
深度學習與人臉識別系列(3)__基於VGGNet的人臉識別系統
作者:wjmishuai
1.引言
本文中介紹的人臉識別系統是基於這兩篇論文:
第一篇論文介紹了海量資料集下的圖片檢索方法。第二篇文章將這種思想應用到人臉識別系統中,實現基於深度學習的人臉識別。2.關於深度學習的簡要介紹
現階段為止,對於影象分類來說,都是使用人工提取特徵的方式來提取影象的特徵。為了提高識別的準確率,我們首先需要收集大量的資料,然後利用更強大的模型提取特徵,並使用更好的演算法來防止過擬合。直到最近幾年,帶有標籤的資料集的規模還是很小的。如果識別任務比較簡單,利用小規模的資料集完全可以。例如,針對MNIST資料集上的數字識別程式已經接近人類的識別能力了3. 人臉識別系統的原理
神經網路提取特徵的過程:一張人臉圖片是由基本的edge構成。但是更結構化,更復雜,具有概念性的特徵如何表示?這就需要更高層次的特徵表示,比如V2,V4。因此V1是畫素級特徵。V2看V1是畫素級的,層次遞進,高層表達由低層表達的組合而成。專業點說就是基basis。V1取提出的basis是邊緣,然後V2層是V1層這些basis的組合,這時候V2區得到的又是高一層的basis。即上一層的basis組合的結果,上上層又是上一層的組合basis……

直觀上說,就是找到make sense的小patch再將其進行combine,就得到了上一層的feature,遞迴地向上learning feature。
在不同object上做training是,所得的edge basis 是非常相似的,但object parts和models 就會completely different了(那咱們分辨car或者face是不是容易多了):

從文字來說,一個doc表示什麼意思?我們描述一件事情,用什麼來表示比較合適?用一個一個字嘛,我看不是,字就是畫素級別了,起碼應該是term,換句話說每個doc都由term構成,但這樣表示概念的能力就夠了嘛,可能也不夠,需要再上一步,達到topic級,有了topic,再到doc就合理。但每個層次的數量差距很大,比如doc表示的概念->topic(千-萬量級)->term(10萬量級)->word(百萬量級)
VGG_Face 網路的配置,列出了每一層濾波器的大小和數量,並且指明瞭步長和padding的方式:
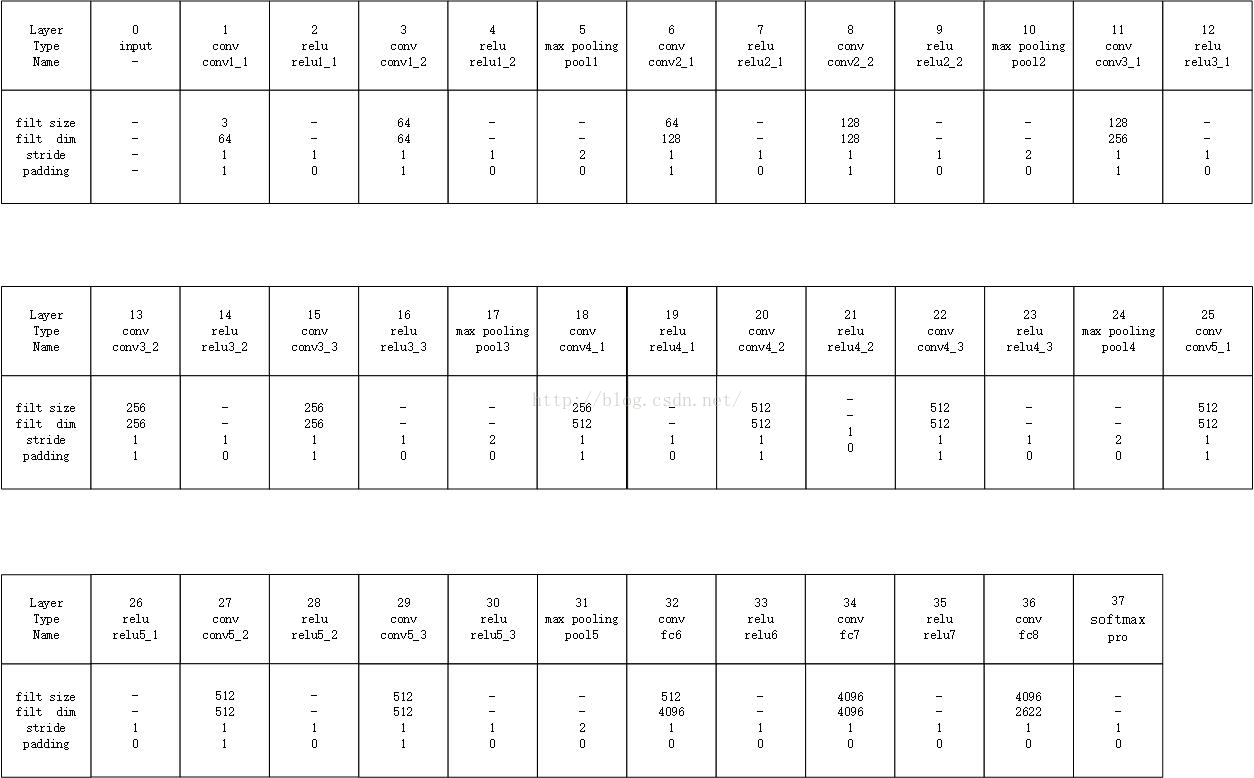
4. 模型的訓練過程
如果沒有實驗條件的話,不建議訓練vgg_net。時間太長了,除非你有泰坦x顯示卡或者更好的顯示卡,這裡給出訓練的過程(基於caffe框架),有條件的可以做一下: