
Apache Beam指南
Apache Beam
標籤(空格分隔): Hadoop
1. What is Beam ?
前世今生:
誕生背景:
分散式資料處理發展迅猛 –> 新的分散式資料處理技術越來越多 –> Hadoop MapReduce,Apache Spark,Apache Storm,Apache Flink,Apache Apex –> 新技術高效能 , 受歡迎,人們喜新厭舊 –> 業務的遷移 –> 遷移條件: 學習新技術,重寫業務邏輯 –> 懶 –> 怎麼辦 ??
Apache Beam 應運而生
貴族身份:
Apache Beam - 原名 Google DateFlow
2016年2月份成為Apache基金會孵化專案
2017年1月10日正式畢業成為頂級專案
繼MapReduce,GFS和BigQuery之後,Google在大資料處理領域對開源社群的又一個超級大的貢獻
目前最新版本: 1.0
業界影響:
被譽為進行資料流處理和批處理的最佳程式設計模型 !
被譽為下一代的大資料處理標準 !
Google的員工已經不再使用MapReduce了 ……
何方神聖:
Beam專案主要是對資料處理(有限的資料集,無限的資料流)的程式設計正規化和介面進行了統一定義(Beam Model) 這樣,基於Beam開發的資料處理程式可以執行在任意的分散式計算引擎上.
主要構成:
– Beam SDKs
Beam SDK定義了開發分散式資料處理任務業務邏輯的API介面,即提供一個統一的程式設計介面給到上層應用的開發者,開發者不需要了解底層的具體的大資料平臺的開發介面是什麼,直接通過Beam SDK的介面,就可以開發資料處理的加工流程,不管輸入是用於批處理的有限資料集,還是流式的無限資料集。對於有限或無限的輸入資料,Beam SDK都使用相同的類來表現,並且使用相同的轉換操作進行處理。
– Beam Pipeline Runner
Runner 是將使用者通過呼叫Beam SDK構成的program(pipeline)進行編譯轉換,當我們指定任意一個Runner時,program就會被轉化為與該Runner相相容的可直接執行的程式,所以,在執行Beam程式時,需要指明底層的正確Runner型別
Beam 架構:
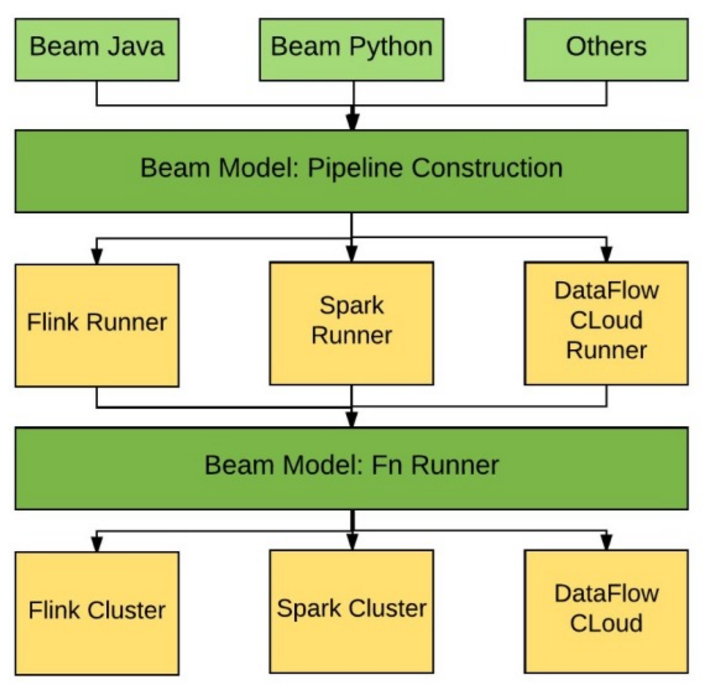
使用者通過Beam Model構建一個數據處理管道(pipeline),呼叫Beam SDK API實現管道里的邏輯,也就是”程式設計實現”,然後pipeline交給具體的Beam Runner編譯,最後執行在分散式計算引擎上.
注: 流處理和批處理的未來在於 Apache Beam,而執行引擎的選擇權在於使用者。
ETL : 基於Beam開發的程式可以執行在多個分散式計算框架上,那麼它可以用來將不同的資料來源,或者多個數據儲存媒體上的資料整合到一起,最終生成我們想要的資料
2. Beam Core
Data
Beam 能處理什麼樣的資料 ?
– 無限的時間亂序資料流
有限的資料集
無限的資料流
有限的資料集可以看做是無限的資料流的一種特例,從資料處理邏輯的角度,這兩者並無不同之處
例如,假設微博資料包含時間戳和轉發量,使用者希望按照統計每小時的轉發量總和,此業務邏輯應該可以同時在有限資料集和無限資料流上執行,並不應該因為資料來源的不同而對業務邏輯的實現產生任何影響
。
資料進入分散式處理框架的時間(Process Time) VS 資料產生的時間(Event-Time)
這兩個時間通常是不同的,例如,對於一個處理微博資料的流計算任務,一條2016-06-01-12:00:00發表的微博經過網路傳輸等延遲可能在2016-06-01-12:01:30才進入到流處理系統中。批處理任務通常進行全量的資料計算,較少關注資料的時間屬性,但是對於流處理任務來說,由於資料流是無窮無盡的,無法進行全量的計算,通常是對某個視窗中得資料進行計算,對於大部分的流處理任務來說,按照時間進行視窗劃分
對於流處理框架處理的資料流來說,其資料的到達順序可能並不嚴格按照Event-Time的時間順序。如果基於Process Time定義時間視窗,資料到達的順序就是資料的順序,因此不存在亂序問題。但是對於基於Event Time定義的時間視窗來說,可能存在時間靠前的訊息在時間靠後的訊息後到達的情況,這在分散式的資料來源中可能非常常見。對於這種情況,如何確定遲到資料,以及對於遲到資料如何處理通常是很棘手的問題。
Beam Model
Beam Model從四個維度歸納了使用者在進行資料處理的時候需要考慮的問題:

翻譯過來:
- What。如何對資料進行計算?例如,Sum,Join或是機器學習中訓練學習模型等。在Beam SDK中由Pipeline中的操作符指定。
- Where。資料在什麼範圍中計算?例如,基於Process-Time的時間視窗,基於Event-Time的時間視窗,滑動視窗等等。在BeamSDK中由Pipeline中的視窗指定。
- When。何時將計算結果輸出?例如,在1小時的Event-Time時間視窗中,每隔1分鐘,將當前視窗計算結果輸出。在Beam SDK中由Pipeline中的Watermark和觸發器指定。
- How。遲到資料如何處理?例如,將遲到資料計算增量結果輸出,或是將遲到資料計算結果和視窗內資料計算結果合併成全量結果輸出。在Beam SDK中由Accumulation指定。
3.How to Design a Pipeline
設計最簡單的pipeline, 預設是最簡單的維度,只需考慮下面四個問題:
- Where is your input data stored?
- What does your data look like?
- What do you want to do with your data?
- What does your output data look like, and where should it go?
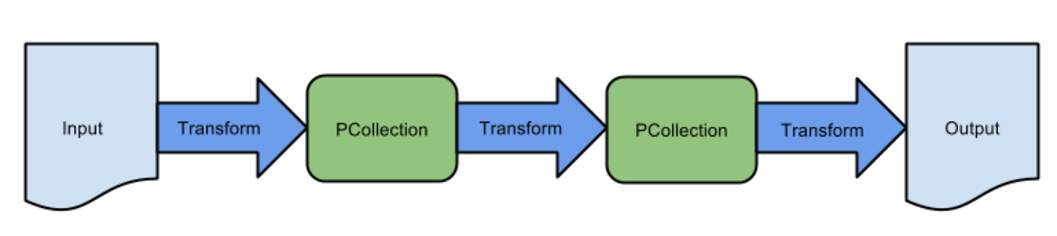
整個流程如何用程式碼實現 ?
—-create a driver program using the classes in one of the Beam SDKs.
理解幾個概念:
* Pipeline
A Pipeline encapsulates your entire data processing task, from start to finish. This includes reading input data, transforming that data, and writing output data. All Beam driver programs must create a Pipeline. When you create the Pipeline, you must also specify the execution options that tell the Pipeline where and how to run.
說白了…跟SparkContext一樣一樣的,承接上下文環境
* PCollection
A PCollection represents a distributed data set that your Beam pipeline operates on. The data set can be bounded, meaning it comes from a fixed source like a file, or unbounded, meaning it comes from a continuously updating source via a subscription or other mechanism. Your pipeline typically creates an initial PCollection by reading data from an external data source, but you can also create a PCollection from in-memory data within your driver program. From there, PCollections are the inputs and outputs for each step in your pipeline.
說白了…跟RDD一樣一樣的,PCollections包含一個潛在的無限資料流。這些資料都來源於輸入源,然後應用於轉換。
* Transform
A Transform represents a data processing operation, or a step, in your pipeline. Every Transform takes one or more PCollection objects as input, perfroms a processing function that you provide on the elements of that PCollection, and produces one or more output PCollection objects.
一個操作PCollection處理步驟執行資料操作。典型的傳遞途徑可能會在一個輸入源有多個轉換操作(例如,將一組日誌條目傳入的字串轉換成一個鍵/值對,關鍵是IP地址和值是日誌訊息)。它由BeamSDK附帶的一系列標準聚合建成,當然,也可以定義根據自己的處理需求自定義。
* I/O Source and Sink
Beam provides Source and Sink APIs to represent reading and writing data, respectively. Source encapsulates the code necessary to read data into your Beam pipeline from some external source, such as cloud file storage or a subscription to a streaming data source. Sink likewise encapsulates the code necessary to write the elements of a PCollection to an external data sink.
So… 建立一個Driver Program的流程如下:
Create a Pipeline object –> set options –> initial PCollection (using the Source API to read data from an external source, or using a Create transform to build a PCollection from in-memory data.) –> Apply Transforms to each PCollection. –> Output the final, transformed PCollection(s)(Sink API ) –> Run the pipeline using the designated Pipeline Runner.
Coding:
Maven 依賴:
<!-- Apache Beam-->
<dependency>
<groupId>org.apache.beam</groupId>
<artifactId>beam-sdks-java-core</artifactId>
<version>0.5.0</version>
</dependency>
<dependency>
<groupId>org.apache.beam</groupId>
<artifactId>beam-runners-direct-java</artifactId>
<version>0.5.0</version>
<scope>runtime</scope>
</dependency>Demo 解析:
public static void main(String[] args) {
// Create the pipeline.
PipelineOptions options =
PipelineOptionsFactory.fromArgs(args).create();
Pipeline p = Pipeline.create(options);
PCollection<String> lines = p.apply(
"ReadMyFile", TextIO.Read.from("protocol://path/to/some/inputData.txt"));
}當使用Beam時,Driver Program中必須先建立Pipeline類的一個例項(一般放在main方法中),而建立例項時,
需要建立 PipelineOptions物件來設定引數,最後將引數傳遞給 Pipeline.create();
建立PCollection的方法:
- Reading from an external source
PCollection<String> lines = p.apply(
"ReadMyFile", TextIO.Read.from("protocol://path/to/some/inputData.txt"));- Creating a PCollection from in-memory data
// Apply Create, passing the list and the coder, to create the PCollection.
p.apply(Create.of(LINES)).setCoder(StringUtf8Coder.of())PCollection 的特徵
- Element type
The elements of a PCollection may be of any type, but must all be of the same type. However, to support distributed processing, Beam needs to be able to encode each individual element as a byte string (so elements can be passed around to distributed workers). The Beam SDKs provide a data encoding mechanism that includes built-in encoding for commonly-used types as well as support for specifying custom encodings as needed. - Immutability
A PCollection is immutable. Once created, you cannot add, remove, or change individual elements. A Beam Transform might process each element of a PCollection and generate new pipeline data (as a new PCollection), but it does not consume or modify the original input collection. - Random access
A PCollection does not support random access to individual elements. Instead, Beam Transforms consider every element in a PCollection individually. - Size and boundedness
A PCollection is a large, immutable “bag” of elements. There is no upper limit on how many elements a PCollection can contain; any given PCollection might fit in memory on a single machine, or it might represent a very large distributed data set backed by a persistent data store.
A PCollection can be either bounded or unbounded in size. A bounded PCollection represents a data set of a known, fixed size, while an unbounded PCollection represents a data set of unlimited size. Whether a PCollection is bounded or unbounded depends on the source of the data set that it represents. Reading from a batch data source, such as a file or a database, creates a bounded PCollection. Reading from a streaming or continously-updating data source, such as Pub/Sub or Kafka, creates an unbounded PCollection (unless you explicitly tell it not to). - Element timestamps
Each element in a PCollection has an associated intrinsic timestamp. The timestamp for each element is initially assigned by the Source that creates the PCollection. Sources that create an unbounded PCollection often assign each new element a timestamp that corresponds to when the element was read or added.
Transforms使用
In Beam SDK each transform has a generic apply method,在運用時,使用輸入的PCollection作為物件,呼叫apply函式,然後以引數,返回輸出PCollection 即
[Output PCollection] = [Input PCollection].apply([Transform])當涉及到多個Transforms ,使用如下:
[Final Output PCollection] = [Initial Input PCollection].apply([First Transform])
.apply([Second Transform])
.apply([Third Transform])由1個PCollection建立兩個PCollection
[Output PCollection 1] = [Input PCollection].apply([Transform 1])
[Output PCollection 2] = [Input PCollection].apply([Transform 2])Core Beam transforms
- ParDo
- GroupByKey
- Flatten and Partition
ParDo
ParDo 是一個並行處理,它的邏輯類似於 Map/Shuffle/Reduce-style 中的Map階段,對PCollection的每個元素進行處理,處理邏輯是使用者自定義的程式碼,處理完之後會輸出一個或多個元素給輸出PCollection.
用途:
- Filtering a data set.
You can use ParDo to consider each element in a PCollection and either output that element to a new collection, or discard it. - Formatting or type-converting each element in a data set.
If your input PCollection contains elements that are of a different type or format than you want, you can use ParDo to perform a conversion on each element and output the result to a new PCollection. - Extracting parts of each element in a data set.
If you have a PCollection of records with multiple fields, for example, you can use a ParDo to parse out just the fields you want to consider into a new PCollection. - Performing computations on each element in a data set. You can use ParDo to perform simple or complex computations on every element, or certain elements, of a PCollection and output the results as a new PCollection.
用法: 當使用ParDo時,必須以DoFn的類的物件作為引數來提供自定義程式碼,即繼承DoFn類,
// The input PCollection of Strings.
PCollection<String> words = ...;
// The DoFn to perform on each element in the input PCollection.
static class ComputeWordLengthFn extends DoFn<String, Integer> { ... }
// Apply a ParDo to the PCollection "words" to compute lengths for each word.
PCollection<Integer> wordLengths = words.apply(
ParDo
.of(new ComputeWordLengthFn())); // The DoFn to perform on each element, which
static class ComputeWordLengthFn extends DoFn<String, Integer> {
@ProcessElement
public void processElement(ProcessContext c) {
// Get the input element from ProcessContext.
String word = c.element();
// Use ProcessContext.output to emit the output element.
c.output(word.length());
}
}還可以以匿名內部類的方式,比如下面:
// The input PCollection.
PCollection<String> words = ...;
// Apply a ParDo with an anonymous DoFn to the PCollection words.
// Save the result as the PCollection wordLengths.
PCollection<Integer> wordLengths = words.apply(
"ComputeWordLengths", // the transform name
ParDo.of(new DoFn<String, Integer>() { // a DoFn as an anonymous inner class instance
@ProcessElement
public void processElement(ProcessContext c) {
c.output(c.element().length());
}
}));GroupByKey
GroupbyKey用來處理PCollection中的Key-Value對,類似於 Map/Shuffle/Reduce-style中shuffle階段
使用 …略!
Flatten and Partition
Flatten用來處理具有相同資料型別的PCollection,它可以將多個PCollection合併為一個PCollection,而Partition 可以將一個PCollection拆分成多個小的PCollection
Flatten示例:
// Flatten takes a PCollectionList of PCollection objects of a given type.
// Returns a single PCollection that contains all of the elements in the PCollection objects in that list.
PCollection<String> pc1 = ...;
PCollection<String> pc2 = ...;
PCollection<String> pc3 = ...;
PCollectionList<String> collections = PCollectionList.of(pc1).and(pc2).and(pc3);
PCollection<String> merged = collections.apply(Flatten.<String>pCollections());Partition示例:
// Provide an int value with the desired number of result partitions, and a PartitionFn that represents the partitioning function.
// In this example, we define the PartitionFn in-line.
// Returns a PCollectionList containing each of the resulting partitions as individual PCollection objects.
PCollection<Student> students = ...;
// Split students up into 10 partitions, by percentile:
PCollectionList<Student> studentsByPercentile =
students.apply(Partition.of(10, new PartitionFn<Student>() {
public int partitionFor(Student student, int numPartitions) {
return student.getPercentile() // 0..99
* numPartitions / 100;
}}));
// You can extract each partition from the PCollectionList using the get method, as follows:
PCollection<Student> fortiethPercentile = studentsByPercentile.get(4);4.Design Your Pipeline
Like this :
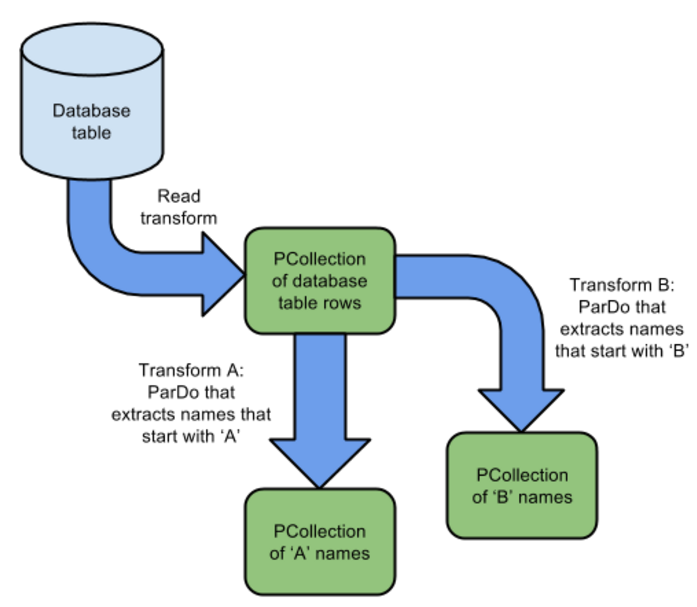
Like this:
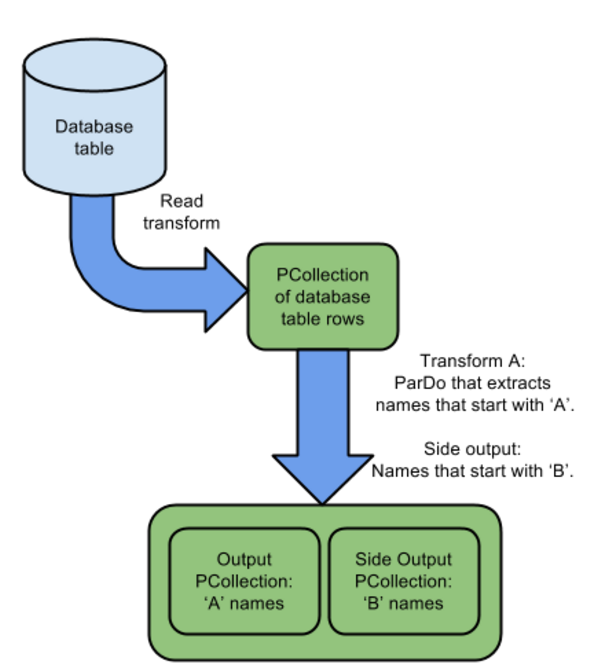
Like this:
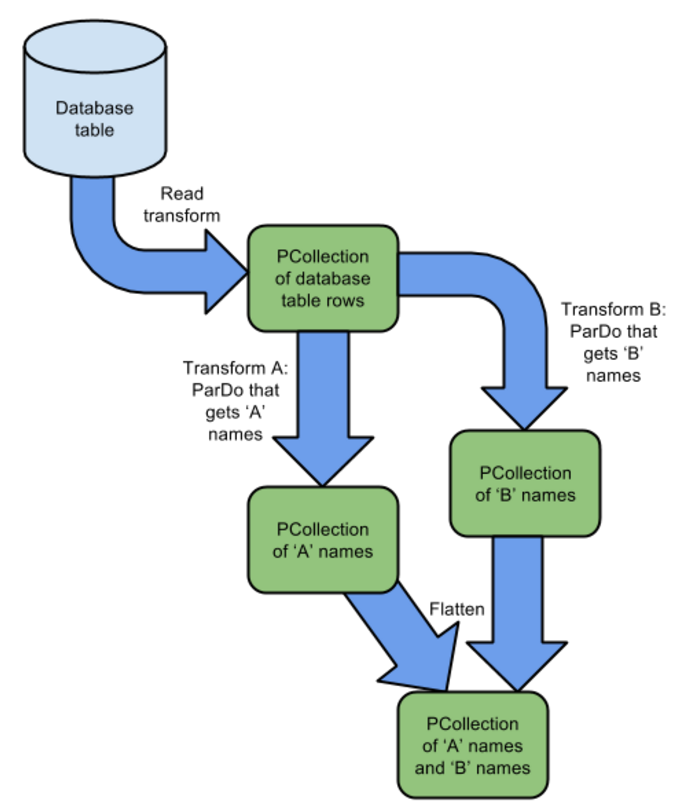
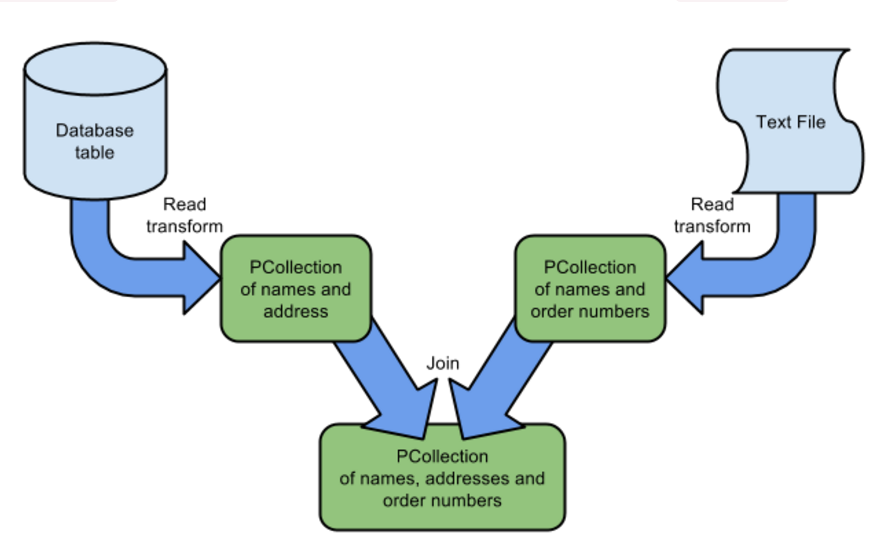
Or Like this:
5.WordCount Example
WordCount pipeline:
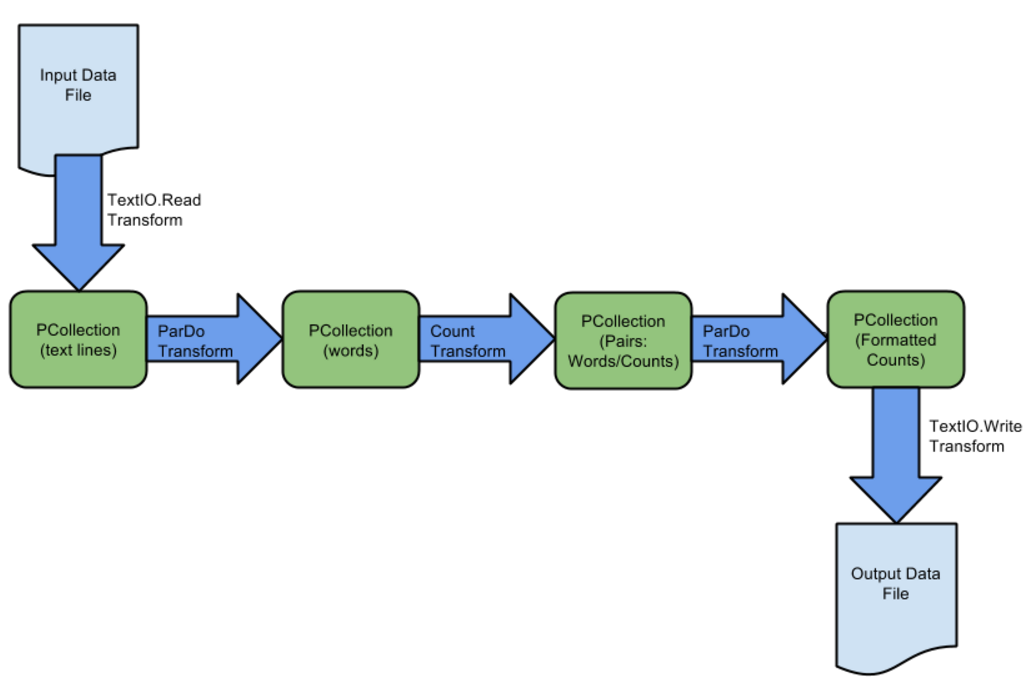
WordCount原始碼解讀:
public class WordCount {
/**
* 1.a.通過DoFn程式設計Pipeline使得程式碼很簡潔。b.對輸入的文字做單詞劃分,輸出。
*/
static class ExtractWordsFn extends DoFn<String, String> {
private final Aggregator<Long, Long> emptyLines =
createAggregator("emptyLines", Sum.ofLongs());
@ProcessElement
public void processElement(ProcessContext c) {
if (c.element().trim().isEmpty()) {
emptyLines.addValue(1L);
}
// 將文字行劃分為單詞
String[] words = c.element().split("[^a-zA-Z']+");
// 輸出PCollection中的單詞
for (String word : words) {
if (!word.isEmpty()) {
c.output(word);
}
}
}
}
/**
* 2.格式化輸入的文字資料,將轉換單詞為並計數的列印字串。
*/
public static class FormatAsTextFn extends SimpleFunction<KV<String, Long>, String> {
@Override
public String apply(KV<String, Long> input) {
return input.getKey() + ": " + input.getValue();
}
}
/**
* 3.單詞計數,PTransform(PCollection Transform)將PCollection的文字行轉換成格式化的可計數單詞。
*/
public static class CountWords extends PTransform<PCollection<String>,
PCollection<KV<String, Long>>> {
@Override
public PCollection<KV<String, Long>> expand(PCollection<String> lines) {
// 將文字行轉換成單個單詞
PCollection<String> words = lines.apply(
ParDo.of(new ExtractWordsFn()));
// 計算每個單詞次數
PCollection<KV<String, Long>> wordCounts =
words.apply(Count.<String>perElement());
return wordCounts;
}
}
/**
* 4.可以自定義一些選項(Options),比如檔案輸入輸出路徑
*/
public interface WordCountOptions extends PipelineOptions {
/**
* 檔案輸入選項,可以通過命令列傳入路徑引數,路徑預設為gs://apache-beam-samples/shakespeare/kinglear.txt
*/
@Description("Path of the file to read from")
@Default.String("gs://apache-beam-samples/shakespeare/kinglear.txt")
String getInputFile();
void setInputFile(String value);
/**
* 設定結果檔案輸出路徑,在intellij IDEA的執行設定選項中或者在命令列中指定輸出檔案路徑,如./pom.xml
*/
@Description("Path of the file to write to")
@Required
String getOutput();
void setOutput(String value);
}
/**
* 5.執行程式
*/
public static void main(String[] args) {
WordCountOptions options = PipelineOptionsFactory.fromArgs(args).withValidation()
.as(WordCountOptions.class);
// options.setRunner(FlinkRunner.class);
// dataflowOptions.setRunner(DataflowRunner.class);
Pipeline p = Pipeline.create(options);
p.apply("ReadLines", TextIO.Read.from(args[0]))
.apply(new CountWords())
.apply(MapElements.via(new FormatAsTextFn()))
.apply("WriteCounts", TextIO.Write.to(args[1]));
p.run().waitUntilFinish();
}
}6.Run The Pipeline
IDEA直接執行
- 設定VM options
-DPdirect-runner
-DPspark-runner
-DPapex-runner
-DPflink-runner - 設定Programe arguments
--inputFile=pom.xml --output=counts
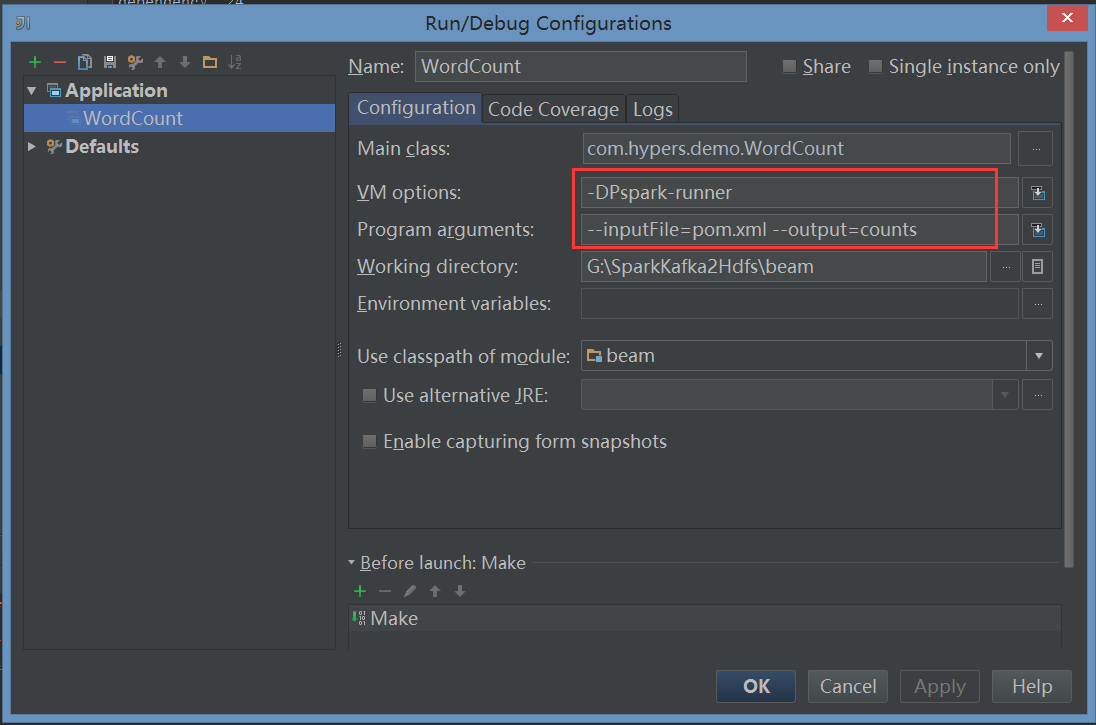
執行結果:
打包提交到叢集上執行
如果要提交到spark 叢集上執行,pom需要以下依賴
<dependency>
<groupId>org.apache.beam</groupId>
<artifactId>beam-runners-spark</artifactId>
<version>0.5.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.10</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.10</artifactId>
<version>${spark.version}</version>
</dependency>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<configuration>
<createDependencyReducedPom>false</createDependencyReducedPom>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
</configuration>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<shadedArtifactAttached>true</shadedArtifactAttached>
<shadedClassifierName>shaded</shadedClassifierName>
</configuration>
</execution>
</executions>
</plugin>使用mvn package打包後生成
beam-examples-1.0.0-shaded.jar提交到spark叢集執行,打包執行是需要在pom中註釋掉direct-runner
<dependency>
<groupId>org.apache.beam</groupId>
<artifactId>beam-runners-direct-java</artifactId>
<version>0.5.0</version>
<scope>runtime</scope>
</dependency>提交命令:
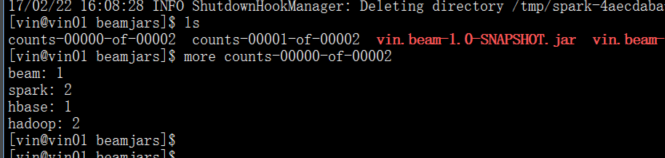
/opt/modules/spark-1.6.1-bin-2.5.0-cdh5.3.6/bin/spark-submit --class com.hypers.demo.WordCount --master local[2] vin.beam-1.0-SNAPSHOT-jar-with-dependencies.jar --runner=SparkRunner --inputFile=wordcount.txt --output=counts測試結果:
7. Mobile Gaming Pipeline Examples
當用戶使用一款手機遊戲時,會生成包含以下內容的資料:
- The unique ID of the user playing the game. //使用者ID
- The team ID for the team to which the user belongs. //使用者所屬Team ID
- A score value for that particular instance of play. //使用者分數
- A timestamp that records when the particular instance of play happened–this is the event time for each game data event. //使用者玩完一局遊戲時產生的時間戳
The data events might be received by the game server significantly later than users generate them.
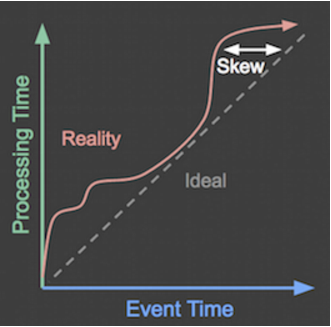
統計UserScore –Basic Score Processing in Batch
UserScore’s basic pipeline flow does the following:
- Read the day’s score data from a file stored in a text file.
- Sum the score values for each unique user by grouping each game event by user ID and combining the score values to get the total score for that particular user.
- Write the result data to a Google Cloud BigQuery table.
public class UserScore {
/**
* Class to hold info about a game event.
*/
@DefaultCoder(AvroCoder.class)
static class GameActionInfo {
@Nullable String user;
@Nullable String team;
@Nullable Integer score;
@Nullable Long timestamp;
public GameActionInfo() {}
public GameActionInfo(String user, String team, Integer score, Long timestamp) {
this.user = user;
this.team = team;
this.score = score;
this.timestamp = timestamp;
}
public String getUser() {
return this.user;
}
public String getTeam() {
return this.team;
}
public Integer getScore() {
return this.score;
}
public String getKey(String keyname) {
if (keyname.equals("team")) {
return this.team;
} else { // return username as default
return this.user;
}
}
public Long getTimestamp() {
return this.timestamp;
}
}
/**
* Parses the raw game event info into GameActionInfo objects. Each event line has the following
* format: username,teamname,score,timestamp_in_ms,readable_time
* e.g.:
* user2_AsparagusPig,AsparagusPig,10,1445230923951,2015-11-02 09:09:28.224
* The human-readable time string is not used here.
*/
static class ParseEventFn extends DoFn<String, GameActionInfo> {
// Log and count parse errors.
private static final Logger LOG = LoggerFactory.getLogger(ParseEventFn.class);
private final Aggregator<Long, Long> numParseErrors =
createAggregator("ParseErrors", Sum.ofLongs());
@ProcessElement
public void processElement(ProcessContext c) {
String[] components = c.element().split(",");
try {
String user = components[0].trim();
String team = components[1].trim();
Integer score = Integer.parseInt(components[2].trim());
Long timestamp = Long.parseLong(components[3].trim());
GameActionInfo gInfo = new GameActionInfo(user, team, score, timestamp);
c.output(gInfo);
} catch (ArrayIndexOutOfBoundsException | NumberFormatException e) {
numParseErrors.addValue(1L);
LOG.info("Parse error on " + c.element() + ", " + e.getMessage());
}
}
}
/**
* A transform to extract key/score information from GameActionInfo, and sum the scores. The
* constructor arg determines whether 'team' or 'user' info is extracted.
*/
// [START DocInclude_USExtractXform]
public static class ExtractAndSumScore
extends PTransform<PCollection<GameActionInfo>, PCollection<KV<String, Integer>>> {
private final String field;
ExtractAndSumScore(String field) {
this.field = field;
}
@Override
public PCollection<KV<String, Integer>> expand(
PCollection<GameActionInfo> gameInfo) {
return gameInfo
.apply(MapElements
.via((GameActionInfo gInfo) -> KV.of(gInfo.getKey(field), gInfo.getScore()))
.withOutputType(
TypeDescriptors.kvs(TypeDescriptors.strings(), TypeDescriptors.integers())))
.apply(Sum.<String>integersPerKey());
}
}
// [END DocInclude_USExtractXform]
/**
* Options supported by {@link UserScore}.
*/
public interface Options extends PipelineOptions {
@Description("Path to the data file(s) containing game data.")
// The default maps to two large Google Cloud Storage files (each ~12GB) holding two subsequent
// day's worth (roughly) of data.
@Default.String("gs://apache-beam-samples/game/gaming_data*.csv")
String getInput();
void setInput(String value);
@Description("BigQuery Dataset to write tables to. Must already exist.")
@Validation.Required
String getDataset();
void setDataset(String value);
@Description("The BigQuery table name. Should not already exist.")
@Default.String("user_score")
String getUserScoreTableName();
void setUserScoreTableName(String value);
}
/**
* Create a map of information that describes how to write pipeline output to BigQuery. This map
* is passed to the {@link WriteToBigQuery} constructor to write user score sums.
*/
protected static Map<String, WriteToBigQuery.FieldInfo<KV<String, Integer>>>
configureBigQueryWrite() {
Map<String, WriteToBigQuery.FieldInfo<KV<String, Integer>>> tableConfigure =
new HashMap<String, WriteToBigQuery.FieldInfo<KV<String, Integer>>>();
tableConfigure.put(
"user",
new WriteToBigQuery.FieldInfo<KV<String, Integer>>(
"STRING", (c, w) -> c.element().getKey()));
tableConfigure.put(
"total_score",
new WriteToBigQuery.FieldInfo<KV<String, Integer>>(
"INTEGER", (c, w) -> c.element().getValue()));
return tableConfigure;
}
/**
* Run a batch pipeline.
*/
// [START DocInclude_USMain]
public static void main(String[] args) throws Exception {
// Begin constructing a pipeline configured by commandline flags.
Options options = PipelineOptionsFactory.fromArgs(args).withValidation().as(Options.class);
Pipeline pipeline = Pipeline.create(options);
// Read events from a text file and parse them.
pipeline.apply(TextIO.Read.from(options.getInput()))
.apply("ParseGameEvent", ParDo.of(new ParseEventFn()))
// Extract and sum username/score pairs from the event data.
.apply("ExtractUserScore", new ExtractAndSumScore("user"))
.apply("WriteUserScoreSums",
new WriteToBigQuery<KV<String, Integer>>(options.getUserScoreTableName(),
configureBigQueryWrite()));
// Run the batch pipeline.
pipeline.run().waitUntilFinish();
}
// [END DocInclude_USMain]
}