
【譯】DeepLab V2:基於深度卷積網、孔洞演算法和全連線CRFs的語義影象分割
【譯】DeepLab:基於深度卷積網、孔洞演算法和全連線CRFs的語義影象分割
Author: Liang-Chieh Chen
摘要
在這項工作中有三個主要貢獻具有實質的實用價值:
第一,使用上取樣濾波器進行卷積,或者將“多孔 convolution”應用在密集預測任務。多孔卷積允許我們在DCNN計算特徵響應時明確地控制響應的解析度。能有效地擴大濾波器的視野以併入更多的上下文而不增加引數的數量或計算量。
第二,提出多孔空間金字塔池化(ASPP),在多尺度上魯棒地分割物體。ASPP使用多個取樣率和有效視野的濾波器來探測進入的卷積特徵層,從多尺度捕獲物體以及影象上下文。
第三,通過合併DCNN和概率圖模型的方法,增強物體邊界的定位。通常在DCNN中採用最大池化和下采樣方法實現不變性,但對定位精度有一定的限制。我們通過將最終的DCNN層的響應與完全連線的條件隨機場(CRF)相結合來克服這一點,定性和定量地提高定位效能。我們提出的“DeepLab”系統在PASCAL VOC-2012語義影象分割任務中達到了新的最新技術,在測試集中達到79.7%的mIOU,並將結果推廣到另外三個資料集:PASCAL-Context,PASCAL-Person Part和Cityscapes。所有程式碼已經開源。
引言
深層卷積神經網路(DCNNs)將計算機視覺系統的表現推向了高層應用問題,包括影象分類和物體檢測,其中DCNN以端對端方式進行訓練,其結果比依靠手工特徵的系統的效能好得多。這一成功是基於DCNN對區域性影象變換的內在不變性,從而學習越來越多的抽象資料表示。這種不變性對於分類任務是需要的,但是會影響密集的預測任務,例如語義分割,不需要抽象的空間資訊。
DCNN應用於語義影象分割中的三個挑戰:(1)下降的特徵解析度(2)多尺度下的物體的存在(3)由於DCNN不變性而下降的定位精度。
挑戰一:是由連續DCNN層中的最大池化和下采樣(滑動步長)的重複組合引起的。當DCNN以完全卷積方式使用時,會導致特徵圖的空間解析度顯著降低。為了克服這一障礙並有效地產生更密集的特徵圖,我們從DCNN的最後幾個最大池化層中取消下采樣操作,而在隨後的卷積層中加入上取樣濾波器,以較高取樣率計算特徵圖。上取樣濾波器相當於在非零濾波抽頭之間插入孔。這種技術在訊號處理方面有著悠久的歷史,最初是用於有效/高效的計算非抽取的小波變換。我們用“多孔卷積
挑戰二:由物體的多尺度狀態引起的。處理這種情況的一個標準方法是向DCNN提供相同影象的重縮放版本,然後聚合特徵或分數圖。這種方法確實提高了系統的效能,但要對所有DCNN層的多尺度輸入影象計算特徵響應,開銷很大。相反,受空間金字塔池化的啟發,我們提出了一種高效地計算方案:在卷積之前以多個取樣率重新取樣特定的特徵層。這相當於用具有互補的有效視野的多個濾波器探測原始影象,從而在多個尺度上捕獲物體以及有用的影象上下文。與實際重新取樣特徵不同,我們有效地使用具有不同取樣率的多個並行的多孔卷積層
挑戰三:涉及到以物體為中心的分類器所需要的空間變換的不變性,固有地限制了DCNN的空間精度。一種減輕此問題的方法是當計算最終的分割結果時使用跳躍層(skip-layers)從多個網路層提取“hyper-column”/超列特徵。我們探索出一種替代方法,並證明這種方法是非常有效的。特別地,通過使用全連線的條件隨機場(CRF)來提高模型捕獲精細細節的能力。CRF廣泛用於語義分割,將從畫素和邊緣或超畫素的區域性互動中捕獲低階資訊的多路分類器計算得到的類分數結合起來。雖然建模分段依賴性[26], [27], [28]和/或分割用的高階依賴性[29, 30, 31, 32, 33]等通過提高複雜度的工作陸續被提出,我們使用[22]提出的全連線的配對CRF,計算更有效,並能夠捕獲細微的邊緣細節,同時也適應長距離的依賴。[22]中的模型很大程度上提高了基於增強畫素級分類器的效能。本文展示了當與基於DCNN的畫素級別分類器相結合時,有更好的結果。
所提出的DeepLab模型的高階示意圖如圖1所示。在影象分類任務中訓練的深度卷積神經網路(VGG-16 [4]或ResNet-101 [11])旨在通過
(1)將所有全連線的層轉換為卷積層(即,全卷積網路[14])
(2)通過多孔卷積層提高特徵解析度,允許我們每8個畫素而不是原始網路中每32個畫素計算特徵響應。然後採用雙線性插值對得分圖進行8倍上取樣以達到原始影象解析度,從而產生全連線的CRF的輸入,再優化分割結果
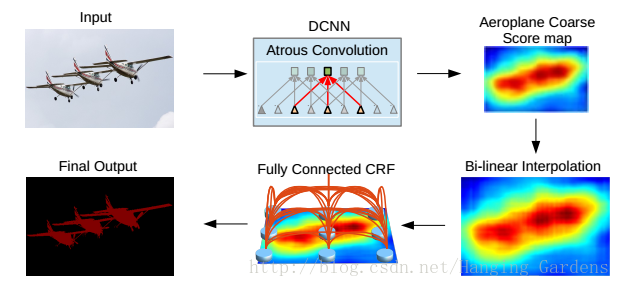
圖1:模型圖。使用VGG-16或ResNet-101的深卷積神經網路以全卷積方式使用,使用多孔卷積來降低訊號下采樣的程度(從32x下降到8x)。雙線性插值階段將特徵圖放大到原始影象解析度。然後應用全連線的CRF來細化分割結果以更好地捕獲物體邊界。
從實際的角度來看,DeepLab系統的三個主要優點是:
- 速度:憑藉多孔卷積,我們的密集DCNN在NVidia Titan X GPU上以8 FPS執行,同時全連線CRF的Mean Field Inference在CPU上需要0.5秒
- 準確性:我們在幾個具有挑戰性的資料集上取得最好結果,包括PASCAL VOC 2012語義分割基準[34],PASCAL-Context[35],PASCAL-Person-Part[36]和Cityscapes[37]]
- 簡單性:系統由兩個非常完善的模組,DCNN和CRF級聯組成
本文中提到的DeepLab系統與原始會議中釋出的第一個版本[38]相比,具有幾個改進。新版本可通過多尺度輸入處理[17],[39],[40]或者所提出的ASPP技術來更好地分割多尺度的物體。通過採用最新的ResNet [11]影象分類DCNN構建了DeepLab的殘差網路變體,與原始基於VGG-16的模型相比,實現了更好的語義分割效能[4]。最後對多個模型變體進行了更全面的實驗評估,不僅在PASCAL VOC 2012基準測試中,還針對其他具有挑戰性的任務得出了最好的結果。用Caffe框架來實現這些方法[41]。在http://liangchiehchen.com/projects/DeepLab.html 上分享了程式碼和模型。
相關工作
在過去十年中開發的大多數成功的語義分割系統都依賴於手工設計特徵的單一分類器(如Boosting[24, 42],Random Forests[43]或Support Vector Machines[44])的結合。通過從上下文[45]和結構化預測技術[22, 26, 27, 46]中收集更豐富的資訊已經實現了顯著的改進,但是這些系統的效能一直受到特徵的有限表達力的影響。在過去幾年中,深度學習從影象分類中的迅速突破轉移到了語義分割任務中。由於這個任務涉及分割和分類,所以核心問題是如何組合這兩個任務。
用於語義分割的基於DCNN的第一類系統通常採用自下而上的級聯的影象分割,然後是基於DCNN的區域分類。例如[47],[48]提供的邊界框候選和掩碼區域在[7]和[49]中被用作DCNN的輸入,整合形狀資訊給分類過程。類似地,[50]的作者採用超畫素表示。即使這些方法可以通過良好的分割得到的尖銳邊界受益,但是它們也無法從任何錯誤中恢復。
第二類作品依賴於使用卷積計算的DCNN特徵進行密集影象標註,並將它們與獨立獲得的分割結合在一起。其中[39]首先在多個影象解析度下應用DCNN,然後採用分割樹來平滑預測結果。最近,[21]提出使用skip層並連線DCNN內的中間特徵圖進行畫素分類。此外,[51]建議按區域性候選池化中間特徵圖。這些方法仍然採用從DCNN分類器結果分離的分割演算法,因此會過早承擔決策風險。
第三類作品使用DCNN直接提供密集的類別級的畫素標籤,以至於可以完全丟棄分割。[14],[52]的免分割方法直接將DCNN以完全卷積的方式應用於整個影象,將DCNN的最後全連線層轉換為卷積層。為了處理引言中概述的空間定位問題,[14]對來自中間特徵圖的分數進行上取樣並連線,[52]通過將粗略結果傳播到另一個DCNN,從粗到細優化分預測結果。我們在這些作品的基礎上,通過對特徵解析度進行控制來擴充套件它們,引入多尺度池化技術並將[2密集連線的CRF整合在DCNN之上。我們發現它產生了明顯地更好的分割結果,特別是在物體邊界處。DCNN和CRF的組合當然不是新的,但以前的工作只嘗試了局部連線的CRF模型。具體來說,[53]使用CRF作為基於DCNN的重排系統,而[39]將超畫素視為區域性配對的CRF節點,並使用圖切割進行離散推理。因此,它們的模型受限於超畫素計算中的錯誤或忽略的長距離依賴關係。我們將每個畫素看作是由DCNN接收一元勢能的CRF節點。重要的是,[22]的全連線CRF模型中的高斯CRF勢能可以捕獲長距離依賴性,同時該模型適合於快速平均場推理。我們注意到,傳統的影象分割任務已經廣泛研究了平均場推理[54],[55],[56],但是這些較舊的模型通常限於短距離連線。在某些獨立工作中,[57]使用了非常相似的密集連線的CRF模型來改進材料分類問題的DCNN結果。然而,[57]的DCNN模組僅通過稀疏點監督進行訓練,而不是每個畫素的密集監督。
多個團體取得了重大進展,大大提高了PASCAL VOC 2012語義分割基準的水平,反映在基準測試排行榜的高水平論文,如[17],[40],[58],[59],[60] ],[61],[62],[63]。http://host.robots.ox.ac.uk:8080/leaderboard/displaylb.php?challengeid=11&compid=6。有趣的是,大多數表現好的方法都採用了DeepLab系統的一個或兩個關鍵點:多孔卷積,用於通過全連線的CRF進行有效的密集特徵提取和細化原始DCNN分數。我們在下面概述一些最重要和有趣的進展。
結構化預測的端到端訓練最近在幾項相關工作中得到探討。雖然我們使用CRF作為後端處理方法,[40],[59],[62],[64],[65]已經成功地進行了DCNN和CRF的聯合學習。特別地,[59],[65]展開了CRF均值場推理步驟,將整個系統轉換成端對端可訓練的前饋網路,而[62]用卷積濾波器近似估計密集CRF平均值場推理的一次迭代。[40],[66]另一個富有成效的方向追求,通過學習配對的DCNN-CRF條件,以更巨大的計算代價大大提高了效能。在另一個不同的方向,[63]將平均場推斷中使用的雙邊濾波模組替換為更快的域變換模組[67],提高了整個系統的速度並降低了儲存器要求,[18],[68]將語義分割與邊緣檢測相結合。
基於弱監督的論文有許多,放寬畫素級語義標註到整個訓練集[58],[69],[70],[71],得到比弱監督的預訓練的DCNN系統更好的結果,如[72]。在另一個研究領域,[49],[73]追求實體分割,同時處理物體檢測和語義分割。
我們所說的多孔卷積,最初是為了高效計算[15]中的多孔變換/非抽取小波變換。感興趣的讀者可參考[74]。多孔卷積也與多比例訊號處理中的“nobel identities”(多采樣率系統中用於將抽取器或插值器移動到合適位置)密切相關,多重比例訊號處理建立在輸入訊號和濾波器取樣率相互作用上,如[75]。很多作者在DCNNs中使用相同的操作進行更密集的特徵提取,如[3],[6],[16]。除了簡單的增強解析度,多孔卷積允許我們擴大濾波器的視野,以納入更多的上下文內容,[38]中已經表明這是有益的。這種方法已經被[76]進一步改進,他們採用一系列取樣率不斷增大的多孔卷積來聚合多尺度上下文。這裡提出的用於捕獲多尺度物體和上下文的多孔空間金字塔池化方案,也採用了具有不同取樣率的多個多孔卷積層,但是它們是並行排列而不是序列的。有趣的是,在更廣泛的任務中,例如物體檢測[12],[77],實體分割[78],視覺問答[79]和光流[80],也採用了多孔卷積技術。
方法
用於密集特徵提取和視野擴充套件的多孔卷積
已經證明能以全卷積方式部署DCNN來簡單而成功地解決語義分割或其他密集預測任務[3],[14]。然而,這些網路上連續層的max-pooling和striding的重複組合顯著減小了最終的特徵圖的空間解析度,典型地最新的DCNN中沿每個方向32倍減小。[14]的補救方法是使用“解/反捲積”層,但需要額外的記憶體和時間。
我們使用[15]中的多孔變換/非抽取小波變換的高效計算而開發的多孔卷積,並且在DCNN上下文中使用,如[3],[6],[16]。該演算法允許我們以任何期望的解析度計算任何層的響應。一旦網路訓練完成,它可以應用於post-hoc,也可以與訓練無縫整合。
首先考慮一維訊號,將具有長度為
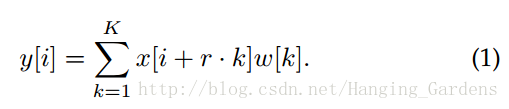
比例
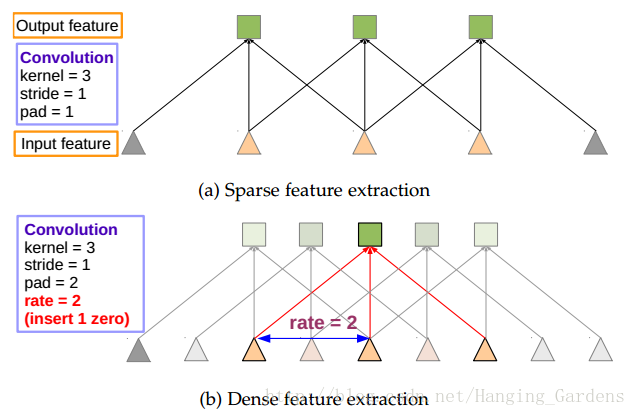
圖2:1-D中多孔卷積圖示。(a)在低解析度輸入特徵圖上具有標準卷積的稀疏特徵提取。(b)以比例
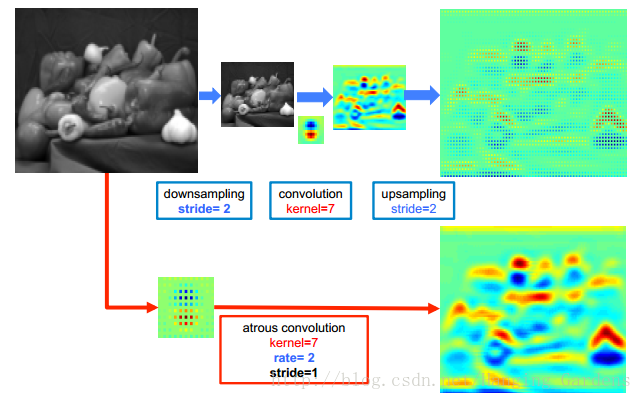
圖3:2維多孔卷積的圖示。頂行:在低解析度輸入特徵圖上具有標準卷積的稀疏特徵提取。底行:比例
我們通過圖3中的一個簡單的例子來說明演算法在2維中的操作:給定一個影象,我們假設我們首新行將解析度降低2倍的下采樣操作,然後再執行核的卷積,這裡是垂直高斯導數濾波器。如果在原始影象座標中植入了所得到的特徵圖,僅能在影象位置的1/4處獲得響應。相反,如果我們將全解析度影象與一個帶有孔的濾波器進行卷積,我們可以計算所有影象位置的響應,其中我們用因子2的上取樣原始濾波器,並在濾波器值之間引入零點。雖然有效濾波器的尺寸增加了,但是我們只需要考慮非零的濾波器值,因此濾波器引數的數量和每個位置的運算元保持不變。所得到的方案允許我們簡單且明確地控制神經網路特徵響應的空間解析度。
在DCNN的上下文中,可以在層次鏈中使用多孔卷積,允許我們以任意高解析度計算最終的DCNN網路響應。例如,為了對VGG-16或ResNet-101網路中計算出的特徵響應的空間密度加倍,我們發現最後的池化層或者卷積層降低了解析度(分別為“pool5”或“conv5_1”),那麼我們設定其步幅為1以避免訊號抽取,並用比例
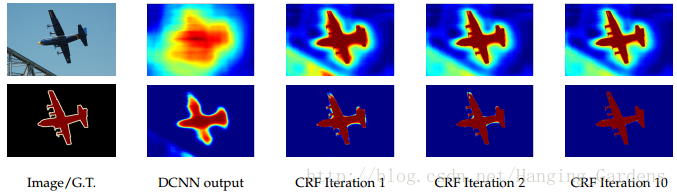
圖5:飛機的分數圖(softmax函式前的輸入)和置信圖(softmax函式的輸出)。提供了每次平均場迭代後的得分圖(第一行)和置信圖(第二行)。DCNN層的最後層的輸出用作平均場推斷的輸入。
多孔卷積還允許我們在任何DCNN層任意放大濾波器的視野。最新的DCNN採用空間小的卷積核心(通常為3×3),以便保持計算和可控的引數數量。比例
關於實現,有兩種方法來有效的執行多孔卷積。第一個是通過插入空洞(零)來隱含地對濾波器進行上取樣,或等效稀疏地對輸入特徵圖進行取樣。如[15]在早期工作中,[6],[38],[76]在Caffe框架內,通過向im2col函式(從多通道特徵圖中提取向量化塊)新增稀疏取樣底層特徵圖實現了這一點。第二種方法,最初由[82]提出並在[3],[16]中使用,它通過用一個與多孔卷積比例
使用多孔空間金字塔池的多尺度影象表示
DCNN已經給出顯著地表示尺度的能力,只需通過對含有多尺度物體的資料集進行訓練。然而,明確的物體尺度可以提高DCNN成功處理大小物體的能力[6]。
我們已經嘗試了兩種方法來處理語義分割中的尺度變換。第一種方法相當於標準多尺度處理[17],[18]。我們通過共享相同引數的並行DCNN分支從多個原始影象(本文取3個)的不同尺度版本中提取DCNN得分圖。為了產生最終的結果,我們對從並行DCNN分支到原始影象解析度之間的特徵圖進行雙線性插值,並融合它們,在不同尺度上獲取每個位置的最大響應。我們在訓練和測試期間都這樣做。多尺度處理顯著提高了效能,但代價是在輸入影象的多個尺度上對所有DCNN層計算特徵響應。
第二種方法受[20]的R-CNN空間金字塔池化方法成功的啟發,它指出在任意尺度的區域可以用從單個尺度中重取樣提取的卷積特徵進行準確有效地分類。我們已經實現了他們的方案的一個變體,用不同取樣率的多個並行的多孔卷積層。對每個取樣率提取的特徵進一步在單獨的分支中進行處理,並進行融合以產生最終結果。所提出的“多孔空間金字塔池化”(DeepLab-ASPP)方法泛化了DeepLab-LargeFOV變體,如圖4所示。
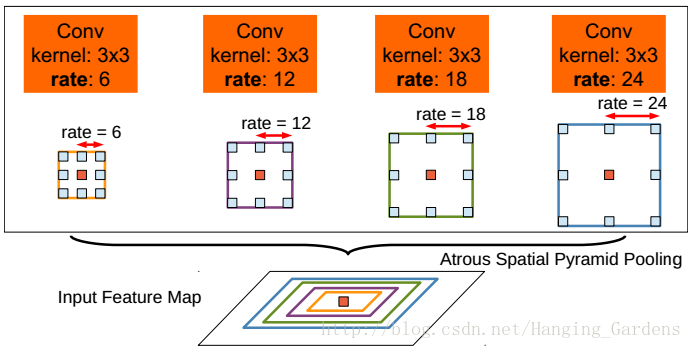
圖4:多孔金字塔池化(ASPP)。為了分類中心畫素(橙色),ASPP通過採用不同比例的多個並行濾波器開發多尺度特徵。視野有效區以不同的顏色顯示。
用於精確邊界恢復的全連線條件隨機場的結構化預測
定位精度與分類效能之間的權衡似乎在DCNN中是固有的:具有多個最大池化層的更深層次的模型在分類任務中被證明是非常成功的,然而頂層節點增加的不變性和大的感受野只能產生平滑的響應。如圖5所示,DCNN得分圖可以預測物體的存在和粗略位置,但不能真正描繪其邊界。
以前的工作從兩個方向來解決這個定位挑戰。第一種方法是利用卷積網路中多層資訊,以更好地估計物體邊界[14],[21],[52]。第二個是採用超畫素表示,將定位任務委託給低層分割方法[50]。
我們通過耦合DCNN的識別能力和全連線的CRF的細粒度定位精度來尋求替代方向,並且在解決定位挑戰方面非常成功,產生了精確的語義分割結果並在一定程度上恢復物體邊界細節,遠遠超出現有方法。
傳統上,條件隨機場(CRF)被用於平滑噪聲分割圖[23],[31]。通常,這些模型耦合鄰近節點,有利於對空間鄰近畫素分配相同的標籤。定性地講,這些短距離CRF的主要功能是減弱基於區域性手工設計特徵的弱分類器的錯誤預測。
與這些弱分類器相比,現代DCNN體系結構如本文中使用的結構得到分數圖和性質不同的語義標籤預測。如圖5所示,分數圖通常相當平滑併產生均勻的分類結果。在這個情況下,使用短距離的CRFs可能是不好的,因為我們的目標應該是恢復詳細的區域性結構,而不是進一步平滑。使用區域性CRF關聯的反差靈敏勢[23]可以潛在地改善定位,但仍然錯過thin-structures/細小的結構,還需要解決高昂的離散優化問題。
為了克服短距離CRF的這些限制,將我們的系統與[22]的全連線的CRF模型相結合。模型採用能量函式如下:
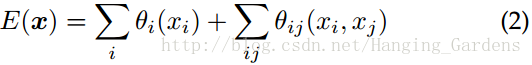
其中
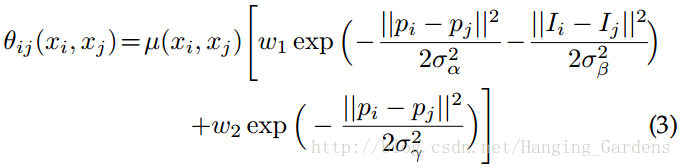
其中如果
關鍵的是,這個模型適合於有效的近似概率推理[22]。在全分解的平均場近似值
實驗結果
我們調整了ImageNet預訓練的VGG-16或ResNet-101網路的模型權重,以[14]的步驟將它們應用在語義分割任務中。我們替換了最後一層的1000路ImageNet分類器,其分類器具有與我們任務中的語義類數(包括背景)。我們的損失函式是DCNN輸出圖(與原始影象相比,被8倍子取樣)中每個空間位置的交叉熵項的總和。所有位置和標籤在整體損失函式中均勻加權(除了未標記的畫素被忽略)。我們的目標是真實值標籤(8倍子取樣)。我們通過[2]中的標準SGD演算法來優化所有網路層中目標函式的權重。在設定CRF引數時,假設DCNN一元項是固定的,我們將DCNN和CRF訓練階段分開進行。
我們在四個具有挑戰性的資料集上評估提出的模型:PASCAL VOC 2012,PASCAL-Context,PASCAL-Person-Part和Cityscapes。我們首先報告了我們在PASCAL VOC 2012上的第一版[38]的主要結果,得到所有資料集的最新結果。
PASCAL VOC 2012
資料集: 有20類前景目標類和1個背景類;
原始資料集:包含1464(train), 1449(val), 1456(test)畫素級的標註影象分別用於訓練、驗證和測試;
增強資料集:由[85]提供的額外標註產生10582(training)的訓練影象;
效能評估:用21類的平均畫素交疊率(mIoU)來衡量
第一版的結果
採用ImageNet預訓練的VGG-16網路,細節參考3.1。使用20個影象的patch,初始學習率為0.001(在分類器最後層為0.01),每2000次迭代學習率乘以0.1。0.9的動量和0.0005的權重衰減。
DCNN在增強集上訓練微調後,我們以[22]的方式交叉驗證了CRF引數。使用預設值
【譯】DeepLab:基於深度卷積網、孔洞演算法和全連線CRFs的語義影象分割
Author: Liang-Chieh Chen
摘要
在這項工作中有三個主要貢獻具有實質的實用價值:
第一,使用上取樣濾波器進行卷積,或者將“多孔 convolut
謝絕任何不通知本人的轉載,尤其是抄襲。
Abstract
1. Introduction
2. ROAD MAP
3. Projects in consulting
4. Return to the university
5. The
謝絕任何不通知本人的轉載,尤其是抄襲。
Abstract
1. Introduction
2. ROAD MAP
3. Projects in consulting
4. Return to the university
5. The
謝絕任何不通知本人的轉載,尤其是抄襲。
Abstract
1. Introduction
2. ROAD MAP
3. Projects in consulting
4. Return to the university
5. The
關鍵點
dart是單執行緒語言
同步程式碼會阻塞你的程式
使用Future物件來執行非同步操作
在async函式裡使用await關鍵字來掛起執行知道一個Future操作完成
或者使用then()方法
在async函式裡使用try-catch表示式捕獲錯誤
或者
原文作者:Tyler McGinnis
原文連結:tylermcginnis.com/ultimate-gu…
文中部分連結可能需要梯子。
歡迎批評指正。
說出來可能嚇你一跳,在我看來,理解Javascript的最重要最基本的思路就是理解執行上下文。吃透了執行上下文,你就能更好地學
作者:白寧超
2017年5月18日17:51:37
摘要:關於查重系統很多人並不陌生,無論本科還是碩博畢業都不可避免涉及論文查重問題,這也對學術不正之風起到一定糾正作用。單位主要針對科技專案申報稽核,傳統的方式人力物力比較大,且伴隨季度性的繁重工作,效率不高。基於此,單位覺得開發一款可以達到實用的
本文翻譯自2018年最熱門的Python金融教程 Python For Finance: Algorithmic Trading。
這篇 Python 金融教程向您介紹演算法交易等內容。
技術已成為金融領域的一項資產:金融機構已不僅僅是單純的金融機構了,它正向著技術公司演進。
資產證券化作為一種新的投融資工具,可以完善資本市場的結構,改善資源配置,提高資金金運作效率,從而促進經濟結構的優化,實現盤活存量量、為實體經濟服務的目的。
作者 | 泛融科技
官網 | w
原文地址:(需要FQ)https://ordina-jworks.github.io/iot/2018/09/28/3D-Printing-Intro.html
文章發表日期:2018-09-28
第一次嘗試翻譯這麼一篇大且長的文章,如果讀著感覺不太通常或者有錯誤的地方,請多包涵..
介紹
3D列印是一
原文標題:Macros in Rust: A tutorial with examples
原文連結:https://blog.logrocket.com/macros-in-rust-a-tutorial-with-examples/
公眾號: Rust 碎碎念
翻譯 by: Praying
在
原文標題:Macros in Rust: A tutorial with examples
原文連結:https://blog.logrocket.com/macros-in-rust-a-tutorial-with-examples/
公眾號: Rust 碎碎念
翻譯 by: Praying
Ru img 對比 images 兩個 避免 pytho lam 其中 src 這個項目主要涉及到兩個網絡,其中卷積神經網絡用來提取圖片表達的情緒,提取出一個二維向量。
網絡結構如圖:
詞向量采用預訓練的glove模型,d=50,其他信息包括了圖片的“空曠程度”、亮度、
目錄
一、jdk
一、jdk
輸入命令,可以看到jdk版本是:1.8.0_181:
cd ~
java -version
二、Tomcat
(1)切換到Tomcat安裝目錄的bin目錄下:
cd /usr/local/tomcat8-dev/b
map將一個RDD中的每個資料項,通過map中的函式對映變為一個新的元素。
輸入分割槽與輸出分割槽一對一,即:有多少個輸入分割槽,就有多少個輸出分割槽。
hadoop fs -cat /tmp/lxw1234/1.txthello worldhello sparkhello 理論 cdn image 深度 大名 end 但我 github 圖像識別 基於圖卷積網絡的圖深度學習
先簡單回顧一下,深度學習到底幹成功了哪些事情!
深度學習近些年在語音識別,圖片識別,自然語音處理等領域可謂是屢建奇功。ImageNet:是一個計算機視
主體內容:作為當前的一大熱門,語音識別在得到快速應用的同時,也要更適應不同場景的需求,特別是對於智慧手機而言,由於元器件的微型化導致對於語音處理方面的器件不可能很大,因此單通道上的語音分離技術就顯得極為重要,而語音分離正是語音識別的前端部分。而傳統的技術由於資
基於深度卷積神經網路的影象去噪方法
摘要:影象去噪在影象處理中仍然是一個具有挑戰性的問題。作者提出了一種基於深度卷積神經網路(DCNN)的影象去噪方法。作者設計的不同於其他基於學習的方法:一個DCNN來實現噪聲影象。因此,通過從汙染影象中分離噪聲影 我這裡簡單講下OpenFace中實現人臉識別的pipeline,這個pipeline可以看做是使用深度卷積網路處理人臉問題的一個基本框架,很有學習價值,它的結構如下圖所示:1、Input Image -> Detect輸入:原始的可能含有人臉的影象。輸出:人臉位置的bounding box。這一步一般我
論文地址基於深度卷積神經網路的高光譜遙感影象分類西華大學學報同時利用高光譜影象的光譜資訊和空間資訊的深度卷積神經網路分類模型。基於深度學習到的深度特徵,用邏輯迴歸分類器進行分類訓練。高光譜影象面臨的挑戰 相關推薦
【譯】DeepLab V2:基於深度卷積網、孔洞演算法和全連線CRFs的語義影象分割
【譯】統計建模:兩種文化(第六部分)
【譯】統計建模:兩種文化(第四、五部分)
【譯】統計建模:兩種文化(第三部分)
【譯】非同步程式設計:Futures
【譯】終極指南:變數提升、作用域和閉包
【NLP】Python例項:基於文字相似度對申報專案進行查重設計
【譯】Python 金融:演算法交易 (1)基礎入門
【案例】蜂巢鏈:基於區塊鏈的資產證劵化
【譯】3D列印:介紹
【譯】Rust巨集:教程與示例(一)
【譯】Rust巨集:教程與示例(二)
【Python圖像特征的音樂序列生成】深度卷積網絡,以及網絡核心
【linux】linux命令:檢視linux伺服器的jdk、Tomcat、mysql、maven版本號
【spark】Spark運算元:RDD基本轉換操作–map、flagMap、distinct
基於圖卷積網絡的圖深度學習
基於深度卷積神經網路的單通道人聲與音樂的分離-論文翻譯
基於深度卷積神經網路(D-CNN)的影象去噪方法
基於深度卷積神經網路進行人臉識別的原理是什麼?
基於深度卷積神經網路的高光譜遙感影象分類---PCA+2D-CNN(偽空譜特徵)