
CUDA學習筆記(2) 第一個CUDA程式
首先,我們用VisualStudio建立了CUDA的工程後,會出現一個數組對應位置元素求和的模版程式碼,我們可以先借此瞭解CUDA工程的主體結構,然後將他們全都刪掉,從頭開始練習。
假設我們現在要建立384個執行緒,並要知道他們具體屬於哪個執行緒束(Warp)、執行緒塊(Block),執行緒序號是多少。
在 main() 函式中,我主要執行以下幾個步驟:
1. 讀取GPU硬體資訊。
2. 計算。
3. 重置GPU。
其中前兩步需要我們自己具體設計,重置GPU可以直接呼叫官方的函式。
int main(int argc, char *argv[])
{
cudaError_t cudaStatus;
// 讀取、檢查裝置資訊
第一步,我們需要包含對應的標頭檔案,並新增對應的包含目錄。
// CUDA
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
// includes CUDA Runtime
#include <cuda_runtime.h>
// includes, project
#include <helper_cuda.h>
#include <helper_functions.h>
// C IO
#include <stdio.h>
// C++ IOstream
#include <iostream>
第二步,我們讀取GPU的硬體屬性,並記錄每個執行緒塊的最大執行緒數。
// 塊最大執行緒數
int max_thread_per_block = 0;
// CUDA檢查裝置資訊
void check_Cuda_information(int main_argc, char ** main_argv);
// 檢查顯示卡硬體屬性
void check_Cuda_information(int main_argc, char ** main_argv)
{
// 裝置ID
int devID;
// 裝置屬性
cudaDeviceProp deviceProps;
// 獲取裝置ID
devID = findCudaDevice(main_argc, (const char **)main_argv);
// 獲取GPU資訊
checkCudaErrors(cudaGetDeviceProperties(&deviceProps, devID));
cout << "devID = " << devID << endl;
// 顯示卡名稱
cout << "CUDA device is \t\t\t" << deviceProps.name << endl;
// 每個 執行緒塊(Block)中的最大執行緒數
cout << "CUDA max Thread per Block is \t" << deviceProps.maxThreadsPerBlock << endl;
max_thread_per_block = deviceProps.maxThreadsPerBlock;
}
第三步,編寫一個CUDA計算函式,執行以下步驟:
1.定義主機變數(Host,指CPU部分及記憶體中的資料),定義裝置(Device,指GPU及視訊記憶體中的資料)變數。
cudaError_t cudaStatus; 用來接收CUDA官方函式的返回值,檢驗函式是否正確執行。
// CUDA計算部分
// CUDA計算部分
// Helper function for using CUDA to add vectors in parallel.
cudaError_t caculate_Cuda_function()
{
cudaError_t cudaStatus;
// my_check_CUDA_status 呼叫計數,方便除錯查錯
int use_counter = 0;
// Host變數(記憶體)
int ARRAY_LENGTH = 3 * 2 * 64;
int *thread_index, *warp_index, *block_index;
thread_index = (int*)malloc(ARRAY_LENGTH * sizeof(int));
warp_index = (int*)malloc(ARRAY_LENGTH * sizeof(int));
block_index = (int*)malloc(ARRAY_LENGTH * sizeof(int));
// Device變數(視訊記憶體)
int *dev_thread_index = NULL, *dev_warp_index = NULL, *dev_block_index = NULL;
2.選擇我們準備使用的GPU。
// 選擇我們準備使用的裝置,在有多塊GPU的電腦中,這一步十分重要!
cudaStatus = cudaSetDevice(0);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaSetDevice failed! Do you have a CUDA-capable GPU installed?");
goto Error;
}3.分配視訊記憶體,cudaMalloc有兩個輸入引數,一個返回值。
- 第一個是 指標變數的地址 ,指標變數dev_thread_index本身存放在記憶體中,而他的內容是視訊記憶體的地址!
- 第二個是分配的視訊記憶體大小。
- 返回值表示函式是否正確的執行。
// 分配視訊記憶體
cudaStatus = cudaMalloc((void**)&dev_thread_index, ARRAY_LENGTH * sizeof(int));
if (!my_check_CUDA_status(cudaStatus, use_counter)) goto Error;
cudaStatus = cudaMalloc((void**)&dev_warp_index, ARRAY_LENGTH * sizeof(int));
if (!my_check_CUDA_status(cudaStatus, use_counter)) goto Error;
cudaStatus = cudaMalloc((void**)&dev_block_index, ARRAY_LENGTH * sizeof(int));
if (!my_check_CUDA_status(cudaStatus, use_counter)) goto Error;這裡我定義一個行內函數 my_check_CUDA_status 來判斷GPU是否正確執行,如果發生錯誤,則輸出在第幾次呼叫這個函式時發生的錯誤,以便快速定位錯誤的程式碼。
// 檢查指令在GPU是否正確執行
inline bool my_check_CUDA_status(cudaError_t inline_cudaStatus, int & use_counter)
{
use_counter++;
if (inline_cudaStatus != cudaSuccess)
{
fprintf(stderr, "CUDA failed! use_counter = %d\r\n", use_counter);
cout << "inline_cudaStatus = " << inline_cudaStatus << endl;
return false;
}
else
{
return true;
}
}4.在編寫核函式時我們一般會用到幾個CUDA已經定義好的變數:
| 變數名 | 說明 |
|---|---|
| threadIdx.x, threadIdx.y, threadIdx.z | 執行緒(Thread) x、y、z三個維度的下標 |
| blockIdx.x, blockIdx.y, blockIdx.z | 執行緒塊(Block) x、y、z三個維度的下標 |
| blockDim.x, blockDim.y, blockDim.z | 一個執行緒塊(Block)單元中x、y、z三個維度的執行緒(Thread)的數量 |
| gridDim.x, gridDim.y, gridDim.z | 一個執行緒網格(Grid)單元中x、y、z三個維度的執行緒塊(Block)的數量 |
| warpSize | 執行緒束(Warp)的大小(一般為32) |
這裡舉一個執行緒塊(Block)和執行緒網格(Grid)都是二維情況的例子:
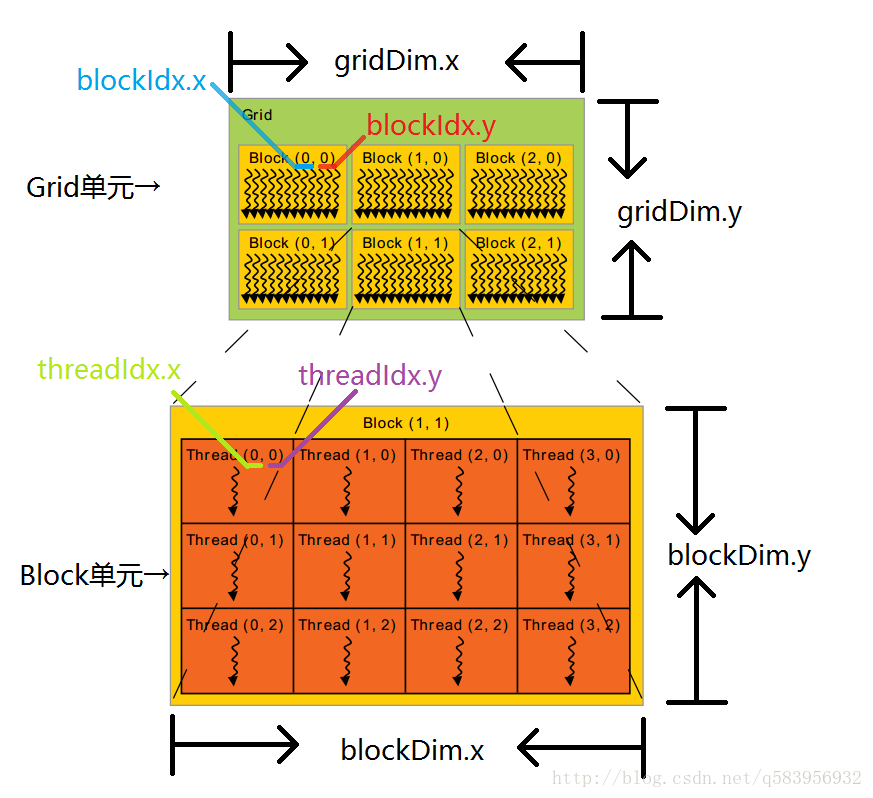
在核函式中__global__字首表示這個函式或變數是一個全域性的,int block_index和int thread_index作為每個流處理器的暫存器變數,分別記錄當前執行緒的執行緒序號與所在的執行緒塊序號。核函式必須為void型別且不能有return!
__global__ void Kernel_func(int * thread_index_array, int * warp_index_array, int * block_index_array)
{
int block_index = blockIdx.x + blockIdx.y * gridDim.x + blockIdx.z * gridDim.x * gridDim.y;
int thread_index = block_index * blockDim.x * blockDim.y * blockDim.z + \
threadIdx.x + threadIdx.y * blockDim.x + threadIdx.z * blockDim.x * blockDim.y;
thread_index_array[thread_index] = thread_index;
warp_index_array[thread_index] = thread_index / warpSize;
block_index_array[thread_index] = block_index;
}那麼如何編寫一個合理、高效的核函式呢,我們必須瞭解以下幾個GPU底層的工作原理。
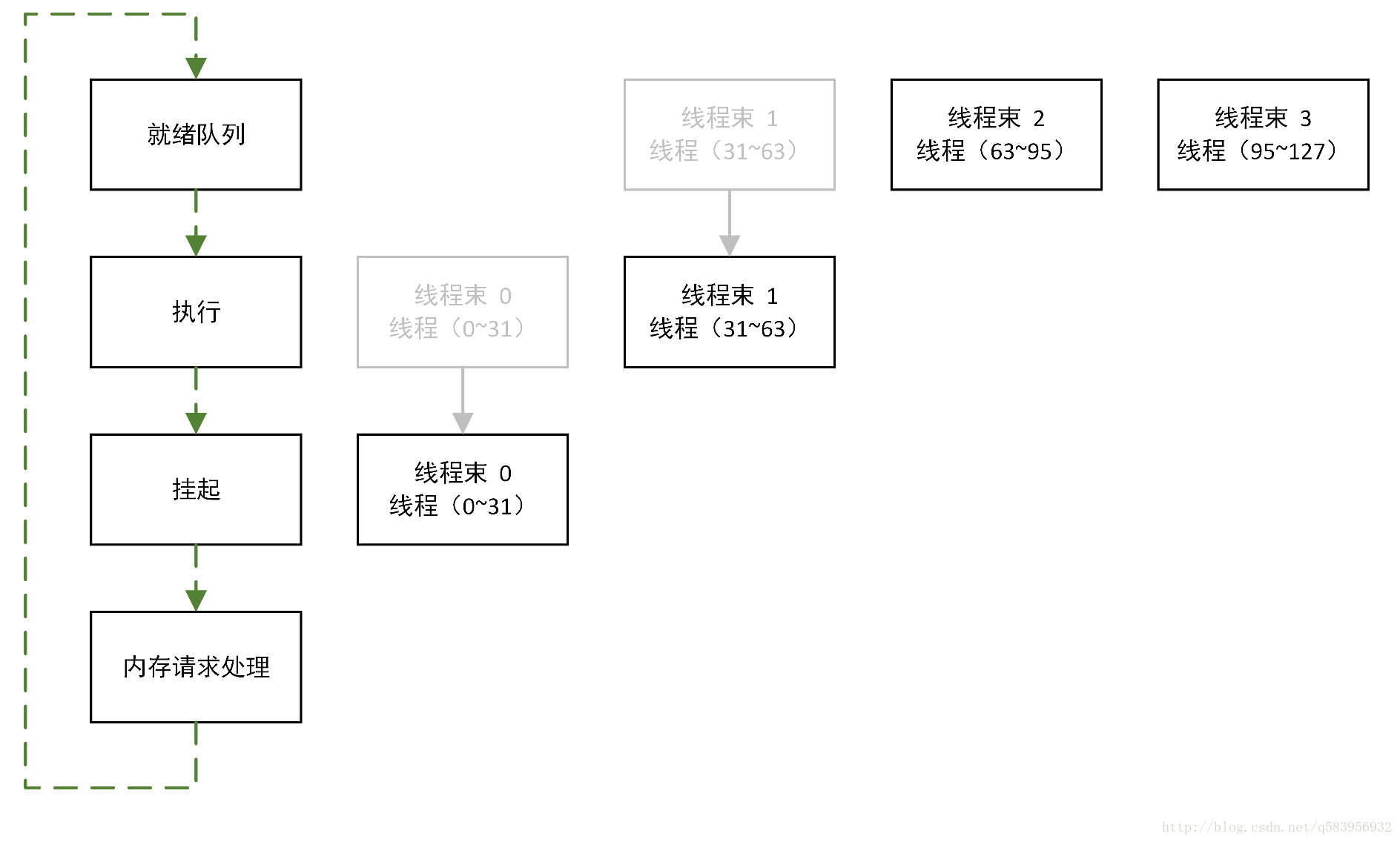
在GPU中,每32個執行緒作為一個執行緒束(Warp)一起執行,一個執行緒束(Warp)同時執行讀取視訊記憶體等操作,所以執行緒塊(Block)中一個單元的大小最好大於32且為32的整數倍,這樣才能儘可能讓GPU高效地執行。
如上圖所示(參考自1),128個執行緒分為4個執行緒束,執行緒束0到3依次被處理記憶體請求,只需要4次週期操作就可以完成對視訊記憶體資料的讀寫。若一個執行緒塊中只有一個執行緒,那麼就會有128次記憶體請求,這樣使得程式的執行大打折扣。
NVIDIA公司在編寫CUDA的時候為使用者提供了一個叫做 dim3 的結構體,用來定義執行緒塊(Block)與執行緒網格(Grid)每一個單元的大小。下面是原始碼,我們可以看到它其實是由3個int組成的結構體,分別代表x、y、z三個維度的下標最大值。
struct __device_builtin__ dim3
{
unsigned int x, y, z;
#if defined(__cplusplus)
__host__ __device__ dim3(unsigned int vx = 1, unsigned int vy = 1, unsigned int vz = 1) : x(vx), y(vy), z(vz) {}
__host__ __device__ dim3(uint3 v) : x(v.x), y(v.y), z(v.z) {}
__host__ __device__ operator uint3(void) { uint3 t; t.x = x; t.y = y; t.z = z; return t; }
#endif /* __cplusplus */
};CUDA的核函式的呼叫方法如下,規定使用“<<<”和“>>>”符號來寫CUDA必要的引數列表,即執行緒塊(Block)與執行緒網格(Grid)每一個單元的大小。後面圓括號中的內容是我們需要傳入的視訊記憶體內資料的地址(指標)。
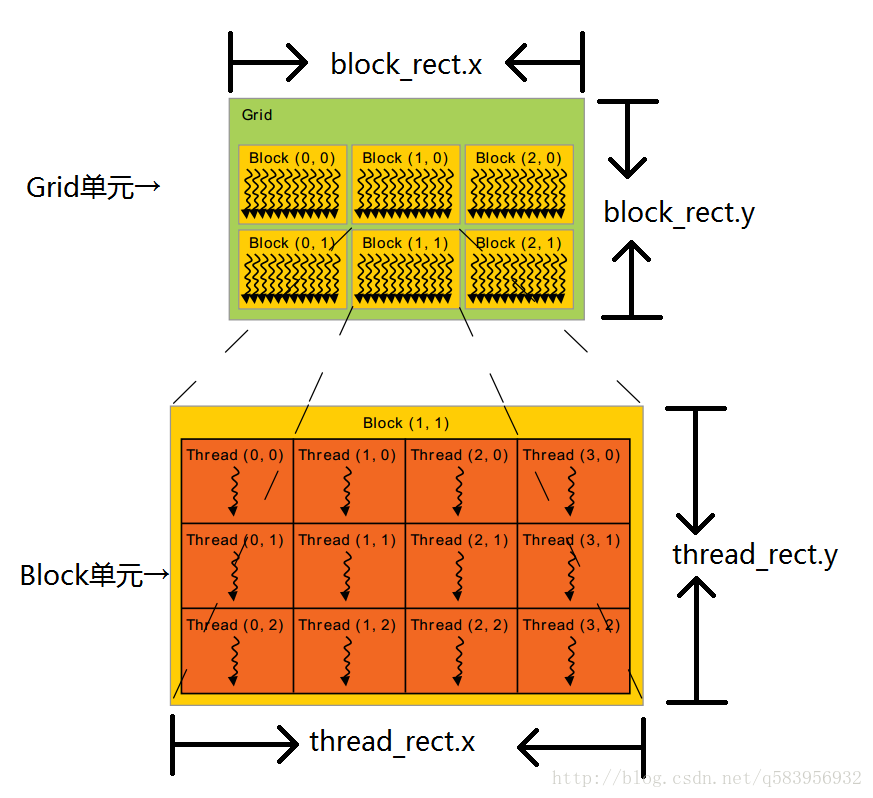
// 定義網格的大小(block_rect)、塊的大小(thread_rect)
dim3 block_rect(3, 2, 1), thread_rect(64, 1, 1);
cout << "block_rect :\t" << block_rect.x << "\t" << block_rect.y << "\t" << block_rect.z << "\t" << endl;
cout << "thread_rect :\t" << thread_rect.x << "\t" << thread_rect.y << "\t" << thread_rect.z << "\t" << endl;
// GPU開始計算(傳入核函式)
Kernel_func <<< block_rect, thread_rect >>>(dev_thread_index, dev_warp_index, dev_block_index);- block_rect是指執行緒網格(Grid)的一個單元中容納block各維度的數量。
- thread_rect是執行緒塊(Block)一個單元中容納thread各維度的數量。當然執行緒塊(Block)一個單元中容納thread各維度的數量不能超過對應架構GPU所規定的量,即maxThreadsPerBlock。
例如maxThreadsPerBlock為1024,那麼 (thread_rect.x * thread_rect.y * thread_rect.z)的值不能超過1024。
5.檢查核函式是否正常執行。
// 檢查核函式執行是否報錯
cudaStatus = cudaGetLastError();
if (!my_check_CUDA_status(cudaStatus, use_counter)) goto Error;
// 與GPU同步,並檢查是否出現錯誤
cudaStatus = cudaDeviceSynchronize();
if (!my_check_CUDA_status(cudaStatus, use_counter)) goto Error;6.傳出資料
// 傳出資料
cudaStatus = cudaMemcpy(thread_index, dev_thread_index, ARRAY_LENGTH * sizeof(int), cudaMemcpyDeviceToHost);
if (!my_check_CUDA_status(cudaStatus, use_counter)) goto Error;
cudaStatus = cudaMemcpy(warp_index, dev_warp_index, ARRAY_LENGTH * sizeof(int), cudaMemcpyDeviceToHost);
if (!my_check_CUDA_status(cudaStatus, use_counter)) goto Error;
cudaStatus = cudaMemcpy(block_index, dev_block_index, ARRAY_LENGTH * sizeof(int), cudaMemcpyDeviceToHost);
if (!my_check_CUDA_status(cudaStatus, use_counter)) goto Error;7.錯誤處理及記憶體、視訊記憶體釋放。
Error:
// 釋放視訊記憶體
cudaFree(dev_thread_index);
cudaFree(dev_warp_index);
cudaFree(dev_block_index);
// 釋放記憶體
free(thread_index);
free(block_index);
free(warp_index);總結:
我認為使用CUDA的過程可以分為以下幾個步驟:
1. 讀取GPU硬體資訊,以保證我們的程式碼可以相容、高效地在不同型號GPU上執行。
2. 選擇我們要使用的GPU序號,這一步在有多塊GPU的平臺上尤為重要。
3. 申請全域性視訊記憶體。
4. 呼叫一次核函式。
5. CPU與GPU同步(通訊),以檢查GPU計算過程是否出錯,並讀出所需資料。
6. 釋放視訊記憶體,重置GPU。
值得注意的是,每呼叫一次核函式,就必須執行一次步驟5檢查執行狀況,之後才能再呼叫一次核函式。
我的 learn_CUDA_02.cu 完整程式碼:
// CUDA
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
// includes CUDA Runtime
#include <cuda_runtime.h>
// includes, project
#include <helper_cuda.h>
#include <helper_functions.h> // helper utility functions
// C IO
#include <stdio.h>
// C++ IOstream
#include <iostream>
using namespace std;
// CUDA檢查裝置資訊
void check_Cuda_information(int main_argc, char ** main_argv);
// CUDA計算部分
cudaError_t caculate_Cuda_function();
// 塊最大執行緒數
int max_thread_per_block = 0;
__global__ void Kernel_func(int * thread_index_array, int * warp_index_array, int * block_index_array)
{
int block_index = blockIdx.x + blockIdx.y * gridDim.x + blockIdx.z * gridDim.x * gridDim.y;
int thread_index = block_index * blockDim.x * blockDim.y * blockDim.z + \
threadIdx.x + threadIdx.y * blockDim.x + threadIdx.z * blockDim.x * blockDim.y;
thread_index_array[thread_index] = thread_index;
warp_index_array[thread_index] = thread_index / warpSize;
block_index_array[thread_index] = block_index;
}
int main(int argc, char *argv[])
{
cudaError_t cudaStatus;
// 讀取、檢查裝置資訊
check_Cuda_information(argc, argv);
// 計算部分
cudaStatus = caculate_Cuda_function();
// cudaDeviceReset must be called before exiting in order for profiling and
// tracing tools such as Nsight and Visual Profiler to show complete traces.
cudaStatus = cudaDeviceReset();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaDeviceReset failed!");
return 1;
}
return 0;
}
// 檢查顯示卡硬體屬性
void check_Cuda_information(int main_argc, char ** main_argv)
{
// 裝置ID
int devID;
// 裝置屬性
cudaDeviceProp deviceProps;
//
cout << "argc = " << main_argc << endl;
for (int i = 0; i < main_argc; i++)
{
printf("argv[%d] = %s\r\n", i, main_argv[i]);
}
cout << endl;
// 獲取裝置ID
devID = findCudaDevice(main_argc, (const char **)main_argv);
// 獲取GPU資訊
checkCudaErrors(cudaGetDeviceProperties(&deviceProps, devID));
cout << "devID = " << devID << endl;
// 顯示卡名稱
cout << "CUDA device is \t\t\t" << deviceProps.name << endl;
// 每個 執行緒塊(Block)中的最大執行緒數
cout << "CUDA max Thread per Block is \t" << deviceProps.maxThreadsPerBlock << endl;
max_thread_per_block = deviceProps.maxThreadsPerBlock;
// 每個 多處理器組(MultiProcessor)中的最大執行緒數
cout << "CUDA max Thread per SM is \t" << deviceProps.maxThreadsPerMultiProcessor << endl;
// GPU 中 SM 的數量
cout << "CUDA SM counter\t\t\t" << deviceProps.multiProcessorCount << endl;
// 執行緒束大小
cout << "CUDA Warp size is \t\t" << deviceProps.warpSize << endl;
// 每個SM中共享記憶體的大小
cout << "CUDA shared memorize is \t" << deviceProps.sharedMemPerMultiprocessor << "\tbyte" << endl;
}
// 檢查指令在GPU是否正確執行
inline bool my_check_CUDA_status(cudaError_t inline_cudaStatus, int & use_counter)
{
use_counter++;
if (inline_cudaStatus != cudaSuccess)
{
fprintf(stderr, "CUDA failed! use_counter = %d\r\n", use_counter);
cout << "inline_cudaStatus = " << inline_cudaStatus << endl;
return false;
}
else
{
return true;
}
}
// CUDA計算部分
// Helper function for using CUDA to add vectors in parallel.
cudaError_t caculate_Cuda_function()
{
cudaError_t cudaStatus;
// my_check_CUDA_status 呼叫計數,方便除錯查錯
int use_counter = 0;
// Host變數(記憶體)
const int ARRAY_LENGTH = 3 * 2 * 64;
int *thread_index, *warp_index, *block_index;
thread_index = (int*)malloc(ARRAY_LENGTH * sizeof(int));
warp_index = (int*)malloc(ARRAY_LENGTH * sizeof(int));
block_index = (int*)malloc(ARRAY_LENGTH * sizeof(int));
// Device變數(視訊記憶體)
int *dev_thread_index = NULL, *dev_warp_index = NULL, *dev_block_index = NULL;
#pragma region(選擇GPU)
// Choose which GPU to run on, change this on a multi-GPU system.
cudaStatus = cudaSetDevice(0);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaSetDevice failed! Do you have a CUDA-capable GPU installed?");
goto Error;
}
#pragma endregion
#pragma region(分配視訊記憶體、傳入資料)
// 分配視訊記憶體
cudaStatus = cudaMalloc((void**)&dev_thread_index, ARRAY_LENGTH * sizeof(int));
if (!my_check_CUDA_status(cudaStatus, use_counter)) goto Error;
cudaStatus = cudaMalloc((void**)&dev_warp_index, ARRAY_LENGTH * sizeof(int));
if (!my_check_CUDA_status(cudaStatus, use_counter)) goto Error;
cudaStatus = cudaMalloc((void**)&dev_block_index, ARRAY_LENGTH * sizeof(int));
if (!my_check_CUDA_status(cudaStatus, use_counter)) goto Error;
#pragma endregion
#pragma region(執行核函式,並在核函式完成時檢查錯誤報告)
// 定義網格的大小(block_rect)、塊的大小(thread_rect)
dim3 block_rect(3, 2, 1), thread_rect(64, 1, 1);
cout << "block_rect :\t" << block_rect.x << "\t" << block_rect.y << "\t" << block_rect.z << "\t" << endl;
cout << "thread_rect :\t" << thread_rect.x << "\t" << thread_rect.y << "\t" << thread_rect.z << "\t" << endl;
// GPU開始計算(傳入核函式)
Kernel_func <<< block_rect, thread_rect >>>(dev_thread_index, dev_warp_index, dev_block_index);
// 檢查核函式執行是否報錯
cudaStatus = cudaGetLastError();
if (!my_check_CUDA_status(cudaStatus, use_counter)) goto Error;
// 與GPU同步,並檢查是否出現錯誤
cudaStatus = cudaDeviceSynchronize();
if (!my_check_CUDA_status(cudaStatus, use_counter)) goto Error;
#pragma endregion
#pragma region(傳出資料)
// 傳出資料
cudaStatus = cudaMemcpy(thread_index, dev_thread_index, ARRAY_LENGTH * sizeof(int), cudaMemcpyDeviceToHost);
if (!my_check_CUDA_status(cudaStatus, use_counter)) goto Error;
cudaStatus = cudaMemcpy(warp_index, dev_warp_index, ARRAY_LENGTH * sizeof(int), cudaMemcpyDeviceToHost);
if (!my_check_CUDA_status(cudaStatus, use_counter)) goto Error;
cudaStatus = cudaMemcpy(block_index, dev_block_index, ARRAY_LENGTH * sizeof(int), cudaMemcpyDeviceToHost);
if (!my_check_CUDA_status(cudaStatus, use_counter)) goto Error;
#pragma endregion
for (int i = 0; i < ARRAY_LENGTH; i++)
{
printf("thread index \t: %d\t", thread_index[i]);
printf("warp flag \t: %d\t", warp_index[i]);
printf("block index \t: %d\t\r\n", block_index[i]);
}
Error:
// 釋放視訊記憶體
cudaFree(dev_thread_index);
cudaFree(dev_warp_index);
cudaFree(dev_block_index);
// 釋放記憶體
free(thread_index);
free(block_index);
free(warp_index);
return cudaStatus;
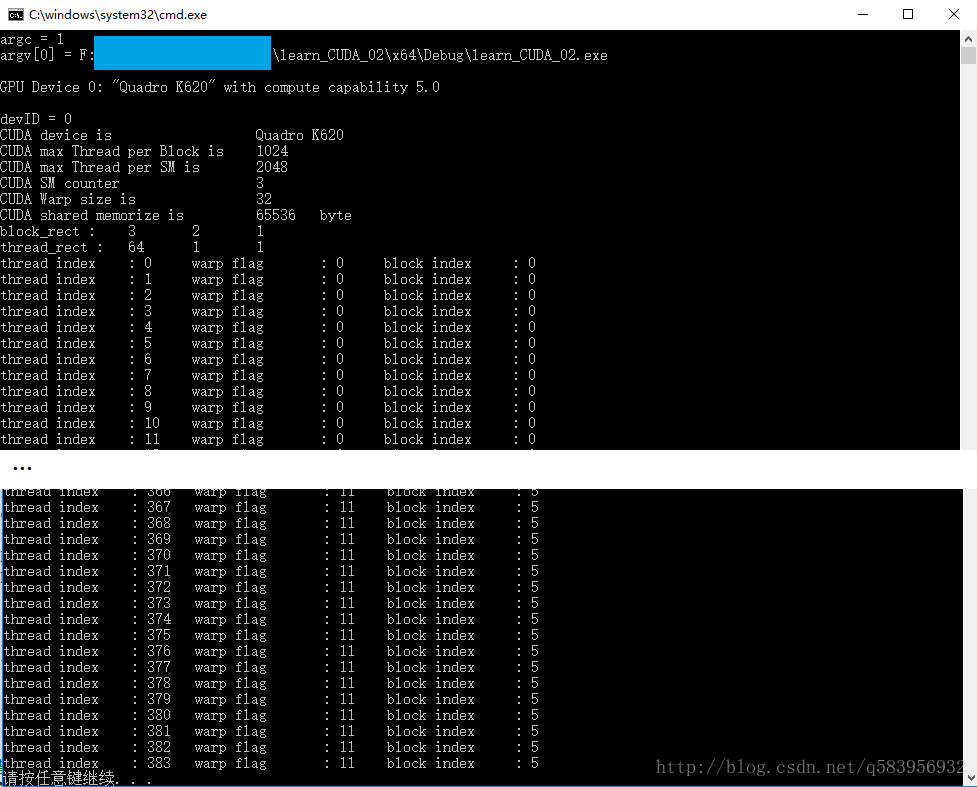
}執行結果:
參考:
1.《CUDA並行程式設計》機械工業出版社