
【tensorflow】TensorFlow入門(五)多層 LSTM 通俗易懂版
前言: 根據我本人學習 TensorFlow 實現 LSTM 的經歷,發現網上雖然也有不少教程,其中很多都是根據官方給出的例子,用多層 LSTM 來實現 PTBModel 語言模型,比如:
tensorflow筆記:多層LSTM程式碼分析
但是感覺這些例子還是太複雜了,所以這裡寫了個比較簡單的版本,雖然不優雅,但是還是比較容易理解。
很多朋友提到多層怎麼理解,所以自己做了一個示意圖,希望幫助初學者更好地理解 多層RNN.
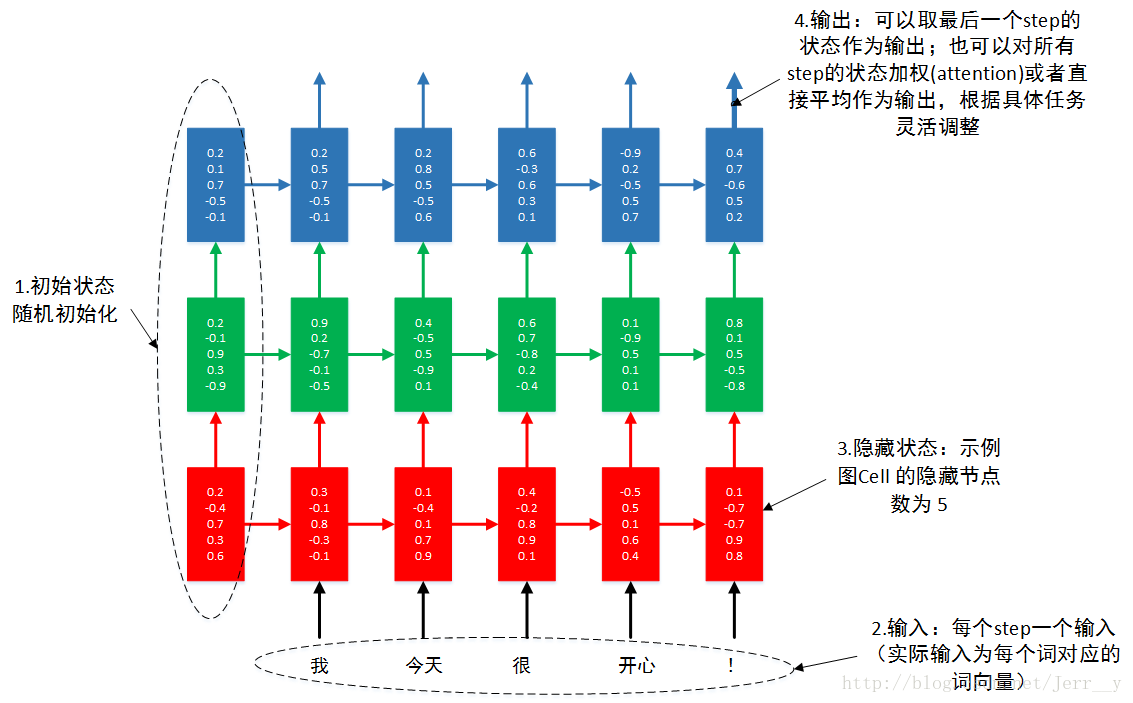
圖1 3層RNN按時間步展開
本例不講原理。通過本例,你可以瞭解到單層 LSTM 的實現,多層 LSTM 的實現。輸入輸出資料的格式。 RNN 的 dropout layer 的實現。
# -*- coding:utf-8 -*-
import tensorflow as tf
import numpy as np
from tensorflow.contrib import rnn
from tensorflow.examples.tutorials.mnist import input_data
# 設定 GPU 按需增長
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
sess = tf.Session(config=config)
# 首先匯入資料,看一下資料的形式
mnist = input_data.read_data_sets('MNIST_data' - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
Extracting MNIST_data/train-images-idx3-ubyte.gz
Extracting MNIST_data/train-labels-idx1-ubyte.gz
Extracting MNIST_data/t10k-images-idx3-ubyte.gz
Extracting MNIST_data/t10k-labels-idx1-ubyte.gz
(55000, 784)
- 1
- 2
- 3
- 4
- 5
- 6
1. 首先設定好模型用到的各個超引數
lr = 1e-3
# 在訓練和測試的時候,我們想用不同的 batch_size.所以採用佔位符的方式 - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
2. 開始搭建 LSTM 模型,其實普通 RNNs 模型也一樣
# 把784個點的字元資訊還原成 28 * 28 的圖片
# 下面幾個步驟是實現 RNN / LSTM 的關鍵
####################################################################
# **步驟1:RNN 的輸入shape = (batch_size, timestep_size, input_size)
X = tf.reshape(_X, [-1, 28, 28])
# **步驟2:定義一層 LSTM_cell,只需要說明 hidden_size, 它會自動匹配輸入的 X 的維度
lstm_cell = rnn.BasicLSTMCell(num_units=hidden_size, forget_bias=1.0, state_is_tuple=True)
# **步驟3:新增 dropout layer, 一般只設置 output_keep_prob
lstm_cell = rnn.DropoutWrapper(cell=lstm_cell, input_keep_prob=1.0, output_keep_prob=keep_prob)
# **步驟4:呼叫 MultiRNNCell 來實現多層 LSTM
mlstm_cell = rnn.MultiRNNCell([lstm_cell] * layer_num, state_is_tuple=True)
# **步驟5:用全零來初始化state
init_state = mlstm_cell.zero_state(batch_size, dtype=tf.float32)
# **步驟6:方法一,呼叫 dynamic_rnn() 來讓我們構建好的網路執行起來
# ** 當 time_major==False 時, outputs.shape = [batch_size, timestep_size, hidden_size]
# ** 所以,可以取 h_state = outputs[:, -1, :] 作為最後輸出
# ** state.shape = [layer_num, 2, batch_size, hidden_size],
# ** 或者,可以取 h_state = state[-1][1] 作為最後輸出
# ** 最後輸出維度是 [batch_size, hidden_size]
# outputs, state = tf.nn.dynamic_rnn(mlstm_cell, inputs=X, initial_state=init_state, time_major=False)
# h_state = outputs[:, -1, :] # 或者 h_state = state[-1][1]
# *************** 為了更好的理解 LSTM 工作原理,我們把上面 步驟6 中的函式自己來實現 ***************
# 通過檢視文件你會發現, RNNCell 都提供了一個 __call__()函式(見最後附),我們可以用它來展開實現LSTM按時間步迭代。
# **步驟6:方法二,按時間步展開計算
outputs = list()
state = init_state
with tf.variable_scope('RNN'):
for timestep in range(timestep_size):
if timestep > 0:
tf.get_variable_scope().reuse_variables()
# 這裡的state儲存了每一層 LSTM 的狀態
(cell_output, state) = mlstm_cell(X[:, timestep, :], state)
outputs.append(cell_output)
h_state = outputs[-1]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
3. 設定 loss function 和 優化器,展開訓練並完成測試
# 上面 LSTM 部分的輸出會是一個 [hidden_size] 的tensor,我們要分類的話,還需要接一個 softmax 層
# 首先定義 softmax 的連線權重矩陣和偏置
# out_W = tf.placeholder(tf.float32, [hidden_size, class_num], name='out_Weights')
# out_bias = tf.placeholder(tf.float32, [class_num], name='out_bias')
# 開始訓練和測試
W = tf.Variable(tf.truncated_normal([hidden_size, class_num], stddev=0.1), dtype=tf.float32)
bias = tf.Variable(tf.constant(0.1,shape=[class_num]), dtype=tf.float32)
y_pre = tf.nn.softmax(tf.matmul(h_state, W) + bias)
# 損失和評估函式
cross_entropy = -tf.reduce_mean(y * tf.log(y_pre))
train_op = tf.train.AdamOptimizer(lr).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(y_pre,1), tf.argmax(y,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
sess.run(tf.global_variables_initializer())
for i in range(2000):
_batch_size = 128
batch = mnist.train.next_batch(_batch_size)
if (i+1)%200 == 0:
train_accuracy = sess.run(accuracy, feed_dict={
_X:batch[0], y: batch[1], keep_prob: 1.0, batch_size: _batch_size})
# 已經迭代完成的 epoch 數: mnist.train.epochs_completed
print "Iter%d, step %d, training accuracy %g" % ( mnist.train.epochs_completed, (i+1), train_accuracy)
sess.run(train_op, feed_dict={_X: batch[0], y: batch[1], keep_prob: 0.5, batch_size: _batch_size})
# 計算測試資料的準確率
print "test accuracy %g"% sess.run(accuracy, feed_dict={
_X: mnist.test.images, y: mnist.test.labels, keep_prob: 1.0, batch_size:mnist.test.images.shape[0]})
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
Iter0, step 200, training accuracy 0.851562
Iter0, step 400, training accuracy 0.960938
Iter1, step 600, training accuracy 0.984375
Iter1, step 800, training accuracy 0.960938
Iter2, step 1000, training accuracy 0.984375
Iter2, step 1200, training accuracy 0.9375
Iter3, step 1400, training accuracy 0.96875
Iter3, step 1600, training accuracy 0.984375
Iter4, step 1800, training accuracy 0.992188
Iter4, step 2000, training accuracy 0.984375
test accuracy 0.9858
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
我們一共只迭代不到5個epoch,在測試集上就已經達到了0.9825的準確率,可以看出來 LSTM 在做這個字元分類的任務上還是比較有效的,而且我們最後一次性對 10000 張測試圖片進行預測,才佔了 725 MiB 的視訊記憶體。而我們在之前的兩層 CNNs 網路中,預測 10000 張圖片一共用了 8721 MiB 的視訊記憶體,差了整整 12 倍呀!! 這主要是因為 RNN/LSTM 網路中,每個時間步所用的權值矩陣都是共享的,可以通過前面介紹的 LSTM 的網路結構分析一下,整個網路的引數非常少。
4. 視覺化看看 LSTM 的是怎麼做分類的
畢竟 LSTM 更多的是用來做時序相關的問題,要麼是文字,要麼是序列預測之類的,所以很難像 CNNs 一樣非常直觀地看到每一層中特徵的變化。在這裡,我想通過視覺化的方式來幫助大家理解 LSTM 是怎麼樣一步一步地把圖片正確的給分類。
import matplotlib.pyplot as plt- 1
看下面我找了一個字元 3
print mnist.train.labels[4]- 1
[ 0. 0. 0. 1. 0. 0. 0. 0. 0. 0.]
- 1
- 2
我們先來看看這個字元樣子,上半部分還挺像 2 來的
X3 = mnist.train.images[4]
img3 = X3.reshape([28, 28])
plt.imshow(img3, cmap='gray')
plt.show()- 1
- 2
- 3
- 4

我們看看在分類的時候,一行一行地輸入,分為各個類別的概率會是什麼樣子的。
X3.shape = [-1, 784]
y_batch = mnist.train.labels[0]
y_batch.shape = [-1, class_num]
X3_outputs = np.array(sess.run(outputs, feed_dict={
_X: X3, y: y_batch, keep_prob: 1.0, batch_size: 1}))
print X3_outputs.shape
X3_outputs.shape = [28, hidden_size]
print X3_outputs.shape- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
(28, 1, 256)
(28, 256)
- 1
- 2
- 3
h_W = sess.run(W, feed_dict={
_X:X3, y: y_batch, keep_prob: 1.0, batch_size: 1})
h_bias = sess.run(bias, feed_dict={
_X:X3, y: y_batch, keep_prob: 1.0, batch_size: 1})
h_bias.shape = [-1, 10]
bar_index = range(class_num)
for i in xrange(X3_outputs.shape[0]):
plt.subplot(7, 4, i+1)
X3_h_shate = X3_outputs[i, :].reshape([-1, hidden_size])
pro = sess.run(tf.nn.softmax(tf.matmul(X3_h_shate, h_W) + h_bias))
plt.bar(bar_index, pro[0], width=0.2 , align='center')
plt.axis('off')
plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14

在上面的圖中,為了更清楚地看到線條的變化,我把座標都去了,每一行顯示了 4 個圖,共有 7 行,表示了一行一行讀取過程中,模型對字元的識別。可以看到,在只看到前面的幾行畫素時,模型根本認不出來是什麼字元,隨著看到的畫素越來越多,最後就基本確定了它是字元 3.
好了,本次就到這裡。有機會再寫個優雅一點的例子,哈哈。其實學這個 LSTM 還是比較困難的,當時寫 多層 CNNs 也就半天到一天的時間基本上就沒啥問題了,但是這個花了我大概整整三四天,而且是在我對原理已經很瞭解(我自己覺得而已。。。)的情況下,所以學會了感覺還是有點小高興的~
17-04-19補充幾個資料:
- recurrent_network.py 一個簡單的
tensorflow LSTM 例子。
- Tensorflow下構建LSTM模型進行序列化標註 介紹非常好的一個 NLP 開源專案。(例子中有些函式可能在新版的
tensorflow 中已經更新了,但並不影響理解)
5. 附:BASICLSTM.__call__()
'''code: https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/rnn/python/ops/core_rnn_cell_impl.py'''
def __call__(self, inputs, state, scope=None):
"""Long short-term memory cell (LSTM)."""
with vs.variable_scope(scope or "basic_lstm_cell"):
# Parameters of gates are concatenated into one multiply for efficiency.
if self._state_is_tuple:
c, h = state
else:
c, h = array_ops.split(value=state, num_or_size_splits=2, axis=1)
concat = _linear([inputs, h], 4 * self._num_units, True, scope=scope)
# ** 下面四個 tensor,分別是四個 gate 對應的權重矩陣
# i = input_gate, j = new_input, f = forget_gate, o = output_gate
i, j, f, o = array_ops.split(value=concat, num_or_size_splits=4, axis=1)
# ** 更新 cell 的狀態:
# ** c * sigmoid(f + self._forget_bias) 是保留上一個 timestep 的部分舊資訊
# ** sigmoid(i) * self._activation(j) 是有當前 timestep 帶來的新資訊
new_c = (c * sigmoid(f + self._forget_bias) + sigmoid(i) *
self._activation(j))
# ** 新的輸出
new_h = self._activation(new_c) * sigmoid(o)
if self._state_is_tuple:
new_state = LSTMStateTuple(new_c, new_h)
else:
new_state = array_ops.concat([new_c, new_h], 1)
# ** 在(一般都是) state_is_tuple=True 情況下, new_h=new_state[1]
# ** 在上面博文中,就有 cell_output = state[1]
return new_h, new_state- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
轉載自:http://blog.csdn.net/Jerr__y/article/details/61195257