
貝葉斯分類器的分類及使用範圍
1、 高斯貝葉斯分類器:
條件概率表示如下:
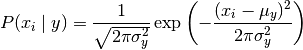
引數  和
和  分別為相應類別的樣本均值和方差,由極大似然估計獲得
分別為相應類別的樣本均值和方差,由極大似然估計獲得
應用範圍:主要應用與連續的樣本
2、多項式貝葉斯分類器哦
應用範圍:文字分類
3:、伯努利貝葉斯分類器
應用範圍:如果樣本中的屬性是二值的可以採用這種分類器
相關推薦
【機器學習實戰】網格搜尋--貝葉斯新聞文字分類器調優
#對文字分類的樸素貝葉斯模型的超引數組合進行網格搜尋 #從sklearn.datasets中匯入20類新聞文字抓取器 from sklearn.datasets import fetch_20newsgroups import numpy as np #抓取新
貝葉斯模型構建分類器的設計與實現
作者:白寧超 2015年9月29日11:10:02 摘要:當前資料探勘技術使用最為廣泛的莫過於文字挖掘領域,包括領域本體構建、短文字實體抽取以及程式碼的語義級構件方法研究。常用的資料探勘功能包括分類、聚類、預測和關聯四大模型。本文針對四大模型之一的分類進行討論。分類演算法包括迴歸、決策樹、支援
(資料探勘-入門-8)基於樸素貝葉斯的文字分類器
主要內容: 1、動機 2、基於樸素貝葉斯的文字分類器 3、python實現 一、動機 之前介紹的樸素貝葉斯分類器所使用的都是結構化的資料集,即每行代表一個樣本,每列代表一個特徵屬性。 但在實際中,尤其是網頁中,爬蟲所採集到的資料都是非結構化的,如新聞、微博、帖子等,如果要對對這一類資料進行分類,應該怎麼辦
(三)樸素貝葉斯運用——文字分類
1、貝葉斯理論 當我們有樣本(包含特徵和類別)的時候,我們非常容易通過 p(x)p(y|x)=p(y)p(x|y) p ( x
數學之美:馬爾科夫鏈的擴充套件-貝葉斯網路 詞分類
前面介紹的馬爾科夫鏈是一種狀態序列,但在實際中,各個事物之間不僅使用鏈序列起來的,而是互相交叉,錯綜複雜。因此通過各個事物之間的聯絡,可以將馬爾科夫鏈推廣至圖論中。 沒想到貝葉斯網路還可以用於詞分類。在前面我們介紹到通過使用SVD可以對文字進行分類,如果把文字和關鍵詞的
機器學習學習筆記 第十六章 基於貝葉斯的新聞分類
利用貝葉斯分類器進行文字分類 考慮情況 1 對於文字分析,首先我們應該先利用停用詞語料庫對部分大量出現的停用詞進行遮蔽,可以百度直接搜停用詞進行下載 我們對於經常出現的詞,有可能是一個不太重要的詞,比
【演算法】樸素貝葉斯法之分類演算法
樸素貝葉斯法之分類演算法 說明 本文只是對於樸素貝葉斯法的其中的一個分類演算法的學習。參考來源《統計學習方法》。 一、 輸入 訓練資料 T={(x1,y1),(x2,y2),...(
第4章 樸素貝葉斯(文字分類、過濾垃圾郵件、獲取區域傾向)
貝葉斯定理: P ( c
python資料分析:內容資料化運營(下)——基於多項式貝葉斯增量學習分類文字
案例背景及資料 見上一篇 案例實現 匯入模組 import re import tarfile import os import numpy as np from bs4 import BeautifulSoup from sklearn.feature_extracti
sklearn——樸素貝葉斯分文字分類2
使用sklearn中的tf-idf向量選擇器對向量進行選擇,是一個特徵選擇的過程 程式碼: # 從sklearn.feature_extraction.text裡分別匯入TfidfVectorizer。 from sklearn.feature_extraction.tex
樸素貝葉斯演算法實現分類以及Matlab實現
開始 其實在學習機器學習的一些演算法,最近也一直在看這方面的東西,並且嘗試著使用Matlab進行一些演算法的實現。這幾天一直在看得就是貝葉斯演算法實現一個分類問題。大概經過了一下這個過程: 看書→演算法公式推演→網上查詢資料→進一步理解→蒐集資料集開始嘗
樸素貝葉斯演算法實現分類問題(三類)matlab程式碼
資料簡介 本訓練資料共有625個訓練樣例,每個樣例有4個屬性x1,x2,x3,x4,每個屬性值可以取值{1,2,3,4,5}。 資料集中的每個樣例都有標籤"L","B"或"R"。 我們在這裡序號末尾為1的樣本當作測試集,共有63個,其他的作為訓練集,共有562個。 下
基於樸素貝葉斯的新聞分類
貝葉斯理論 在我們有一大堆樣本(包含特徵和類別)的時候,我們非常容易通過統計得到 p(特徵|類別) . 大家又都很熟悉下述公式: #coding: utf-8 import os import time import random import
jieba和樸素貝葉斯實現文字分類
#盜取男票年輕時候的程式碼,現在全給我教學使用了,感恩臉#分類文件為多個資料夾 資料夾是以類別名命名 內含多個單個文件#coding: utf-8 from __future__ import print_function, unicode_literals import
文字處理之貝葉斯垃圾郵件分類
本文所講解的是如何通過Python將文字讀取,並且將每一個文字生成對應的詞向量並返回. 文章的背景是將50封郵件(包含25封正常郵件,25封垃圾郵件)通過貝葉斯演算法對其進行分類. 主要分為如下幾個部分: ①讀取所有郵件; ②建立詞彙表; ③生成沒封郵件對應的詞
基於的樸素貝葉斯的文字分類(附完整程式碼(spark/java)
本文主要包括以下內容: 1)模型訓練資料生成(demo) 2 ) 模型訓練(spark+java),資料儲存在hdfs上 3)預測資料生成(demo) 4)使用生成的模型進行文字分類。 一、訓練資料生成 spark mllib模型訓練的輸入資料格
模式分類與應用-貝葉斯垃圾郵件分類
垃圾郵件分類 任務要求 使用檔案spambase.data中的資料,訓練垃圾郵件分類的貝葉斯分類器,並測試分類效能。 資料初步分析 spambase.data是一個垃圾郵件的資料庫,來自於惠普公司的Hewlett Packard L
乾貨 | 基於貝葉斯推斷的分類模型& 機器學習你會遇到的“坑”
本文轉載自公眾號“讀芯術”(ID:AI_Discovery)本文3153字,建議閱讀8分鐘。本文
樸素貝葉斯-新聞分類
樸素貝葉斯分類器的構造基礎是基於貝葉斯定理與特徵條件獨立假設的分類方法,與基於線性假設的模型(線性分類器和支援向量機分類器)不同。最為廣泛的兩種分類模型是決策樹模型(Decision Tree Model)和樸素貝葉斯模型(Naive Bayesian Model,NBM
機器學習之貝葉斯演算法影象分類
資料集:資料集採用Sort_1000pics資料集。資料集包含1000張圖片,總共分為10類。分別是人(0),沙灘(1),建築(2),大卡車(3),恐龍(4),大象(5),花朵(6),馬(7),山峰(8),食品(9)十類,每類100張,(資料集可以到網上下載)