
Linux下五種I/O模型詳解(阻塞IO、非阻塞IO、IO複用、訊號驅動、非同步IO)
文章轉載自微信公眾號:漫話程式設計
1 什麼是I/O
程式是由資料+指令構成的,執行程式的過程可以分成下面這幾步:
1.將程式碼載入到記憶體中,逐條執行記憶體中的程式碼
2.在執行程式碼的過程中,可能需要對檔案的讀寫,即將檔案輸入(Input)到記憶體和將程式碼執行結果產生的檔案輸出(Output)到外設(網路、磁碟)的過程。那麼這個資料交換的過程就是I/O
…
IO中的阻塞、非阻塞、同步、非同步概念分析
通過上面這篇文章你可以知道同步、非同步、阻塞、非阻塞這些概念,並且可以瞭解到java中I/O程式設計的三種模型,阻塞IO(BIO)、非阻塞IO(NIO)和非同步IO(AIO)。Java中NIO和AIO都是通過epoll來實現的。
我們常說的IO,指的是檔案的輸入和輸出,但是在作業系統層面是如何定義IO的呢?到底什麼樣的過程可以叫做是一次IO呢?
拿一次磁碟檔案讀取為例,我們要讀取的檔案是儲存在磁碟上的,我們的目的是把它讀取到記憶體中。可以把這個步驟簡化成把資料從硬體(硬碟)中讀取到使用者空間中。
其實真正的檔案讀取還涉及到快取等細節,這裡就不展開講述了。關於使用者空間、核心空間以及硬體等的關係如果讀者不理解的話,可以通過釣魚的例子理解。
釣魚的時候,剛開始魚是在魚塘裡面的,我們的釣魚動作的最終結束標誌是魚從魚塘中被我們釣上來,放入魚簍中。
這裡面的魚塘就可以對映成磁碟,中間過渡的魚鉤可以對映成核心空間,最終放魚的魚簍可以對映成使用者空間。一次完整的釣魚(IO)操作,是魚(檔案)從魚塘(硬碟)中轉移(拷貝)到魚簍(使用者空間)的過程
在Linux(UNIX)作業系統中,共有五種IO模型,分別是:阻塞IO模型、非阻塞IO模型、IO複用模型、訊號驅動IO模型以及非同步IO模型。
2 同步IO模型
2.1 阻塞IO模型
我們釣魚的時候,有一種方式比較愜意,比較輕鬆,那就是我們坐在魚竿面前,這個過程中我們什麼也不做,雙手一直把著魚竿,就靜靜的等著魚兒咬鉤。一旦手上感受到魚的力道,就把魚釣起來放入魚簍中。然後再釣下一條魚。
對映到Linux作業系統中,這就是一種最簡單的IO模型,即阻塞IO。 阻塞 I/O 是最簡單的 I/O 模型,一般表現為程序或執行緒等待某個條件,如果條件不滿足,則一直等下去。條件滿足,則進行下一步操作。

應用程序通過系統呼叫 recvfrom 接收資料,但由於核心還未準備好資料報,應用程序就會阻塞住,直到核心準備好資料報,recvfrom 完成資料報復制工作,應用程序才能結束阻塞狀態。
這種釣魚方式相對來說比較簡單,對於釣魚的人來說,不需要什麼特製的魚竿,拿一根夠長的木棍就可以悠閒的開始釣魚了(實現簡單)。缺點就是比較耗費時間,比較適合那種對魚的需求量小的情況(併發低,時效性要求低)。
2.2 非阻塞IO模型
我們釣魚的時候,在等待魚兒咬鉤的過程中,我們可以做點別的事情,比如玩一把王者榮耀、看一集《延禧攻略》等等。但是,我們要時不時的去看一下魚竿,一旦發現有魚兒上鉤了,就把魚釣上來。
對映到Linux作業系統中,這就是非阻塞的IO模型。應用程序與核心互動,目的未達到之前,不再一味的等著,而是直接返回。然後通過輪詢的方式,不停的去問核心資料準備有沒有準備好。如果某一次輪詢發現數據已經準備好了,那就把資料拷貝到使用者空間中。
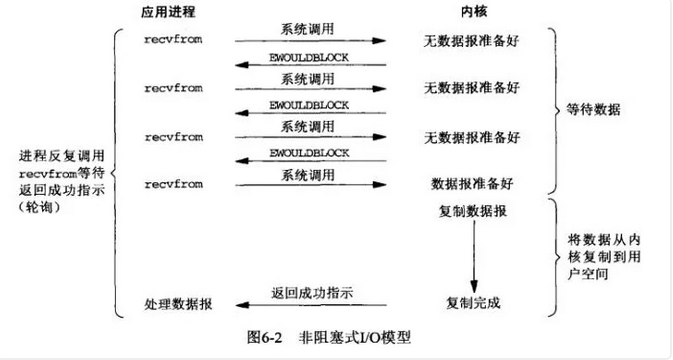
應用程序通過 recvfrom 呼叫不停的去和核心互動,直到核心準備好資料。如果沒有準備好,核心會返回error,應用程序在得到error後,過一段時間再發送recvfrom請求。在兩次傳送請求的時間段,程序可以先做別的事情。
這種方式釣魚,和阻塞IO比,所使用的工具沒有什麼變化,但是釣魚的時候可以做些其他事情,增加時間的利用率。
2.3 訊號驅動IO模型
我們釣魚的時候,為了避免自己一遍一遍的去檢視魚竿,我們可以給魚竿安裝一個報警器。當有魚兒咬鉤的時候立刻報警。然後我們再收到報警後,去把魚釣起來。
對映到Linux作業系統中,這就是訊號驅動IO。應用程序在讀取檔案時通知核心,如果某個 socket 的某個事件發生時,請向我發一個訊號。在收到訊號後,訊號對應的處理函式會進行後續處理。
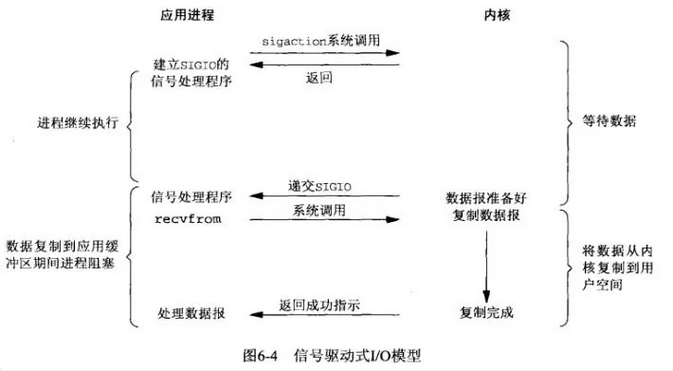
應用程序預先向核心註冊一個訊號處理函式,然後使用者程序返回,並且不阻塞,當核心資料準備就緒時會發送一個訊號給程序,使用者程序便在訊號處理函式中開始把資料拷貝的使用者空間中。
這種方式釣魚,和前幾種相比,所使用的工具有了一些變化,需要有一些定製(實現複雜)。但是釣魚的人就可以在魚兒咬鉤之前徹底做別的事兒去了。等著報警器響就行了。
2.4 IO複用模型
生產中經常會用到的一種模型
我們釣魚的時候,為了保證可以最短的時間釣到最多的魚,我們同一時間擺放多個魚竿,同時釣魚。然後哪個魚竿有魚兒咬鉤了,我們就把哪個魚竿上面的魚釣起來。
對映到Linux作業系統中,這就是IO複用模型。多個程序的IO可以註冊到同一個管道上,這個管道會統一和核心進行互動。當管道中的某一個請求需要的資料準備好之後,程序再把對應的資料拷貝到使用者空間中。
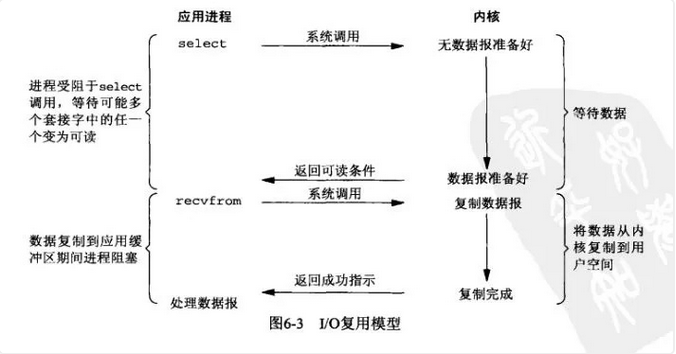
IO多路轉接是多了一個select函式,多個程序的IO可以註冊到同一個select上,當用戶程序呼叫該select,select會監聽所有註冊好的IO,如果所有被監聽的IO需要的資料都沒有準備好時,select呼叫程序會阻塞。當任意一個IO所需的資料準備好之後,select呼叫就會返回,然後程序在通過recvfrom來進行資料拷貝。
這裡的IO複用模型,並沒有向核心註冊訊號處理函式,所以,他並不是非阻塞的。程序在發出select後,要等到select監聽的所有IO操作中至少有一個需要的資料準備好,才會有返回,並且也需要再次傳送請求去進行檔案的拷貝。
這種方式的釣魚,通過增加魚竿的方式,可以有效的提升效率。
2.5 小結
我們說阻塞IO模型、非阻塞IO模型、IO複用模型和訊號驅動IO模型都是同步的IO模型。原因是因為,無論以上那種模型,真正的資料拷貝過程,都是同步進行的。
訊號驅動難道不是非同步的麼? 訊號驅動,核心是在資料準備好之後通知程序,然後程序再通過recvfrom操作進行資料拷貝。我們可以認為資料準備階段是非同步的,但是,資料拷貝操作是同步的。所以,整個IO過程也不能認為是非同步的。
我們把釣魚過程,可以拆分為兩個步驟:1、魚咬鉤(資料準備)。2、把魚釣起來放進魚簍裡(資料拷貝)。無論以上提到的哪種釣魚方式,在第二步,都是需要人主動去做的,並不是魚竿自己完成的。所以,這個釣魚過程其實還是同步進行的。
3 非同步IO模型
我們釣魚的時候,採用一種高科技釣魚竿,即全自動釣魚竿。可以自動感應魚上鉤,自動收竿,更厲害的可以自動把魚放進魚簍裡。然後,通知我們魚已經釣到了,他就繼續去釣下一條魚去了。
對映到Linux作業系統中,這就是非同步IO模型。應用程序把IO請求傳給核心後,完全由核心去操作檔案拷貝。核心完成相關操作後,會發訊號告訴應用程序本次IO已經完成。

使用者程序發起aio_read操作之後,給核心傳遞描述符、緩衝區指標、緩衝區大小等,告訴核心當整個操作完成時,如何通知程序,然後就立刻去做其他事情了。當核心收到aio_read後,會立刻返回,然後核心開始等待資料準備,資料準備好以後,直接把資料拷貝到使用者控制元件,然後再通知程序本次IO已經完成。
這種方式的釣魚,無疑是最省事兒的。啥都不需要管,只需要交給魚竿就可以了。
