
EM演算法原理與證明
EM演算法解高斯混合模型Gaussian Mixture Models
假設我們需要調查我們學校的男生和女生的身高分佈。在校園裡隨便地活捉了100個男生和100個女生,他們共200個人(也就是200個身高的樣本資料)。
高斯模型
你開始喊:“男的左邊,女的右邊,其他的站中間!”。然後你就先統計抽樣得到的100個男生的身高。假設他們的身高是服從高斯分佈N(u,∂)的。但是這個分佈的均值u和方差∂2我們不知道,這兩個引數就是我們要估計的。記作θ=[u, ∂]T。用數學的語言來說就是:在學校那麼多男生(身高)中,我們獨立地按照概率密度p(x|θ)(高斯分佈N(u,∂)的形式)抽取100了個(身高),組成樣本集X,我們想通過樣本集X來估計出未知引數θ。抽到的樣本集是X={x1,x2,…,xN},其中xi表示抽到的第i個人的身高,這裡抽到的樣本個數N就是100。用MLE解決的公式:

通過抽取得到的那100個男生的身高和已知其身高服從高斯分佈,我們通過最大化其似然函式,就可以得到了對應高斯分佈的引數θ=[u, ∂]T了。對於女生的身高分佈也可以用同樣的方法得到。
高斯混合模型
再回到例子本身,如果沒有“男的左邊,女的右邊,其他的站中間!”這個步驟,或者說我抽到這200個人都戴了面具。那現在這200個人已經混到一起了,這時候,你從這200個人(的身高)裡面隨便給我指一個人(的身高),我都無法確定這個人(的身高)是男生(的身高)還是女生(的身高)。也就是說你不知道抽取的那200個人裡面的每一個人到底是從男生的那個身高分佈裡面抽取的,還是女生的那個身高分佈抽取的。用數學的語言就是,抽取得到的每個樣本都不知道是從哪個分佈抽取的。這個時候,對於每一個樣本或者你抽取到的人,就有兩個東西需要猜測或者估計的了,一是這個人是男的還是女的?二是男生和女生對應的身高的高斯分佈的引數是多少? 只有當我們知道了哪些人屬於同一個高斯分佈的時候,我們才能夠對這個分佈的引數作出靠譜的預測。只有當我們對這兩個分佈的引數作出了準確的估計的時候,才能知道到底哪些人屬於第一個分佈,那些人屬於第二個分佈。
為了解決這個你依賴我,我依賴你的迴圈依賴問題,總得有一方要先打破僵局,先隨便整一個值出來,然後我再根據你的變化調整我的變化,然後如此迭代著不斷互相推導,最終就會收斂到一個解。
EM解高斯混合模型
在我們上面這個問題裡面,我們是先隨便猜一下男生(身高)的正態分佈的引數:如均值和方差是多少。例如男生的均值是1米7,方差是0.1米(當然了,剛開始肯定沒那麼準),然後計算出每個人更可能屬於第一個還是第二個正態分佈中的(lz某個身高值代入男生和女生的高斯分佈中,選擇概率大的作為其所在分佈),這個是屬於Expectation一步。
有了每個人的歸屬,已經大概地按上面的方法將這200個人分為男生和女生兩部分,我們就可以根據之前說的最大似然那樣,通過這些被大概分為男生的n個人來重新估計第一個分佈的引數,女生的那個分佈同樣方法重新估計。這個是Maximization。
然後,當我們更新了這兩個分佈的時候,每一個屬於這兩個分佈的概率又變了,那麼我們就再需要調整E步……如此往復,直到引數基本不再發生變化為止。
這裡把每個人(樣本)的完整描述看做是三元組yi={xi,zi1,zi2},其中,xi是第i個樣本的觀測值,對應身高,可觀測值。zi1和zi2表示男生和女生這兩個高斯分佈中哪個被用來產生值xi,就是說這兩個值標記這個人到底是男生還是女生(的身高分佈產生的)。這兩個值我們是不知道的,是隱含變數。確切的說,zij在xi由第j個高斯分佈產生時值為1,否則為0。例如一個樣本的觀測值為1.8,然後他來自男生的那個高斯分佈,那麼我們可以將這個樣本表示為{1.8, 1, 0}。如果zi1和zi2的值已知,也就是說每個人我已經標記為男生或者女生了,那麼我們就可以利用上面說的最大似然演算法來估計他們各自高斯分佈的引數。但是它們未知,因此我們只能用EM演算法。
假設已經知道這個隱含變量了,那麼直接按上面說的最大似然估計求解那個分佈的引數就好了。我們可以先給這個分佈弄一個初始值,然後求這個隱含變數的期望,當成是這個隱含變數的已知值,那麼現在就可以用最大似然求解那個分佈的引數了吧,那假設這個引數比之前的那個隨機的引數要好,它更能表達真實的分佈,那麼我們再通過這個引數確定的分佈去求這個隱含變數的期望,然後再最大化,得到另一個更優的引數,……迭代,就能得到一個皆大歡喜的結果了。
迭代時咋知道新的引數的估計就比原來的好啊?這些問題在數學上是可以穩當的證明的。
[Mitchell的Machine Learning書中一個EM應用的例子]
EM演算法
Jensen不等式
凸函式:優化理論中,設f是定義域為實數的函式,如果對於所有的實數x, ,那麼f是凸函式。當x是向量時,如果其hessian矩陣H是半正定的(
,那麼f是凸函式。當x是向量時,如果其hessian矩陣H是半正定的(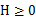 ),那麼f是凸函式。如果
),那麼f是凸函式。如果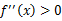 或者
或者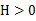 ,那麼稱f是嚴格凸函式。 當f是(嚴格)凹函式當且僅當-f是(嚴格)凸函式。比如
,那麼稱f是嚴格凸函式。 當f是(嚴格)凹函式當且僅當-f是(嚴格)凸函式。比如 是凹函式。
是凹函式。
Note: lz發現好多地方凸函式定義可能是相反的,國內外定義好像也不一樣。這裡只要記得,正常的碗就是凸函式!
Jensen不等式:如果f是凸函式,X是隨機變數,那麼 。特別地,如果f是嚴格凸函式,那麼
。特別地,如果f是嚴格凸函式,那麼 當且僅當
當且僅當 ,也就是說X是常量。Jensen不等式應用於凹函式時,不等號方向反向,也就是
,也就是說X是常量。Jensen不等式應用於凹函式時,不等號方向反向,也就是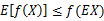 。
。
這裡我們將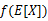 簡寫為
簡寫為 。
。
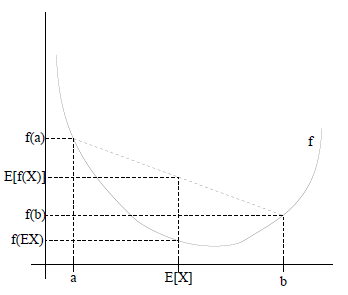
圖中,實線f是凸函式,X是隨機變數,有0.5的概率是a,有0.5的概率是b。(就像擲硬幣一樣)。X的期望值就是a和b的中值了,圖中可以看到![clip_image010[1]](http://images.cnblogs.com/cnblogs_com/jerrylead/201104/201104061615563561.png) 成立。
成立。
EM演算法
EM問題描述
給定的訓練樣本是 ,樣例間獨立,我們想找到每個樣例隱含的類別z,能使得p(x,z)最大。
,樣例間獨立,我們想找到每個樣例隱含的類別z,能使得p(x,z)最大。
p(x,z)的最大似然估計如下:

第一步是對極大似然取對數,第二步是對每個樣例的每個可能類別z求聯合分佈概率和。但是直接求θ一般比較困難,因為有隱藏變數z存在,但是一般確定了z後,求解就容易了。竟然不能直接最大化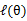 ,我們可以不斷地建立
,我們可以不斷地建立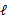 的下界(E步),然後優化下界(M步)[E步固定
的下界(E步),然後優化下界(M步)[E步固定![clip_image026[8]](http://images.cnblogs.com/cnblogs_com/jerrylead/201104/201104061617009740.png) ,優化
,優化 ,M步固定
,M步固定![clip_image107[1]](http://images.cnblogs.com/cnblogs_com/jerrylead/201104/20110406161702810.png) 優化
優化![clip_image026[9]](http://images.cnblogs.com/cnblogs_com/jerrylead/201104/201104061617031989.png) ]。
]。
對於每一個樣例i,讓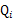 表示該樣例隱含變數z的某種分佈(這裡隱含變數z的分佈概率是未知的),
表示該樣例隱含變數z的某種分佈(這裡隱含變數z的分佈概率是未知的),![clip_image032[1]](http://images.cnblogs.com/cnblogs_com/jerrylead/201104/201104061616025060.png) 滿足的條件是
滿足的條件是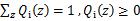 。(如果z是連續性的,那麼
。(如果z是連續性的,那麼![clip_image032[2]](http://images.cnblogs.com/cnblogs_com/jerrylead/201104/201104061616041321.png) 是概率密度函式,需要將求和符號換做積分符號)。比如要將班上學生聚類,假設隱藏變數z是身高,那麼就是連續的高斯分佈。如果按照隱藏變數是男女,那麼就是伯努利分佈了。
是概率密度函式,需要將求和符號換做積分符號)。比如要將班上學生聚類,假設隱藏變數z是身高,那麼就是連續的高斯分佈。如果按照隱藏變數是男女,那麼就是伯努利分佈了。
建立![clip_image028[5]](http://images.cnblogs.com/cnblogs_com/jerrylead/201104/20110406161629375.png) 的下界(E步)
的下界(E步)
![clip_image028[5]](http://images.cnblogs.com/cnblogs_com/jerrylead/201104/20110406161628865.png)
可以由前面闡述的內容得到下面的公式:

上述公式推導:
(1)到(2)比較直接,就是分子分母同乘以一個相等的函式。(2)到(3)利用了Jensen不等式,考慮到是凹函式(二階導數小於0),而且
 就是
就是 (Zi的函式)的期望
(Zi的函式)的期望
|
Lazy Statistician規則: 設Y是隨機變數X的函式 (1) X是離散型隨機變數,它的分佈律為 (2) X是連續型隨機變數,它的概率密度為 |







對應於上述問題,Y是![clip_image039[1]](http://images.cnblogs.com/cnblogs_com/jerrylead/201104/201104061616122703.png) ,X是
,X是 ,
, 是
是 ,g是
,g是![clip_image055[1]](http://images.cnblogs.com/cnblogs_com/jerrylead/201104/201104061616155575.png) 到
到![clip_image039[2]](http://images.cnblogs.com/cnblogs_com/jerrylead/201104/201104061616164561.png) 的對映。這樣解釋了式子(2)中的期望
的對映。這樣解釋了式子(2)中的期望
根據凹函式時的Jensen不等式:
 可以得到(3)。
可以得到(3)。
對於![clip_image032[3]](http://images.cnblogs.com/cnblogs_com/jerrylead/201104/201104061616196777.png) 的選擇,有多種可能,那種更好的?
的選擇,有多種可能,那種更好的?
假設![clip_image026[1]](http://images.cnblogs.com/cnblogs_com/jerrylead/201104/201104061616198512.png) 已經給定,那麼
已經給定,那麼![clip_image028[2]](http://images.cnblogs.com/cnblogs_com/jerrylead/201104/201104061616205023.png) 的值就決定於
的值就決定於![clip_image057[1]](http://images.cnblogs.com/cnblogs_com/jerrylead/201104/201104061616218677.png) 和
和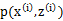 了。我們可以通過調整這兩個概率使下界不斷上升,以逼近
了。我們可以通過調整這兩個概率使下界不斷上升,以逼近![clip_image028[3]](http://images.cnblogs.com/cnblogs_com/jerrylead/201104/201104061616223237.png) 的真實值,那麼什麼時候算是調整好了呢?當不等式變成等式時,說明我們調整後的概率能夠等價於
的真實值,那麼什麼時候算是調整好了呢?當不等式變成等式時,說明我們調整後的概率能夠等價於![clip_image028[4]](http://images.cnblogs.com/cnblogs_com/jerrylead/201104/201104061616235844.png) 了。按照這個思路,我們要找到等式成立的條件。根據Jensen不等式,要想讓等式成立,需要讓隨機變數變成常數值,這裡得到:
了。按照這個思路,我們要找到等式成立的條件。根據Jensen不等式,要想讓等式成立,需要讓隨機變數變成常數值,這裡得到:
 ,c為常數,不依賴於
,c為常數,不依賴於 。對此式子做進一步推導,我們知道
。對此式子做進一步推導,我們知道 ,那麼也就有
,那麼也就有 ,那麼有下式:
,那麼有下式:

至此,我們推出了在固定其他引數![clip_image026[2]](http://images.cnblogs.com/cnblogs_com/jerrylead/201104/201104061616278192.png) 後,
後, 的計算公式就是後驗概率{裡面主要包含要求的引數,要初始化},解決了
的計算公式就是後驗概率{裡面主要包含要求的引數,要初始化},解決了![clip_image072[1]](http://images.cnblogs.com/cnblogs_com/jerrylead/201104/201104061616282751.png) 如何選擇的問題(保證了在給定
如何選擇的問題(保證了在給定![clip_image077[2]](http://images.cnblogs.com/cnblogs_com/jerrylead/201104/201104061616375104.png) 時,Jensen不等式中的等式成立,取得下界)。
時,Jensen不等式中的等式成立,取得下界)。
優化下界(M步)
接下來的M步,就是在給定![clip_image072[2]](http://images.cnblogs.com/cnblogs_com/jerrylead/201104/201104061616295391.png) 後,調整
後,調整![clip_image026[3]](http://images.cnblogs.com/cnblogs_com/jerrylead/201104/201104061616305457.png) ,去極大化
,去極大化![clip_image028[6]](http://images.cnblogs.com/cnblogs_com/jerrylead/201104/201104061616311096.png) 的下界(在固定
的下界(在固定![clip_image072[3]](http://images.cnblogs.com/cnblogs_com/jerrylead/201104/201104061616317259.png) 後,下界還可以調整的更大)。
後,下界還可以調整的更大)。
EM演算法的步驟
Note: 通過男女混合高斯模型來記!
|
初始化分佈引數θ; 迴圈重複直到收斂 { (E步)對於每一個i,計算 #E步驟:根據引數初始值或上一次迭代的模型引數來計算出隱性變數的後驗概率,其實就是隱性變數的期望。作為隱藏變數的現估計值: (M步)計算 #將似然函式最大化以獲得新的引數值(log式中分母可省略) |



那麼究竟怎麼確保EM收斂?
假定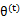 和
和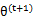 是EM第t次和t+1次迭代後的結果。
是EM第t次和t+1次迭代後的結果。
如果我們證明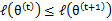 ,也就是說極大似然估計單調增加,那麼最終我們會到達最大似然估計的最大值。下面來證明,選定
,也就是說極大似然估計單調增加,那麼最終我們會到達最大似然估計的最大值。下面來證明,選定![clip_image077[1]](http://images.cnblogs.com/cnblogs_com/jerrylead/201104/201104061616354100.png) 後,我們得到E步
後,我們得到E步
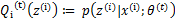
這一步保證了在給定時,Jensen不等式中的等式成立,也就是
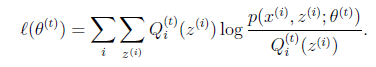
然後進行M步,固定 ,並將
,並將 視作變數,對上面的
視作變數,對上面的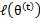 求導後,得到
求導後,得到 ,這樣經過一些推導會有以下式子成立:
,這樣經過一些推導會有以下式子成立:
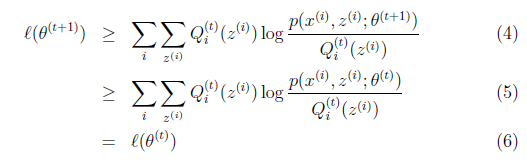
解釋第(4)步,得到![clip_image092[1]](http://images.cnblogs.com/cnblogs_com/jerrylead/201104/201104061616447467.png) 時,只是最大化
時,只是最大化![clip_image090[1]](http://images.cnblogs.com/cnblogs_com/jerrylead/201104/201104061616441993.png) ,也就是
,也就是 的下界,而沒有使等式成立,等式成立只有是在固定
的下界,而沒有使等式成立,等式成立只有是在固定![clip_image026[4]](http://images.cnblogs.com/cnblogs_com/jerrylead/201104/201104061616458504.png) ,並按E步得到
,並按E步得到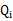 時才能成立。
時才能成立。
況且根據我們前面得到的下式,對於所有的![clip_image097[1]](http://images.cnblogs.com/cnblogs_com/jerrylead/201104/201104061616477830.png) 和
和![clip_image026[5]](http://images.cnblogs.com/cnblogs_com/jerrylead/201104/201104061616486293.png) 都成立
都成立
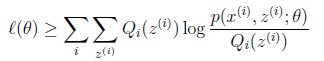
第(5)步利用了M步的定義,M步就是將![clip_image088[1]](http://images.cnblogs.com/cnblogs_com/jerrylead/201104/2011040616164946.png) 調整到
調整到 ,使得下界最大化。因此(5)成立。(自證明?)
,使得下界最大化。因此(5)成立。(自證明?)
(6)是之前的等式結果
這樣就證明了 會單調增加。一種收斂方法是
會單調增加。一種收斂方法是![clip_image102[1]](http://images.cnblogs.com/cnblogs_com/jerrylead/201104/20110406161652900.png) 不再變化,還有一種就是變化幅度很小。
不再變化,還有一種就是變化幅度很小。
再次解釋一下(4)、(5)、(6)。首先(4)對所有的引數都滿足,而其等式成立條件只是在固定![clip_image026[6]](http://images.cnblogs.com/cnblogs_com/jerrylead/201104/201104061616535459.png) ,並調整好Q時成立,而第(4)步只是固定Q,調整
,並調整好Q時成立,而第(4)步只是固定Q,調整![clip_image026[7]](http://images.cnblogs.com/cnblogs_com/jerrylead/201104/201104061616559179.png) ,不能保證等式一定成立。(4)到(5)就是M步的定義,(5)到(6)是前面E步所保證等式成立條件。也就是說E步會將下界拉到與
,不能保證等式一定成立。(4)到(5)就是M步的定義,(5)到(6)是前面E步所保證等式成立條件。也就是說E步會將下界拉到與![clip_image102[2]](http://images.cnblogs.com/cnblogs_com/jerrylead/201104/201104061616566803.png) 一個特定值(這裡
一個特定值(這裡![clip_image088[2]](http://images.cnblogs.com/cnblogs_com/jerrylead/201104/201104061616575266.png) )一樣的高度,而此時發現下界仍然可以上升,因此經過M步後,下界又被拉昇,但達不到與
)一樣的高度,而此時發現下界仍然可以上升,因此經過M步後,下界又被拉昇,但達不到與![clip_image102[3]](http://images.cnblogs.com/cnblogs_com/jerrylead/201104/201104061616588953.png) 另外一個特定值一樣的高度,之後E步又將下界拉到與這個特定值一樣的高度,重複下去,直到最大值。
另外一個特定值一樣的高度,之後E步又將下界拉到與這個特定值一樣的高度,重複下去,直到最大值。
如果我們定義
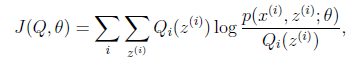
從前面的推導中我們知道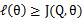 ,EM可以看作是J的座標上升法,E步固定,優化,M步固定優化。
,EM可以看作是J的座標上升法,E步固定,優化,M步固定優化。
重新審視混合高斯模型
我們已經知道了EM的精髓和推導過程,再次審視一下混合高斯模型。之前提到的混合高斯模型的引數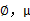 和
和 計算公式都是根據很多假定得出的,有些沒有說明來由。為了簡單,這裡在M步只給出
計算公式都是根據很多假定得出的,有些沒有說明來由。為了簡單,這裡在M步只給出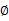 和
和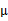 的推導方法。
的推導方法。
E步很簡單,按照一般EM公式得到:
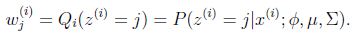
簡單解釋就是每個樣例i的隱含類別![clip_image055[2]](http://images.cnblogs.com/cnblogs_com/jerrylead/201104/201104061617082551.png) 為j的概率可以通過後驗概率計算得到。
為j的概率可以通過後驗概率計算得到。
在M步中,我們需要在固定![clip_image072[4]](http://images.cnblogs.com/cnblogs_com/jerrylead/201104/201104061617097077.png) 後最大化最大似然估計,也就是
後最大化最大似然估計,也就是

這是將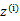 的k種情況展開後的樣子,未知引數
的k種情況展開後的樣子,未知引數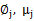 和
和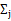 。
。
固定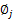 和
和 ,對
,對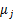 求導得
求導得

等於0時,得到之前模型中的![clip_image115[1]](http://images.cnblogs.com/cnblogs_com/jerrylead/201104/201104061617195658.png) 的更新公式
的更新公式
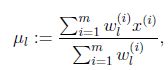
然後推導![clip_image126[1]](http://images.cnblogs.com/cnblogs_com/jerrylead/201104/201104061617202169.png) 的更新公式。看之前得到的
的更新公式。看之前得到的
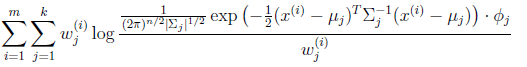
在![clip_image113[1]](http://images.cnblogs.com/cnblogs_com/jerrylead/201104/201104061617228987.png) 和
和![clip_image115[2]](http://images.cnblogs.com/cnblogs_com/jerrylead/201104/201104061617227450.png) 確定後,分子上面的一串都是常數了,實際上需要優化的公式是:
確定後,分子上面的一串都是常數了,實際上需要優化的公式是:
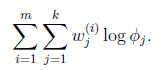
需要知道的是,![clip_image126[2]](http://images.cnblogs.com/cnblogs_com/jerrylead/201104/20110406161724647.png) 還需要滿足一定的約束條件就是
還需要滿足一定的約束條件就是 。
。
這個優化問題我們很熟悉了,直接構造拉格朗日乘子。
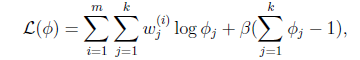
還有一點就是 ,但這一點會在得到的公式裡自動滿足。
,但這一點會在得到的公式裡自動滿足。
求導得,
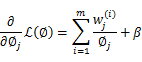
等於0,得到

也就是說 再次使用
再次使用![clip_image136[1]](http://images.cnblogs.com/cnblogs_com/jerrylead/201104/201104061617289091.png) ,得到
,得到
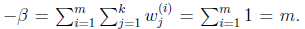
這樣就神奇地得到了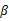 。
。
那麼就順勢得到M步中![clip_image126[3]](http://images.cnblogs.com/cnblogs_com/jerrylead/201104/201104061617306257.png) 的更新公式:
的更新公式:
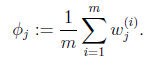
![clip_image111[1]](http://images.cnblogs.com/cnblogs_com/jerrylead/201104/201104061617314994.png) 的推導也類似,不過稍微複雜一些,畢竟是矩陣。結果在之前的混合高斯模型中已經給出。
的推導也類似,不過稍微複雜一些,畢竟是矩陣。結果在之前的混合高斯模型中已經給出。
總結
如果將樣本看作觀察值,潛在類別看作是隱藏變數,那麼聚類問題也就是引數估計問題,只不過聚類問題中引數分為隱含類別變數和其他引數,這猶如在x-y座標系中找一個曲線的極值,然而曲線函式不能直接求導,因此什麼梯度下降方法就不適用了。但固定一個變數後,另外一個可以通過求導得到,因此可以使用座標上升法,一次固定一個變數,對另外的求極值,最後逐步逼近極值。對應到EM上,E步估計隱含變數,M步估計其他引數,交替將極值推向最大。EM中還有“硬”指定和“軟”指定的概念,“軟”指定看似更為合理,但計算量要大,“硬”指定在某些場合如K-means中更為實用(要是保持一個樣本點到其他所有中心的概率,就會很麻煩)。
另外,EM的收斂性證明方法確實很牛,能夠利用log的凹函式性質,還能夠想到利用創造下界,拉平函式下界,優化下界的方法來逐步逼近極大值。而且每一步迭代都能保證是單調的。最重要的是證明的數學公式非常精妙,硬是分子分母都乘以z的概率變成期望來套上Jensen不等式。
EM演算法另一種理解
座標上升法(Coordinate ascent):

圖中的直線式迭代優化的路徑,可以看到每一步都會向最優值前進一步,而且前進路線是平行於座標軸的,因為每一步只優化一個變數。
這猶如在x-y座標系中找一個曲線的極值,然而曲線函式不能直接求導,因此什麼梯度下降方法就不適用了。但固定一個變數後,另外一個可以通過求導得到,因此可以使用座標上升法,一次固定一個變數,對另外的求極值,最後逐步逼近極值。對應到EM上,E步:固定θ,優化Q;M步:固定Q,優化θ;交替將極值推向最大。
lz NG的協同過濾引數更新演算法也有類似EM的演算法,再研究。
ref:http://www.cnblogs.com/jerrylead/archive/2011/04/06/2006936.html
Tom Mitchell的Machine Learning書
M. Bishop - PatternRecognitionAndMachineLearning: EM演算法原理