
A Curious Course on Coroutines and Concurrency 翻譯
這是David Beazley 在 Pycon 2009 做的講座,下文是初步的翻譯
總體概述
- 協程是什麼?
- 我們可以用協程做什麼?
- 我們應該在意協程嗎?
- 使用協程是否是一個好主意?
圖片概述
頭部爆炸指數圖表, 隨著本文的持續推進, 難度逐漸上升
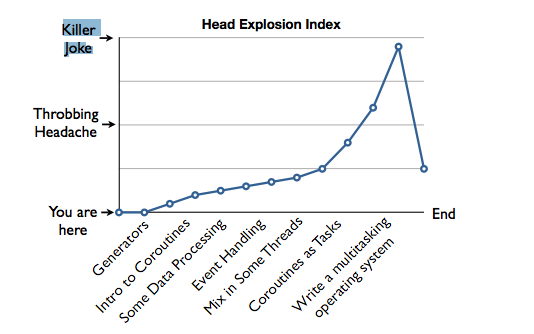
縱軸分別是 起點, 引起頭疼, 開玩笑(基本不可能)
在繼續往下閱讀時必須對生成器和生成器表示式非常熟悉, 關於生成器可以參考作者在08年PyCon 的演講
協程和生成器
- 在 python2.5 版本中, 生成器添加了一些新的功能來支援“協程”
- 其中最特別的是一個send()方法
- 在一些python的入門指南書籍中, 這個部分可能是佔用最少篇幅的一部分,因為它顯然沒有任何用處。。
ohh, 你現在可以將值傳遞給生成器去生成fibonacci數列
def fibonacci(max):
n, a, b = 0, 0, 1
while n < max:
a, b = a + b, a
yield a
n += 1宣告
- 協程, 可能是最晦澀的一種python特性
- 併發, 在電腦科學中最複雜的話題之一
- 這篇文章將兩者混合在一起
進一步宣告
作為一個80年代到90年代的程式設計師, 在python出現協程之前, 我從來沒有用過任何一種其他語言支援協程的
在60年代到70年代,可以隨處可見協程工作的身影, 但是後來 被執行緒和延續性等其他方式逐漸替代
我想知道這裡是否有什麼特殊原因使得python和其他語言重新關注協程?
延續性: 計算續體(continuation)是計算機程式的控制狀態的一種抽象表現。 延續性實化了程式狀態資訊。可以理解為,一個計算續體以資料結構的形式表現了程式在執行過程中某一點的計算狀態,相應的資料內容可以被程式語言訪問,而不是被執行時環境所隱藏掉。這對實現程式語言的某些控制機制,如異常處理、協程、生成器非常有用。
計算續體包含了當前程式的棧(包括當前週期內的所有資料,也就是本地變數),以及當前執行的位置。一個計算續體的例項可以在將來被用做控制流,被呼叫時它從所表達的狀態開始恢復執行。 from wikipedia
更進一步宣告
- 我是一箇中立的第三方
- 我與PEP-342沒有任何關係(PEP 342 – Coroutines via Enhanced Generators)
- 這邊不推薦任何的庫和框架
最後宣告
- 這個不是學術演講
- 沒有現有技術的概括
- 沒有程式語言的理論
- 沒有鎖的相關證明
- 這裡沒有fibonacci
- 實際應用是主要的關注點
part1 生成器和協程的簡介
generator functions
yield produces a value but suspends the function,
Instead of returning a value, it generate a series of values
一個小練習
讓我們寫一個python版本的 ‘tail -f’
see https://github.com/mowangdk/leetcode_question python_related用生成器實現流水執行緒序
- 生成器應用之一就是用來建立處理流水線
- 與Unix的管道非常相似
input_sequence –> generator –> generator –> generator –> for x in s
流水線例子
列印所有的包含‘python’的server-log。
yield 作為一個表示式
在python2.5裡面, 對yield宣告進行了輕微修改, 你現在可以將yield當做表示式來用
def grep(pattern):
print "looking for %s" % pattern
while True
line = (yield)
if pattern in line:
print line協程
如果你更普遍的使用yield, 那麼你就會得到一個協程,協程做的不是生產資料。 相反,方法將會暫停,直到一個新的value send進去。
g = grep("python")
g.next()
Looking for python
g.send("Yeah, but no, but yeah, but no")
g.send("A series of tubes")
g.send("python generators rock")
python generators rocksend進去的value,將由(yield)返回
協程執行
協程執行與生成器相同, 當你呼叫一個協程什麼都不會發生, 它只會返回給你一個result去呼叫next()和send()
g = grep("python") # 注意, 這裡沒有任何的output
g.next()
looking for python協程啟動
所有的協程必須由首次呼叫(.next() or .send(None))來啟動,這個操作將執行協程到第一個(yield)處。這時協程已經隨時準備好接收資料了
使用裝飾器
首次呼叫.next()很容易忘記, 所以我們可以將協程用裝飾器包裝起來
def coroutine(func):
def start(*args, **kwargs):
cr = func(*args, **kwargs)
cr.next()
return cr
return start關閉協程
協程關閉可以被捕捉, 通過(GeneratorExit)
g = grep('python')
g.close()
def grep(pattern):
print "looking for %s" % pattern
try:
while True:
line = (yield)
if pattern in line:
print line
except GeneratorExit:
print "going away . Goodbye"你不能忽略這個異常, 只有清理和返回合理的做法
丟擲異常
異常可以在協程內部被丟擲來
g = grep("python")
g.next()
looking for python
g.send("python generators rock")
python generators rock
g.throw(RuntimeError, "you're hosed")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<stdin>", line 4, in grep
RuntimeError: You're hosed異常會被yield 表示式丟擲, 可以以通常方式處理
小插曲
- 儘管有一些相似之處, 從根本上來說協程和生成器是兩個不同的概念
生成器生成值, 協程一般會消費值
- 很容易被誤解, 因為方法也就是協程,有時候被描述為
一種在迭代中調整生成器的行為方式的方法(例如, 重置value)
def countdown(n):
print "counting down from : {}".format(n)
while n >= 0:
new_value = (yield n)
if new_value is not None:
n = newvalue
else:
n -= 1
c = countdown(5)
for n in c:
print n
if n == 5:
c.send(3)協程並不與迭代相關聯
在協程裡有一種通過yield 生產資料的方式, 但是這個並不依賴於迭代
part2 協程,流水線 和 資料流
處理流水線
- 協程可以用來設定管道
send() -> coroutine -> send()-> coroutine -> send() -> coroutine
你可以將協程連線在一起, 用send()操作通過管道來push 資料
流水線源
- 流水線需要一個初始源(一個生產者)
source -> send() -> coroutine -> send()
def source(target):
while not done:
item = produce_an_item()
...
target.send(item)
...
target.close()
這個生產者通常不是協程
管道接收器
- 流水線一定也會有一個終點(sink)
send() -> coroutine -> send() -> sink
@coroutine
def sink():
try:
while True:
item = (yield)
...
except GeneratorExit:
# Donesource & sink example
我們來模擬unix的 ‘tail -f’ 的source 和 sink
source_follow() -> send() -> sink_follow()
source_follow通過讀檔案中的line,和將line推到sink_follow()中來驅動整個協程
流水線過濾器
- 中間階段既接收資料又傳送資料
send() -> coroutine -> send()
- 這個過程通常執行某種資料轉換,過濾,路由等功能
@coroutine
def filter(target):
while True:
item = (yield)
# transform/filter item
...
# send it along to the next stage
target.send(item)filter example
- 一個 grep 過濾協程
@coroutine
def grep(pattern, target):
while True:
lien = (yield) # receive a line
if pattern in line:
target.send(line) # send to next stage小插曲
- 協程其實是生成器的反轉
generators/iteration
input_sequence -> generator -> generator -> generator -> for x in s
coroutines
source -> send() -> coroutine -> send() -> coroutine
生成器以遍歷的方式通過流水線pull data, 協程以send()方法向流水線push data
分支
- 通過協程, 你可以向不同的目的地傳送資料

source 只是簡單的send資料, 進一步的路由可以是任意複雜的
廣播例子
@coroutine
def broadcast(targets):
while True:
item = (yield)
for target in targets:
target.send(item)
f = open('access-log')
source_follow(f, broadcast([grep('python', sink_follow(),
grep('ply', sink_follow()),
grep('swig', sink_follow())]))
or
sink = sink_follow()
source_follow(f, broadcast([grep('python', sink,
grep('ply', sink),
grep('swig', sink)]))
小插曲
- 協程提供了一種比簡單的迭代器更加強大的資料路由方式
- 如果你建立了一個簡單資料處理集合, 你可以將他們粘合成複雜的管道,分支結構等
- 當然這個有一些限制
協程vs物件
協程某種程度上與面向物件設計模式在呼叫的簡單處理物件的方式比較相似
oo version
class GrepHandler(object):
def __init__(self, pattern, target):
self.pattern = pattern
self.target = target
def send(self, line):
if self.pattern in line:
self.target.send(line)
coroutine
def grep(pattern, target):
while True:
line = (yield)
if pattern in line:
target.send(line)- 協程是一個函式定義
- 如果你定義一個處理類
- 你需要定義一個類
- 需要定義兩個方法
- 或許有一個基類和包引用
協程的方式更加快, 而且寫起來更加簡單
part3 協程和事件分發
處理事件
- 協程可以用來寫各種處理事件流的元件
問題
芝加哥運輸局在它名下的大多數的公交上裝上了gps系統,來實時監控bus的位置,你可以通過一個巨大的xml表來觀察所有巴士的實時資料
我們用sax來解析xml
sax_handler
import xml.sax
class EventHandler(xml.sax.ContentHandler):
def __init__(self, target):
self.target = target
def startElement(self, name, attrs):
self.target.send(('start', (name, attrs._attrs)))
def characters(self, text):
self.target.send(('text', text))
def endElement(self, name):
self.target.send(('end', name))
這個類沒有做任何事情,只是將事件傳送給了target
事件處理(handler)
對event事件流進行處理, 例子, 將bus資料轉換成字典
def buses_to_dicts(target):
while True:
event, value = (yield)
# look for the start of a <bus> element
if event == 'start' and value[0] == 'bus':
busdict = dict()
fragment = list()
# capture text of inner elements in a dict
while True:
event, value = (yield)
if event == 'start':
fragment = list()
elif event == 'text':
fragment.append(value)
elif event == 'end':
if value != 'bus':
busdict[value] = ''.join(fragment)
else:
target.send(busdict)
break上述程式碼是通過實現一個簡單的狀態機來工作的, 協程對這方面的處理是完美的
- 狀態A, 收集,查詢bus資訊
- 狀態B, 收集bus狀態屬性

過濾元素
@coroutine
def filter_on_field(fieldname, value, target):
while True:
d = (yield)
if d.get(fieldname) == value:
target.send(d)
filter_on_field('route', "22", target)處理元素
@coroutine
def bus_locations():
while True:
bus = (yield)
print "%(route)s,%(id)s,\"%(direction)s\","\"%(latitude)s,%(longitude)s" % bus 呼叫
xml.sax.parse('allroutes.xml',
EventHandler(
buses_to_dicts(
filter_on_field('route', "22",
filter_on_field('direction', 'north bound', bus_locations())))))part4 從資料處理到併發程式設計
到現在為止。。
- 協程與生成器十分相似
- 你可以將多個小的功能處理單元連線在一起
- 你可以通過設定管道,資料流等方式來處理資料
- 你可以使用協程來編寫具有棘手的執行方式的程式碼
- 但是,協程還可以做更多的事情
共同的主題
- 你將資料傳送給協程
- 你將資料傳送給執行緒(通過佇列)
- 你將資料傳送給程序(通過訊息傳遞)
- 協程天然的被併入與執行緒和分散式系統相關的問題
基本併發
- 你可以將協程打包進協程中或者將協程封裝到子程序中

@coroutine
def threaded(target):
messages = Queue()
def run_target():
while True:
item = messages.get()
if item is GeneratorExit:
target.close()
return
else:
target.send(item)
Thread(target=run_target).start()
try:
while True:
item = (yield)
message.put(item)
except GeneratorExit:
messages.put(GeneratorExit)- 首先宣告一個訊息佇列
- 之後, 一個執行緒,不斷去輪詢從訊息佇列中拉取資料,並且將拉取到的資料給target
- 從外部獲取資料並且將其推送到執行緒中
- 當外部沒有資料傳進來的時候, 確保程式被正確關閉
xml.sax.parse("allroutes.xml",
EventHandler(
buses_to_dicts(
threaded(
filter_on_field('route', '22',
filter_one_field('direction', 'north bound',
bus_locations())))))注:新加的執行緒使這個例子慢了 50%

使用子程序
@coroutine
def sendto(f):
try:
while True:
item = (yield)
pickle.dump(tiem, f)
f.flush()
except StopIteration:
f.close()
def recvfrom(f, target):
try:
while True:
item = pickle.load(f)
target.send(item)
except EOFError:
target.close()- 這只是大致的實現方式, 細節處有很多坑
- 除非你可以cover底層通訊的成本,否則不會試著使用這種方式的
使用協程你可以將任務的實現和任務的執行環境分離開來
警告
- 建立一個巨大的協程 執行緒和程序的混合體是一種建立不可維護程式碼的好方法
- 它有可能使你的程式變得很慢
- 你需要謹慎的學習這個問題,來判斷使用協程是否值得
一些潛在的危險
- 協程中的send() 方法必須是保持同步的
- 如果你在一個已經執行的協程中呼叫send方法, 那麼這個這個程式就會崩潰掉
多執行緒同時send資料到同一個target中,會引發這種情況
你不能在協程呼叫中建立迴圈

- 堆疊sends() 其實是構建了一種呼叫棧(但是send()並不會返回資料, 直到target yield為止)
- send 不會暫停協程執行
part 5 協程作為任務
任務概念
- 在併發程式設計中, 一個典型的做法是將一個問題細分為幾個“任務”
- 任務有一些必要的特性
- 獨立的控制流
- 有內部狀態
- 可以被控制(暫停/恢復)
- 任務是可以通訊的
我們將從上述四點來判斷,協程是否是一個任務
- 首先 協程有自己的控制流,並且只是一系列的宣告,與python其他函式一樣
- 協程是有自己的內部狀態的(區域性變數locals), 只要協程沒有退出, locals一直存在, 並且協程是會建立一個執行環境的
- 協程也是可通訊的,通過send()方法
- 協程是可以控制的, yield 暫停執行, send 恢復執行,close結束執行
我堅信
- 非常清楚的, 協程非常像任務
- 但是協程並沒有與threads或者子程序繫結
- 一個問題, 你能不用thread或者process來實現一個多工嗎?
- 如何只用協程來實現多工?
part 6 作業系統裡面的崩潰課程
單核CPU基礎上
程式執行
當程式轉換成指令執行在cpu上執行的時候, cpu在某一時刻只執行一個指令或者進行任務切換
多工問題
- cpu 根本不知道什麼多工
- 當然應用程式也不知道
- 但是顯然必須有人知道這個事情
- 只能是作業系統了
作業系統
- 作業系統對機器上所有執行著的程式負責
- 就像你觀察到的, 作業系統確實允許多個程序同時執行
- 他是通過快速切換多個task來實現的
一個難題
- 當你的cpu在執行你的程式的時候,它是沒有在執行作業系統的
- 這裡有一個問題, 作業系統是如何在沒有執行的情況下去切換一個正在執行的任務的呢?
- 這是”context-switching”問題
traps
指的是當異常或者中斷髮生時,處理器捕捉到一個執行執行緒,並且將控制權轉移到作業系統中某一個固定地址的機制。
中斷和陷阱
- 通常有兩種機制來讓作業系統重新獲取控制權
- 中斷 某種硬體訊號(資料到達, 計時器, 按鍵操作等)
- 陷阱 一種軟體生成的訊號
- 兩種情況下, cpu都會暫停現在正在做的工作並且開始執行作業系統
就是在這個情況下, 作業系統會進行任務切換
traps 和作業系統呼叫
- 底層系統呼叫通常是陷阱
- 陷阱通常是一種特殊的cpu 指令
read(fd, buf, nbytes) -> mov 0x10(%esp), %edx
mov 0xc(%esp), %ecx
...
int $0x80 # this is trap當陷阱指令執行的時候程式會在當前點暫停執行, 然後作業系統繼續執行
巨集觀來看
- 現代作業系統是由中斷驅動的
- 作業系統將你的程式放在cpu上執行
- 程式會一直執行直到遇見一個trap(system call)
- 程式暫停, os開始執行
- 一直重複這個流程
任務切換

在每個trap發生的時候, 作業系統來切換不同的任務
洞察力
- yield 就相當於一種trap
- 但是不是真正的trap
- 當生成器方法執行到了yield, 它會立即停止執行
- cpu執行權會被轉移到任何可以使這個生成器執行的地方(隱式的)
- 如果你將yield看成trap, 那麼你可以用python建立一個多工的mini作業系統
part 7 讓我們來建立一個作業系統吧
see https://github.com/mowangdk/leetcode_question python_related/build_python_os part 8 棧問題
限制
- 當你使用協程的時候, 你不能編寫產生子程式的函式
def Accept(sock):
yield ReadWait(sock)
return sock.accept()
def server(port):
while True:
client, addr = Accept(sock)
yield NewTask(handle_client(client, addr))以上程式碼控制流會完全亂掉
yield語句只可以被用來暫停最外層的協程, 你不能將其放入一個巢狀方法裡面
def bar():
yield
def foo():
bar()上述程式碼bar中的yield無法將foo中的程式碼暫停
解決方案
- 這裡有一種方法可以實現可暫停的子協程
- 但是這個只能在任務排程器中實現
- 必須嚴格的遵守yield的宣告
- 這種技巧被稱作“trampolining”
# A subroutine
def add(x, y):
yield x + y
# A function that calls a subroutine
def main():
r = yield add(2, 2)
print r
yield
def run():
m = main()
sub = m.send(None)
result = sub.send(None)
m.send(result)

這裡就是就是“蹦床”, 如果你想使用subroutine, 那麼所有資料都必須通過排程器
part9 一些最後的話
進一步的主題
對於我們的task scheduler, 還有很多可以改進的點
- task之間的溝通
- 對於阻塞操作的處理(比如資料庫的訪問)
- 協程多工和執行緒
- 異常處理
python的生成器比人們認為的還要複雜的多
- 它可以實現定製的迭代模式
- 它可以實現流水線處理和資料流處理
- 它可以實現事件處理
- 合作多工
許多教程和文件都沒有對生成器進行詳細的說明以及深層的探索,到生成fibonacci就結束了
對於協程的效能表現
- 協程有很好的效能表現
協程 vs 執行緒
- 我不確定使用協程可以比一般的多工處理要快
- 執行緒程式設計已經很好的建立了範例
- python多執行緒由於GIL的原因, 往往是一個很糟糕的選擇
- 但是我不太清楚,自己寫一個排程系統是否比讓作業系統進行task排程要好
風險
- 協程最初在1960年被開發出來, 然後在這之後靜靜的死去了
- 也許它是由於一個很好的理由死去了
- 我想一個合理的程式設計師都會抱怨在生產軟體中使用協程是很惡毒的
- 這個時候可以對我們之前的程式碼,或者其他用協程編寫的程式碼進行code review
注意
- 如果你將要使用協程, 其中非常關鍵的一點是, 你不可以混用程式設計範例
- yield的三種使用場景
- 遍歷(資料生產者)
- 收資料 (資料消費者)
- trap (合作多工)
- 一個生成器只用來完成一項功能, 不可以再一個生成器中完成上述多個功能
小心的使用它
- 我認為協程就像是一個高爆炸藥
- 我們應該小心的儲存它
- 如果建立一個特別糾結混亂的協程,那麼他所屬的執行緒或者子程序很有可能崩潰
- 舉個栗子, 在我們的作業系統中, 協程是不能訪問task和scheduler的, 這就非常好