
2018.06.06論文:12個NLP分類模型
1 概述
這個庫 的目的是探索用深度學習進行NLP文字分類的方法。它具有文字分類的各種基準模型。
雖然這12個模型都很簡單,可能不會讓你在這項文字分類任務中游刃有餘,但是這些模型中的其中一些是非常經典的,因此它們可以說是非常適合作為基準模型的。每個模型在模型型別(github程式碼)下都有一個測試函式。這個幾個模型也可以用於構建問答系統,或者是序列生成。
1.1模型概覽
這篇文章介紹的模型有以下:
- 1.fastText
- 2.TextCNN
- 3.TextRNN
- 4.RCNN
- 5.分層注意網路(Hierarchical Attention Network)
- 6.具有注意的seq2seq模型(seq2seq with attention)
- 7.Transformer(“Attend Is All You Need”)
- 8.動態記憶網路(Dynamic Memory Network)
- 9.實體網路:追蹤世界的狀態
- 10.Ensemble models
- 11.Boosting:
該模型是多模型堆疊而來的。每一層都是一個模型。結果將基於加在一起的logits,層之間的唯一連結是標籤權重。每個標籤的淺層預測誤差率將成為下一層的權重。那些錯誤率很高的標籤會有很大的權重。所以後面的層將更加關注那些錯誤預測的標籤,並試圖修復前一層的誤差。結果是,我們可以得到一個很強大的模型。檢視: a00_boosting/boosting.py
還包括一下其他模型:
- 1.BiLstm Text Relation
- 2.Two CNN Text Relation
- 3.BiLstm Text Relation Two RNN
1.2各模型效果對比:
效能(多標籤標籤預測任務,要求預測能夠達到前5,300萬訓練資料,滿分:0.5)

1.4 程式碼用法:
模型在xxx_model.py中
執行python xxx_train.py來訓練模型
執行python xxx_predict.py進行推理(測試)。
- 執行環境:
python 2.7+tensorflow 1.1
TextCNN 模型已經可以轉換成python 3.6版本
- 注意:
一些util函式是在data_util.py中的;典型輸入如:“x1 x2 x3 x4 x5 label 323434”,其中“x1,x2”是單詞,“323434”是標籤;它具有一個將預訓練的單詞載入和分配嵌入到模型的函式,其中單詞嵌入在word2vec或fastText中進行預先訓練。
2 模型細節:
2.1 快速文字(fastText)
介紹
FastText是Facebook開發的一款快速文字分類器,提供簡單而高效的文字分類和表徵學習的方法,不過這個專案其實是有兩部分組成的:
- 一部分是 文字分類paper:A. Joulin, E. Grave, P. Bojanowski, T. Mikolov, Bag of Tricks for Efficient Text
Classification(高效文字分類技巧)。 - 另一部分是詞嵌入學習(paper:P. Bojanowski*, E. Grave*, A. Joulin, T. Mikolov, Enriching Word Vectors with Subword Information(使用子字資訊豐富詞彙向量))。
fastText是Facebook於2016年開源的一個詞向量計算和文字分類工具,在學術上並沒有太大創新。但是它的優點也非常明顯,在文字分類任務中,fastText(淺層網路)往往能取得和深度網路相媲美的精度,卻在訓練時間上比深度網路快許多數量級。在標準的多核CPU上, 能夠訓練10億詞級別語料庫的詞向量在10分鐘之內。可以看出fastText有兩個主要的特點:
1. 速度很快
2. 在速度的基礎上精度較高 。
對應的解決辦法就是:
- 層級簡單 + embedding疊加 + 分層Softmax
- 字元級別的n-gram
解釋
- 快的原因:
- 層級簡單:
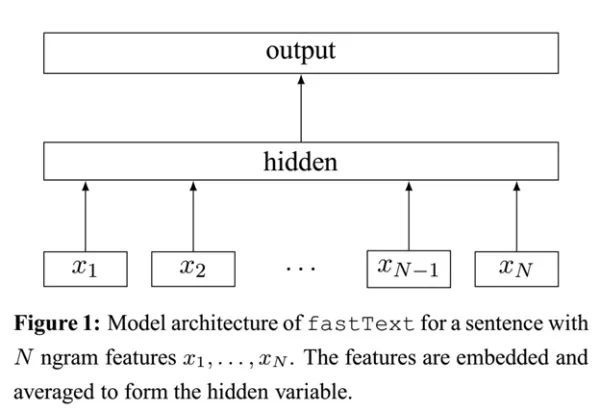
- 單詞的embedding疊加獲得的文件向量. 全連線引數由 n * L * 1024 變成 1 * L * 1024
- 在輸出時,fastText採用了分層Softmax,大大降低了模型訓練時間:
- 層級簡單:
標準的Softmax迴歸中,要計算y=j時的Softmax概率:,我們需要對所有的K個概率做歸一化,這在|y|很大時非常耗時。於是,分層Softmax誕生了,它的基本思想是使用樹的層級結構替代扁平化的標準Softmax,使得在計算時,只需計算一條路徑上的所有節點的概率值,無需在意其它的節點。
下圖是一個分層Softmax示例:
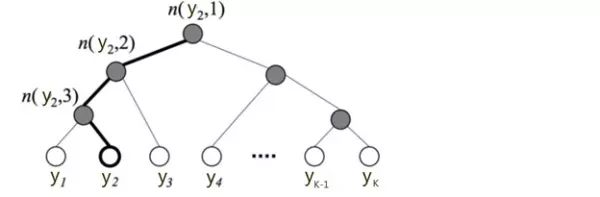
樹的結構是根據類標的頻數構造的霍夫曼樹。K個不同的類標組成所有的葉子節點,K-1個內部節點作為內部引數,從根節點到某個葉子節點經過的節點和邊形成一條路徑。從根節點走到葉子節點,實際上是在做了3次二分類的邏輯迴歸。通過分層的Softmax,計算複雜度一下從|K|降低到log|K|。
- 準的原因:字元級別的n-gram:
word2vec把語料庫中的每個單詞當成原子的,它會為每個單詞生成一個向量。這忽略了單詞內部的形態特徵,比如:“apple” 和“apples”,“達觀資料”和“達觀”,這兩個例子中,兩個單詞都有較多公共字元,即它們的內部形態類似,但是在傳統的word2vec中,這種單詞內部形態資訊因為它們被轉換成不同的id丟失了。
為了克服這個問題,fastText使用了字元級別的n-grams來表示一個單詞。對於單詞“apple”,假設n的取值為3,則它的trigram有:
“<ap”, “app”, “ppl”, “ple”, “le>”其中,<表示字首,>表示字尾。於是,我們可以用這些trigram來表示“apple”這個單詞,進一步,我們可以用這5個trigram的向量疊加來表示“apple”的詞向量。
這帶來兩點好處:(論文中怎麼說》》》》》????)
對於低頻詞生成的詞向量效果會更好。因為它們的n-gram可以和其它詞共享。
對於訓練詞庫之外的單詞,仍然可以構建它們的詞向量。我們可以疊加它們的字元級n-gram向量。
總結
於是fastText的核心思想就是:將整篇文件的詞及n-gram向量疊加平均得到文件向量,然後使用文件向量做softmax多分類。這中間涉及到兩個技巧:字元級n-gram特徵的引入以及分層Softmax分類。github程式碼:p5_fastTextB_model.py
2.2文字卷積神經網路(Text CNN)
《卷積神經網路進行句子分類》ConvolutionalNeuralNetworksforSentenceClassification論文的實現
結構:降維—> conv —> 最大池化 —>完全連線層——–> softmax
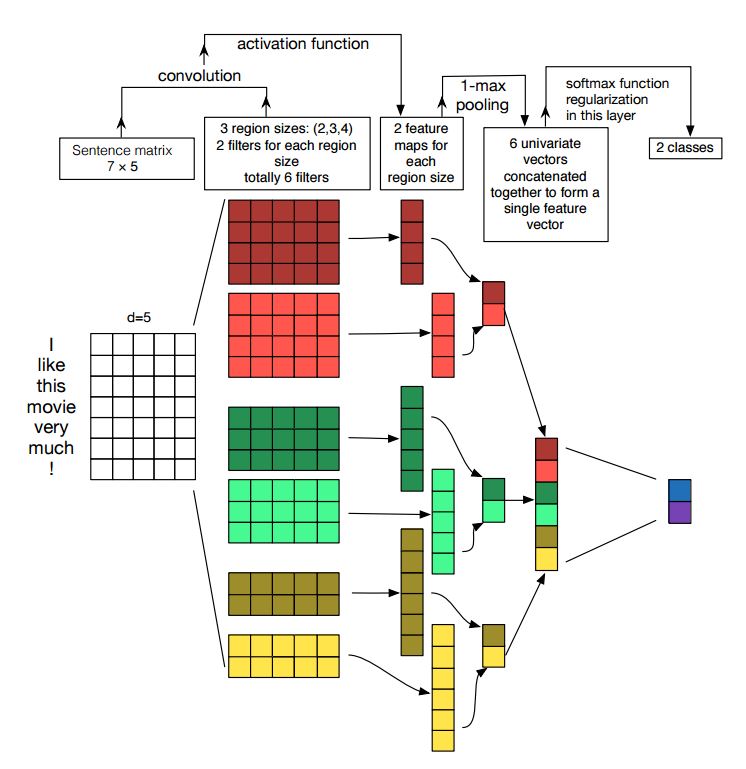
卷積神經網路是解決計算機視覺問題的主要手段。 現在我們將展示CNN如何用於NLP,特別是文字分類。句子長度會略有不同。 所以我們將使用padding來獲得固定長度,n。
對於句子中的每個標記,我們將使用單詞嵌入來獲得一個固定的維度向量d。 所以我們的輸入是一個二維矩陣:(n,d)。這跟CNN用於圖象是類似的。
首先,我們將對我們的輸入進行卷積計算。他是濾波器和輸入部分之間的元素乘法。我們使用k個濾波器,每個濾波器是一個二維矩陣(f,d)注意d與詞向量的長度相同。現在輸出的將是k個列表,每個列表的長度是n-f+1。每個元素是標量(scalar)。請注意,第二維將始終是單詞嵌入的維度。我們使用不同的大小的濾波器從文字輸入中獲取豐富的特徵,這與n-gram特徵是類似的。
其次,我們將卷積運算的輸出做最大池化。對於k個特徵對映,我們將得到k個標量。
第三,我們將連線所有標量來獲得最終的特徵。他是一個固定大小的向量。它與我們使用的濾波器的大小無關。
最後,我們將使用全連線層把這些特徵對映到之前定義的標籤。
2.3文字迴圈神經網路(Text RNN)
Github 程式碼檢視:p8_Text RNN_model.py
儘管TextCNN能夠在很多工裡面能有不錯的表現,但CNN有個最大問題是固定 filter_size 的視野,一方面無法建模更長的序列資訊,另一方面 filter _size 的超參調節也很繁瑣。CNN本質是做文字的特徵表達工作,而自然語言處理中更常用的是遞迴神經網路(RNN, Recurrent Neural Network),能夠更好的表達上下文資訊。
模型結構:embedding—>bi-drectional lstm —> concat output –>average—–> softmax layer
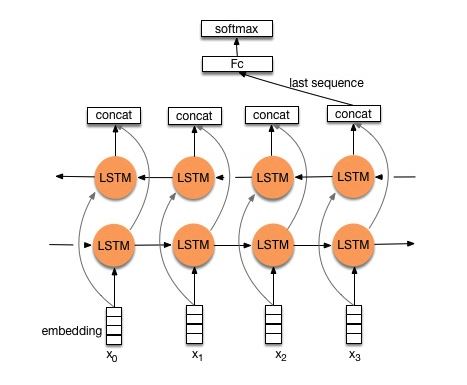
通過利用雙向LSTM建模,然後輸出最後一個詞的結果直接接全連線層softmax輸出了。
2.4 雙向長短期記憶網路文字關係(BiLstm Text Relation)
結構:結構與Text RNN相同。但輸入是被特別設計,直接把兩個句子進行拼接。
例如:
# "how much is the computer? EOS price of laptop"---> label:1“EOS”是一個特殊的標記,將問題1和問題2分開。但是 模型並沒有把兩個句子分割開來,而是當做一個輸入進行建模: 把 (背後的邏輯應該是 BiLstm 的自動“雙向”建模能力)
2.5 兩個卷積神經網路文字關係(two CNN Text Relation)
Github 程式碼檢視:p9_two CNN Text Relation_model.py
結構:首先用兩個不同的卷積來提取兩個句子的特徵,然後連線兩個特徵,使用線性變換層將投影輸出到目標標籤上,然後使用softmax二分類。
2.6 雙長短期記憶文字關係雙迴圈神經網路(BiLstm Text Relation Two RNN)
Github 程式碼檢視:p9_BiLstm Text Relation Two RNN_model.py
結構:一個句子的一個雙向lstm(得到輸出1),另一個句子的另一個雙向lstm(得到輸出2)。拼接之後加全連線, 最後:softmax(輸出1 輸出0)
2.7 迴圈卷積神經網路(text-RCNN)
結構:1)迴圈結構(卷積層)2)最大池化3)完全連線層+ softmax
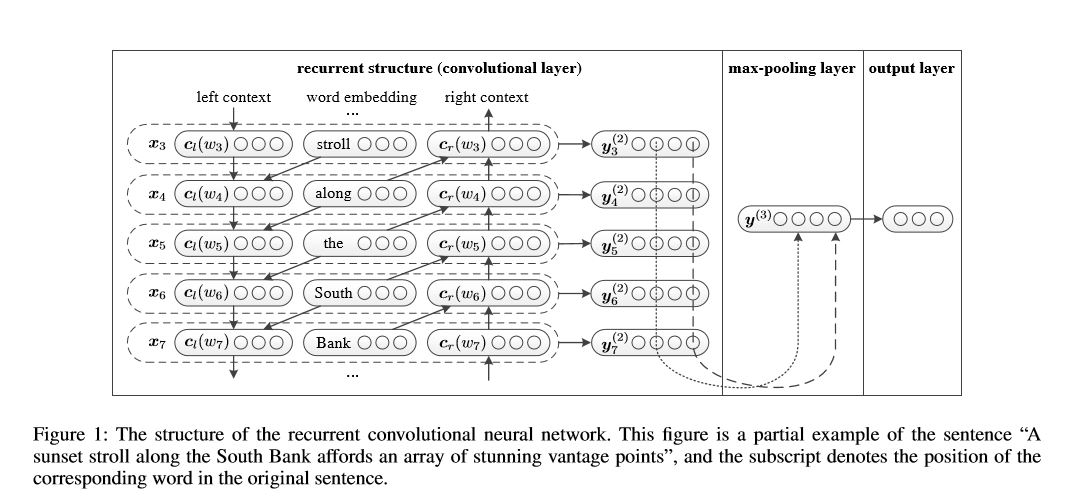
重點是 迴圈結構(卷積層),在迴圈神經網路中,加入了“上一個單詞”的詞向量,類似於 卷積神經網路的2-gram特徵。這就是為什麼是迴圈網路 卻叫卷積層,重點程式碼如下:
def get_context_left(self,context_left,embedding_previous):
"""
:param context_left:
:param embedding_previous:
:return: output:[None,embed_size]
"""
left_c=tf.matmul(context_left,self.W_l) #context_left:[batch_size,embed_size];W_l:[embed_size,embed_size]
left_e=tf.matmul(embedding_previous,self.W_sl)#embedding_previous;[batch_size,embed_size]
left_h=left_c+left_e
context_left=self.activation(left_h)
return context_left
def get_context_right(self,context_right,embedding_afterward):
"""
:param context_right:
:param embedding_afterward:
:return: output:[None,embed_size]
"""
right_c=tf.matmul(context_right,self.W_r)
right_e=tf.matmul(embedding_afterward,self.W_sr)
right_h=right_c+right_e
context_right=self.activation(right_h)
return context_right2.8 分層注意力
程式碼:p1_HierarchicalAttention_model.py
結構:
- 詞編碼器:詞級雙向GRU,以獲得豐富的詞彙表徵
- 詞注意力:詞級注意在句子中獲取重要資訊
- 句子編碼器:句子級雙向GRU,以獲得豐富的句子表徵
- 句子注意:句級注意以獲得句子中的重點句子
- FC + Softmax
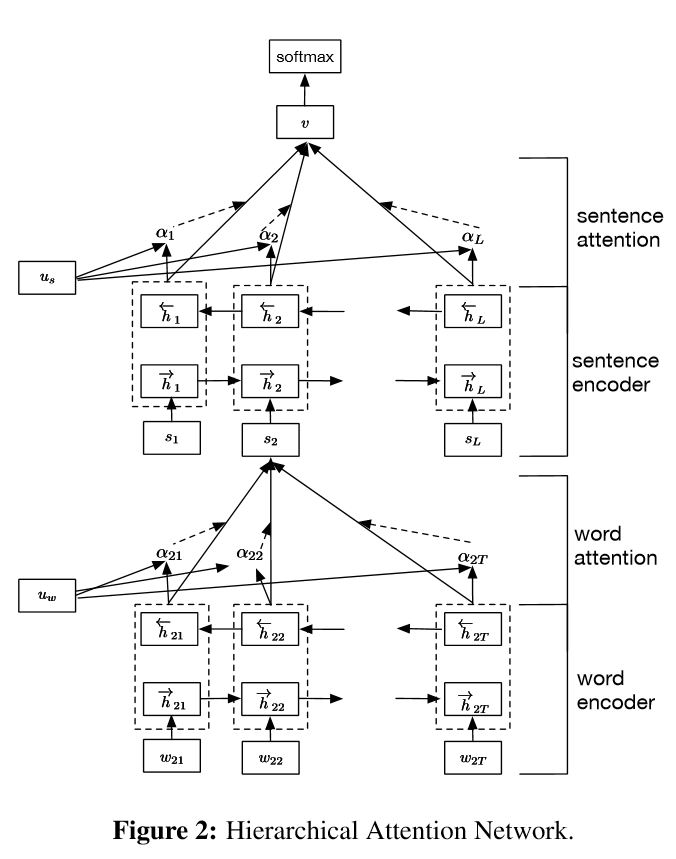
它有兩個獨特的特點:
1)它具有體現檔案層次結構的層次結構
2)它在單詞和句子級別使用兩個級別的注意力機制,它使模型能夠捕捉到不同級別的重要資訊。
一個重要問題: ==Uw和Us 的來源 去向?==
計算方式:
- 就是一個 隨機初始化的“權重向量”,通過訓練更新, 每次計算出前向神經網路的隱層輸出之後,乘以權重得到注意力向量。
從程式碼來研究:
def AttentionLayer(self, inputs, name):
#inputs是GRU的輸出,size是[batch_size, max_time, encoder_size(hidden_size * 2)]
with tf.variable_scope(name):
# u_context是上下文的重要性向量,用於區分不同單詞/句子對於句子/文件的重要程度,
# 因為使用雙向GRU,所以其長度為2×hidden_szie
u_context = tf.Variable(tf.truncated_normal([self.hidden_size * 2]), name='u_context')
#使用一個全連線層編碼GRU的輸出的到期隱層表示,輸出u的size是[batch_size, max_time, hidden_size * 2]
h = layers.fully_connected(inputs, self.hidden_size * 2, activation_fn=tf.nn.tanh)
#shape為[batch_size, max_time, 1]
alpha = tf.nn.softmax(tf.reduce_sum(tf.multiply(h, u_context), axis=2, keep_dims=True), dim=1)
#reduce_sum之前shape為[batch_szie, max_time, hidden_szie*2],之後shape為[batch_size, hidden_size*2]
atten_output = tf.reduce_sum(tf.multiply(inputs, alpha), axis=1)
return atten_output
###########################################################################################
1. 詞向量層:省略
2. 句子級注意力:
def sent2vec(self, word_embedded):
with tf.name_scope("sent2vec"):
#GRU的輸入tensor是[batch_size, max_time, ...].在構造句子向量時max_time應該是每個句子的長度,所以這裡將
#batch_size * sent_in_doc當做是batch_size.這樣一來,每個GRU的cell處理的都是一個單詞的詞向量
#並最終將一句話中的所有單詞的詞向量融合(Attention)在一起形成句子向量
#shape為[batch_size*sent_in_doc, word_in_sent, embedding_size]
word_embedded = tf.reshape(word_embedded, [-1, self.max_sentence_length, self.embedding_size])
#shape為[batch_size*sent_in_doce, word_in_sent, hidden_size*2]
word_encoded = self.BidirectionalGRUEncoder(word_embedded, name='word_encoder')
#shape為[batch_size*sent_in_doc, hidden_size*2]
sent_vec = self.AttentionLayer(word_encoded, name='word_attention')
return sent_vec
3.文件級注意力
def doc2vec(self, sent_vec):
#原理與sent2vec一樣,根據文件中所有句子的向量構成一個文件向量
with tf.name_scope("doc2vec"):
sent_vec = tf.reshape(sent_vec, [-1, self.max_sentence_num, self.hidden_size*2])
#shape為[batch_size, sent_in_doc, hidden_size*2]
doc_encoded = self.BidirectionalGRUEncoder(sent_vec, name='sent_encoder')
#shape為[batch_szie, hidden_szie*2]
doc_vec = self.AttentionLayer(doc_encoded, name='sent_attention')
return doc_vec
4. 全連線層:省略2.9具有注意的Seq2seq模型
2.9.1 encoder to decoder
首先是第一篇《NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE》,這篇論文算是在自然語言處理(NLP)中第一個使用attention機制的工作,將attention機制用到了神經網路機器翻譯(NMT),NMT其實就是一個典型的Seq2Seq模型,也就是一個encoder to decoder模型,傳統的NMT使用兩個RNN,一個RNN對源語言進行編碼,將源語言編碼到一個固定維度的中間向量,再使用一個RNN進行解碼翻譯到目標語言:

按照論文所述,encoder中的每個隱層單元的計算公式為:
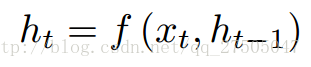
encoder的輸出語義編碼向量c為:
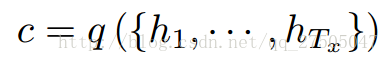
而decoder通過將聯合概率p(y)分解成有序條件來定義翻譯y的概率:
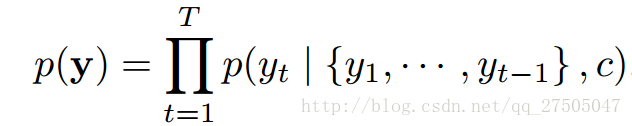
2.9.2 引入注意力機制
而引入注意力機制後的模型如下:
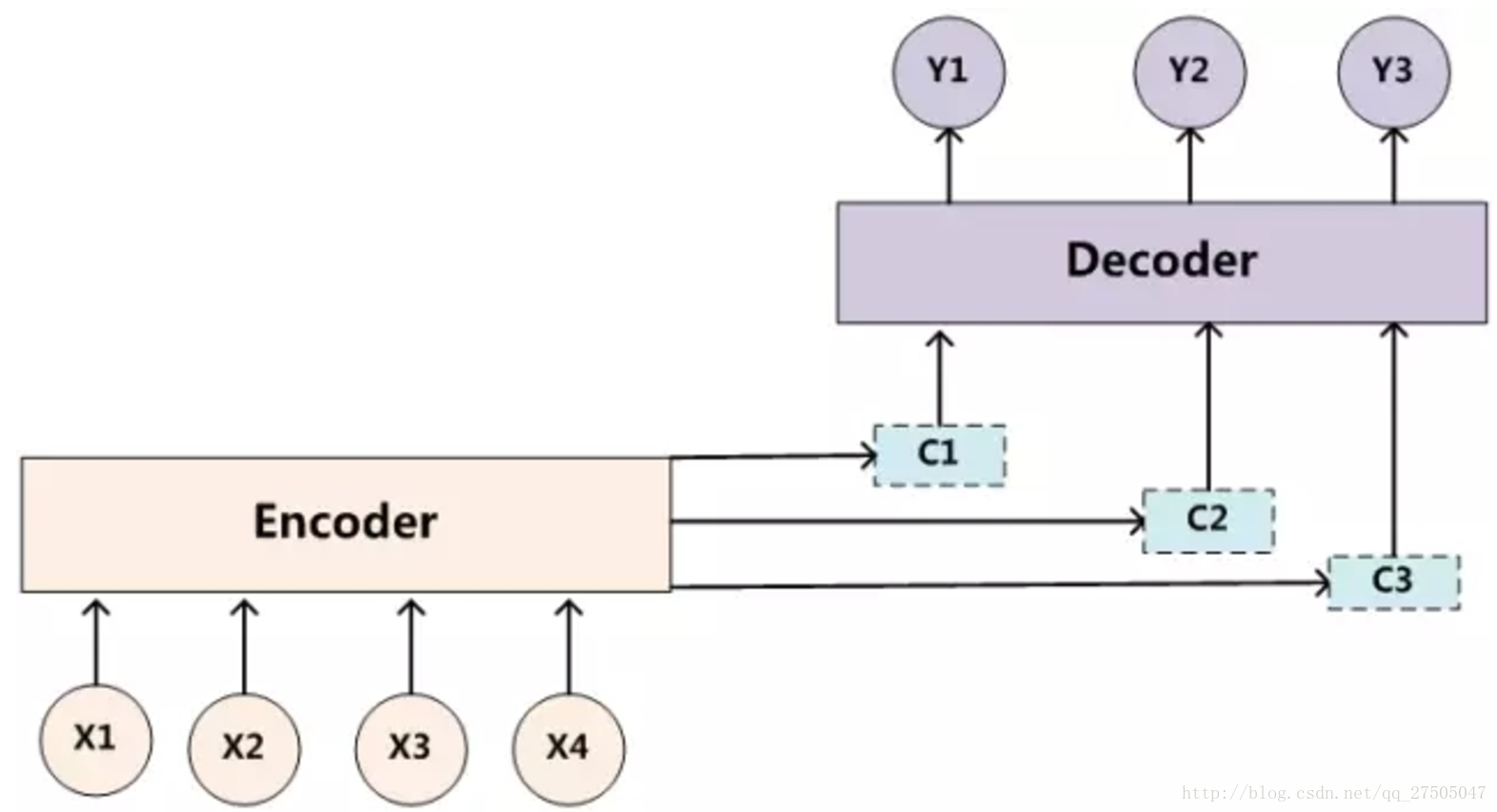
此時,關於p(y)的定義變化如下:

此處c變成了ci,即要輸出的第i個單詞時對應的ci向量,因此要如何計算ci向量時注意力機制實現的關鍵.但在此之前si的計算也變成了:
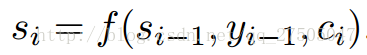
此時引入 論文示意圖:
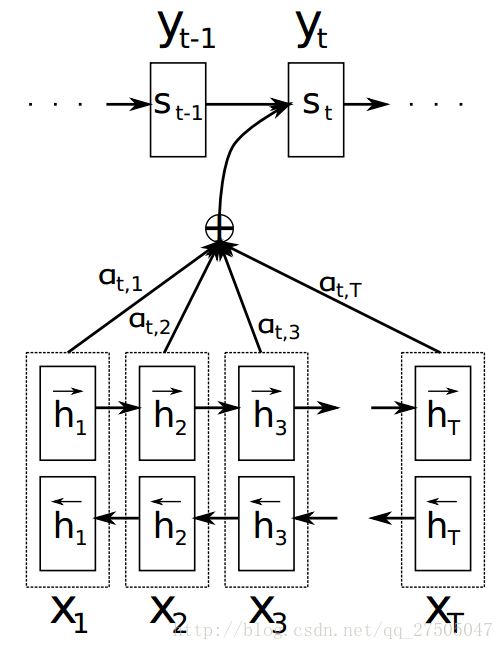
2.9.3 attention的計算方式
那麼重點來了,這個係數a是怎麼計算的呢?
注意機制計算過程:
- 計算每個編碼器輸入 與 解碼器隱藏狀態的相似度,以獲得每個編碼器輸入的可能性分佈。
- 計算 基於可能性分佈的 編碼器注意力的加權和。ci是所有具有概率αij的hj的期望。

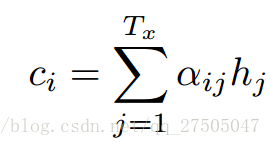
2.10 Transformer(“Attention Is All You Need”)
帶注意的 seq2seq是解決序列生成問題的典型模型,如翻譯、對話系統。
Transformer,它僅僅依靠注意機制執行這些任務 (編碼器 解碼器 都只用attention),是快速的、實現新的最先進的結果。
結構如下:
- 編碼器:
由N = 6個相同層的堆疊組成。
每個層都有兩個子層。第一是多向自注意機制;第二個是全連線前饋網路。
- 解碼器:
1.解碼器由N = 6個相同層的堆疊組成。
2.除了每個編碼器層中的兩個子層之外,解碼器多加入了一層 多向注意。
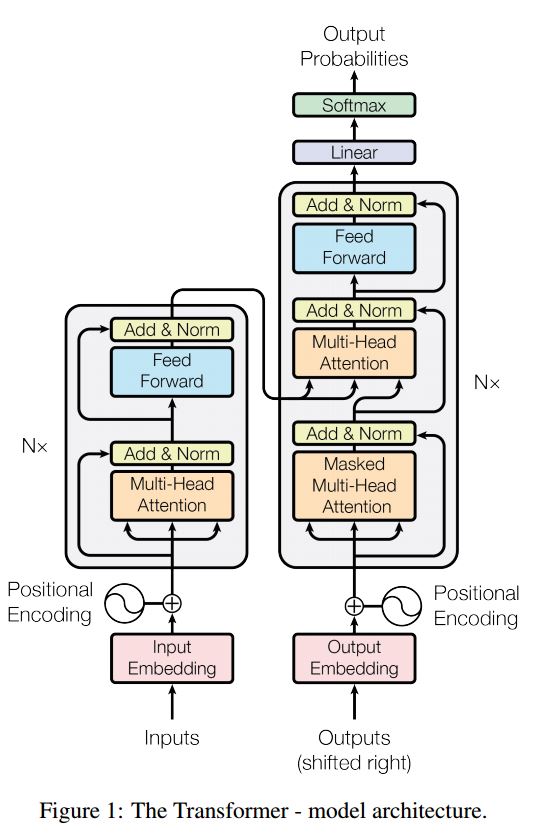
這個模型主要創新點: ==多頭注意力 和位置編碼== 關鍵點:
- ==位置編碼==: 由於模型沒有任何迴圈或者卷積,為了使用序列的順序資訊,需要將tokens的相對以及絕對位置資訊注入到模型中去。論文在輸入embeddings的基礎上加了一個“位置編碼”。位置編碼和embeddings由同樣的維度都是d 所以兩者可以直接相加。 有很多位置編碼的選擇,既有學習到的也有固定不變的。本文中用了正弦和餘弦函式進行編碼。` `
其中的pos是位置,i是維度(比如50維的詞向量 如果位置 和 確定了 )。 偶數維度用sin 奇數維度用cos。 最後將詞向量與位置向量直接相加。 - ==多頭注意力 的基本組成單位==:
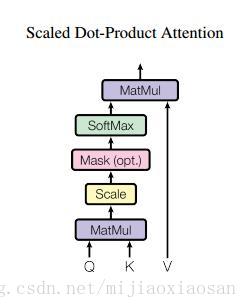
- 普通注意力 :attention函式可以看作將一個query和一系列key-value對對映為一個輸出(output)的過程(多數情況下 K和V是同一向量)事實上這種 Attention 的定義並不新鮮,但由於 Google 的影響力,我們可以認為現在是更加正式地提出了這個定義,並將其視為一個層地看待。。
- 論文自創在普通attention的基礎上加了一個Scale(縮放層):計算query和所有keys的點乘,然後每個都除以dk−−√(這個操作就是所謂的Scaled)。之後利用一個softmax函式來獲取values的權重。 這樣可以起到“歸一化”的作用。Mask層沒看懂。
- 總的來說 attention公式如下: 。只要稍微思考一下就會發現,這樣的 Self Attention模型並不能捕捉序列的順序。換句話說,如果將 K,V 按行打亂順序(相當於句子中的詞序打亂),那麼 Attention 的結果還是一樣的。但是對於 NLP 中的任務來說,順序是很重要的資訊,它代表著區域性甚至是全域性的結構,學習不到順序資訊,那麼效果將會大打折扣。於是 Google 再祭出了一招——Position Embedding,也就是上面的“位置向量”。
- 普通注意力 :attention函式可以看作將一個query和一系列key-value對對映為一個輸出(output)的過程(多數情況下 K和V是同一向量)事實上這種 Attention 的定義並不新鮮,但由於 Google 的影響力,我們可以認為現在是更加正式地提出了這個定義,並將其視為一個層地看待。。
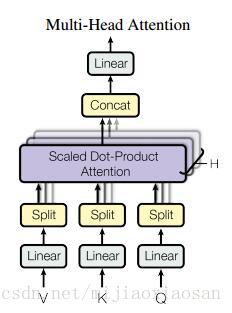
- ==Multi-Head Attention 多頭注意力==:本文結構中的Attention並不是簡簡單單將一個attention應用進去。作者發現對 原始向量 進行h 次不同的attention,再拼接起來 效果特別好。所謂“多頭”(Multi-Head),就是隻多做幾次同樣的事情(引數不共享),然後把結果拼接。
分別對每一個對映之後的得到的queries,keys以及values進行attention函式的並行操作,最後拼接成output值。具體操作細節如以下公式。 結構示意圖:
相關推薦
2018.06.06論文:12個NLP分類模型
1 概述
這個庫 的目的是探索用深度學習進行NLP文字分類的方法。它具有文字分類的各種基準模型。
雖然這12個模型都很簡單,可能不會讓你在這項文字分類任務中游刃有餘,但是這些模型中的其中一些是非常經典的,因此它們可以說是非常適合作為基準模型
前端知識:12個非常實用的JavaScript小技巧
布爾 基本上 瀏覽器 表達 variable 希望 [] fine 實用 在這篇文章中將給大家分享12個有關於JavaScript的小技巧。這些小技巧可能在你的實際工作中或許能幫助你解決一些問題。
使用!!操作符轉換布爾值
有時候我們需要對一個變量查檢其是否存在或者檢查值是
第213天:12個HTML和CSS必須知道的重點難點問題
ie7 html 技術 article 就會 cap 簡述 同時存在 空間 12個HTML和CSS必須知道的重點難點問題
這12個問題,基本上就是HTML和CSS基礎中的重點個難點了,也是必須要弄清楚的基本問題,其中定位的絕對定位和相對定位到底相對什麽定位?這個還是容易被
演算法:12 個高矮不同的人,排成兩排,每排必須是從矮到高排列,而且第二排比對應的第一排的人高,問排列方式有多少種?
自己去動手寫了一下,記錄下來
#include "pch.h"
#include <iostream>
int count = 0;//記錄共count種排列
void fun(int pai1[], int p1, int pai2[], int p2, i
Java學習:12個提高Java程式設計師工作效率的工具
Java開發者常常都會想辦法如何更快地編寫Java程式碼,讓開發過程變得更加輕鬆,更加高效。目前,市面上湧現出越來越多的高效程式設計工具。團長總結了幾個常用的工具,其中包含了大多數開發人員已經使用、正在使用或將來一定會用到的高效工具。
1、Eclipse
Eclipse是
用 Python 做資料處理必看:12 個使效率倍增的 Pandas 技巧(上下)
http://datartisan.com/article/detail/81.html
導語
Python正迅速成為資料科學家偏愛的語言,這合情合理。它擁有作為一種程式語言廣闊的生態環境以及眾多優秀的科學計算庫。如果你剛開始學習Python,可以先了解一下Python的學習路線。
在眾多的科學計算庫中
用 Python 做資料處理必看:12 個使效率倍增的 Pandas 技巧(上)
導語
Python正迅速成為資料科學家偏愛的語言,這合情合理。它擁有作為一種程式語言廣闊的生態環境以及眾多優秀的科學計算庫。如果你剛開始學習Python,可以先了解一下Python的學習路線。在眾多的科學計算庫中,我認為Pandas對資料科學運算最有用。Pandas,
用 Python 做資料處理必看:12 個使效率倍增的 Pandas 技巧(下)
7 – 資料框合併
當我們有收集自不同來源的資料時,合併資料框就變得至關重要。假設對於不同的房產型別,我們有不同的房屋均價資料。讓我們定義這樣一個數據框:
prop_rates = pd.DataFrame([1000, 5000, 12000], index
例子:12個趨勢
未來12個趨勢
今天,我非常高興能夠來到中國,尤其是來到深圳!深圳正在發生著翻天覆地的變化,我來這裡不僅僅是給大家分享未來將會發生什麼事情,更多的是要向大家學習,與大家共同探討深圳將會發生什麼。這裡代表著未來,今天要重點談談我所認為的未來將發生的十二個趨勢。
我所
一道演算法題:12個黑球和1個白球圍成一個圓
問題:
桌上有12個黑球和1個白球圍成一個圓,按順時針方向順序數到13就拿走對應的一個球,
如果要求最後拿走的是白球,請問該從哪個球開始數數。
分析:
從最後一輪開始考慮,按輪次倒推。可以用遞迴法
在 Linux 命令列中使用和執行 PHP 程式碼(二):12 個 PHP 互動性 shell 的用法
Run PHP Codes in Linux Commandline
本文旨在讓你瞭解一些相當不錯的Linux終端中的PHP互動性 shell 的用法特性。
讓我們先在PHP 的互動shell中來對php.ini設定進行一些配置吧。
6. 設定PHP命令列提示符
LoRa vs NB-IoT:12個角度看哪個物聯網標準更具優勢?
近期全球低功耗廣域網(LPWAN)市場的激增可歸因於多個因素。機器學習和 M2M 通訊標準的快速發展發揮了重要作用,加之全球對物聯網服務的需求不斷增長、低價的 LPWAN 工具和節能機會的增多。
預計在2022 年,全球 LPWAN 市場的價值將會提升
機器學習實戰(二)LR演算法:實現簡單的分類模型
說明:,裡面有更詳盡的Logistic Regression原理分析和案例實現流程詳解,是一個關於機器學習實戰的不錯的學習資料,推薦一波。出於程式設計實踐和機器學習演算法梳理的目的,按照自己的程式碼風格重寫該應用案例,在實現的過程中也很有助於自己的思考。為方便下次看時能快速理
2018 08/06-08/12周總結
oracl san 直接 select post javascrip 但是 -c 導致 1、Oracle在已經存在主鍵的表中插入復合主鍵的SQL語句
如已有一個表test_key,其中a1列為主鍵。
CREATE TABLE TEST_KEY(
A1 VARCHAR
2017-05-06隨記:基礎命令和符號
基礎命令2017-05-06基礎命令:1.mkdir 創建目錄 make directory -p 遞歸創建2.ls 顯示目錄中的內容,列表 list -l (小寫字母L) 顯示詳細的信息 3.pwd 顯示當前你所在的位置
[2017.06.08] 給自己定下個目標把
ring 設計 現在 需要 由於 oracl 自己 6.0 聯網 需要拼搏,感覺自己是那種屬於很懶散的性格的人。
在這個社會還是不能安於現狀。
現在給自己定下個目標,在期末之前盡力去做去完成這幾個目標。
由於目標是考研,所以在這個月之內,
英語要背單詞,看句子,做閱讀。
數
精通JavaScript--06設計模式:結構型
bsp sin callback 時有 入參 遍歷 toupper 出現 state 本章主要學習結構性設計模式,前一章介紹的創建型設計模式側重於對象的處理,而結構型設計模式則有助於把多個對象整合為一個更大型的、更有組織的代碼庫。它們具有靈活性,可維護性,可擴展性,並能夠
精選文章推薦匯總-2018.02.06
ava 理解 qps 朋友 用法 java and james ken 對高並發流量控制的一點思考
作者:zfz_linux_boy簡介:在實際項目中,曾經遭遇過線上5W+QPS的峰值,也在壓測狀態下經歷過10W+QPS的大流量請求,本篇博客的話題主要就是自己對高並發流
2018-03-06阿銘Linux學習
Linux學習7.6 yum更換國內源
cd /etc/yum.repos.d/
rm -r dvd.repo
wget http://mirrors.163.com/.help/CentOS7-Base-163.repo
或者
curl -O http://mirrors.163.com/.help
阿裏財報:雲計算年度營收133億,季度營收連續12個季度翻番
阿裏巴巴摘要: 北京時間5月4日晚間,阿裏巴巴集團公布2018財年第四季度和全年財報,該季度內(2018年1月至3月底)阿裏雲營收43.85億元,同比增長103%;2018財年(2017年4月至2018年3月底)營收133.9億元,同比增長101%。北京時間5月4日晚間,阿裏巴巴集團公布2018財年第四季度和
2018.06.06論文:12個NLP分類模型
1 概述 這個庫 的目的是探索用深度學習進行NLP文字分類的方法。它具有文字分類的各種基準模型。 雖然這12個模型都很簡單,可能不會讓你在這項文字分類任務中游刃有餘,但是這些模型中的其中一些是非常經典的,因此它們可以說是非常適合作為基準模型
前端知識:12個非常實用的JavaScript小技巧
布爾 基本上 瀏覽器 表達 variable 希望 [] fine 實用 在這篇文章中將給大家分享12個有關於JavaScript的小技巧。這些小技巧可能在你的實際工作中或許能幫助你解決一些問題。 使用!!操作符轉換布爾值 有時候我們需要對一個變量查檢其是否存在或者檢查值是
第213天:12個HTML和CSS必須知道的重點難點問題
ie7 html 技術 article 就會 cap 簡述 同時存在 空間 12個HTML和CSS必須知道的重點難點問題 這12個問題,基本上就是HTML和CSS基礎中的重點個難點了,也是必須要弄清楚的基本問題,其中定位的絕對定位和相對定位到底相對什麽定位?這個還是容易被
演算法:12 個高矮不同的人,排成兩排,每排必須是從矮到高排列,而且第二排比對應的第一排的人高,問排列方式有多少種?
自己去動手寫了一下,記錄下來 #include "pch.h" #include <iostream> int count = 0;//記錄共count種排列 void fun(int pai1[], int p1, int pai2[], int p2, i
Java學習:12個提高Java程式設計師工作效率的工具
Java開發者常常都會想辦法如何更快地編寫Java程式碼,讓開發過程變得更加輕鬆,更加高效。目前,市面上湧現出越來越多的高效程式設計工具。團長總結了幾個常用的工具,其中包含了大多數開發人員已經使用、正在使用或將來一定會用到的高效工具。 1、Eclipse Eclipse是
用 Python 做資料處理必看:12 個使效率倍增的 Pandas 技巧(上下)
http://datartisan.com/article/detail/81.html 導語 Python正迅速成為資料科學家偏愛的語言,這合情合理。它擁有作為一種程式語言廣闊的生態環境以及眾多優秀的科學計算庫。如果你剛開始學習Python,可以先了解一下Python的學習路線。 在眾多的科學計算庫中
用 Python 做資料處理必看:12 個使效率倍增的 Pandas 技巧(上)
導語 Python正迅速成為資料科學家偏愛的語言,這合情合理。它擁有作為一種程式語言廣闊的生態環境以及眾多優秀的科學計算庫。如果你剛開始學習Python,可以先了解一下Python的學習路線。在眾多的科學計算庫中,我認為Pandas對資料科學運算最有用。Pandas,
用 Python 做資料處理必看:12 個使效率倍增的 Pandas 技巧(下)
7 – 資料框合併 當我們有收集自不同來源的資料時,合併資料框就變得至關重要。假設對於不同的房產型別,我們有不同的房屋均價資料。讓我們定義這樣一個數據框: prop_rates = pd.DataFrame([1000, 5000, 12000], index
例子:12個趨勢
未來12個趨勢 今天,我非常高興能夠來到中國,尤其是來到深圳!深圳正在發生著翻天覆地的變化,我來這裡不僅僅是給大家分享未來將會發生什麼事情,更多的是要向大家學習,與大家共同探討深圳將會發生什麼。這裡代表著未來,今天要重點談談我所認為的未來將發生的十二個趨勢。 我所
一道演算法題:12個黑球和1個白球圍成一個圓
問題: 桌上有12個黑球和1個白球圍成一個圓,按順時針方向順序數到13就拿走對應的一個球, 如果要求最後拿走的是白球,請問該從哪個球開始數數。 分析: 從最後一輪開始考慮,按輪次倒推。可以用遞迴法
在 Linux 命令列中使用和執行 PHP 程式碼(二):12 個 PHP 互動性 shell 的用法
Run PHP Codes in Linux Commandline 本文旨在讓你瞭解一些相當不錯的Linux終端中的PHP互動性 shell 的用法特性。 讓我們先在PHP 的互動shell中來對php.ini設定進行一些配置吧。 6. 設定PHP命令列提示符
LoRa vs NB-IoT:12個角度看哪個物聯網標準更具優勢?
近期全球低功耗廣域網(LPWAN)市場的激增可歸因於多個因素。機器學習和 M2M 通訊標準的快速發展發揮了重要作用,加之全球對物聯網服務的需求不斷增長、低價的 LPWAN 工具和節能機會的增多。 預計在2022 年,全球 LPWAN 市場的價值將會提升
機器學習實戰(二)LR演算法:實現簡單的分類模型
說明:,裡面有更詳盡的Logistic Regression原理分析和案例實現流程詳解,是一個關於機器學習實戰的不錯的學習資料,推薦一波。出於程式設計實踐和機器學習演算法梳理的目的,按照自己的程式碼風格重寫該應用案例,在實現的過程中也很有助於自己的思考。為方便下次看時能快速理
2018 08/06-08/12周總結
oracl san 直接 select post javascrip 但是 -c 導致 1、Oracle在已經存在主鍵的表中插入復合主鍵的SQL語句 如已有一個表test_key,其中a1列為主鍵。 CREATE TABLE TEST_KEY( A1 VARCHAR
2017-05-06隨記:基礎命令和符號
基礎命令2017-05-06基礎命令:1.mkdir 創建目錄 make directory -p 遞歸創建2.ls 顯示目錄中的內容,列表 list -l (小寫字母L) 顯示詳細的信息 3.pwd 顯示當前你所在的位置
[2017.06.08] 給自己定下個目標把
ring 設計 現在 需要 由於 oracl 自己 6.0 聯網 需要拼搏,感覺自己是那種屬於很懶散的性格的人。 在這個社會還是不能安於現狀。 現在給自己定下個目標,在期末之前盡力去做去完成這幾個目標。 由於目標是考研,所以在這個月之內, 英語要背單詞,看句子,做閱讀。 數
精通JavaScript--06設計模式:結構型
bsp sin callback 時有 入參 遍歷 toupper 出現 state 本章主要學習結構性設計模式,前一章介紹的創建型設計模式側重於對象的處理,而結構型設計模式則有助於把多個對象整合為一個更大型的、更有組織的代碼庫。它們具有靈活性,可維護性,可擴展性,並能夠
精選文章推薦匯總-2018.02.06
ava 理解 qps 朋友 用法 java and james ken 對高並發流量控制的一點思考 作者:zfz_linux_boy簡介:在實際項目中,曾經遭遇過線上5W+QPS的峰值,也在壓測狀態下經歷過10W+QPS的大流量請求,本篇博客的話題主要就是自己對高並發流
2018-03-06阿銘Linux學習
Linux學習7.6 yum更換國內源 cd /etc/yum.repos.d/ rm -r dvd.repo wget http://mirrors.163.com/.help/CentOS7-Base-163.repo 或者 curl -O http://mirrors.163.com/.help
阿裏財報:雲計算年度營收133億,季度營收連續12個季度翻番
阿裏巴巴摘要: 北京時間5月4日晚間,阿裏巴巴集團公布2018財年第四季度和全年財報,該季度內(2018年1月至3月底)阿裏雲營收43.85億元,同比增長103%;2018財年(2017年4月至2018年3月底)營收133.9億元,同比增長101%。北京時間5月4日晚間,阿裏巴巴集團公布2018財年第四季度和