
【網路爬蟲】爬取豆瓣電影Top250評論
前言
本爬蟲大致流程為:
(1)分析網頁——分析網站結構
(2)傳送請求——通過requests傳送請求
(3)響應請求——得到請求響應的頁面
(4)解析響應——分析頁面,得到想要的資料
(5)儲存文字——以txt格式儲存
使用環境
- anaconda3
- python3.6
- jupyter notebook
用到的庫
- requests
- lxml
- urllib
- re
庫的安裝很簡單,自行百度
中文簡體和繁體轉換所需Python庫,用於將評論中的繁體字轉為簡體字
下載zh_wiki.py 和 langconv
下載後,將這兩個py檔案放在程式碼同一個目錄下,即可
(1)分析網頁
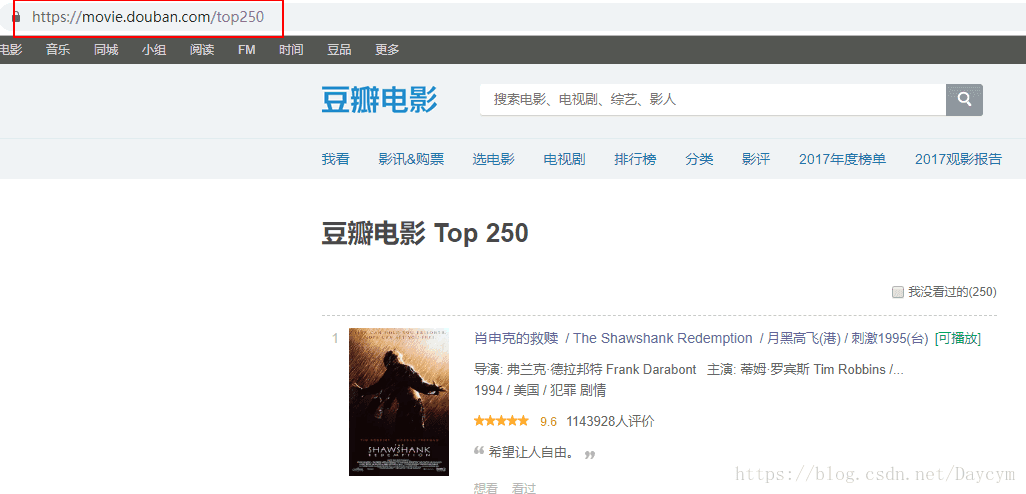
下面我們點選下一頁,觀察網址的變化
我們發現,只有start變數在變化,而且每次加25,正好是每頁電影的個數
要想獲得每部電影的評論,我們首先要進入這部電影評論的地方
下面我們就要看每部電影的評論
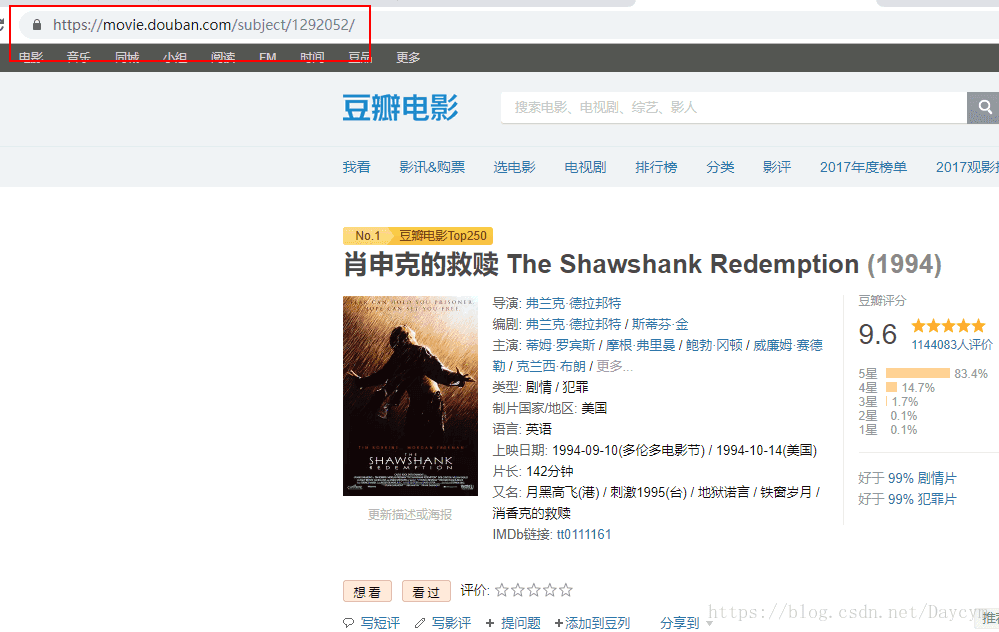
檢視全部評論

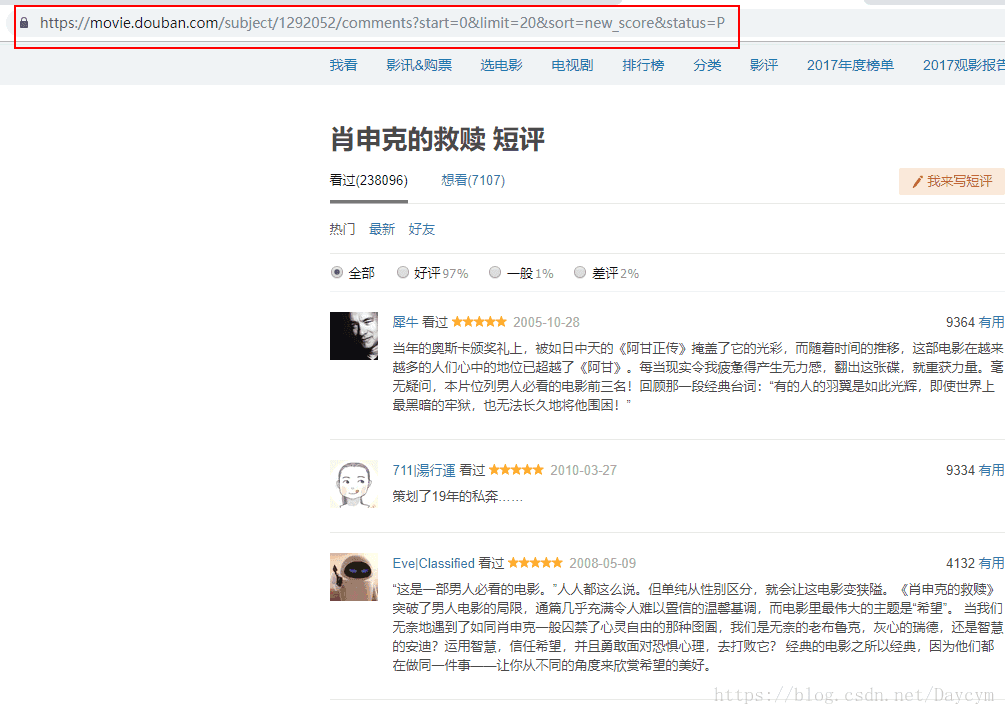
同樣,一開始第一頁的引數不全,我們先點評論第2頁,再點第1頁,如上圖:
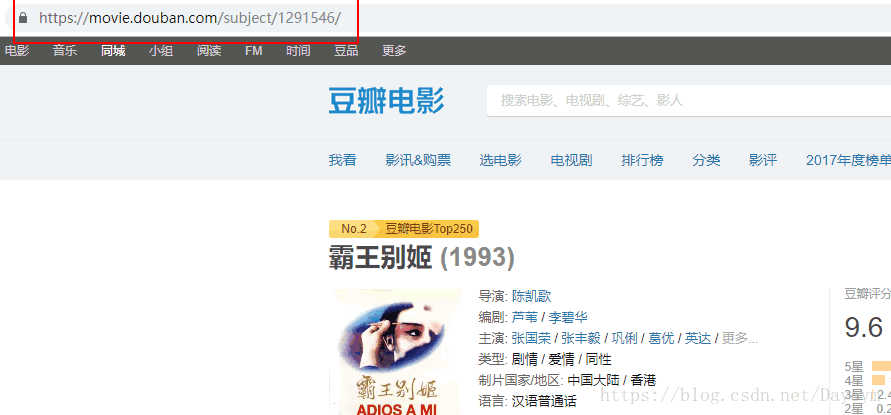
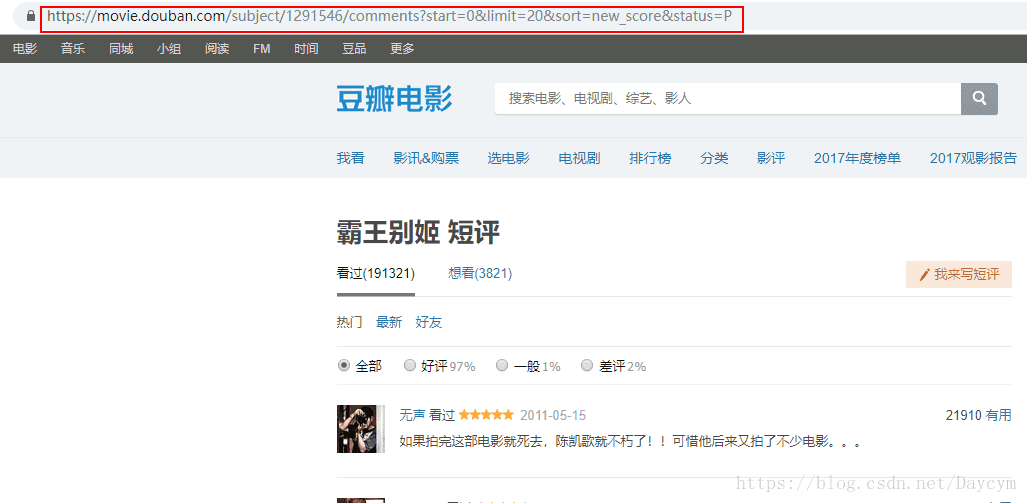
在top250頁面下開啟開發者工具(F12)
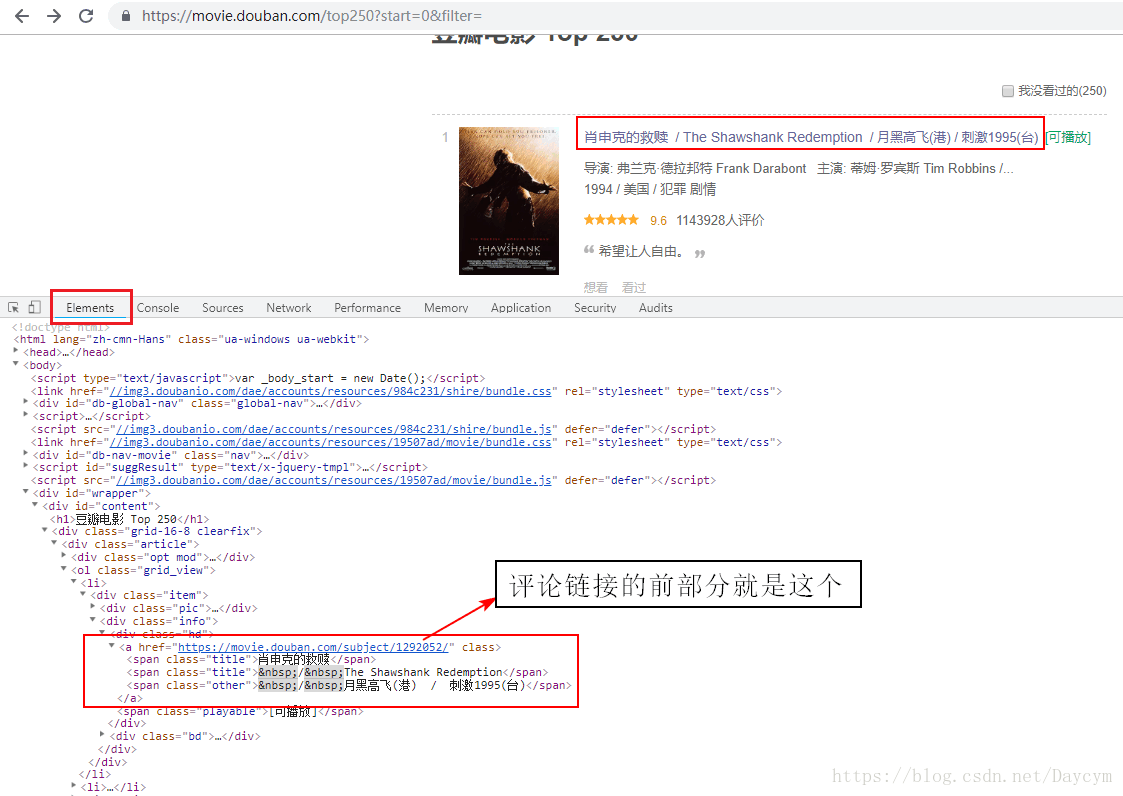
圖中紅框內,便是評論連結的前部分,那我們就可通過top頁面,獲取每一箇中每部電影的評論連結
通過一系列連結的拼接就可以獲得每部電影的評論地址,然後再通過評論連結獲取評論頁面,再獲取評論文字,這樣就可以了
流程如下:
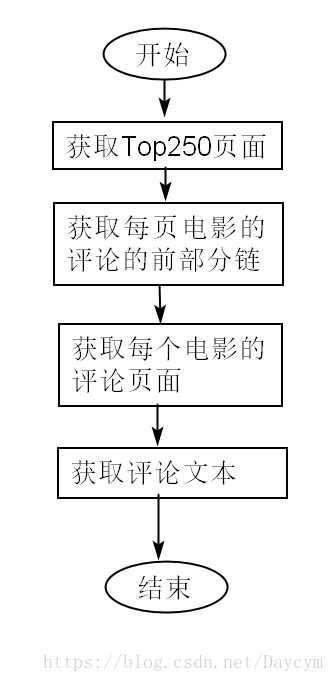
(2)傳送請求,響應請求,解析網頁
需要匯入的庫:
import - 獲取Top250頁面
# 獲取電影排行頁面
def get_top_page(start):
params = {
'start': start,
'filter': '',
}
url = 'https://movie.douban.com/top250?' + urlencode( - 獲取每頁電影連結
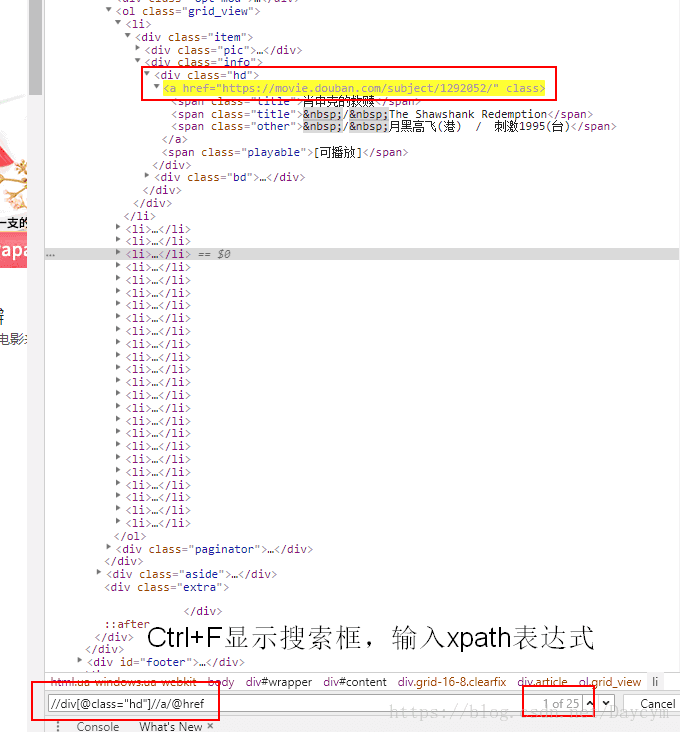
# 獲取每頁每部電影的評論連結前部分
def get_comment_link(top_page):
html = etree.HTML(top_page)
result = html.xpath('//div[@class="hd"]//a/@href') # 分析上面得到的頁面獲得
return result
# 測試
comment_link = get_comment_link(top_page)
print(comment_link)
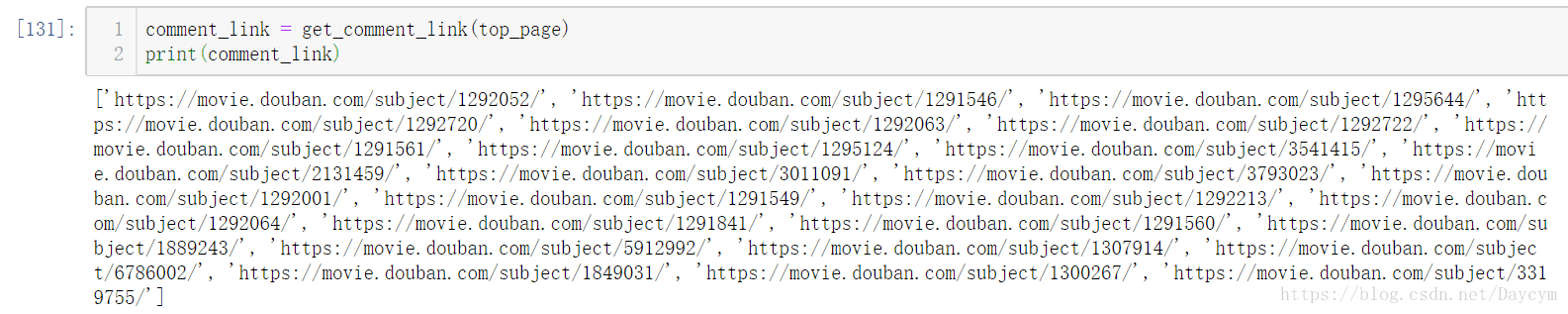
這樣我們就獲得了第1頁裡面每部電影的評論連結的前部分
- 獲取評論頁面
# 根據評論連結,獲取評論頁面
def get_comment_page(comment_link,start):
params = {
'start': start,
'limit': '20',
'sort':'new_score',
'status':'P'
}
url = comment_link +'comments?'+ urlencode(params)
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'
}
response = requests.get(url,headers=headers)
if response.status_code == 200:
return response.text
return 'Error'
except RequestException:
print('get_comment_page() Error')
return None
- 根據評論頁面獲取評論
# 根據評論頁面獲取評論
def get_comment(comment_page):
html = etree.HTML(comment_page)
result = html.xpath('//div[@class="mod-bd"]//div/div[@class="comment"]/p/span/text()') # 類似前面的方法,找節點
return result
(3)儲存資料
- 繁體字轉為簡體字
import langconv
def Traditional2Simplified(sentence): # 將sentence中的繁體字轉為簡體字
sentence = langconv.Converter('zh-hans').convert(sentence)
return sentence
- 評論資料清理
import re
# 清理一下評論資料
def clear(string):
string = string.strip() # 去掉空格等空白符號
string = re.sub("[A-Za-z0-9]", "", string) # 去掉英文字母 數字
string = re.sub(r"[!!?。。,&;"★#$%&'()*+-/:;<=>@[\]^_`{|}~⦅⦆「」、、〃「」『』【】"
r"〔〕〖〗〘〙#〚〛〜〝〞/?=~〟,〰–—‘’‛“”„‟…‧﹏.]", " ", string) # 去掉中文符號
string = re.sub(r"[!\'\"#。$%&()*+,-.←→/:~;<=>[email protected][\\]^_`_{|}~", " ", string) # 去掉英文符號
return Traditional2Simplified(string).lower() # 所有的英文都換成小寫
- 存為txt檔案
# 儲存評論
def save_to_txt(results):
for result in results:
result = clear(result)
# print(result)
with open('comment1.txt','a',encoding='utf-8') as file:
file.write(result)
file.write('\n'+'='*50+'\n')
完整程式碼
import requests # 請求庫
from urllib.parse import urlencode # 解析連結
from lxml import etree # 解析頁面
import langconv
import re # 正則表示式,用去匹配去除評論中的符合
# 獲取電影排行頁面
def get_top_page(start):
params = {
'start': start,
'filter': '',
}
url = 'https://movie.douban.com/top250?' + urlencode(params)
print(url)
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'
}
response = requests.get(url,headers=headers)
if response.status_code == 200:
return response.text
return None
except RequestException:
print('get_top_page() Error')
return None
# 獲取每頁每部電影的評論連結
def get_comment_link(top_page):
html = etree.HTML(top_page)
result = html.xpath('//div[@class="hd"]//a/@href') # 通過..獲取父節點
return result
# 根據評論連結,獲取評論頁面
def get_comment_page(comment_link,start):
params = {
'start': start,
'limit': '20',
'sort':'new_score',
'status':'P'
}
url = comment_link +'comments?'+ urlencode(params)
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'
}
response = requests.get(url,headers=headers)
if response.status_code == 200:
return response.text
return 'Error'
except RequestException:
print('get_comment_page() Error')
return None
# 根據評論頁面獲取評論
def get_comment(comment_page):
html = etree.HTML(comment_page)
result = html.xpath('//div[@class="mod-bd"]//div/div[@class="comment"]/p/span/text()') # 通過..獲取父節點
return result
# 將sentence中的繁體字轉為簡體字
def Traditional2Simplified(sentence):
sentence = langconv.Converter('zh-hans').convert(sentence)
return sentence
# 清理一下評論資料
def clear(string):
string = string.strip() # 去掉空格等空白符號
string = re.sub("[A-Za-z0-9]", "", string) # 去掉英文字母 數字
string = re.sub(r"[!!?。。,&;"★#$%&'()*+-/:;<=>@[\]^_`{|}~⦅⦆「」、、〃「」『』【】"
r"〔〕〖〗〘〙#〚〛〜〝〞/?=~〟,〰–—‘’‛“”„‟…‧﹏.]", " ", string) # 去掉中文符號
string = re.sub(r"[!\'\"#。$%&()*+,-.←→/:~;<=>[email protected][\\]^_`_{|}~", " ", string) # 去掉英文符號
return Traditional2Simplified(string).lower() # 所有的英文都換成小寫
# 儲存評論
def save_to_txt(results):
for result in results:
result = clear(result)
# print(result)
with open('comment.txt','a',encoding='utf-8') as file:
file.write(result)
file.write('\n'+'='*50+'\n')
# 執行
print("爬取開始...")
for start in range(0,250,25): # 可以爬取第一頁,減少爬蟲時間
print("正在爬取第"+str(int(start/25+1))+"頁!!!")
#print(start)
top_page = get_top_page(start)
comment_link = get_comment_link(top_page)
#print(comment_link)
for i in range(25):
print("正在爬取第"+str(i)+"個電影!!!")
#print(comment_link[i])
for j in range(0,100,20):
comment_page = get_comment_page(comment_link[i],j)
results = get_comment(comment_page)
save_to_txt(results)
print("爬取第"+str(i)+"個電影結束")
爬取結果

我沒爬完,可以通過修改引數,只爬取第一頁每部電影的前100條評論
總結
在做這個爬蟲前,我看了一些相關的書,瞭解大致流程,和一些庫的使用,很明顯程式碼不是最簡化的,但是對於一個初學者來說挺有成就感,希望再接再厲,繼續加油!!!
- 在爬取的過程中,可能出現IP被封鎖,網站可能設定了IP訪問次數限制——解決方法:可以使用代理
- 只爬取了評論,可以將電影名稱和評論對應起來,另外,還可以將好評/壞評分別標記每條評論,以便以後對文字資料進行一些情感分析啥的,這樣就不用自己條件標籤了
- 還可以以其他方式儲存資料,如資料庫
相關推薦
【網路爬蟲】爬取豆瓣電影Top250評論
前言 本爬蟲大致流程為: (1)分析網頁——分析網站結構 (2)傳送請求——通過requests傳送請求 (3)響應請求——得到請求響應的頁面 (4)解析響應——分析頁面,得到想要的資料 (5)儲存文字——以txt格式儲存 使用環境 anaconda3 pyt
案例學python——案例三:豆瓣電影資訊入庫 一起學爬蟲——通過爬取豆瓣電影top250學習requests庫的使用
閒扯皮 昨晚給高中的妹妹微信講題,函式題,小姑娘都十二點了還迷迷糊糊。今天凌晨三點多,被連續的警報聲給驚醒了,以為上海拉了防空警報,難不成地震,空襲?難道是樓下那個車主車子被堵了,長按喇叭?開窗看看,好像都不是。好鬼畜的警報聲,家裡也沒裝報警器啊,莫不成家裡煤氣漏了?起床循聲而查,報警
一起學爬蟲——通過爬取豆瓣電影top250學習requests庫的使用
學習一門技術最快的方式是做專案,在做專案的過程中對相關的技術查漏補缺。 本文通過爬取豆瓣top250電影學習python requests的使用。 1、準備工作 在pycharm中安裝request庫 請看上圖,在pycharm中依次點選:File->Settings。然後會彈出下圖的介面: 點選2
簡易爬蟲:爬取豆瓣電影top250
爬蟲目的說明: 此爬蟲簡單到不能再簡單了,主要內容就是爬取豆瓣top250電影頁面的內容,然後將該內容匯入了資料庫。下面先上結果圖: 爬蟲部分程式碼: def getlist(listurl, result): time.sleep(2
【go語言爬蟲】go語言爬取豆瓣電影top250
抓取欄位:電影名稱、評分、評價人數 二、執行: 正在抓取第0頁…… 肖申克的救贖 9.6 824764人 這個殺手不太冷 9.4 791399人 霸王別姬 9.5 589028人 阿甘正傳 9.4 678850人 美麗人生 9.5 3940
【Python爬蟲】Scrapy框架運用1—爬取豆瓣電影top250的電影資訊(1)
一、Step step1: 建立工程專案 1.1建立Scrapy工程專案 E:\>scrapy startproject 工程專案 1.2使用Dos指令檢視工程資料夾結構 E:\>tree /f step2: 建立spid
【Python3爬蟲】Scrapy爬取豆瓣電影TOP250
今天要實現的就是使用是scrapy爬取豆瓣電影TOP250榜單上的電影資訊。 步驟如下: 一、爬取單頁資訊 首先是建立一個scrapy專案,在資料夾中按住shift然後點選滑鼠右鍵,選擇在此處開啟命令列視窗,輸入以下程式碼: scrapy startprojec
python爬蟲【例項】爬取豆瓣電影評分連結並圖示()-問題如何爬取電影圖片(解決有程式碼)
這裡只有尾巴,來分析一下確定範圍:如何爬取圖片並下載?參考:http://blog.csdn.net/chaoren666/article/details/53488083----------------------------------------------------
【爬蟲】爬取貓眼電影top100
用正則表示式爬取 #!/usr/bin/python # -*- coding: utf-8 -*- import json # 快速匯入此模組:滑鼠先點到要匯入的函式處,再Alt + Enter進行選擇 from multiprocessing.pool im
Python網路爬蟲:利用正則表示式爬取豆瓣電影top250排行前10頁電影資訊
在學習了幾個常用的爬取包方法後,轉入爬取實戰。 爬取豆瓣電影早已是練習爬取的常用方式了,網上各種程式碼也已經很多了,我可能現在還在做這個都太土了,不過沒事,畢竟我也才剛入門…… 這次我還是利用正則表示式進行爬取,怎麼說呢,有人說寫正則表示式很麻煩,很多人都不
團隊-張文然-需求分析-python爬蟲分類爬取豆瓣電影信息
工具 新的 翻頁 需求 使用 html 頁面 應該 一個 首先要明白爬網頁實際上就是:找到包含我們需要的信息的網址(URL)列表通過 HTTP 協議把頁面下載回來從頁面的 HTML 中解析出需要的信息找到更多這個的 URL,回到 2 繼續其次還要明白:一個好的列表應該:包含
【Python3 爬蟲】爬取博客園首頁所有文章
表達式 技術 標記 itl 1.0 headers wow64 ignore windows 首先,我們確定博客園首頁地址為:https://www.cnblogs.com/ 我們打開可以看到有各種各樣的文章在首頁,如下圖: 我們以上圖標記的文章為例子吧!打開網頁源碼,搜
Python爬蟲入門 | 爬取豆瓣電影信息
Python 編程語言 web開發這是一個適用於小白的Python爬蟲免費教學課程,只有7節,讓零基礎的你初步了解爬蟲,跟著課程內容能自己爬取資源。看著文章,打開電腦動手實踐,平均45分鐘就能學完一節,如果你願意,今天內你就可以邁入爬蟲的大門啦~好啦,正式開始我們的第二節課《爬取豆瓣電影信息》吧!啦啦哩啦啦,
爬蟲之爬取豆瓣電影的名字
import requests #requests模組用於傳送HTTP請求 import json #json模組用於對JSON資料進行編解碼 #新建陣列用於存放多個電影資料 movielist=[] #瀏覽器演示json crawlSite="https://api.douba
python爬蟲,爬取豆瓣電影《芳華》電影短評,分詞生成雲圖。
專案github地址:https://github.com/kocor01/spider_cloub/ Python版本為3.6 最近突然想玩玩雲圖,動手寫了個簡單的爬蟲,搭建了簡單的爬蟲架構 爬蟲爬取最近比較火的電影《芳華》分詞後生成雲圖 使用了 jieba分詞,雲圖用word
【Python3爬蟲】爬取中國國家地理的62個《古鎮》和363張攝影照片
宣告:爬蟲為學習使用,請各位同學務必不要對當放網站或i伺服器造成傷害。務必不要寫死迴圈。 - 思路:古鎮——古鎮列表(迴圈獲取古鎮詳情href)——xx古鎮詳情(獲取所有img的src) - from bs4 import BeautifulSoup import u
【Python爬蟲】爬取微信公眾號文章資訊準備工作
有一天發現我關注了好多微信公眾號,那時就想有沒有什麼辦法能夠將微信公眾號的文章弄下來,而且還想將一些文章的精彩評論一起搞下來。參考了一些文章,通過幾天的研究基本上實現了自己的要求,現在記錄一下自己的一些心得。 整個研究過程如下: 1.瞭解微信公眾號文章連結的組成,歷史文章API組成,單個文章
python爬蟲(爬取豆瓣電影)_動態網頁,json解釋,中文編碼
from bs4 import BeautifulSoup import requests import json import sys import codecs reload(sys) sys.setdefaultencoding( "utf-8" ) rank
[python爬蟲入門]爬取豆瓣電影排行榜top250
要爬取內容的是豆瓣網的電影排行top250: https://movie.douban.com/top250, 將電影名和評分爬取下來並輸出, 如下圖: 使用了tkinter做了簡單頁面 然後分析如何爬取內容: 首先爬取標題: 檢視原始碼後, 發現標
(7)Python爬蟲——爬取豆瓣電影Top250
利用python爬取豆瓣電影Top250的相關資訊,包括電影詳情連結,圖片連結,影片中文名,影片外國名,評分,評價數,概況,導演,主演,年份,地區,類別這12項內容,然後將爬取的資訊寫入Excel表中。基本上爬取結果還是挺好的。具體程式碼如下: #!/us