
FPGA機器學習之stanford機器學習第二十堂

線性二次相關問題。選擇動作。
POMDP引數又多了2個。
o是觀察分佈。

隨機策略???
狀態和行為的對映,π(s,a)
制定一個可能的行為分佈。
π,策略。

a1,a2是兩個行為,加速度。
1,兩個的內積。s是位置,theta引數。
2,目標,最大化預期回報。

取樣,然後最大化收益,然後更新。
非常像梯度上升,
寫了四個步驟。這幾個步驟,看不懂就不截圖了。
預期回報是梯度方向。加強優化是梯度方向。
PEGASUS策略搜尋。
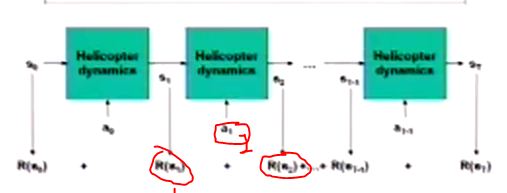
1獎勵,2是動作,行向轉移的是狀態。
飛機的執行用的是這個pegasus方法完成的。

pegasus演算法的結果。

MDP模型,偏差估計。
60分鐘開始講了很多的例子。機器學習應用。
 我能力有限,但是我努力的理解。他們都成了專家,我好想才理解了一點點,在學習,在瞭解。stanford就到此為止。
我能力有限,但是我努力的理解。他們都成了專家,我好想才理解了一點點,在學習,在瞭解。stanford就到此為止。
相關推薦
FPGA機器學習之stanford機器學習第二十堂
線性二次相關問題。選擇動作。 POMDP引數又多了2個。 o是觀察分佈。 隨機策略??? 狀態和行為的對映,π(s,a) 制定一個可能的行為分佈。 π,策略。 a1,a2是兩個行為,加速度。 1,兩個的內積。s是位置,theta引數。 2,目標,最大化預期回報
FPGA機器學習之stanford機器學習第一堂
主講:吳恩達。如果你學機器學習,對這個人牛,神的程度,不瞭解。你就可以洗洗睡了。必定全球人工智慧最權威專家中有他一個。 他說,機器學習是最重要的IT技能。這個是在矽谷那種地方。在中國,目前最火爆的是,網頁和安卓。不過大資料,網際網路,智慧機
FPGA機器學習之stanford機器學習第十六堂
Reinforcement Learning 強化學習。這裡舉例子是自主飛行的飛機。控制飛機,如果自主寫程式的話,會很難,所以需要它自學習。 最好用的地方,就是下棋。不過,怎麼半監督學習演算
FPGA機器學習之stanford機器學習第四堂
這個是第一篇講義的20頁。
FPGA機器學習之stanford機器學習第十八堂
MDP的幾個參量。 這個就比較熟悉了。獎勵最大化函式。 獎勵函式改變,並不會有太多影響。 s狀態,a行為。獎勵機制。 1是當前回報,2未來總回報。 左邊的圈是加1,後邊的圈加10,下面是機器人 的行為,為什麼沒有向10方向,是因為沒有足夠的
FPGA機器學習之stanford機器學習第三堂2
我已經寫過一遍了,為了我的分享事業,我在寫一次吧。 上一次我寫到了,這裡加號後面的那個就是錯誤率。為什麼會引入這個,上一篇,我有寫清楚。 這裡,我們假定它符合高斯分佈。為什麼是高斯分佈,上一篇也寫了。 這裡引
FPGA機器學習之stanford機器學習第九堂
接下來他要講的內容是,如何使用好這些工具。 開始的時候說了一些過擬合,欠擬合線性。 為了方便理解,來一個簡化版機器學習模型。 被假設錯誤分類的訓練樣本數的和。 叫ERM 最小化。這個是最基本的
FPGA機器學習之stanford機器學習第十堂
誤差都為0. 這次用三點舉例子。也是可以完全分離的。 如果用這三個點的話。h就不可以分離了。 可是用4個點的話。h函式也不可以完全分離。 在二維空間裡面,任何線性分離器都不可以分割右上角四個點的情況。 根據這些情況可以得到一些結論。 如果要分離
機器學習之路--機器學習演算法一覽,應用建議與解決思路
作者:寒小陽 時間:2016年1月。 出處:http://www.lai18.com/content/2440126.html 宣告:版權所有,轉載請聯絡作者並註明出處 1.引言提起筆來寫這篇部落格,突然有點愧疚和尷尬。愧疚的是,工作雜事多,加之懶癌嚴重,導致這個系列一直沒有更新,向關注該系列的同學們
機器學習之迴圈神經網路(十)
摘要: 多層反饋RNN(Recurrent neural Network、迴圈神經網路)神經網路是一種節點定向連線成環的人工神經網路。這種網路的內部狀態可以展示動態時序行為。不同於前饋神經網路的是,RNN可以利用它內部的記憶來處理任意時序的輸入序列,這讓
機器學習之python入門指南(十一)numpy常用方法簡介
numpy庫的安裝: window下命令列直接輸入pip install numpy 匯入numpy庫:import numpy 或者 import numpy as np numpy與list: 相同之處: 都可以用下標訪問元素,如a[3]. 都可以
機器學習之優化演算法學習總結
優化演算法演化歷程 機器學習和深度學習中使用到的優化演算法的演化歷程如下: SGD –> Momentum –> Nesterov –> Adagrad –> Adadelta –> Adam –> Nadam 表1優化
Caffe學習之——虛擬機器下Ubuntu16.04 安裝caffe教程
轉載自:https://blog.csdn.net/c20081052/article/details/79775127安裝caffe的依賴項1)一般依賴項sudo apt-get install libprotobuf-dev libleveldb-dev libsnapp
機器學習之監督標題學習__線性分類
機器學習之監督標題學習__線性分類 一,logistic迴歸 (邏輯迴歸): 通過不斷修正縮小誤差最終得到準確的模型,整個過程中需要不斷迴歸,直到達到指定的次數或者達到設定的精度 二,sigsigmoid函式: 啟用函式sigmoid函式是一種階躍函式,輸出範圍在[0,1],在迴歸問題中
機器學習之決策樹——學習總結
決策樹學習總結 機器學習的應用越來越廣泛,特別是在資料分析領域。本文是我學習決策樹演算法的一些總結。 機器學習簡介 機器學習 (Machine Learning) 是近 20 多年興起的一門多領域交叉學科,涉及概率論、統計學、逼近論、凸分析、演
Python學習之虛擬機器環境
上週趕上兩次面試和清明節,一回家人就變懶了,錯過了文章更新時間,且修改了讀書筆記的篇數。慚愧慚愧啊。。。 序 之前開發編譯平臺二期,需要自己進行python整個執行環境的部署,特地跟著師傅從頭到尾學習了環境的搭建和維護,以前總覺得只要會設計、會程
openwrt學習之虛擬機器vm下編譯執行測試
之前成功編譯出來openwrt的img韌體,現在進一步學習,編譯一個基於x86cpu的映象,並用vm跑起來,自己學著先配置一下 1.更新openwrt ./scripts/feeds update -a 2.更新完成後,安裝需要的更新依賴包 /scripts/feeds
機器學習之感知機學習筆記第一篇:求輸入空間R中任意一點X0到超平面S的距離
我的學習資料是“統計學習方法”,作者是李航老師,這本書很著名,百度有很多關於它的PDF。 作為學習筆記,就說明我還是屬於學習中,所以,這個分類中我暫時不打算討論詳細的演算法,這個分類會講到我在學習遇到的問題和我自己解決這些問題的思路。 今天這個問題(見題目)是在學習李航老師
【itext學習之路】-------(第二篇)設定pdf的一些常用屬性
在上一篇文章中,我們已經成功的建立了一個簡單的pdf,下面我將學習設定該pdf的常用屬性,其中包括:作者,建立時間,pdf建立者,pdf生產者,關鍵字,標題,主題 下面是我們的程式碼,非常簡單。 package cn.tomtocc.pdf; imp
python學習之函數學習進階
python學習之函數進階1.名稱空間 python有三種名稱空間 內置名稱空間: 隨著python解釋器的啟動而產生 print(sum) print(max) 全局名稱空間: 文件的執行會產生全局名稱空間,指的是文件級別的定義名字都會放入該空間 x = 11 if x == 11: print