
CPU Cache的優化:解決偽共享問題
無鎖的快取框架: Disruptor
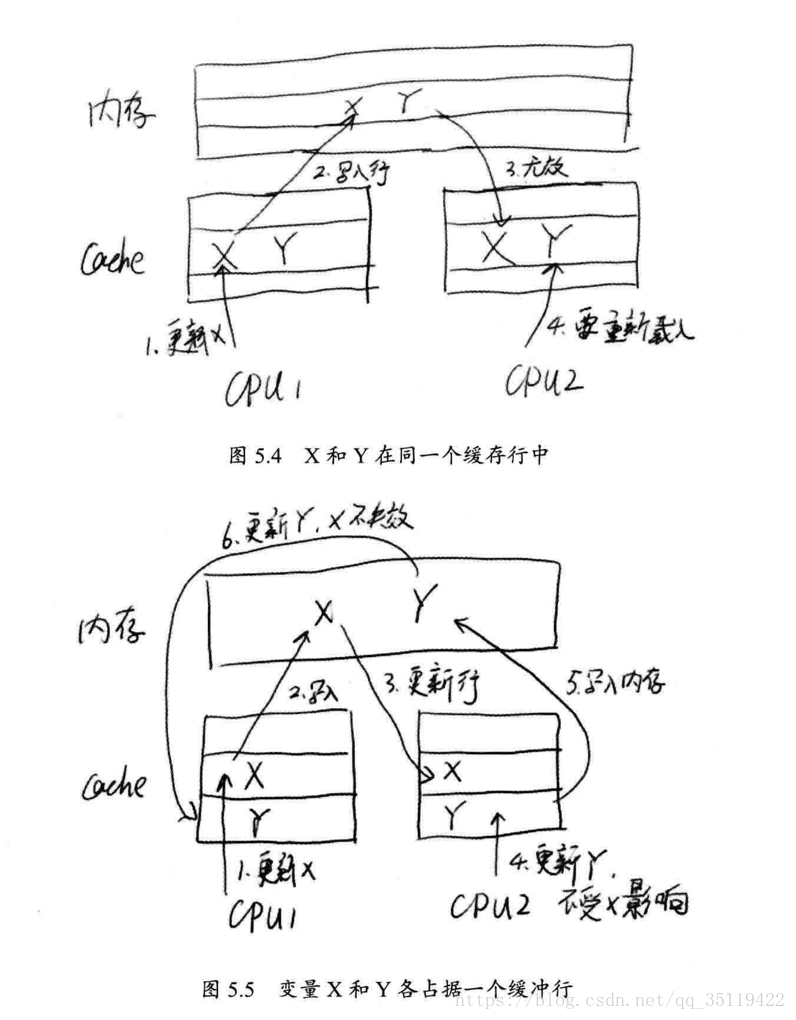
除了使用CAS和提供了各種不同的等待策略來提高系統的吞吐量外。Disruptor大有將優化進行到底的氣勢,它甚至嘗試解決CPU快取的偽共享問題。什麼是偽共享問題呢?我們知道,為了提高CPU的速度,CPU有一個快取記憶體Cache。在快取記憶體中,讀寫資料的最小單位為快取行(Cache Line),它是從主存(memory) 複製到緩字(Cache) 的最小單位,一般為32位元組到128位元組。如果兩個變數存放在一個快取行中時,在多執行緒訪問中,可能會相互影響彼此的效能。如圖5.4所示,假設X和Y在同一個快取行。執行在CPU1上的執行緒更新了X,那麼CPU2上的快取行就會失效,同一行的Y即使沒有修改也會變成無效,導致Cache無法命中。接著,如果在CPU2.上的執行緒更新了Y,則導致CPU1上的快取行又失效(此時,同一行的X又變得無法訪問)。這種情況反反覆覆發生,無疑是一個潛在的效能殺手。如果CPU經常不能命中快取,那麼系統的吞吐量就會急劇下降。為了使這種情況不發生,一-種可行的做法就是在x變數的前後空間都先佔據一定的位置(把它叫做padding吧,用來填充用的)。這樣,當記憶體被讀入快取中時,這個快取行中,只有x一個變數實際是有效的,因此就不會發生多個執行緒同時修改快取行中不同變數而導致變數全體
失效的情況,如圖5.5 所示。
為了實現這個目的,我們可以這麼做:
public class FalseSharing implements Runnable { public final static int NUM_THREADS = 4; // change public final static long ITERATIONS = 50L * 1000L * 1000L; private final int arrayIndex; private static VolatileLong[] longs = new VolatileLong[NUM_THREADS]; static { for (int i = 0; i < longs.length; i++) { longs[i] = new VolatileLong(); } } public FalseSharing(final int arrayIndex) { this.arrayIndex = arrayIndex; } public static void main(final String[] args) throws Exception { final long start = System.currentTimeMillis(); runTest(); System.out.println("duration =" + (System.currentTimeMillis() - start)); } private static void runTest() throws InterruptedException { Thread[] threads = new Thread[NUM_THREADS]; for (int i = 0; i < threads.length; i++) { threads[i] = new Thread(new FalseSharing(i)); } for (Thread t : threads) { t.start(); } for (Thread t : threads) { t.join(); } } @Override public void run() { long i = ITERATIONS + 1; while (0 != --i) { longs[arrayIndex].value = i; } } public final static class VolatileLong { public volatile long value = 0L; public long p1, p2, p3, p4, p5, p6, p7; //comment out } }
這裡我們使用兩個執行緒,因為我的計算機是4核的,大家可以根據自己的硬體配置修改引數NUM_ THREADS (第2行)。我們準備一個數組longs (第6行),陣列元素個數和執行緒數量一致。每個執行緒都會訪問自己對應的longs中的元素(從第42行、第27行和第14行可以看到這一點)。
最後,最關鍵的一點就是VolatileLong。 在第48行,準備了7個long型變數用來填充快取。實際上,只有VolatileLong.value 是會被使用的。而那些pl、p2 等僅僅用於將陣列中第一個VolatileLong.value和第二個VolatileLong.value分開,防止它們進入同一個快取行。
這裡,我使用JDK7 64位的Java虛擬機器,執行, 上述程式,輸出如下:
duration = 1007
這說明系統花費了5秒鐘完成所有的操作。如果我註釋掉第48行,也就是允許系統中兩個
VolatileLong.value放置在同一個快取行中,程式輸出如下:
duration = 4756
很明顯,第48行的填充對系統的效能是非常有幫助的。
**注意:**由於各個JDK版本內部實現不一致,在某些JDK版本中(比如JDK8),會自動優化不使用的欄位。這將直接導致這種padding的偽共享解決方案失效。更多詳細內容大家可以參考後續有關LongAddr的介紹。
Disruptor框架充分考慮了這個問題,它的核心元件Sequence會被非常頻繁的訪問(每次入隊,它都會被加1),其基本結構如下:
class LhsPadding {
protected long p1, p2, p3, p4, p5, p6, p7;
}
class Value extends LhsPadding {
protected volatile long value;
}
class RhsPadding extends Value {
protected long p9, p10, p11, p12, p13, p14, p15;
}
public class Sequence extends RhsPadding {
//省略具體實現
}
雖然在Sequence中,主要使用的只有value。但是,通過LhsPadding和RhsPadding,在這
個value的前後安置了一些佔位空間,
使得value可以無衝突的存在於快取中。
此外,對於Disruptor的環形緩衝區RingBuffer,它內部的陣列是通過以下語句構造的:
this. entries = new object [sequencer . getBufferSize() +2 *BUFFER PAD];
大家注意,實際產生的陣列大小是緩衝區實際大小再加上兩倍的BUFFER PAD。這就相當於在這個陣列的頭部和尾部兩段各增加了BUFFER_ PAD個填充,使得整個陣列被載入Cache時不會受到其他變數的影響而失效。