
R中logistics迴歸分析以及K-CV
K倍交叉驗證是對模型的效能進行評估,可以用來防止過擬合,比如對決策樹節點數目的確定或是迴歸模型引數個數地決定等情況。
1.對於一些特殊資料來說,在呼叫glm()方法時候,會出現兩種常見錯誤
Warning: glm.fit: algorithm did not converge
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning messages:
1: glm.fit:演算法沒有聚合
2: glm.fit:擬合機率算出來是數值零或一
針對第一種,一般是因為在迴歸擬合的時候次數少,control=list(maxit=100)修改次數為100即可;
第二種一般就是資料已經分散好了,可以理解為一種過擬合,由於資料的原因,在迴歸係數的優化搜尋過程中,使得分類的種類屬於某一種類(y=1)的線性擬合值趨於大,分類種類為另一 類(y=0)的線性擬合值趨於小。
以鳶尾花資料為例子,
這裡寫程式碼片
testdata$y <- c(1:80)
qplot(pl,y,data =testdata,colour =factor(species));
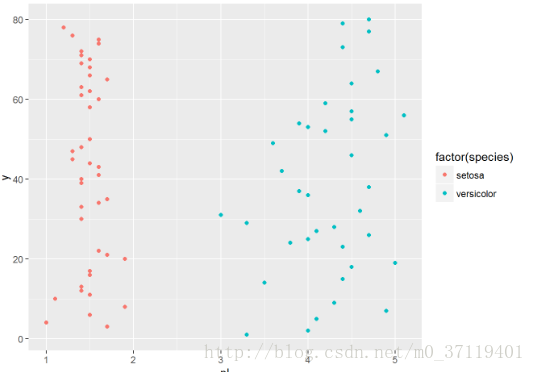
這種情況直接就可以劃分了,無需迴歸分析
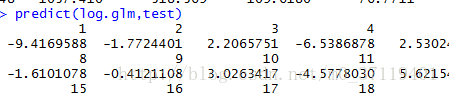
2.建立好迴歸模型,呼叫predict()進行評價,根據包裡面的解釋:

預設是線性預測因子的尺度; 若是
type= “response“<==>“響應”是響應變數的規模。
所以predict(log.glm) 返回的是”β0+β1x1+…βmxm”,而predict(log.glm,typee= “response“)返回的是P值。下圖是我做的認為驗證


3。下來就是通過K倍交叉驗證評價模型好壞了,cv.glm(log.glm,trian,K=10)
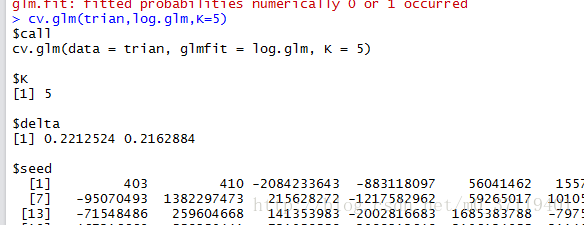
可以得到錯誤率;
4.最後可以畫ROC曲線,由於cv.glm只有錯誤率沒有P值,所以自己編了一個程式作了CV,得到圖為:
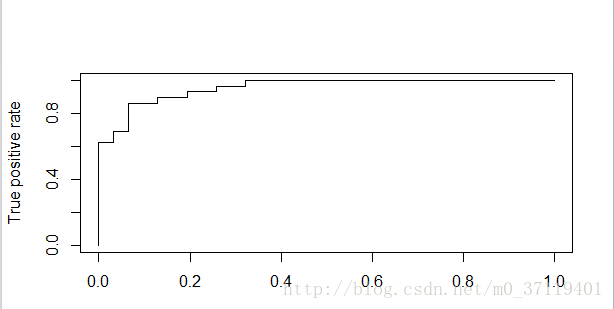
有一個疑問,就是做ROC曲線的時候,是不是把test_data分別帶入相同模型五個不同的引數中得P值(以5倍交叉驗證為例)??
自己也是蠻笨的,為了這個事情搞了一天半,加油吧,感情上是個loser,學習上盼望有點建樹吧。