
Cassandra學習筆記之資料讀取
讀取流程
cassandra的資料可能在Memtable中,也可能在多個SSTable中,每個地方都可能有某個column對應的值,怎麼才能讀取最新的值呢?有必要了解下cassandra讀取資料流程:
(1)判斷rowcache中是否有需要讀取的資料,如果有直接返回;
(2)從Memtable中獲取資料,呼叫getColumnFamily方法獲取該列族的資料;
(3)從多個SSTable中獲取相關列的資料:
a、先通過bloom filter檔案判斷該key是否存在於SSTable中,如果存在,進行第二步;
b、查詢key_cache中是否有當前key,如果有直接定位到key所在SSTable中的位置;
c、 key_cache可不存在,通過index定位到具體位置。
下圖是從SSTable中獲取資料的過程
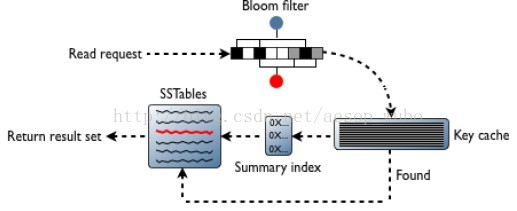
(4)將(2)(3)中的資料進行合併後返回給客戶端。
下圖是cassandra讀取資料示意:

RowCache
RowCache中快取了最近讀取的列資訊,常常將一些熱點資料放入RowCache中,減少了操作磁碟的開銷。Cassandra寫入資料後會同步更新RowCache,保證RowCache中的資料是最新的。
KeyCache
與RowCache不同,KeyCache中快取了最近查詢的row key在SSTable中的位置,每次查詢到row key所在位置後會寫入KeyCache中。如果KeyCache中含有對應key,就不用再通過訪問index檔案了,減少了一次磁碟訪問。二級索引
如果查詢的key並不是一個row key怎麼辦,比如User列族以userId做為row key,每個row key中包含姓名、性別、身份證等,需要按身份證查詢使用者怎麼辦?
需要在身份證這個列上建一個二級索引,二級索引也相當於是一個列族,row key為身份證號碼, 只有一個column名為userId。
先通過二級索引找到key對應的row key,再用row key定位到具體資料。
壓縮機制
cassandra後臺會有一個執行緒,將多個SSTable進行合併,保證同一個列族在一個SSTable檔案中,同時會刪除被標記為墓碑的值(超過 gc_grace_seconds)。
壓縮可以防止檔案碎片,有效提升讀取效率,減少磁碟I/O。
壓縮是在後臺進行的,對客戶端透明,頻繁地進行資料壓縮會導致系統不穩定,因為壓縮本身也會有大量的磁碟I/O,可以在配置檔案中配置壓縮的優先順序,還可以考慮關閉自動壓縮,在系統空閒時手動壓縮。
-