
hadoop平臺搭建(4)--偽分散式的配置及執行
摘要:本文主要講述Linux環境下搭建hadoop平臺過程中,基於hadoop單機模式執行正確的基礎上,配置hadoop的偽分散式模式,並在配置完畢的基礎上執行hadoop的偽分散式例項。
環境說明:文章延續hadoop平臺搭建(3)中的步驟,因為只涉及hadoop自身配置檔案的修改,所以操作步驟適用於所有版本的Linux系統。
Hadoop 可以在單節點上以偽分散式的方式執行,Hadoop 程序以分離的 Java 程序來執行,節點既作為 NameNode 也作為 DataNode。(注意,偽分散式讀取的是 分散式檔案系統hdfs 中的檔案。)
Hadoop 的配置檔案位於 /usr/local/hadoop/etc/hadoop/ 中,偽分散式需要修改2個配置檔案 core-site.xml 和 hdfs-site.xml 。(注意,在比較老的版本比如hadoop1.x中,沒有core-site.xml檔案,需要做相應調整)
1修改配置檔案core-site.xml、hdfs-site.xml
開啟core-site.xml檔案
命令:
sudo gedit ./etx/hadoop/core-site.xml


將檔案內容修改為如下:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop/develop/hadoop/myhadooptemp</value>
<description 其中,hadoop.tmp.dir屬性表示hadoop的臨時目錄,可以自定義;若沒有配置 hadoop.tmp.dir 引數,則預設使用的臨時目錄為 /tmp/hadoo-hadoop,這個目錄在重啟時有可能被系統清理掉,導致必須重新執行 format 才行。fs.defaultFS表示提供HDFS服務的主機名和埠號
開啟hdfs-site.xml檔案
命令:sudo gedit ./etc/hadoop/hdfs-site.xml

將檔案內容修改為如下
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/develop/hadoop/myhadooptemp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/develop/hadoop/myhadooptemp/dfs/data</value>
</property>
</configuration>其中,dfs.replication表示HDFS中同一份檔案的數目,表示有value-1份冗餘。dfs.namenode.name.dir配置namenode的元資料存放的本地檔案系統路徑,dfs.datanode.data.dir設定datanode存放資料的本地檔案系統路徑。
注意:Hadoop 的執行方式是由配置檔案決定的(執行 Hadoop 時會讀取配置檔案),因此如果需要從偽分散式模式切換回非分散式模式,需要刪除 core-site.xml 中的配置項。
2執行NameNode的格式化命令
命令:
./bin/hdfs namenode -format

注意,因為已經配置好hadoop的環境變數,所以可以不進入bin目錄直接呼叫bin目錄下的工具
格式化成功後,會有如下輸入結果

此外,格式化成功後,會根據配置檔案,生成相應的目錄
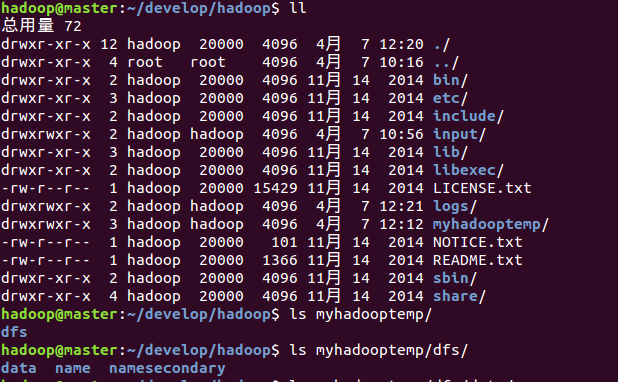
3執行偽分散式例項
開啟NameNode 和 DataNode 守護程序
命令:
./sbin/start-dfs.sh
注意:start-dfs.sh是個完整的可執行指令碼,中間沒有空格。
啟動完成後,用jdk的jps命令檢視程序啟動是否成功,若成功啟動則會列出如下程序: “NameNode”、”DataNode” 和 “SecondaryNameNode”

(1)如果 SecondaryNameNode 沒有啟動,執行如下操作
命令:sbin/stop-dfs.sh#關閉程序
命令:sbin/start-dfs.sh#嘗試再次啟動(2)若是 DataNode 沒有啟動,可嘗試執行如下操作
命令:./sbin/stop-dfs.sh# 關閉程序
命令:rm -r ./tmp# 刪除 tmp 檔案,注意這會刪除 HDFS 中原有的所有資料
命令:./bin/hdfs namenode -format# 重新格式化 NameNode
命令:./sbin/start-dfs.sh# 重啟
成功啟動後,可以訪問 Web 介面localhost:50070 檢視 NameNode 和 Datanode 資訊,還可以線上檢視 HDFS 中的檔案
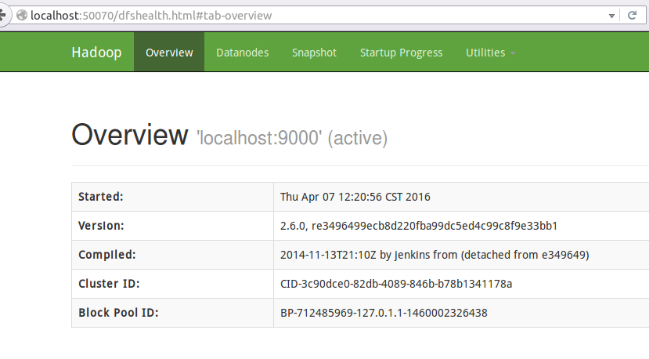
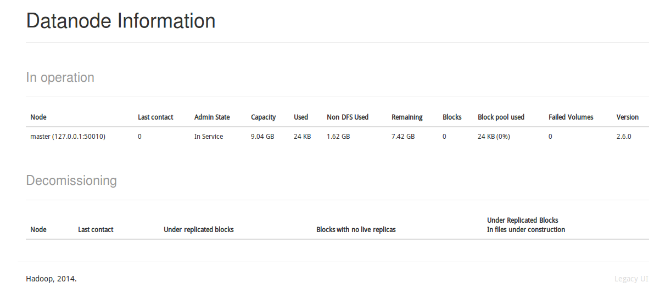
單機模式中,讀取的是本地的資料;偽分散式模式中,讀取的是HDFS上的資料。要使用HDFS資料,首先在HDFS上建立使用者目錄
命令:
hdfs dfs -mkdir -p ./HDFS#建立hdfs格式的輸入輸出根目錄HDFS
命令:hdfs dfs -mkdir -p ./HDFS/input#在HDFS目錄下建立hdfs檔案型別的輸入目錄
注意,使用hdfs dfs -mkdir <新目錄名> 命令時,預設建立HDFS型別的/user/<使用者名稱> 目錄,並將此目錄作為當前的HDFS型預設父目錄,即便當前路徑是hadoop安裝根目錄或其它,一律建立目錄/user/<使用者名稱>/<新目錄名>。若想在hadoop安裝根目錄下建立HDFS文,則建立或呼叫時必須給出完整路徑名,如:
hdfs dfs -mkdir -p /home/hadoop/develop/hadoop/HDFS
hdfs dfs -ls -R /home/hadoop/develop/hadoop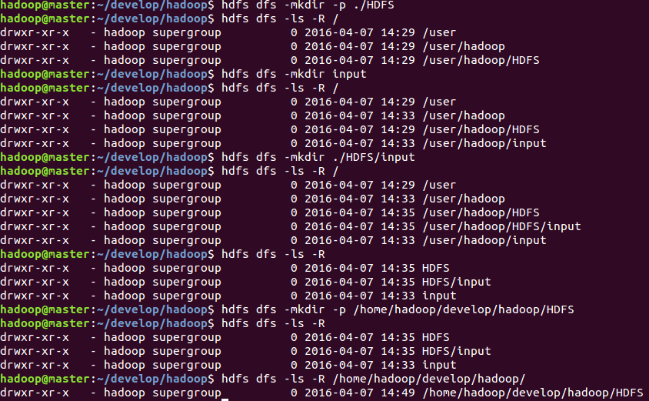
注意,如果此時出現錯誤Cannot create directory /user/hadoop/HDFS. Name node is in safe mode則表示NameNode節點處於安全模式,需要關閉安全模式,執行如下命令
命令:
hadoop dfsadmin -safemode leave
解讀:關閉安全模式
在此,我們選擇系統為HDFS檔案提供的預設根路徑,在根路徑下建立輸入目錄input。在根目錄下,統一刪除HDFS型目錄,重新建立HDFS型目錄。

向輸入目錄裡新增待處理檔案
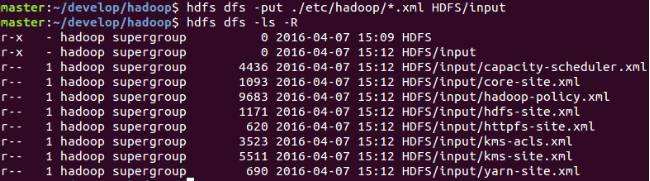
注意:再次強調,HDFS型別的預設根目錄是user/<使用者名稱>,也是HDFS的預設當前目錄。
執行偽分散式例項
命令:
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar grep ./HDFS/input ./HDFS/output 'du[a-z.+]'

執行無誤後會有如下輸出
檢視輸出路徑以及輸出檔案
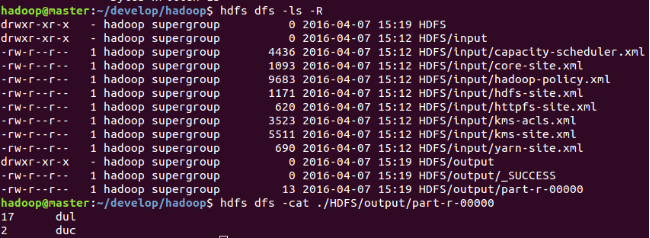
注意,由於偽分散式模式更改了配置檔案,所以與單機模式執行結果不同
也可以將結果去回到本地,執行命令 hdfs dfs -get <源路徑> <目標路徑>
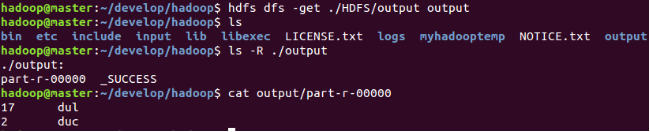
無論是單機模式還是偽分散式模式,執行之前輸出路徑不能存在,所以執行結束後先刪除輸出路徑,避免出錯
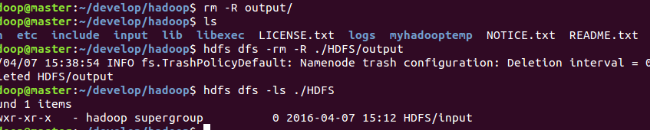
如果需要關閉hadoop則執行如下命令
./sbin/stop-dfs.sh
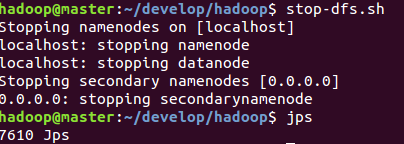
下次啟動 hadoop 時,無需進行 NameNode 的初始化,只需要執行 ./sbin/start-dfs.sh 就可以
再次強調:Hadoop 的執行方式是由配置檔案決定的(執行 Hadoop 時會讀取配置檔案),因此如果需要從偽分散式模式切換回非分散式模式,需要刪除 core-site.xml 中的配置項