
谷歌TPU研究論文:專注神經網路專用處理器
OFweek通訊網訊 過去十五年裡,我們一直在我們的產品中使用高計算需求的機器學習。機器學習的應用如此頻繁,以至於我們決定設計一款全新類別的定製化機器學習加速器,它就是 TPU。
TPU 究竟有多快?今天,聯合在矽谷計算機歷史博物館舉辦的國家工程科學院會議上發表的有關 TPU 的演講中,我們釋出了一項研究,該研究分享了這些定製化晶片的一些新的細節,自 2015 年以來,我們資料中心的機器學習應用中就一直在使用這些晶片。第一代 TPU 面向的是推論功能(使用已訓練過的模型,而不是模型的訓練階段,這其中有些不同的特徵),讓我們看看一些發現:
● 我們產品的人工智慧負載,主要利用神經網路的推論功能,其 TPU 處理速度比當前 GPU 和 CPU 要快 15 到 30 倍。
● 較之傳統晶片,TPU 也更加節能,功耗效率(TOPS/Watt)上提升了 30 到 80 倍。
● 驅動這些應用的神經網路只要求少量的程式碼,少的驚人:僅 100 到 1500 行。程式碼以 TensorFlow 為基礎。
● 70 多個作者對這篇文章有貢獻。這份報告也真是勞師動眾,很多人蔘與了設計、證實、實施以及佈局類似這樣的系統軟硬體。

TPU 的需求大約真正出現在 6 年之前,那時我們在所有產品之中越來越多的地方已開始使用消耗大量計算資源的深度學習模型;昂貴的計算令人擔憂。假如存在這樣一個場景,其中人們在 1 天中使用谷歌語音進行 3 分鐘搜尋,並且我們要在正使用的處理器中為語音識別系統執行深度神經網路,那麼我們就不得不翻倍谷歌資料中心的數量。
TPU 將使我們快速做出預測,並使產品迅速對使用者需求做出迴應。TPU 執行在每一次的搜尋中;TPU 支援作為谷歌影象搜尋(Google Image Search)、谷歌照片(Google Photo)和谷歌雲視覺 API(Google Cloud Vision API)等產品的基礎的精確視覺模型;TPU 將加強谷歌翻譯去年推出的突破性神經翻譯質量的提升;並在谷歌 DeepMind AlphaGo 對李世乭的勝利中發揮了作用,這是計算機首次在古老的圍棋比賽中戰勝世界冠軍。
我們致力於打造最好的基礎架構,並將其共享給所有人。我們期望在未來的數週和數月內分享更多的更新。
論文題目:資料中心的 TPU 效能分析(In-Datacenter Performance Analysis of a Tensor Processing Unit)

摘要:許多架構師相信,現在要想在成本-能耗-效能(cost-energy-performance)上獲得提升,就需要使用特定領域的硬體。這篇論文評估了一款自 2015 年以來就被應用於資料中心的定製化 ASIC,亦即張量處理器(TPU),這款產品可用來加速神經網路(NN)的推理階段。TPU 的中心是一個 65,536 的 8 位 MAC 矩陣乘法單元,可提供 92 萬億次運算/秒(TOPS)的速度和一個大的(28 MiB)的可用軟體管理的片上記憶體。相對於 CPU 和 GPU 的隨時間變化的優化方法(快取記憶體、無序執行、多執行緒、多處理、預取……),這種 TPU 的確定性的執行模型(deterministic execution model)能更好地匹配我們的神經網路應用的 99% 的響應時間需求,因為 CPU 和 GPU 更多的是幫助對吞吐量(throughout)進行平均,而非確保延遲效能。這些特性的缺失有助於解釋為什麼儘管 TPU 有極大的 MAC 和大記憶體,但卻相對小和低功耗。我們將 TPU 和伺服器級的英特爾 Haswell CPU 與現在同樣也會在資料中心使用的英偉達 K80 GPU 進行了比較。我們的負載是用高階的 TensorFlow 框架編寫的,並是用了生產級的神經網路應用(多層感知器、卷積神經網路和 LSTM),這些應用佔到了我們的資料中心的神經網路推理計算需求的 95%。儘管其中一些應用的利用率比較低,但是平均而言,TPU 大約 15-30 倍快於當前的 GPU 或者 CPU,速度/功率比(TOPS/Watt)大約高 30-80 倍。此外,如果在 TPU 中使用 GPU 的 GDDR5 記憶體,那麼速度(TOPS)還會翻三倍,速度/功率比(TOPS/Watt)能達到 GPU 的 70 倍以及 CPU 的 200 倍。
選自 Google Drive
作者:Norman P. Jouppi 等
痴笑@矽說 編譯
該論文將正式發表於 ISCA 2017
從去年七月起,Google就號稱了其面向深度學習的專用積體電路(ASIC)產品——Tensor Processing Unit (TPU),然而其神祕面紗一直未被揭開。直至本週,Google公開了其向ISCA(國際計算機體系架構年會)投稿的的預錄取論文——In Datacenter Performance Analysis of a Tensor Processing Unit,TPU的技術細節才公開發表,令我們才有幸見識其真面目。雖然可能只是“猶抱琵琶半遮面”,但其作為CPU/GPU/FPGA後的另一深度學習選項,特別是TPU和tensorflow間可能存在的微妙聯絡值得我們特別關注。矽說在第一時間選編、翻譯了其中的重要部分,以饗讀者。
論文地址:(需翻牆)
https://drive.google.com/file/d/0Bx4hafXDDq2EMzRNcy1vSUxtcEk/view
前言
文章具體描述了Tensor Processing Unit (TPU)的體系結構,並與目前主流的CPU(Intel Haswell Xeon)和GPU(Nvidia K80)的效能做出了比較,採用的benchmark包含了CNN,RNN(LSTM)和全連結(MLP)神經網路。其特點包括:
(1) 面向inference的專用app與硬體,強調了吞吐率上的效能
(2) TPU的不僅在面積和功耗上低於GPU,而且在乘累加的數量和儲存器容量是K80的25倍和3.5倍
(3) TPU的速度上的優勢明顯,達到GPU和CPU的15到30倍
(4) 在6個NN架構中,4種神經網路的效能瓶頸在於儲存器頻寬。若儲存器頻寬達到K80的效能,作者相信效能能提升到30到50倍
(5) TPU的能效值(TOPS/W)達到在目前其他產品的30到80倍
(6) CNN在TPU中工作量的比列只有5%
起源、架構與實現
早在2006年開始,Google就開始討論在資料中心部署GPU,FPGA或定製ASIC。在2013年,當DNN已經展露頭腳,以致可能會使我們的資料中心的計算需求加倍時,傳統的CPU已經被認為不合時宜了。因此,我們開始了一個高度優先的專案,以快速生成用於Inference的定製ASIC,(訓練仍使用GPU)。 目標是將效能提升10倍以上。 根據這一任務,Google的TPU的設計和驗證在短短15個月內完成,並構建並部署在資料中心。
而不是與CPU緊密整合,為了減少延遲部署的可能性,TPU被設計為PCIe I/O總線上的協處理器,允許它像GPU那樣插入現有的伺服器。 此外,為了簡化硬體設計和除錯,主機伺服器傳送TPU指令來執行,而不是自己提取它們。 因此,TPU在精神上比FPU(浮點單元)協處理器更接近於GPU。
TPU的目標是執行整體深度學習的神經網路模型,以減少與主機CPU的互動,並且具有足夠的靈活性,以滿足2015年及其後的NN需求,而不僅僅是2013年NN所需。
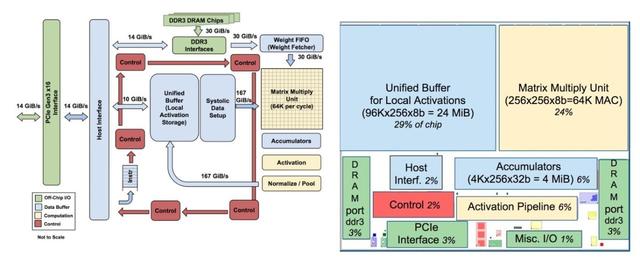
圖1是TPU的整體體系架構。TPU指令通過PCIe Gen3 x16匯流排從主機發送到指令緩衝區。 內部塊通常通過256位元組寬的路徑連線在一起。 從右上角開始,Matrix Multiply Unit是TPU的核心。 它包含256x256個乘累加單元(MAC),可以對有符號或無符號整數執行8位乘法和加法。 求和單元(Accumulator)的輸入為16位乘積,輸出和的位寬為32,共有4906個,每個的輸入個數為256。 因此,矩陣單元每個時鐘週期產生一個256元素的部分和。
當使用8位權重和16位啟用函式的混合計算結構時,MMU的計算速度將減半,當它們都是16位,計算速度將減為四分之一。 它每個時鐘週期讀取和寫入256個值,並且可以執行矩陣乘法或卷積。 矩陣單元採用兩個64KiB的權重tile的雙緩衝設計,其中的一個僅在非稀疏模式下才會被啟用,這樣就提升了TPU對於稀疏網路的效能支援。Google相信稀疏性將在未來的設計中佔有優先地位。
矩陣單元的權重通過片上Weight FIFO進行分級,該FIFO從片外8 GiB DRAM讀取(在inference中,權重是隻讀的)。Weight FIFO儲存了四個4個tile。 中間結果儲存在24 MiB片上Unified Buffer中,可作為未來的Matrix單元的輸入。 可程式設計DMA控制器向CPU主機記憶體和Unified Buffer傳輸資料。
圖2顯示了TPU晶片的佈局圖。 24 MiB Unified Buffer幾乎是晶片的三分之一,Matrix Multiply Unit是四分之一,因此資料路徑佔到了整個晶片的三分之二。由於開發時間短,部分設計選取了簡單的值以簡化編譯器設計。 控制邏輯佔到總面積的只有2%。 圖3顯示了搭載在PCB上的TPU實現圖,期介面類似SATA磁碟,可通過PCIe直接接入資料中心。
TPU的指令是通過PCI額發射的,遵循CISC傳統,包括重複欄位。 這些CISC指令的每個指令的平均時鐘週期(CPI)在10到20之間。它總共有大約十多個指令,這裡羅列最關鍵的五個:
(1) Read_Host_Memory
(2) Read_Weights
(3) MatrixMultiply/Convolve
(6) Activation
(5) Write_Host_Memory
其他指令是備用主機記憶體讀/寫,設定配置,兩個版本的同步,中斷主機,除錯Jtag,空操作和停止。 CISC MatrixMultiply指令為12個位元組,其中3個為Unified Buffer地址; 2是累加器地址; 4是長度(有時是卷積的2個維度); 其餘的是操作碼和標誌。TPU微架構的理念是保持MMU的繁忙。 因此,MMC的CISC指令使用4級流水線結構,其中每條指令在其中的單獨一級執行。 其目標是通過將其執行與MatrixMultiply指令重疊來隱藏其他指令(如Read_Weights等)。但,當啟用的輸入或權重資料尚未就緒,矩陣單元將進入等待模式。
由於讀取大型SRAM資料的功耗比算術功耗高的多,所以MMU通過systolic方式減少對Unified Buffer的方位,節省功耗。 圖4顯示了TPU資料流程,輸入從左側流入,權重從頂部載入。 給定的256元乘法累加運算通過矩陣作為對角波前移動。 此過程中權重是預先載入的,並且與資料同步。通過對控制邏輯和資料流水線操作,使得對於MMU而言,256個輸入一次讀取的,並且它們立即更新到256個累加器中的一個個具體位置。 從正確的角度來看,軟體不知道硬體的systoli特性,但是卻需要對於systoilc引起的延時效果有正確的評估。
TPU軟體堆疊必須與為CPU和GPU開發的軟體棧相容,以便應用程式可以快速移植到TPU。在TPU上執行的應用程式的一部分通常寫在TensorFlow中,並被編譯成可以在GPU或TPU上執行的API。像GPU一樣,TPU堆疊分為使用者空間驅動程式和核心驅動程式。核心驅動程式是輕量級的且長期穩定的,只處理記憶體管理和中斷。使用者空間驅動程式頻繁更改。它設定和控制TPU執行,將資料重新格式化為TPU命令,將API呼叫轉換為TPU指令,並將其轉換為應用程式二進位制檔案。使用者空間驅動程式在首次評估模型時編譯模型,快取程式映像並將重量映像寫入TPU的重量儲存器; 第二次和以下評估全速執行。 對於大部分模型,TPU可以從輸入到輸出完整實現。實際操作中,同一時間通常每次進行一層的MMC計算,而其非關鍵路徑操作將被隱藏在MMU操作下。
CPU、GPU與TPU的效能比較
在TPU與CPU和GPU的效能比較部分,Google選擇了兩款並非最新但具有代表性的平臺——Intel Haswell架構的Xeon 5處理器和Nvidia的K80處理器,其整合板卡後的效能對比如下:
以MLP0為例子,7ms的反應時間內TPU可得到的資料處理吞吐率是CPU和GPU的數十倍(但值得指出的是,該benchmark下TPU的計算佔用率要遠遠高於GPU和CPU)。
圖9將K80 GPU和TPU相對於Haswell CPU的幾何平均功耗效能進行了對比,包括兩種計算量程——第一個是“總計”效能/瓦,包括在計算GPU和TPU的效能/瓦特時由主機CPU伺服器消耗的功率。;第二個“增量”效能/瓦,僅包括預先從GPU和TPU中減去主機CPU伺服器的電源餘下的功耗。TPU伺服器的總效能/瓦特比Haswell高出17到34倍,這使得TPU伺服器的效能/ Katt伺服器的功率是14到16倍。 TPU的相對增量效能/瓦特(Google致力於定製ASIC的核心價值)為41到83,這將TPU提升到GPU的效能/瓦特的25到29倍。
在去年5月中旬的Google I/O大會上,Google就已經透露了自己的Tensor Processing Unit(Tensor處理單元)處理器,簡稱TPU。但相關細節,Google卻遲遲沒有公佈,直到這次TPU論文的釋出。
TPU的最新細節
首先需要指出,TPU是一個人工智慧技術專用處理器,在種類上歸屬於ASIC(Application Specific Integrated Circuit,為專門目的而設計的積體電路)。
相比人工智慧技術常見的另外幾種處理器CPU(中央處理器)、GPU(影象處理器)、FPGA(陣列可程式設計邏輯閘陣列),ASIC天生就是為了應用場景而生,所以在效能表現和工作效率上都更加突出。以下是Google硬體工程師 Norm Jouppi 在Google雲端計算部落格上透露的部分效能資訊:
1、在神經網路層面的操作上,處理速度比當下GPU和CPU快15到30倍;
2、在能效比方面,比GPU和CPU高30到80倍;
3、在程式碼上也更加簡單,100到1500行程式碼即可以驅動神經網路;
這要歸功於ASIC本身的特點:處理器的計算部分專門為目標資料設計,100%利用;不需要考慮相容多種情況,控制配套結構非常簡單,間接提升了能效比;可以在硬體層面對軟體層面提前進行優化,優化到位的情況下可以極大減少API介面的工作量。
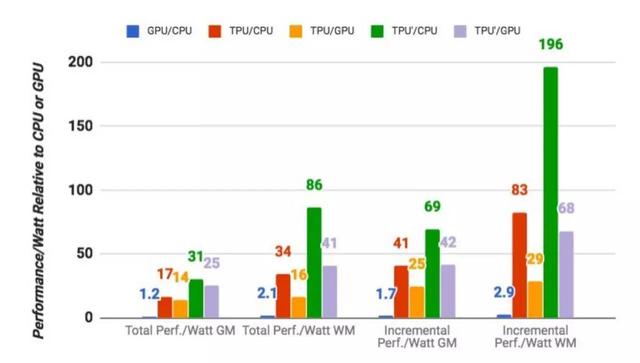
Google也專門對比了在人工智慧場景下TPU相對於CPU/GPU的能效比表現,不同顏色分別對應不同對比物件的結果(注:TPU'是改進版TPU)。可以看到GPU相對於CPU的領先倍數最多隻有2.9,而TPU'對CPU的領先幅度已經達到了196倍,對GPU的領先幅度也達到了68倍。能效比上的突出表現也能直接進行轉化,為使用者帶來更低的使用成本。
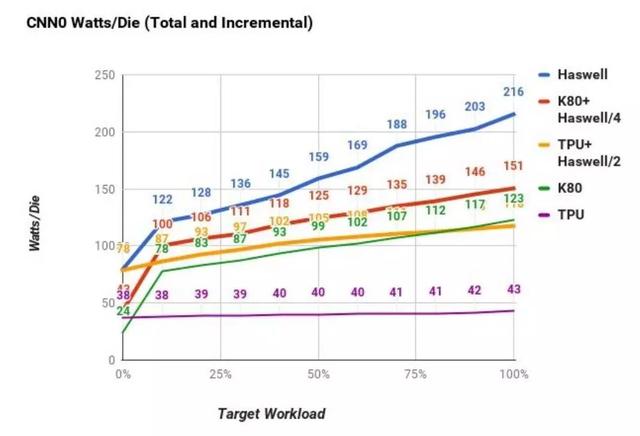
Google另外還對比了單晶片的平臺單位功耗,可以看到TPU在計算任務逐漸加重情況下,功耗浮動不過10%左右。而單CPU伺服器的功耗波動接近300%,絕對功耗數字的更高也讓伺服器需要配備更多散熱資源,無形中也增加成本。

Google這次也公佈了TPU的真實長相,通過板載的DDR3顆粒、PCIE介面可以看出實際尺寸並不算很大。PCB佈局看上去也並不複雜,TPU在中間,上下是DDR3顆粒陣列,左側是供電部分,右側是剩餘配套零件。
值得注意的是,Google還在論文中增加了一段描述:“這塊電路板也可以安裝在伺服器預留的SATA盤位中,但是目前這款卡使用的是 PCIe Gen3 X16介面”。這一方面透露出了TPU的資料吞吐能力,同時也讓人遐想,Google是否會嘗試將其打造成更加通用化的硬體產品,比如適配SATA介面之後對外出售。
業內人士告訴你怎麼看TPU
TPU一出,數倍於CPU、GPU的效能技驚四座。但也有業內人士向Xtecher說出了自己的看法:這個晶片沒有什麼太神奇的地方,雖然效能很驚豔,但是成本也會很高,而且目前TPU並不能單獨使用,還是要配套CPU/GPU。

華登國際合夥人王林也在朋友圈貼出了自己的看法(Xtecher已經獲得了許可):
1、晶片本身設計難度並不大,以floor plan看,data buffe加上乘加器陣列佔了2/3面積,再去掉比較大的兩個DDR3的PHY,一個PCIE Gen3 x16介面,控制電路只有2%。
2、為了降低功耗,提高效能,目前這款TPU的幾個設計指導原則是:增加資料頻寬,減少和host CPU的互動,不讓乘加器陣列閒著。所以用了24MB的片上Memory,多DDR3介面用於資料交換,4階CISC指令流水線保證MatrixMultiply優先順序。帶來的代價就是大的die size,主頻不高。
3、考慮現有生態環境,TPU軟體要和CPU/GPU相容。
4、稀疏化應是TPU以後的開發重點,論文來頭就提到壓縮到8位整數用於inference已經足夠好了。
5、這麼貴的晶片,我也就是看看......
Xtecher也專門採訪了國內創業公司縱目科技CEO唐悅:
這個東西實際跟視訊解碼一個道理,人工智慧你能夠拿CPU來做也可以拿GPU來做,當它演算法相對固定之後,你就可以專門去打造專用硬體。實際上各種各樣的東西都能夠實現一個目標,問題在於靈活度和專業性兩個方向如何把握。如果當前演算法沒有固定,那就應該多用CPU和GPU,如果演算法固定了,那麼就可以嘗試打造專用晶片。而事實上,人工智慧恰巧處於這兩個方向的變化當中。
因為之前神經網路一直在變,完全可程式設計的GPU更加適合用來探索,CPU以為並行能力比較弱還是定位在通用處理器。但隨著人工智慧技術的推進,我們就能夠根據目前人工智慧的需求來專門打造晶片,它比本身為影象運算打造的GPU更加專注,自然效果更好。
這跟很多人現在用FPGA去運算也是一樣的,因為專用的硬體比通用的硬體效能一定更好。反過來說,究竟這個負責人工智慧的處理器叫什麼完全沒有所謂。同樣的,這件事Google可以做,高通也在做,這並不是什麼特別的神奇的東西。
Google自己怎麼說?

去年年中,谷歌全球資料中心網路主管烏爾斯·霍勒澤(Urs H lzle)就曾在公開場合對TPU的一系列問題進行了公開解答:
Google今後還將研發更多這樣的晶片。
Google不會把這種晶片出售給其他公司,不會直接與英特爾或NVIDIA進行競爭。但Google擁有龐大的資料中心,是這兩家公司迄今為止最大的潛在客戶。與此同時,隨著越來越多的企業使用谷歌提供的雲端計算服務,它們自己購買伺服器(和晶片)的數量就會越來越少,也就給晶片市場帶來進一步的衝擊。
TPU目前(當時)主要用來處理Android手機語音識別所需要的“一部分計算”。GPU已經在一點點出局。GPU太通用了,對於機器學習針對性不強。機器學習本來就不是GPU的設計初衷 。
之所以不採用更加方便的方式——直接在FPGA基礎上固化演算法,是因為ASIC快得多。
TPU背後的人工智慧趨勢?

既然TPU只不過是一顆帶有人工智慧“光環”的ASIC,那麼它究竟反映出了什麼趨勢?
首先是專注人工智慧領域硬體的市場巨大,雖然CPU/GPU已經提供了通用運算能力,但是效能更好,能效比更高的FPGA、ASIC需求日趨強烈。
二個是隨著人工智慧技術的進一步發展,硬體專業化趨勢不可避免。就像比特幣挖礦一樣,主力挖礦裝置從CPU到GPU,從GPU到FPGA,最後再到ASIC。
除了Google,很多公司其實也在進行著類似的專業化硬體開發工作,相信不久的將來,一大批專業化硬體的出現將會為人工智慧的發展再次注入動力,促進更多應用場景和更優質服務的出現。
總的來看,TPU的確算是人工智慧發展歷程中的一個“小里程碑”,但真的沒有什麼好大驚小怪的。