
Hadoop2.6.3版本叢集搭建
一、環境說明
1.機器:三臺虛擬機器
2.Linux版本
cat /proc/versionLinux version 3.19.0-25-generic ([email protected]) (gcc version 4.8.2 (Ubuntu 4.8.2-19ubuntu1) ) #26~14.04.1-Ubuntu SMP
3.jdk版本
java -versionjava version “1.8.0_65”
Java(TM) SE Runtime Environment (build 1.8.0_65-b17)
Java HotSpot(TM) 64-Bit Server VM (build 25.65-b01, mixed mode)
4.叢集節點:一個masters,兩個slave
二、準備工作
1.安裝jdk:http://blog.csdn.net/u014706843/article/details/50442329
2.ssh免密碼驗證:http://blog.csdn.net/u014706843/article/details/50442533
3 建立hadoop執行帳號
即為hadoop叢集專門設定一個使用者組及使用者,這部分比較簡單,參考示例如下:
sudo groupadd hadoop //設定hadoop使用者組
sudo useradd –s /bin/bash –d /home/xx–m xx–g hadoop –G root//新增一個xx使用者,此使用者屬於hadoop使用者組,且具有root許可權。
sudo passwd xx//設定使用者xx登入密碼
su xx//切換到zhm使用者中
上述3個虛機結點均需要進行以上步驟來完成hadoop執行帳號的建立。
三、安裝Hadoop
tar -xzvf hadoop-2.6.3.tar.gz 3、修改檔名字
mv hadoop-2.6.3 hadoop4、配置hosts檔案
vi /etc/hosts大家可以參考自己的IP地址以及相應的主機名完成配置,我的如下圖
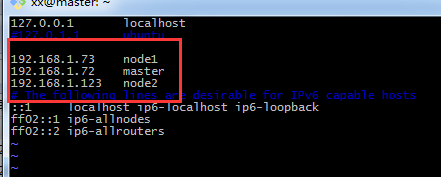
5、修改配置檔案
主要涉及的配置檔案有7個:都在/hadoop/etc/hadoop資料夾下,可以用gedit命令對其進行編輯。如果沒有安裝gedit的話,可以使用vi命令,我使用的是vi命令。
xx@master:~$ sudo cd hadoop/etc/hadoop5.1、配置 hadoop-env.sh檔案–>修改JAVA_HOME
xx@master:~$ sudo vi hadoop-env.sh#The java implementation to use.
export JAVA_HOME=/home/xx/user/java/jdk1.8.0_65
5.2、配置 yarn-env.sh 檔案–>>修改JAVA_HOME
xx@master:~$ sudo vi yarn-env.sh檔案裡面新增內容
# some Java parameters
export JAVA_HOME=/home/xx/user/java/jdk1.8.0_65
5.3、配置slaves檔案–>>增加slave節點
xx@master:~$ vi slave新增主機名,我的slave節點名稱是node1,node2
5.4配置 core-site.xml檔案–>>增加hadoop核心配置(hdfs檔案埠是9000、file:/home/xx/hadoop-/tmp/)
xx@master:~$ vi core-site.xml檔案內容如下:
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
<final>true</final>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/xx/hadoop/tmp</value>
<description>A base for other temporary directories</description>
</property>
<property>
<name>hadoop.proxyuser.spark.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.spark.groups</name>
<value>*</value>
</property>
</configuration>
-- INSERT -- 5.5配置 hdfs-site.xml 檔案–>>增加hdfs配置資訊(namenode、datanode埠和目錄位置)
xx@master:~$ vi hdfs-site.xml檔案內容如下:
<final>true</final>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
<final>true<final>
</property>
<property>
<name>dfs.data.dir</name>
<value>/home/xx/hadoop/data</value>
<final>true</final>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
<final>true</final>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration> 5.6配置 mapred-site.xml 檔案–>>增加mapreduce配置(使用yarn框架、jobhistory使用地址以及web地址)
xx@master:~$ vi mapred-site.xml檔案內容如下:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<final>true</final>
</property>
<property>
<name>mapreduce.jobhistory.adress</name>
<value>master:10020</value>
<final>true</final>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
<final>true</final>
</property>
</configuration>
5.7配置 yarn-site.xml 檔案–>>增加yarn功能
xx@master:~$ vi yarn-site.xml檔案內容如下:
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<final>true</final>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
<final>true</final>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8035</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
</configuration>
5.8將配置好的hadoop檔案copy到另一臺slave機器上
xx@master:~$ scp -r ./hadoop node1:~到節點node1和node2上面檢視,看到Hadoop檔案目錄已經複製過去,這樣slave節點node1,node2已經安裝好了Hadoop-2.6.3。
四、驗證
1、格式化namenode:
xx@master:~/hadoop$ ./bin/hdfs namenode -format出現以下資訊就是格式化成功:
INFO common.Storage: Storage directory /home/xx/hadoop/name has been successfully formatted.2、啟動hdfs:
xx@master:~/hadoop$ ./sbin/start-dfs.sh啟動內容如下:
Starting namenodes on [master]
master: starting namenode, logging to /home/xx/hadoop/logs/hadoop-xx-namenode-master.out
node1: starting datanode, logging to /home/xx/hadoop/logs/hadoop-xx-datanode-node1.out
node2: starting datanode, logging to /home/xx/hadoop/logs/hadoop-xx-datanode-node2.out
Starting secondary namenodes [master]
master: starting secondarynamenode, logging to /home/xx/hadoop/logs/hadoop-xx-secondarynamenode-master.out
[email protected]:~/hadoop/sbin$ jps
4042 Jps
3612 NameNode
3871 SecondaryNameNode在slave節點node1,node2上面會有datanode的程序,如果沒有就是沒有啟動成功。有時候會手誤,導致配置檔案少了節點或者少了‘/’等符號,master節點就會報錯,修改完master節點的檔案之後,要記得slave節點上面也要修改,不然你在master節點上看不到詳細錯誤資訊。
3、停止hdfs
xx@master:~/hadoop/sbin$ ./stop-dfs.sh停止內容如下:
Stopping namenodes on [master]
master: stopping namenode
node2: stopping datanode
node1: stopping datanode
Stopping secondary namenodes [master]
master: stopping secondarynamenode
xx@master:~/hadoop/sbin$ jps
6632 Jps4、啟動yarn:
xx@master:~/hadoop/sbin$ ./start-yarn.sh啟動內容如下:
starting yarn daemons
starting resourcemanager, logging to /home/xx/hadoop/logs/yarn-xx-resourcemanager-master.out
node2: starting nodemanager, logging to /home/xx/hadoop/logs/yarn-xx-nodemanager-node2.out
node1: starting nodemanager, logging to /home/xx/hadoop/logs/yarn-xx-nodemanager-node1.out
[email protected]:~/hadoop/sbin$ jps
7412 Jps
7135 ResourceManager
5、停止yarn:
xx@master:~/hadoop/sbin$ ./stop-yarn.sh停止過程內容如下:
stopping yarn daemons
stopping resourcemanager
node2: stopping nodemanager
node1: stopping nodemanager
no proxyserver to stop
xx@master:~/hadoop/sbin$ jps
7532 Jps
xx@master:~/hadoop/sbin$
6、檢視叢集狀態:
xx@master:~/hadoop/bin$ ./hdfs dfsadmin -reportConfigured Capacity: 245987983360 (229.09 GB)
Present Capacity: 229095870464 (213.36 GB)
DFS Remaining: 229095813120 (213.36 GB)
DFS Used: 57344 (56 KB)
DFS Used%: 0.00%
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
-------------------------------------------------
Live datanodes (2):
Name: 192.168.1.73:50010 (node1)
Hostname: node1
Decommission Status : Normal
Configured Capacity: 194334412800 (180.99 GB)
DFS Used: 28672 (28 KB)
Non DFS Used: 12184432640 (11.35 GB)
DFS Remaining: 182149951488 (169.64 GB)
DFS Used%: 0.00%
DFS Remaining%: 93.73%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Sun Jan 03 22:15:18 EST 2016
Name: 192.168.1.123:50010 (node2)
Hostname: node2
Decommission Status : Normal
Configured Capacity: 51653570560 (48.11 GB)
DFS Used: 28672 (28 KB)
Non DFS Used: 4707680256 (4.38 GB)
DFS Remaining: 46945861632 (43.72 GB)
DFS Used%: 0.00%
DFS Remaining%: 90.89%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Sun Jan 03 22:15:17 EST 2016
xx@master:~/hadoop$ mkdir input9.2、在input建立f1、f2並寫內容
xx@master:~/hadoop$ touch input/f1
xx@master:~/hadoop$ vi ./input/f1
Hello world ,
xx@master:~/hadoop$ touch input/f2
xx@master:~/hadoop$ vi ./input/f2
Hello Hadoop .
xx@master:~/hadoop$9.3、在hdfs建立/tmp/input目錄
xx@master:~/hadoop$ ./bin/hadoop fs -mkdir /tmp
xx@master:~/hadoop$ ./bin/hadoop fs -mkdir /tmp/input
9.4、將f1、f2檔案copy到hdfs /tmp/input目錄
xx@master:~/hadoop$ ./bin/hadoop fs -put input/ /tmp
9.5、檢視hdfs上是否有f1、f2檔案
xx@master:~/hadoop$ ./bin/hadoop fs -ls /tmp/input
Found 2 items
-rw-r--r-- 2 xx supergroup 14 2016-01-03 22:29/tmp/input/f1
-rw-r--r-- 2 xx supergroup 15 2016-01-03 22:29/tmp/input/f29.6、執行wordcount程式
注意空格
xx@master:~/hadoop$ ./bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.3.jar wordcount /tmp/input /output執行內容如下:
16/01/03 22:35:03 INFO client.RMProxy: Connecting to ResourceManager at master/192.168.1.72:8032
16/01/03 22:35:04 INFO input.FileInputFormat: Total input paths to process : 2
16/01/03 22:35:04 INFO mapreduce.JobSubmitter: number of splits:2
16/01/03 22:35:05 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1451877255267_0001
16/01/03 22:35:05 INFO impl.YarnClientImpl: Submitted application application_1451877255267_0001
16/01/03 22:35:05 INFO mapreduce.Job: The url to track the job: http://master:8088/proxy/application_1451877255267_0001/
16/01/03 22:35:05 INFO mapreduce.Job: Running job: job_1451877255267_0001
16/01/03 22:35:16 INFO mapreduce.Job: Job job_1451877255267_0001 running in uber mode : false
16/01/03 22:35:16 INFO mapreduce.Job: map 0% reduce 0%
16/01/03 22:35:25 INFO mapreduce.Job: map 100% reduce 0%
16/01/03 22:35:33 INFO mapreduce.Job: map 100% reduce 100%
16/01/03 22:35:33 INFO mapreduce.Job: Job job_1451877255267_0001 completed successfully9.7、檢視執行出來的檔名
[email protected]:~/hadoop$ ./bin/hadoop fs -ls /output/
Found 2 items
-rw-r--r-- 2 xx supergroup 0 2016-01-03 22:35 /output/_SUCCESS
-rw-r--r-- 2 xx supergroup 33 2016-01-03 22:35 /output/part-r-00000
9.8、檢視結果
xx@master:~/hadoop$ ./bin/hadoop fs -cat /output/part-r-00000 , 1
. 1
Hadoop 1
Hello 2
world 1
至此,搭建結束!歡迎收藏
相關推薦
Hadoop2.6.3版本叢集搭建
一、環境說明 1.機器:三臺虛擬機器 2.Linux版本 cat /proc/version Linux version 3.19.0-25-generic ([email protected]) (gcc version 4.8.2 (U
Hadoop2.7.3-HA 叢集搭建(傳智播客)
前期準備 1 修改Linux主機名 2 修改IP 3 修改主機名和IP的對映關係 /etc/hosts 4 關閉防火牆 5 ssh免登陸 6 安裝JDK,配置環境變數等 叢集規劃 主機名
hadoop-2.6.0.tar.gz + spark-1.5.2-bin-hadoop2.6.tgz的叢集搭建(單節點)(Ubuntu系統)
前言 關於幾個疑問和幾處心得! a.用NAT,還是橋接,還是only-host模式? b.用static的ip,還是dhcp的? 答:static c.別認為快照和克隆不重要,小技巧,比別人靈活用,會很節省時間和大大減少錯誤。 d.重用起來指令碼語言的程式設計,如paython
hadoop-2.6.0.tar.gz + spark-1.6.1-bin-hadoop2.6.tgz的叢集搭建(單節點)(CentOS系統)
前言 關於幾個疑問和幾處心得! a.用NAT,還是橋接,還是only-host模式? b.用static的ip,還是dhcp的? 答:static c.別認為快照和克隆不重要,小技巧,比別人靈活用,會很節省時間和大大減少錯誤。 d.重用起來指令碼語言
CentOS7搭建Hadoop2.6完全分散式叢集環境
3臺主機 192.168.30.207 Master 192.168.30.251 Node1 192.168.30.252 Node2 直接用root裝,省事. 有特殊需求自行add user裝. 以下步驟除非特殊說明,否則每臺都必須配置. 1.rpm -ivh XX
hadoop-2.6.0-cdh5.4.5.tar.gz(CDH)的3節點叢集搭建(含zookeeper叢集安裝)
前言 附連結如下: http://blog.csdn.net/u010270403/article/details/51446674 關於幾個疑問和幾處心得! a.用NAT,還是橋接,還是only-host模式? b.用static的ip,還是dhcp的? 答:stat
hadoop2.8.4+spark2.3.1叢集搭建
1、安裝虛擬機器和linux系統(本文示例Ubuntu16.04 x86_64系統)(此處略過,詳見《安裝linux虛擬機器》) 為了更好使用,記得安裝virtual box的增強功能
Hadoop2.6.0版本號MapReudce演示樣例之WordCount(一)
set pat -m 代碼 分享 ont extends gravity csdn 一、準備測試數據 1、在本地Linux系統/var/lib/hadoop-hdfs/file/路徑下準備兩個文件file1.txt和file2.tx
OSG 3.6.3 版本編譯一些問題
編譯OSG最新版本3.6.3,本以為沒什麼問題(因為曾經便已過N多次),但還是遇到些棘手問題,在這裡做一總結。 1. 編譯出現 osg庫正常編譯,osgDB編譯提示找不到glColor4fv、 glLoadMatrix等基礎函式。 查明原因:gl.
Ubuntu + Hadoop2.7.3偽分佈搭建
1.在virtualbox上設定共享目錄 將 JDK 和 hadoop 壓縮包上傳到Ubuntu: 參考連結:https://blog.csdn.net/qq_38038143/article/details/83017877 2.JDK安裝 在 /usr/loca
CDH 6.0.1 叢集搭建 「Process」
這次搭建我使用的機器 os 是 Centos7.4 RH 系的下面以流的方式紀錄搭建過程以及注意事項 Step1: 配置域名相關,因為只有三臺機器組叢集,所以直接使用了 hosts 的方法: 修改主機名 hostnamectl set-hostname ryze-1.bigdata
CDH 6.0.1 叢集搭建 「After install」
叢集搭建完成之後其實還有很多配置工作要做,這裡我列舉一些我去做的一些。 首先是去把 zk 的角色重新分配一下,不知道是不是我在配置的時候遺漏了什麼在啟動之後就有報警說目前只能檢查到一個節點。去將 zk 角色調整到三個節點。 上一張目前的角色圖 下面我將分別列出各應用的各個簡寫代表的意義: Hbas
3.Zookeeper-叢集搭建
1. 下載 zookeeper 2. 執行 tar -zxvf zookeeper-3.4.13.tar.gz -C /opt/ 解壓 zookeeper 到 /opt 目錄下。
elasticsearch6.3版本linux搭建
搭建過程中遇到的問題,總結一下: 由於6.3版本需要的jdk是1.8的,所以必須升級jdk。 1.cdh版本目前的jdk是1.7,所以再安裝1.8的jdk,需要注意兩個版本如何共存。 2.安裝6.3版本的時候,會遇到的問題: 一:ERROR: bootstrap checks failed
美逛app3.6.3版本更新功能十分強大 淘客大牛評論:美逛越來越牛逼了
淘寶客自2007年誕生至今已有10年之久,經歷了多個發展階段,網站群、QQ群、微博,到現在自媒體和微信群、微信公眾號的玩法,現在做淘寶客對技術的要求越來越低。 【淘寶客的發展史也是網際網路的發展史、電商的發展史】 淘寶客的發展史,也是整個網際網路、電商的發展史的縮影,哪裡能獲取流量和使用者,
CentOS7部署ElasticSearch 5.2.2 版本叢集搭建
CentOS7(CentOS Linux release 7.3.1611 (Core))部署ElasticSearch-5.2.2集群系統規劃 節點名稱 內部IP地址 對外IP地址 軟體版本 no
Hadoop2.0高可用叢集搭建
0、叢集節點分配 Hadoop01: Zookeeper NameNode(active) DataNode NodeManager JournalNode ResourceManager(active) Hadoop02: Zookeeper DataNod
Redis 3.0叢集搭建測試(一)
Redis3.0 最大的特點就是有了cluster的能力,使用redis-trib.rb工具可以輕鬆構建Redis Cluster。Redis Cluster採用無中心結構,每個節點儲存資料和整個叢集狀態,每個節點都和其他所有節點連線。節點之間使用gossip協議傳播資訊以
Redis 3.0叢集搭建測試(二)
四、客戶端叢集命令 叢集 cluster info 列印叢集的資訊 cluster nodes 列出叢集當前已知的所有節點(node),以及這些節點的相關資訊。 節點 cluster meet <ip> <port> 將ip和port所指定的節點
redis4.0.2版本叢集搭建
redhat7下redis原始碼編譯安裝,需要先安裝pcre,openssl等依賴。 yum install openssl-devel pcre-devel 然後下載redis-4.0.2.tar.gz,解壓,進入redis-4.0.2解壓完的目錄,以root使用者執行m