
遊戲與常用的五大演算法---上篇
前言:
什麼時候,我們之間竟然變得這麼生疏
什麼時候,我想見到你,卻又害怕見到你
什麼時候,才能在我身邊,告訴我。其實,你一直都在
-----------《仙劍奇俠傳》
PS:為了方便大家閱讀,個人認為比較重要的內容-------紅色字型顯示
---------------------------------------------------------------------------
-----------------------------------------------分-割-線--------------------------------------------
最近感覺好忙啊,不過每天也都過得很充實,希望這樣保持下去,一直到畢業。好久沒有提筆寫部落格了,盡然已經有半個月之多了,不過今天來討論一下游戲與演算法,主要準備從常用的五大演算法入手,順便討論一下,遊戲與演算法之間的關係。其實遊戲與演算法真的密不可分!如果沒有了這些演算法,那麼遊戲幾乎就無法運作,加上本身遊戲對於效能的要求就很高,所以一款遊戲的遊戲必然要求有讓人拍案叫絕的演算法!演算法之一:分治演算法
一、什麼是分治演算法
首先來說一說什麼是分治法,“分治”二字顧名思義,就是“分而治之”的意思,說的通俗一點就是步步為營,各個擊破,再來解釋分而治之的意思,其實也就是把一個問題(一般來說這個問題都是比較複雜的)分成兩個相同或者相似的子問題,再把子問題分成更小的問題,一直這樣下去.......直到最後,子問題可以簡單地求解,還有一點就是把所有求得的子問題合併就是原問題的解。其實在很多場合下都會使用到分治演算法,比如說我們常用的歸併排序、快速排序都是很常見的分治思想的體現。
二、核心思想
說完了分治演算法的概念,我們就該談一談分治演算法的思想及策略
分治法的思想:將一個難以直接解決的大問題,分解成規模較小的相同問題,接下來就是剛剛說的八個字:步步為營、各個擊破。
怎麼樣才能達到這種狀態呢?我們需要用什麼方法呢?首先假設遇到一個規模為n的問題,若該問題可以容易地解決(比如說規模n較小)則直接解決。不過有時候卻沒有很好地思路去解,這時候如果你發現如果n取得比較小的情況下,很容易解決,那麼我們就應該將其分解為k個規模較小的子問題,這些子問題互相獨立且與原問題形式相同,遞迴地解這些子問題,然後將各子問題的解合併得到原問題的解。
不過在使用的時候還要多說幾句:
假設我們遇到一個規模為n的問題,這個問題可分割成k個子問題,1<k≤n,且這些子問題都可解並可利用這些子問題的解求出原問題的解,那麼這種分治法就是可行的。由分治法產生的子問題往往是原問題的較小模式,這就為使用遞迴技術提供了方便。在這種情況下,反覆應用分治手段,可以使子問題與原問題型別一致而其規模卻不斷縮小,最終使子問題縮小到很容易直接求出其解。這自然導致遞迴過程的產生。分治與遞迴像一對孿生兄弟,經常同時應用在演算法設計之中,並由此產生許多高效演算法
三、分治演算法的適用場景
知道了分治演算法的原理,接下來的自然是歸結到一個“用”字上面,怎麼使用呢?要使用之前肯定要知道什麼樣的條件下可以使用或者說是適合使用分治演算法。
1) 該問題的規模縮小到一定的程度就可以容易地解決
2) 該問題可以分解為若干個規模較小的相同問題,即該問題具有最優子結構性質。
3) 利用該問題分解出的子問題的解可以合併為該問題的解;
4) 該問題所分解出的各個子問題是相互獨立的,即子問題之間不包含公共的子子問題。
需要注意的是:第一條特徵是絕大多數問題都可以滿足的,因為問題的計算複雜性一般是隨著問題規模的增加而增加,所以說第一條不能作為重要的依據。
第二條特徵是應用分治法的前提它也是大多數問題可以滿足的,此特徵反映了遞迴思想的應用;、
第三條特徵是關鍵,能否利用分治法完全取決於問題是否具有第三條特徵,如果具備了第一條和第二條特徵,而不具備第三條特徵,則可以考慮用貪心法或動態規劃法。
第四條特徵涉及到分治法的效率,如果各子問題是不獨立的則分治法要做許多不必要的工作,重複地解公共的子問題,此時雖然可用分治法,但一般用動態規劃法較好。
四、實際運用
具體到實際運用的過程之中,歸結到到遊戲上面的話,其實用的還是挺常見的。最常見的就是在RGP遊戲之中,主角會經常獲得道具,有時候我們會想給這些道具按個數的多少拍個序,那麼最常見的做法就是按一下數量這個按鈕。按下之後就會給這些道具內容進行排序了!一般來說快排是用的最多的,但是歸併也很常見,恰好這兩者都是分治演算法的體現。
總結一下在實際過程之中怎麼運用,以下三步是分治思想的慣用套路
//---------------------------歸併排序之中問題增大時候的求解方法---------------------------------
void Merge(int sourceArr[], int tempArr[], int startIndex, int midIndex, int endIndex)
{
int i = startIndex, j = midIndex + 1, k = startIndex;
while (i != midIndex + 1 && j != endIndex + 1)
{
if (sourceArr[i] >= sourceArr[j])
tempArr[k++] = sourceArr[j++];
else
tempArr[k++] = sourceArr[i++];
}
while (i != midIndex + 1)
tempArr[k++] = sourceArr[i++];
while (j != endIndex + 1)
tempArr[k++] = sourceArr[j++];
for (int index = startIndex; index <= endIndex; ++index)
sourceArr[index] = tempArr[index];
}
//---------------------------------歸併排序劃分為子問題------------------------------------------
void MergeSort1(int sourceArr[], int tempArr[], int startIndex, int endIndex) //內部遞迴使用
{
int midIndex = 0;
if (startIndex < endIndex)
{
midIndex = startIndex + (endIndex - startIndex) / 2;
MergeSort1(sourceArr, tempArr, startIndex, midIndex);
MergeSort1(sourceArr, tempArr, midIndex + 1, endIndex);
Merge(sourceArr, tempArr, startIndex, midIndex, endIndex);
}
}
//----------------------------------------優化方法---------------------------------------------
void MergeSort2(int sourceArr[], int tempArr[], int startIndex, int endIndex)
{
int midIndex = 0;
if ((endIndex - startIndex) >= 50) // 大於50個數據的陣列進行歸併排序
{
midIndex = startIndex + (endIndex - startIndex) / 2;
MergeSort2(sourceArr, tempArr, startIndex, midIndex);
MergeSort2(sourceArr, tempArr, midIndex + 1, endIndex);
Merge(sourceArr, tempArr, startIndex, midIndex, endIndex);
}
else // 小於50個數據的陣列進行插入排序
InsertSort(sourceArr + startIndex, endIndex - startIndex + 1);
}</span></span></font>來看一看優化與不優化兩者時間實驗結果比較:

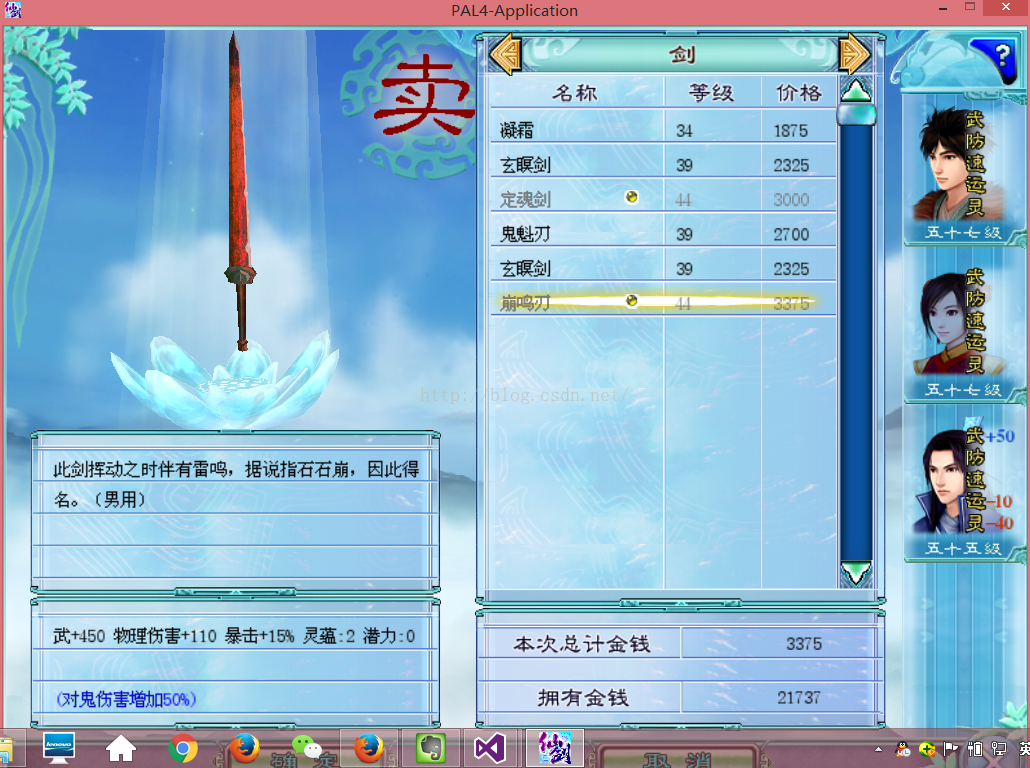
最後再來看一看遊戲之中排序的應用(一般是歸併排序或者是快速排序)吧,一般來說歸併排序在檔案的排序用的比較多,而快速排序在大多數情況都適用,如下圖所示(圖為《仙劍四》買物品的場景,遊戲確實有點老了,而且仙劍六都已經出了,仙劍七也正在開發過程之中,但是個人還是認為仙劍四和五前最為經典,所以電腦上一直保留著,自己希望能多多研究這樣的經典遊戲),對於物品的選擇,如果我們物品很多,但是你希望按價格高低排序看一看的,這時候排序就派上用場了,點一下價格,就會按照價格降序排列!
演算法之二:動態規劃演算法
一、什麼是動態規劃
關於什麼是動態規劃呢?用通俗一點的話來說就是“邊走邊看”,注意和回溯法這種先把一條道走到黑的方法區別開來,總的來說就是前面的知道了,後面的也可以根據前面的推匯出來了。好了通俗的話說到這了,下面用正規一點的語言總結一下:每次決策依賴於當前狀態,又隨即引起狀態的轉移。一個決策序列就是在變化的狀態中產生出來的,所以,這種多階段最優化決策解決問題的過程就稱為動態規劃。
二、核心思想
其實在剛開始接觸的時候,很容易把動態規劃與分治演算法混在一起,不過這兩者還真的有些類似,也是將待求解的問題分解為若干個子問題(階段),按順序求解子階段。不過動態規劃之中前一子問題的解,為後一子問題的求解提供了有用的資訊。在求解任一子問題時,列出各種可能的區域性解,通過決策保留那些有可能達到最優的區域性解,丟棄其他區域性解。依次解決各子問題,最後一個子問題就是初始問題的解。
由於動態規劃解決的問題多數有重疊子問題這個特點,為減少重複計算,對每一個子問題只解一次,將其不同階段的不同狀態儲存在一個二維陣列中。
與分治法最大的差別是:適合於用動態規劃法求解的問題,經分解後得到的子問題往往不是互相獨立的(即下一個子階段的求解是建立在上一個子階段的解的基礎上,進行進一步的求解),但是分治法不同,分治法一般最後才把這些子問題合併,但是在這之前他們是互不干擾的,所以分治法只要一直往下劃分即可。
三、動態規劃的適用場景
動態規劃適用的場景還是挺多的,而且什麼筆試的時候也很喜歡考,這樣的題目都有一個特點,就是如果你知道要使用動態規劃區解這個題,那麼做起來回很方便,很快速,程式碼量不多,但卻很考驗思維。這也是為什麼動態規劃出現地比較多的原因,甚至在一些什麼ACM大賽上,動態規劃也是一個易考點。
高中裡我們都學過線性規劃,使用來求最優解的方法,動態規劃與它也有點類似,所以說動態規劃本質上來說還是規劃,是不斷進行決策的問題,一般用於求解最(優)值;而分治是一種處理複雜問題的方法,不僅僅只用於解決最值問題(而且我們一般也不用它來求最值,你想一串數字如果特別多,你想找一個最大的出來,用了一個排序是不是有一點奢侈呢,比較遊戲與效率要求真的很高)。
所以如果能用動態規劃來解決的問題,通常要滿足以下三點要求:
(1)最優化原理:如果問題的最優解所包含的子問題的解也是最優的,就稱該問題具有最優子結構,即滿足最優化原理。
(2)無後效性:即某階段狀態一旦確定,就不受這個狀態以後決策的影響。也就是說,某狀態以後的過程不會影響以前的狀態,只與當前狀態有關。
(3)有重疊子問題:即子問題之間是不獨立的,一個子問題在下一階段決策中可能被多次使用到。(該性質並不是動態規劃適用的必要條件,但是如果沒有這條性質,動態規劃演算法同其他演算法相比就不具備優勢)
四、實際運用
前面說了這麼多,還是得歸結到一個"用"字上面,什麼情況下適用呢?具體到遊戲上又應該用在什麼什麼上面呢?先來說一說怎麼用吧!這裡我用一下我之前看到的一段總結的比較好的話來說明一下怎麼動態規劃怎麼使用!
動態規劃所處理的問題是一個多階段決策問題,一般由初始狀態開始,通過對中間階段決策的選擇,達到結束狀態。這些決策形成了一個決策序列,同時確定了完成整個過程的一條活動路線(通常是求最優的活動路線)。動態規劃的設計都有著一定的模式,一般要經歷以下幾個步驟。
初始狀態→│決策1│→│決策2│→…→│決策n│→結束狀態
動態規劃決策過程示意圖
(1)劃分階段:按照問題的時間或空間特徵,把問題分為若干個階段。在劃分階段時,注意劃分後的階段一定要是有序的或者是可排序的,否則問題就無法求解。
(2)確定狀態和狀態變數:將問題發展到各個階段時所處於的各種客觀情況用不同的狀態表示出來。當然,狀態的選擇要滿足無後效性。
(3)確定決策並寫出狀態轉移方程:因為決策和狀態轉移有著天然的聯絡,狀態轉移就是根據上一階段的狀態和決策來匯出本階段的狀態。所以如果確定了決策,狀態轉移方程也就可寫出。但事實上常常是反過來做,根據相鄰兩個階段的狀態之間的關係來確定決策方法和狀態轉移方程。
(4)尋找邊界條件:給出的狀態轉移方程是一個遞推式,需要一個遞推的終止條件或邊界條件。
一般,只要解決問題的階段、狀態和狀態轉移決策確定了,就可以寫出狀態轉移方程(包括邊界條件)。
實際應用中可以按以下幾個簡化的步驟進行設計:
(1)分析最優解的性質,並刻畫其結構特徵。
(2)遞迴的定義最優解。
(3)以自底向上或自頂向下的記憶化方式(備忘錄法)計算出最優值,一般我們可以把需要記憶的內容放在一個全域性變數或者一個多維陣列之中。
(4)根據計算最優值時得到的資訊,構造問題的最優解。
不過在具體地操作過程之中還是有幾點需要說明一下的:
動態規劃的主要難點在於理論上的設計,也就是上面4個步驟的確定,一旦設計完成,實現部分就會非常簡單。
使用動態規劃求解問題,最重要的就是確定動態規劃三要素:
(1)問題的階段 (2)每個階段的狀態 (3)從前一個階段轉化到後一個階段之間的遞推關係。
遞推關係必須是從次小的問題開始到較大的問題之間的轉化,從這個角度來說,動態規劃往往可以用遞迴程式來實現,不過因為遞推可以充分利用前面儲存的子問題的解來減少重複計算,所以對於大規模問題來說,有遞迴不可比擬的優勢,這也是動態規劃演算法的核心之處。
確定了動態規劃的這三要素,整個求解過程就可以用一個最優決策表來描述,最優決策表是一個二維表,其中行表示決策的階段,列表示問題狀態,表格需要填寫的資料一般對應此問題的在某個階段某個狀態下的最優值(如最短路徑,最長公共子序列,最大價值等),填表的過程就是根據遞推關係,從1行1列開始,以行或者列優先的順序,依次填寫表格,最後根據整個表格的資料通過簡單的取捨或者運算求得問題的最優解。
f(n,m)=max{f(n-1,m), f(n-1,m-w[n])+P(n,m)}
網上看到一個通用的動態規劃演算法的通用架子,如下: for(j=1; j<=m; j=j+1) // 第一個階段
xn[j] = 初始值;
for(i=n-1; i>=1; i=i-1)// 其他n-1個階段
for(j=1; j>=f(i); j=j+1)//f(i)與i有關的表示式
xi[j]=j=max(或min){g(xi-1[j1:j2]), ......, g(xi-1[jk:jk+1])};
t = g(x1[j1:j2]); // 由子問題的最優解求解整個問題的最優解的方案
print(x1[j1]);
for(i=2; i<=n-1; i=i+1)
{
t = t-xi-1[ji];
for(j=1; j>=f(i); j=j+1)
if(t=xi[ji])
break;
} 基本用法介紹完了,我們可以來看一看使用動態規劃的典型例子,首先就是典型的問題:揹包問題。揹包問題在我看來就是使用有限的資源,儘可能的創造出更多的價值。揹包問題原題是給定n種物品和一揹包。物品i的重量是wi,其價值為vi,揹包的容量為C。問應如何選擇裝入揹包的物品,使得裝入揹包中物品的總價值最大?
接下來我們先把揹包問題解決了,然後在說一說在遊戲之中揹包問題引出的動態規劃思想的體現。
先給出一個具體地揹包問題,題目如下:
有編號分別為a,b,c,d,e的五件物品,它們的重量分別是2,2,6,5,4,它們的價值分別是6,3,5,4,6,現在給你個承重為10的揹包,如何讓揹包裡裝入的物品具有最大的價值總和?
一看到最大最小值的問題,我們首先應該想一想是否可以使用動態規劃解決這個問題呢?一般來說求最值問題,最常用的或者說是最先想到的就應該是動態規劃。之前通過上面的分析,我們對於揹包問題應該有了一定地思路,不過就是寫程式碼的問題了,關於這道題目的分析過程,這裡給出一個連結地址:點這裡
上面給出的連結文章之中對於揹包問題進行了很好的分析,所以有需要的可以點進去看一下,不過個人感覺他的程式碼給出的解釋太少,所以自己寫了一個,大家可以參考參考。
//--------------------------------------------揹包問題------------------------------------------
const int Bag_Capacity = 10; //揹包的總容量
const int Weight[] = { 0, 2, 2, 6, 5, 4 }; //用於存放物品重量的陣列,其中0號位置沒有用到,只是為了方便而已
const int Value[] = { 0, 6, 3, 5, 4, 6 }; //用於存放物品價值的陣列,同樣的0號位置沒有用到
const int nCount = sizeof(Weight) / sizeof(Weight[0]) - 1;//物品的總個數
int GoodList[nCount + 1]; //物品的存在序列(1表示存在,0表示不存在)
void Package(int mor[][11], const int Wei[], const int Val[], const int size)
{
//通常來說揹包問題採用自底向上的方式解決比較好,所以我們假定先放的是最後一個物品,也就是Wei[size]
//通過自底向上的方式來設定mor這個陣列比較好
//首先進行引數檢測
if (NULL == mor || NULL == Wei || NULL == Val)
return;
//在放入第一個元素,也就是Wei[n]
for (int index = 0; index <= Bag_Capacity; ++index)
{
//判斷是否可以放揹包,index從0到揹包的最大容量,可以理解為index是一個試探變數
//因為物品重量都是整數,所以一定存在某一個值正好等於物品重量(在物品重量小於揹包重量的前提之下)
//如果比揹包重量大的話,直接不放如,那麼總價值為0(放第一個物品)
if (index < Wei[size])
mor[size][index] = 0;
else
mor[size][index] = Val[size];
}
//接下來就是動態規劃的體現,對剩下的n-1個物品放入,也就是填充mor陣列
for (int row = size - 1; row >= 0; --row)
{
for (int col = 0; col <= Bag_Capacity; ++col)
{
if (col < Wei[row]) //這裡保持和下面一樣就可以了
mor[row][col] = mor[row + 1][col];
else //這裡需要理解一下
{
mor[row][col] = mor[row + 1][col] > mor[row + 1][col - Wei[row]] + Val[row] ?
mor[row + 1][col] : mor[row + 1][col - Wei[row]] + Val[row];
}
}
}
}
void GetList(int mor[][11], const int size)
{
//現在的目的就是為了得到了一個序列,關於物品是否存在的序列
int index = Bag_Capacity;
int i = 0;
for (i = 1; i <= size - 1; ++i) //判斷前n-1個物品是存在
{
if (mor[i][index] == mor[i + 1][index])
GoodList[i] = 0;
else
{
GoodList[i] = 1;
index = index - Weight[i];
}
}
//對於最後一個問題,那麼只需要判斷相應位置是否為0即可
GoodList[i] = mor[i][index] ? 1 : 0;
}
int main()
{
int Memory[6][11] = { 0 };
Package(Memory, Weight, Value, nCount);
//先把整個過程打印出來
for (int row = 1; row <= nCount; ++row)
{
for (int col = 0; col <= Bag_Capacity; ++col)
printf("%4d", Memory[row][col]); //使用printf在這裡比較方便指定行寬
cout << endl;
}
GetList(Memory, nCount);
cout << "最優解為:" << endl;
for (int idx = 1; idx <= nCount; ++idx)
cout << GoodList[idx];
cout << endl;
return 0;
}</span></span></span> 還有一個感覺可能符合的是今年寒假期間剛剛發行的《三國志13》,裡面採用了與《三國志12》完全不同的畫風,感覺是大地圖上巨集偉了很多,來看一張截圖:

從上圖我們可以看到,這一代玩家可以扮演任意一個角色,而且可以去執行任務。但是需要錢,不同的人執行所需要的金錢也是不同的(同智力成反比),智力越高,所花的金錢越少,所以說這裡就需要AI選擇了。怎麼樣花最少的金錢,獲得最大的發展。智力就相當於我們上面揹包問題裡面的重量,執行人物效果又可以對應於揹包問題之中的價值。從而選擇對於總價值最高的建設方式,儘快提升城市的繁榮程度。個人感覺這一代的AI比上一代的AI明顯會思考了很多,而且發展也快了很多。當然遊戲裡面肯定設計複雜很多,所以說AI的設計真的是一個很大的研究方向,總之應該設計這樣的AI,會簡單模擬人的思考。用最少的資源,儘快建設城市,訓練部隊(這兩者怎麼取捨,這也是一個大問題),而且這些還用到了一些博弈論裡面的知識,所以這裡就不在贅述了!
演算法之三:貪心演算法
一、什麼是貪心演算法
剛剛上面講了動態規劃,接下來講一講貪心演算法。解釋一下貪心演算法,從字面上先解釋一下,所謂貪心就是總是在當前情況下做出最為有利的選擇,也就是說它不從整體上考慮。它只是做出了某種意義上的區域性最優解。
需要說明的一點就是,貪心演算法不像動態規劃那樣有固定的框架,由於貪心演算法沒有固定的演算法框架,因此怎麼樣區分有關於貪心演算法呢?這就需要一種貪心策略了!利用它來區分各種貪心演算法。還有需要說明的就是它與動態規劃最本質的區別就是貪心演算法不是所有情況下都能得到整體最優解,而且往往來說得到的只是一個近似最優解,所以說如果是求最值的問題上,我們一般不用貪心演算法,而是採用動態規劃演算法。
另外,貪心策略的選擇必須滿足無後效性,這是很重要的一點,說的具體一點就是某個狀態以後的過程不會影響以前的狀態,只與當前狀態有關。所以我們在使用貪心演算法的時候一點要看一看是否滿足無後效性。
二、核心思想
第一步:建立數學模型來描述問題。 第二步:把求解的問題分成若干個子問題。 第三步:對每一子問題求解,得到子問題的區域性最優解。 第四步:把子問題的解區域性最優解合成原來解問題的一個解。
三、貪心演算法的適用場景
由於貪心演算法求出來的解並不是最優解,也就註定在某些要求結果精確的情況之中無法使用,有人可能會認為貪心演算法用到的並不多,而且貪心策略的前提就是儘量保證區域性最優解可以產生全域性最優解,最美好的貪心策略當然就是希望能通過不斷地求區域性最優解從而得到全域性最優解!
就拿剛剛的揹包問題來說,顯然使用貪心演算法是無法得出答案的(一般情況下不能,不過也有很小的可能恰好是全域性最優解),因為貪心策略只能從某一個方向考慮,比如單單以重量(每次選擇重量最輕的),或者用價值(每次選擇價值最高的),甚至用價格與重量的比值,其實這三者都實際運用過程之中都有問題,基本很難得到最優解。
一般,對一個問題分析是否適用於貪心演算法,可以先選擇該問題下的幾個實際資料進行分析,就可做出判斷。
不過還是給出使用貪心演算法的一般框架吧:
//從問題的某一初始解出發;
while (能朝給定總目標前進一步)
{
利用可行的決策,求出可行解的一個解元素;
}
//由所有解元素組合成問題的一個可行解;</span></span></span>因為用貪心演算法只能通過解區域性最優解的策略來達到全域性最優解,因此,一定要注意判斷問題是否適合採用貪心演算法策略,找到的解是否一定是問題的最優解。
四、實際運用
因為在實際過程之中我們都希望通過貪心求得最值,所以說在實際之中運用的不是特別多,最小生成樹算是一種。但是在遊戲之中貪心演算法特別常見!因為對於遊戲來說盡可能快求得一個解,從而提高遊戲效能顯得更為重要,哪怕這個解不是最優解,只要他快,而且最好能讓他儘可能的接近最優解的話,那麼這樣的演算法有何嘗不是一種好演算法呢?在遊戲之中貪心演算法用的最普遍的就是尋路。
先引用一段網上關於尋路的一段話:
我們嘗試解決的問題是把一個遊戲物件(game object)從出發點移動到目的地。路徑搜尋(Pathfinding)的目標是找到一條好的路徑——避免障礙物、敵人,並把代價(燃料,時間,距離,裝備,金錢等)最小化。運動(Movement)的目標是找到一條路徑並且沿著它行進。把關注的焦點僅集中於其中的一種方法是可能的。一種極端情況是,當遊戲物件開始移動時,一個老練的路徑搜尋器(pathfinder)外加一個瑣細的運動演算法(movement algorithm)可以找到一條路徑,遊戲物件將會沿著該路徑移動而忽略其它的一切。另一種極端情況是,一個單純的運動系統(movement-only system)將不會搜尋一條路徑(最初的“路徑”將被一條直線取代),取而代之的是在每一個結點處僅採取一個步驟,同時考慮周圍的環境。同時使用路徑搜尋(Pathfinding)和運動演算法(movement algorithm)將會得到最好的效果。
A*尋路演算法
先從背景知識開始吧!在電腦科學中,A*演算法廣泛應用於尋路和圖的遍歷。最早是於1968年,由Peter Hart, Nils Nilsson 和Bertram Raphael3人在斯坦福研究院描述了 該演算法。是對Dijkstra演算法的一種擴充套件。是一種高效的搜尋演算法。
尋路的步驟
總結出下面的尋路六部曲,大家先看看下面這張圖,因為下面的步驟都是基於這兩張圖的(一張是開始的圖,一張是最終找到了的圖)


第一步:從起點A開始, 把它作為待處理的方格存入一個"開啟列表", 開啟列表就是一個等待檢查方格的列表。
第二步:尋找起點A周圍可以到達的方格, 將它們放入"開啟列表", 並設定它們的"父方格"為A。
第三步:從"開啟列表"中刪除起點 A, 並將起點A 加入"關閉列表", "關閉列表"中存放的都是不需要再次檢查的方格

注:圖中淺綠色描邊的方塊表示已經加入"開啟列表" 等待檢查.淡綠色又有點接近淡藍色描邊的起點 A 表示已經放入"關閉列表" , 它不需要再執行檢查
從 "開啟列表" 中找出相對最靠譜的方塊, 什麼是最靠譜? 它們通過公式 F=G+H 來計算,F也叫作啟發函式
F = G + H
G 表示從起點 A 移動到網格上指定方格的移動耗費 (可沿斜方向移動).
H 表示從指定的方格移動到終點 B 的預計耗費 (關於H的取法有很多種,最常見的也是用最多的就是曼哈頓演算法,兩點之間的橫座標之差與縱座標之差的和,需要注意的是用曼哈頓演算法不一定能得到最優路徑 而且如果採用曼哈頓演算法,那麼嚴格意義上來說只能叫A搜尋,不能叫A*搜尋,由於採用這個方法說起來簡單,實現起來也比較簡單,適合初學者,所以本文就採用了曼哈頓演算法。A*本身不限制H使用的估計演算法,如max(dx,dy)、sqrt(dx*dx+dy*dy)、min(dx,dy)*(0.414)+max(dx+dy)這些都可以(可惜曼哈頓演算法dx+dy不在此列),記住一點,只要你能保證H值恆小於實際路徑長,A*就是成立的。你甚至可以取一個常數0,這樣A*就退化為廣搜了)。
我們還是採用曼哈頓演算法來說明吧,因為這樣寫起來方便,就暫時不去區分A演算法與A*演算法了!假設橫向移動一個格子的耗費為10, 為了便於計算, 沿斜方向移動一個格子耗費是14.。為了更直觀的展示如何運算 FGH, 圖中方塊的左上角數字表示 F, 左下角表示 G, 右下角表示 H。
從 "開啟列表" 中選擇 F 值最低的方格 C (綠色起始方塊 A 右邊的方塊), 然後對它進行如下處理:
第四步:把它從 "開啟列表" 中刪除, 並放到 "關閉列表" 中。
第五步: 檢查它所有相鄰並且可以到達 (障礙物和 "關閉列表" 的方格都不考慮) 的方格. 如果這些方格還不在 "開啟列表" 裡的話, 將它們加入 "開啟列表", 計算這些方格的 G,,H 和 F 值各是多少, 並設定它們的 "父方格" 為 C。
第六步: 如果某個相鄰方格 D 已經在 "開啟列表" 裡了, 檢查如果用新的路徑 (就是經過C 的路徑) 到達它的話, G值是否會更低一些,,如果新的G值更低, 那就把它的 "父方格" 改為目前選中的方格 C, 然後重新計算它的 F 值和 G 值 (H 值不需要重新計算, 因為對於每個方塊, H 值是不變的).。如果新的 G 值比較高, 就說明經過 C 再到達 D 不是一個明智的選擇,,因為它需要更遠的路, 這時我們什麼也不做.
上述已構成了一個子問題的求解過程,所以就這樣, 我們每次都從 "開啟列表" 找出 F 值最小的, 將它從 "開啟列表" 中移掉, 新增到 "關閉列表".。再繼續找出它周圍可以到達的方塊,如此迴圈下去...
那麼什麼時候停止呢? —— 當我們發現 "開始列表" 裡出現了目標終點方塊的時候, 說明路徑已經被找到。
最後一個問題就是如何返回路徑呢?
別忘了,我們還儲存了”父節點“呢,最後從目標格開始, 沿著每一格的父節點移動直到回到起始格, 這就是路徑。
最後用一張動態圖作為結束吧!(關於A*演算法的程式碼,後面會補上!)
