
智慧運維在百度日常業務監控中的探索
http://os.51cto.com/art/201508/488470_all.htm
二、百度資料情況
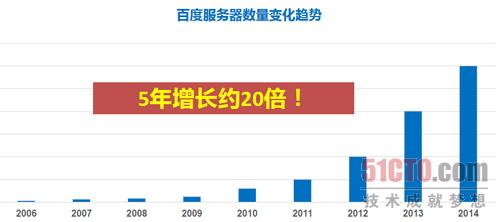
隨著百度各產品的蓬勃發展,百度的伺服器數量也呈現出爆發式增長,最近5年增長了大概20倍的規模。與產品規模不斷增長相對應地,運維人員每天會收到越來越多的監控報警,面對海量的運維指標,如何快速定位問題所發生的業務層面,達到精準化報警、快速解決問題的目標就成為運維監控常態化的需求。
百度監控系統資料規模,單以時間序列資料為例,不包含日誌類資料。
- 伺服器指標數量:>1億
- 業務指標數量:>8千萬
- 資料增長速度:50TB/日
三、運維中面臨的監控問題
當前,面對複雜的業務監控和問題診斷,運維人員想找到指標和事件之間的關聯關係,進行因果關係推導,並最終定位故障,基本依靠人的經驗來進行。但隨著業務和監控規模的膨脹,運維也希望能夠更加自動化、智慧化地達成保證服務高可用性的目標,即快速的問題發現、分析定位或止損。

下面,我們可以從發現問題—分析問題—解決問題的思路出發,逐步給出遞進的解決方案。
四、發現問題篇:異常自動檢測
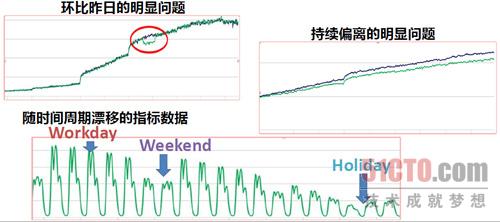
日常運維的業務指標資料會出現一些環比昨日的明顯異常、持續偏離的明顯問題和隨著時間週期漂移的指標資料等問題,以前這些監控的配置基本靠工程師經驗或持續的迭代修正,甚至純人工排查。隨著監控系統的發展,可以通過制定監控標準和自動化監控部署實現運維的標準化和自動化,最終的目標,是希望用智慧化的方法徹底解決這個問題。
一般,在系統出現指標資料波動時,需要先判定是否確實為異常情況,確定異常後再實現精準報警。那麼,怎麼自動檢測業務的異常指標,幫助運維工程師和開發工程師處理問題呢?
這裡主要有兩個策略,自動恆定閾值設定與動態閾值設定:
1.恆定閾值設定法
對於普通資料,運維人員在伺服器端設定伺服器應用指標超過某合理數值自動報警,並對伺服器異常的波動狀態進行報警。這個可使用一些標準的統計學方法去自動計算這個閾值,取代人工配置成本。
參考方式:
- 基於歷史資料統計
- 假設正態分佈
- 3-sigma策略
2.動態閾值設定法
百度大多數業務資料的流量呈現很強的天週期特性,在某時刻出現資料波峰的驟降或波谷資料的驟增等變動情況時,恆定閾值法很難解決這類問題的精準異常判斷。那麼我們可以把上述方法衍變升級一下,採用動態時間視窗的閾值設定法來解決週期性資料的異常判斷。
參考方式:
- 多分佈形式:將資料分段
- 按天同期計算統計閾值
- 分段3-sigma策略
3.恆定閾值和動態閾值的使用
針對以上兩種閾值劃分方式,異常檢測系統如何知道應該對每組資料進行什麼樣的異常檢測策略呢?這就需要一種方法提前對資料進行分類,可以採用一種可判斷資料是否具有周期性趨勢的分類器方式來解決。如果資料具有很強的週期性特徵,建議使用動態閾值設定法;如果資料分析後沒有周期性特徵,那麼使用恆定閾值就可以了。

另外,我們還會遇到這種特殊的情況,資料會隨時間出現漂移。比如某產品流量,會按照工作日、週末、傳統長假等時間呈現出不同的資料特徵,產生階段性變化。這個時候要進行異常檢測,就不僅要考慮資料的普通週期性,還要考慮季節性和趨勢性的變化。監控系統可通過對日常資料進行分析,採用三次指數平滑等方法,對資料本身的趨勢性進行學習。
當然,上述方法都是基於從歷史資料進行學習分析從而進行異常檢測的,如果缺少歷史資料,那麼對於這些指標,基於歷史資料進行同環比分析的意義就不大,核心就轉化為檢測資料有沒有突升和突降異常。可採用類似於區域性平滑的方法檢視真實資料與區域性平滑後資料有沒有大的出入,如果差距較大,可判斷為有大的突升和突降,可以標識資料異常。
參考方式:
- 區域性平滑法
- 速度法
經過經驗的積累,對於核心產品的流量變動,即使波動不大,監控系統也可以做到靈敏且精準的指標監控,能夠快速發現異常情況。當然,全自動的異常檢測系統難免會出現誤報、漏報等情況,這就要求異常檢測系統需要支援工程師的標註與反饋,百度監控系統的自學習能力可以根據工程師的需求進行動態調整,可同時支援人為調整和系統自動引數學習調整,系統可自動根據工程師的標註或報警量的多少,進行引數訓練,把異常檢測引數調整到合理的範圍。
工程師標註
- 修改引數
- 標記未檢測到的異常
- 標記錯誤的報警
機器學習
- 標註報警 => 引數訓練
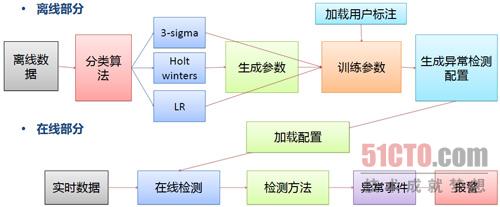
綜合上述方法,百度智慧監控系統中的自動異常檢測最終形成兩種狀態的結合:離線狀態和線上狀態,離線部分可根據歷史資料進行分類學習、引數訓練,而線上部分能夠進行最終的異常檢測和報警。
具體的組成如圖所示:
五、發現問題篇:精準報警
監控系統僅僅發現了問題還不夠,由於指標數量太過繁雜,為了起到輔助工程師快速解決問題的效果,還需要做到精準化報警。百度的精準報警主要分成兩個層面,一個是單個指標的報警是否足夠精準;這裡需要考慮兩個問題,一是是否每次異常都應該報警?需要容忍系統毛刺的存在;二是異常過濾,把離散的異常點轉化為異常事件或狀態,找到指標和事件的關聯關係。
在單一指標的報警足夠精準的基礎上,另一個是把不同指標的報警結合起來做到足夠精準。如何把多個指標的報警綜合起來呢?簡單策略是固定時間視窗來報警,時間相近的報警可進行一定的合併,只要將首先出現的指標報警送達給到運維人員即可。從整個監控策略來看,把報警綜合起來,同類的報警進行合併來報給運維人員。複雜一些的策略是關聯挖掘,把歷史上產生的運維報警和事件關聯起來報警,同時,某些報警經常頻繁地一起出現,可以認為這是同一個報警,不再單獨分別進行報警。
採用的具體策略有:
1. 報警合併簡單策略
- 固定時間視窗
- 相同監控策略
- 相同監控物件
2. 報警合併複雜策略
- 關聯挖掘
- 合併置信度較高的頻繁項集
3. 報警依賴
- 策略依賴
- 異常依賴
六、分析問題篇:關聯分析
監控系統不僅需要幫助工程師發現問題,同時還需要通過建立關聯分析,進行輔助問題定位,甚至迅速找到相關的指標或影響。那麼,如何為複雜多樣的運維資料建立關聯呢?
產品服務層級的關聯關係圖:
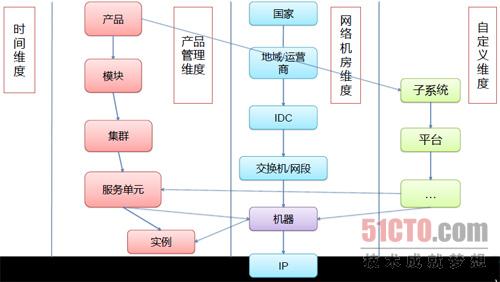
運維工程師可以把一些基礎的關聯關係配置到監控系統中,可以讓監控系統明白一些常態化的運維指標與其它指標是否存在關聯,比如多個模組的異常是否存在關聯、伺服器升級或者部署產生問題是否與資料中心或交換機異常有關等。
具體的實現策略有:
1.關聯挖掘
(1)事件和事件間的關聯
- 頻繁項集挖掘
- 所有運維事件
(2)事件和時序間的關聯
- 指標異常經常與部署升級事件相伴發生
- 問題診斷&故障定位
(3)多時序間的關聯
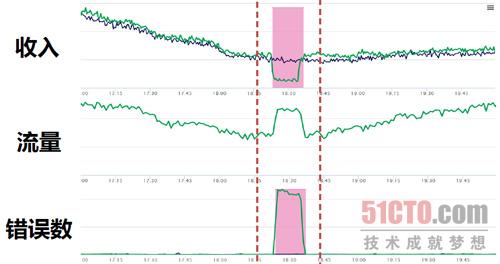
2.關聯視覺化
通過關聯變動,幫助運維人員分析重點資料的變動情況。
(1)事件&事件關聯
(2)事件&時序關聯
3.服務透視定位問題
運維事件多是與時間持續緊密關聯,我們可以把運維事件按照時間軸演進順序進行展示。同時,運維工程師常常接觸的服務拓撲,本身也是一種運維模組的關聯關係。把這些離散的運維資料通過模組關聯、時間關聯、資料流關聯等緊密地聯絡起來,構成一個完整的服務透檢視,如果異常發生在關係透檢視中的某個部分,就可以按照周邊關係的通路來快速定位問題。
(1)模組呼叫關係
(2)事件和模組關聯
六、分析問題篇:故障定位
僅僅找到關聯還不夠,真正分析業務問題解決問題才是關鍵。這裡介紹兩個常用的輔助定位問題策略。
1.多維資料分析
監控系統採集到的很多指標具備包含關係,很多情況下,一個總體指標是由許多子指標加和構成的,或者也可以說成是總體維度是由許多子維度組成的。監控系統可以計算出每個子指標或子維度佔總指標總維度的百分比,並按照影響權重去進行分析,當某個子指標的變化幅度對總體指標影響權重最大,我們就傾向於認為這個指標可能是問題的原因。
舉個例子,百度的總體流量指標對應每個地域的流量之和,總體流量有問題有可能是某個地域流量出現問題,找到目前對總體流量變化影響最大的地域進行問題處理就可以解決問題。同樣的道理也可以推廣到其它情況。
2.故障診斷樹
運維人員可以通過資料視覺化(熱力圖、多維報表)的形式,結合以前發現問題的經驗沉澱模式,發現指標間的強相關,做出問題診斷。那我們是不是可以將運維人員的經驗固化到監控系統中,通過不同指標的分析方向和下探方法可以形成樹狀結構,通過樹上的某個節點進行逐級探查。最終形成故障診斷樹,通過推導路徑不僅可以幫助運維人員快速完成問題出現時的排查過程,節省這部分的定位時間,也很有可能達到直接定位問題或加速解決故障的目的。
故障檢測:
(1)領域專家知識
(2)邏輯推導引擎
(3)迅速找到問題根因
七、解決問題篇
- 監控系統產生決策
- 部署排程系統執行
1.單邊故障自動止損
單邊故障指單個IDC故障、單個鏈路故障等。比如一個IDC或者某些IDC出現問題,解決辦法是切走這部分流量,利用監控系統來做動態的部署排程。通過某個資料中心或鏈路的部署調整,幫助系統快速恢復,進而實現自動化決策和執行來實現單邊故障止損。
具體策略有:
(1)實現自動冗餘與排程
(2)智慧監控系統負責動態決策
(3)部署排程系統負責排程執行
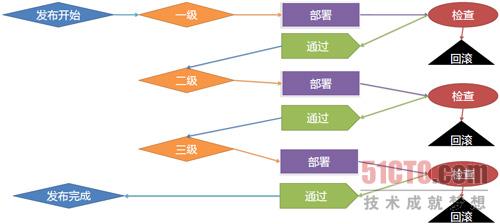
2.灰度釋出自動止損
研發工程師做灰度釋出時,可以先做小流量的釋出,部署系統可以跟監控系統配合,如果出現問題,直接進行狀態終止或回滾,把問題控制在灰度釋出範圍內。
八、智慧運維監控總結
通過上述說明,百度的智慧運維監控系統最終形成了一個監控閉環,包含問題發現、分析決策和問題的解決。具體的組成包括異常檢測、報警收斂、關聯分析、故障定位和自動處理五部分內容。

九、未來運維變被動為主動
1.全方位覆蓋
在使用者端(APP、瀏覽器等)、雲端(機房、伺服器、自身服務、第三方服務等)、管道(鏈路、運營商)等任何維度進行資料採集並進行異常自動檢測。
2. 讓監控更聰明
- 分析運用已有資料,並把服務狀態、問題影響分析等視覺化
- 自動學習並理解故障的趨勢和模式
- 自動發現服務或依賴環境的變更
當然,更進一步地,監控系統是不是可以先於故障發生而預測到故障,在故障發生之前就可以處理並解決故障,從而達成產品的超高可用性目標。未來的智慧監控應該是這樣的,運維工程師經過完善的監控部署,實現全方位的異常自動檢測覆蓋,同時,在系統剛出現故障徵兆,有損之前就進行處理並解決,實現完整的智慧化監控系統解決方案。
歡迎所有對智慧化運維技術感興趣的同學加入百度運維部,一起推動智慧化運維的發展。
歡迎訪問百度運維部部落格:http://op.baidu.com