理的資料 lst = [ "Tom", "Jack",
Python Hadoop Mapreduce 實現Hadoop Streaming分組和二次排序
需求:公司給到一份全國各門店銷售資料,要求:1.按門店市場分類,將同一市場的門店放到一起;2.將各家門店按銷售額從大到小,再按利潤從大到小排列 一 需求一:按市場對門店進行分組 分組(partition) Hadoop streaming框架預設情況下會以’/t
介面測試基礎(fiddler、postman的使用、python實現測試介面程式)
寫在前面:本文主要的章節規劃: 1.什麼是介面測試 另外,有的時候會直接呼叫別的公司的介面,比如銀行的、淘寶的、支付寶的,此時也需要做介面測試以及驗證資料; 做介面測試的好處:
python實現的發紅包程式
本文轉載來自:https://www.zh30.com/python-hongbao1.html 注:如有侵權請告知,並刪除此文 最近網上出現了各種的搶紅包,支付寶、QQ、微信。其中一種拼手氣紅包,發紅包時使用者輸入一個紅包總金額和待發紅包總數,釋出紅包後,其它使用者搶紅包
利用Python的requests模組實現翻譯程式
1:安裝requests模組 pip install requests 2:開啟百度翻譯進行抓包,剛剛操作了一波發現pc版的正面不好剛,有sign不知道是什麼玩意,,emmmm,剛了半天不知道,所有切換到手機版,奇蹟出現了,,,嘿嘿嘿.... 3:抓取介面 Reque
Python實現微信小程式支付功能
由於最近自己在做小程式的支付,就在這裡簡單介紹一下講一下用python做小程式支付這個流程。當然在進行開發之前還是建議讀一下具體的流程,清楚支付的過程。 1.支付互動流程 2.獲取openid(微信使用者標識) 1 import requests 2 3 from config import
Maven工程的MapReduce程式3---實現統計各部門員工薪水總和功能(優化)
本文在實現統計各部門員工薪水總和功能的基礎上進行,還沒實現的話請參考:實現統計各部門員工薪水總和功能 優化專案: 1.使用序列化 2.實現分割槽Patitioner 3.Map使用Combiner 使用序列化 序列化與反序列化: 序列化是指將Java物件轉換
倒排索引的分散式實現(MapReduce程式)
package aturbo.index.inverted; import java.io.IOException; import java.util.HashSet; import org.apache.commons.lang3.StringUtils; imp
博導推薦給我一本基於Python實現爬蟲的書, 最適合程式猿們看的!
網際網路包括了至今為止最有效的資料集,並且大年夜大年夜區域性能地下收費拜候。但這些資料根基上不克不及複用。它們被嵌入在網站的佈局、樣式中,得抽取出來才調應用。我們從網頁中抽取資料的過程就是我們熟知的彙集爬蟲,網際網路期間每天都有大年夜大年夜量的資訊被頒佈發表到彙集上,彙集爬蟲也愈來愈有效。
用Python實現人工造雪,誰說程式設計師不懂浪漫!
1import pygame 2import random 3#初始化 4pygame.init() 載入背
python實現簡單的抽獎小程式,抽獎的內容從檔案裡面讀取
開啟檔案,讀取檔案的內容,隨機抽出一個然後刪掉已經抽出來的號碼 import randomfrom random import choicef = open('allnum.txt')data = f.read()a = datab = a.strip('\n').split('\n')pr
python實現增刪改查電話本程式筆記
import json class Person(): def init(self,name,tel): self.name=name self.tel=tel r=open(“notebook.json”,‘rb’) d=json.load® while True: action=inpu
基於XML和Python實現白盒測試程式與測試用例分離
【摘要】進行白盒測試時,或者將測試用例和測試程式混在一起難以閱讀;或者花很大精力構思用例的格式,然後編寫較複雜的程式進行用例的提取;本文提出一種XML用例編寫規範和解析思路,它基於python的XML解析器minidom,可以快速完成測試用例與測試程式分離。 鑑於XML
基於Jupyter平臺通過python實現Spark的應用程式之wordCount
1、啟動spark平臺,介面如下: 2、啟動Jupyter,介面如下圖所示: 如果你對以上啟動存在疑問的話,請看我的上一篇部落格,關於Jupyter配置Spark的。 3、功能分析 - 我們要實現的一個功能是統計詞頻 - 我們需要把統計的檔