
韋東山第三期視訊數碼相框中的電子書專案的ShowOnePage函式解析
阿新 • • 發佈:2019-01-31
解析:int ShowOnePage(unsigned char *pucTextFileMemCurPos)
其中:
iLen = g_ptEncodingOprForFile->GetCodeFrmBuf(pucBufStart, g_pucTextFileMemEnd, &dwCode);
這裡得到一個字 但是得到的編碼並不是返回值而是存在*pdwCode裡 返回的是本次一共處理了檔案裡的多少個位元組資料
iError = ptFontOpr->GetFontBitmap(dwCode, &tFontBitMap); //這裡得到點陣圖資料,就是點陣資料具體參看程式解析說明:
ptFontOpr是誰? 以編碼是UTF8來說:
從編碼的初始化函式可知:
int Utf8EncodingInit(void)
{
AddFontOprForEncoding(&g_tUtf8EncodingOpr, GetFontOpr("freetype"));
AddFontOprForEncoding(&g_tUtf8EncodingOpr, GetFontOpr("ascii"));
return RegisterEncodingOpr(&g_tUtf8EncodingOpr);
}
這裡註冊了字型,ptFontOpr就是其中的一個,那到底是誰?
再看AddFontOprForEncoding函式:
int AddFontOprForEncoding(PT_EncodingOpr ptEncodingOpr, PT_FontOpr ptFontOpr)
{
PT_FontOpr ptFontOprCpy;
if (!ptEncodingOpr || !ptFontOpr)
{
return -1;
}
else
{
ptFontOprCpy = malloc(sizeof(T_FontOpr));
if (!ptFontOprCpy)
{
return -1;
}
else
{
memcpy(ptFontOprCpy, ptFontOpr, sizeof(T_FontOpr));
ptFontOprCpy->ptNext = ptEncodingOpr->ptFontOprSupportedHead;
ptEncodingOpr->ptFontOprSupportedHead = ptFontOprCpy;
return 0;
}
}
}
由上可知:
越是後呼叫該函式的字型,他在連結串列中的位置越靠前,即最後新增的就是連結串列頭指向的字型
往上參看ptFontOpr的來源看到這句話:ptFontOpr = g_ptEncodingOprForFile->ptFontOprSupportedHead;
而其中的ptFontOprSupportedHead就是上面設定的連結串列頭,從上面的這個函式看 int Utf8EncodingInit(void)
可以知道這裡的ptFontOpr就是名為"ascii"的字型。
但是這樣更加得到一個疑惑,如果是從"ascii"字型庫提出字型的,那非"ascii"碼該怎麼辦,現在就來看看"ascii"字型的GetFontBitmap函式,也就是下面的程式碼:
static int ASCIIGetFontBitmap(unsigned int dwCode, PT_FontBitMap ptFontBitMap)
{
int iPenX = ptFontBitMap->iCurOriginX;
int iPenY = ptFontBitMap->iCurOriginY;
if (dwCode > (unsigned int)0x80)
{
//DBG_PRINTF("don't support this code : 0x%x\n", dwCode);
return -1;
}
ptFontBitMap->iXLeft = iPenX;
ptFontBitMap->iYTop = iPenY - 16;
ptFontBitMap->iXMax = iPenX + 8;
ptFontBitMap->iYMax = iPenY;
ptFontBitMap->iBpp = 1;
ptFontBitMap->iPitch = 1;
ptFontBitMap->pucBuffer = (unsigned char *)&fontdata_8x16[dwCode * 16];;
ptFontBitMap->iNextOriginX = iPenX + 8;
ptFontBitMap->iNextOriginY = iPenY;
return 0;
}
現在就出現了一個疑惑,從這裡看根本就沒有對非ascii的支援。
有一個函式與AddFontOprForEncoding相對,也就是DelFontOprFrmEncoding函式,這個函式在這裡應用:
int SetTextDetail(char *pcHZKFile, char *pcFileFreetype, unsigned int dwFontSize)
{
............................
if (strcmp(ptFontOpr->name, "ascii") == 0)
{
iError = ptFontOpr->FontInit(NULL, dwFontSize);
}
else if (strcmp(ptFontOpr->name, "gbk") == 0)
{
iError = ptFontOpr->FontInit(pcHZKFile, dwFontSize);
}
else
{
iError = ptFontOpr->FontInit(pcFileFreetype, dwFontSize);
}
if (iError == 0)
{
/* 比如對於ascii編碼的檔案, 可能用ascii字型也可能用gbk字型,
* 所以只要有一個FontInit成功, SetTextDetail最終就返回成功
*/
iRet = 0;
}
else
{
DelFontOprFrmEncoding(g_ptEncodingOprForFile, ptFontOpr);
}
}
說明如果字型初始換不成功,這裡就會刪除掉字型,那是不是如果傳入的不是ascii碼,在這裡會被刪除了,來看看ascii字型的初始換函式:
static int ASCIIFontInit(char *pcFontFile, unsigned int dwFontSize)
{
if (dwFontSize != 16)
{
//DBG_PRINTF("ASCII can't support %d font size\n", dwFontSize);
return -1;
}
return 0;
}
由這裡可以知道其實如果傳入的字型大小不是16,ascii字型將從utf8碼了刪除,所以utf8只有FileFreetype字型的支援
但是還有一個疑惑,就是當傳入的字型大小為16的時候,如果傳入的內容又有非ascii碼(如“abcd工具能用eclipse進行原始碼級別的除錯有些前提”)又該怎麼辦:
繼續看int ShowOnePage(unsigned char *pucTextFileMemCurPos)函式,在最後看到有這句話:
}
ptFontOpr = ptFontOpr->ptNext;
}
}
也就說如果字型的GetFontBitmap函式不支援的話,將換字型
測試我們的想法:
兩個不同的命令:
./show_file -s 16 -f MSYH.TTF utf8_test.txt
./show_file -s 20 -f MSYH.TTF utf8_test.txt
由上面的分析可知:
第一個命令將會使用ascii字型,第二個命令將使用將使用FileFreetype字型
為了參看結果我們在函式int ShowOnePage(unsigned char *pucTextFileMemCurPos)的pucBufStart = pucTextFileMemCurPos;行後面加上下列列印語句:
printf("g_ptEncodingOprForFile: %s\n",g_ptEncodingOprForFile->name);
printf("first ptFontOpr: %s\n",g_ptEncodingOprForFile->ptFontOprSupportedHead->name);
第二條命令的結果:
/digital_photo_frame/04.show_file_mysel # ./show_file -s 20 -f MSYH.TTF utf8_te
st.txt
g_ptEncodingOprForFile: utf-8
first ptFontOpr: freetype
if (strcmp(ptFontOpr->name, "ascii") == 0)
{
iError = ptFontOpr->FontInit(NULL, dwFontSize);
}
是失敗的,所以utf-8的字型支援庫裡已經沒有了ascii字型
我們再看看第一個指令,
/digital_photo_frame/04.show_file_mysel # ./show_file -s 16 -f MSYH.TTF utf8_te
st.txt
g_ptEncodingOprForFile: utf-8
first ptFontOpr: ascii
在函式int ShowOnePage(unsigned char *pucTextFileMemCurPos)的改變字型的語句:ptFontOpr = ptFontOpr->ptNext;後加上列印:
printf("now ptFontOpr: %s\n",ptFontOpr->name);
改變後的周邊語句應該是這樣的:
/* 繼續取出下一個編碼來顯示 */
break;
}
ptFontOpr = ptFontOpr->ptNext;
printf("now ptFontOpr: %s\n",ptFontOpr->name);
}
}
這樣再看看命令./show_file -s 16 -f MSYH.TTF utf8_te的執行:
/digital_photo_frame/04.show_file_mysel # ./show_file -s 16 -f MSYH.TTF utf8_te
st.txt
g_ptEncodingOprForFile: utf-8
first ptFontOpr: ascii
now ptFontOpr: freetype
now ptFontOpr: freetype
now ptFontOpr: freetype
now ptFontOpr: freetype
now ptFontOpr: freetype
now ptFontOpr: freetype
now ptFontOpr: freetype
now ptFontOpr: freetype
-----------------------
說明切換了很多次字型檔,至於為什麼,我們再來看看int ShowOnePage(unsigned char *pucTextFileMemCurPos)函式的執行過程:
int ShowOnePage(unsigned char *pucTextFileMemCurPos)
{
------------------------
printf("g_ptEncodingOprForFile: %s\n",g_ptEncodingOprForFile->name);
printf("first ptFontOpr: %s\n",g_ptEncodingOprForFile->ptFontOprSupportedHead->name);
while (1)
{
//這裡得到一個字 但是得到的編碼並不是返回值而是存在*pdwCode裡 返回的是本次一共處理了檔案裡的多少個位元組資料
iLen = g_ptEncodingOprForFile->GetCodeFrmBuf(pucBufStart, g_pucTextFileMemEnd, &dwCode);
----------------------------------------
ptFontOpr = g_ptEncodingOprForFile->ptFontOprSupportedHead;
while (ptFontOpr)
{
//這裡得到點陣圖資料,就是點陣資料具體參看程式解析說明:
//當獲取結果不對時出錯 也就是字型發現自己不能支援改編碼的時候
iError = ptFontOpr->GetFontBitmap(dwCode, &tFontBitMap);
if (0 == iError)
{
------------------------------
/* 顯示一個字元 */
if (ShowOneFont(&tFontBitMap))
{
return -1;
}
tFontBitMap.iCurOriginX = tFontBitMap.iNextOriginX;
tFontBitMap.iCurOriginY = tFontBitMap.iNextOriginY;
g_pucLcdNextPosAtFile = pucBufStart;
/* 繼續取出下一個編碼來顯示 */
break;
}
ptFontOpr = ptFontOpr->ptNext;
printf("now ptFontOpr: %s\n",ptFontOpr->name);
}
}
return 0;
}
由此可以發現現實一頁這個功能是在while (1)裡的,注意其中的現實下一個字元的推出語句是break;,其將推出while (ptFontOpr),所以沒顯示完一個字元後都會推出到while (1)下繼續執行,而while (1)下又會重新賦值字型ptFontOpr = g_ptEncodingOprForFile->ptFontOprSupportedHead;所以也就是說當發現某個編碼是非ascii碼需要改變,當現實完一個字元後將重新把字型賦值成預定義的ascii字型,這也就是為什麼出現那麼多的now ptFontOpr: freetype列印語句的原因。
從液晶上也是可以看到凡是英文都是用ascii字型來顯示的,也就是16號字型
至此int ShowOnePage(unsigned char *pucTextFileMemCurPos)函式的以後分析完畢
,
其中:
iLen = g_ptEncodingOprForFile->GetCodeFrmBuf(pucBufStart, g_pucTextFileMemEnd, &dwCode);
這裡得到一個字 但是得到的編碼並不是返回值而是存在*pdwCode裡 返回的是本次一共處理了檔案裡的多少個位元組資料
iError = ptFontOpr->GetFontBitmap(dwCode, &tFontBitMap); //這裡得到點陣圖資料,就是點陣資料具體參看程式解析說明:
ptFontOpr是誰? 以編碼是UTF8來說:
從編碼的初始化函式可知:
int Utf8EncodingInit(void)
{
AddFontOprForEncoding(&g_tUtf8EncodingOpr, GetFontOpr("freetype"));
AddFontOprForEncoding(&g_tUtf8EncodingOpr, GetFontOpr("ascii"));
return RegisterEncodingOpr(&g_tUtf8EncodingOpr);
}
這裡註冊了字型,ptFontOpr就是其中的一個,那到底是誰?
再看AddFontOprForEncoding函式:
int AddFontOprForEncoding(PT_EncodingOpr ptEncodingOpr, PT_FontOpr ptFontOpr)
{
PT_FontOpr ptFontOprCpy;
if (!ptEncodingOpr || !ptFontOpr)
{
return -1;
}
else
{
ptFontOprCpy = malloc(sizeof(T_FontOpr));
if (!ptFontOprCpy)
{
return -1;
}
else
{
memcpy(ptFontOprCpy, ptFontOpr, sizeof(T_FontOpr));
ptFontOprCpy->ptNext = ptEncodingOpr->ptFontOprSupportedHead;
ptEncodingOpr->ptFontOprSupportedHead = ptFontOprCpy;
return 0;
}
}
}
由上可知:
越是後呼叫該函式的字型,他在連結串列中的位置越靠前,即最後新增的就是連結串列頭指向的字型
往上參看ptFontOpr的來源看到這句話:ptFontOpr = g_ptEncodingOprForFile->ptFontOprSupportedHead;
而其中的ptFontOprSupportedHead就是上面設定的連結串列頭,從上面的這個函式看 int Utf8EncodingInit(void)
可以知道這裡的ptFontOpr就是名為"ascii"的字型。
但是這樣更加得到一個疑惑,如果是從"ascii"字型庫提出字型的,那非"ascii"碼該怎麼辦,現在就來看看"ascii"字型的GetFontBitmap函式,也就是下面的程式碼:
static int ASCIIGetFontBitmap(unsigned int dwCode, PT_FontBitMap ptFontBitMap)
{
int iPenX = ptFontBitMap->iCurOriginX;
int iPenY = ptFontBitMap->iCurOriginY;
if (dwCode > (unsigned int)0x80)
{
//DBG_PRINTF("don't support this code : 0x%x\n", dwCode);
return -1;
}
ptFontBitMap->iXLeft = iPenX;
ptFontBitMap->iYTop = iPenY - 16;
ptFontBitMap->iXMax = iPenX + 8;
ptFontBitMap->iYMax = iPenY;
ptFontBitMap->iBpp = 1;
ptFontBitMap->iPitch = 1;
ptFontBitMap->pucBuffer = (unsigned char *)&fontdata_8x16[dwCode * 16];;
ptFontBitMap->iNextOriginX = iPenX + 8;
ptFontBitMap->iNextOriginY = iPenY;
return 0;
}
現在就出現了一個疑惑,從這裡看根本就沒有對非ascii的支援。
有一個函式與AddFontOprForEncoding相對,也就是DelFontOprFrmEncoding函式,這個函式在這裡應用:
int SetTextDetail(char *pcHZKFile, char *pcFileFreetype, unsigned int dwFontSize)
{
............................
if (strcmp(ptFontOpr->name, "ascii") == 0)
{
iError = ptFontOpr->FontInit(NULL, dwFontSize);
}
else if (strcmp(ptFontOpr->name, "gbk") == 0)
{
iError = ptFontOpr->FontInit(pcHZKFile, dwFontSize);
}
else
{
iError = ptFontOpr->FontInit(pcFileFreetype, dwFontSize);
}
if (iError == 0)
{
/* 比如對於ascii編碼的檔案, 可能用ascii字型也可能用gbk字型,
* 所以只要有一個FontInit成功, SetTextDetail最終就返回成功
*/
iRet = 0;
}
else
{
DelFontOprFrmEncoding(g_ptEncodingOprForFile, ptFontOpr);
}
}
說明如果字型初始換不成功,這裡就會刪除掉字型,那是不是如果傳入的不是ascii碼,在這裡會被刪除了,來看看ascii字型的初始換函式:
static int ASCIIFontInit(char *pcFontFile, unsigned int dwFontSize)
{
if (dwFontSize != 16)
{
//DBG_PRINTF("ASCII can't support %d font size\n", dwFontSize);
return -1;
}
return 0;
}
由這裡可以知道其實如果傳入的字型大小不是16,ascii字型將從utf8碼了刪除,所以utf8只有FileFreetype字型的支援
但是還有一個疑惑,就是當傳入的字型大小為16的時候,如果傳入的內容又有非ascii碼(如“abcd工具能用eclipse進行原始碼級別的除錯有些前提”)又該怎麼辦:
繼續看int ShowOnePage(unsigned char *pucTextFileMemCurPos)函式,在最後看到有這句話:
}
ptFontOpr = ptFontOpr->ptNext;
}
}
也就說如果字型的GetFontBitmap函式不支援的話,將換字型
測試我們的想法:
兩個不同的命令:
./show_file -s 16 -f MSYH.TTF utf8_test.txt
./show_file -s 20 -f MSYH.TTF utf8_test.txt
由上面的分析可知:
第一個命令將會使用ascii字型,第二個命令將使用將使用FileFreetype字型
為了參看結果我們在函式int ShowOnePage(unsigned char *pucTextFileMemCurPos)的pucBufStart = pucTextFileMemCurPos;行後面加上下列列印語句:
printf("g_ptEncodingOprForFile: %s\n",g_ptEncodingOprForFile->name);
printf("first ptFontOpr: %s\n",g_ptEncodingOprForFile->ptFontOprSupportedHead->name);
第二條命令的結果:
/digital_photo_frame/04.show_file_mysel # ./show_file -s 20 -f MSYH.TTF utf8_te
st.txt
g_ptEncodingOprForFile: utf-8
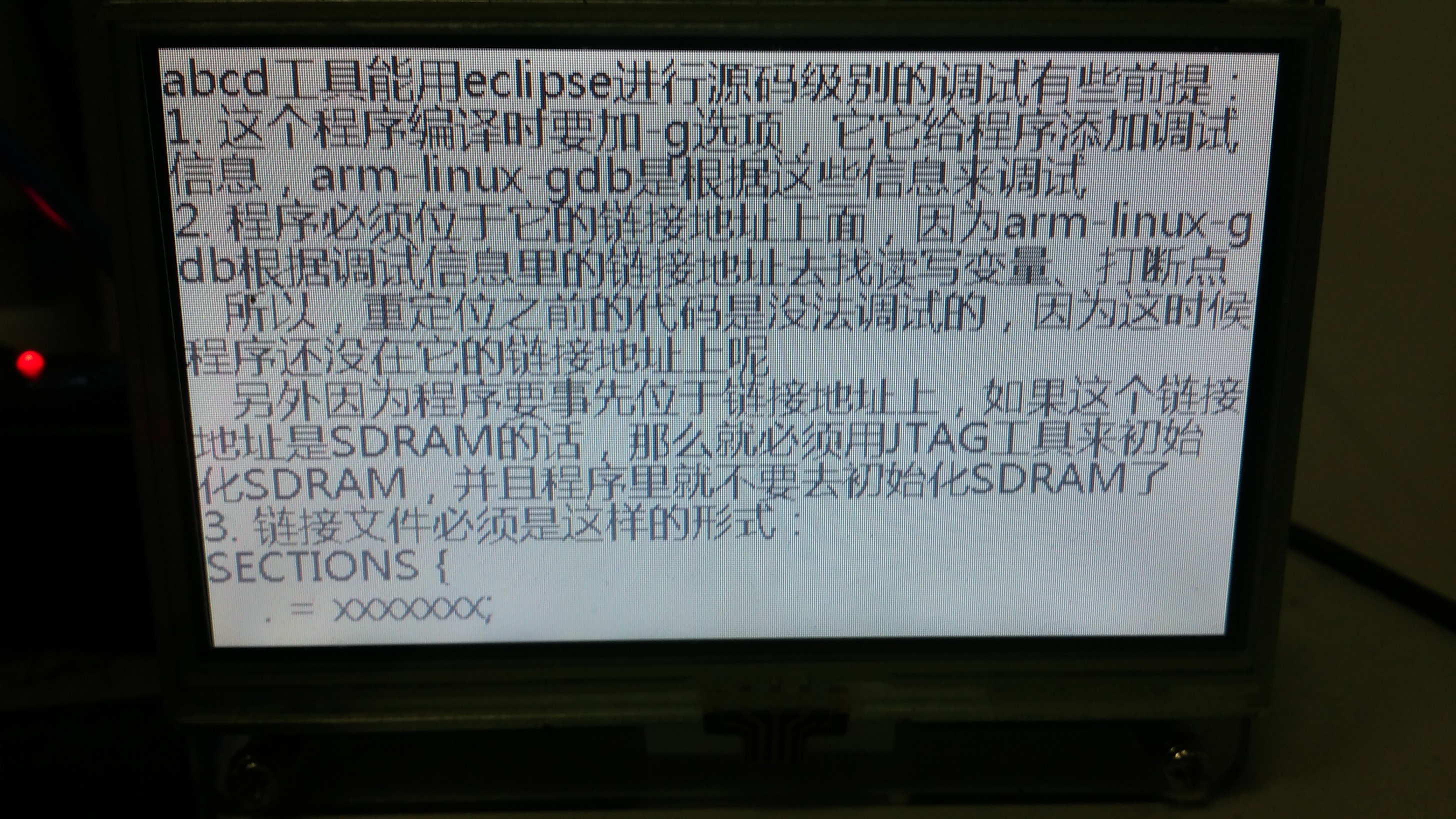
first ptFontOpr: freetype
Enter 'n' to show next page, 'u' to show previous page, 'q' to exit:
液晶顯示的影象:
if (strcmp(ptFontOpr->name, "ascii") == 0)
{
iError = ptFontOpr->FontInit(NULL, dwFontSize);
}
是失敗的,所以utf-8的字型支援庫裡已經沒有了ascii字型
我們再看看第一個指令,
/digital_photo_frame/04.show_file_mysel # ./show_file -s 16 -f MSYH.TTF utf8_te
st.txt
g_ptEncodingOprForFile: utf-8
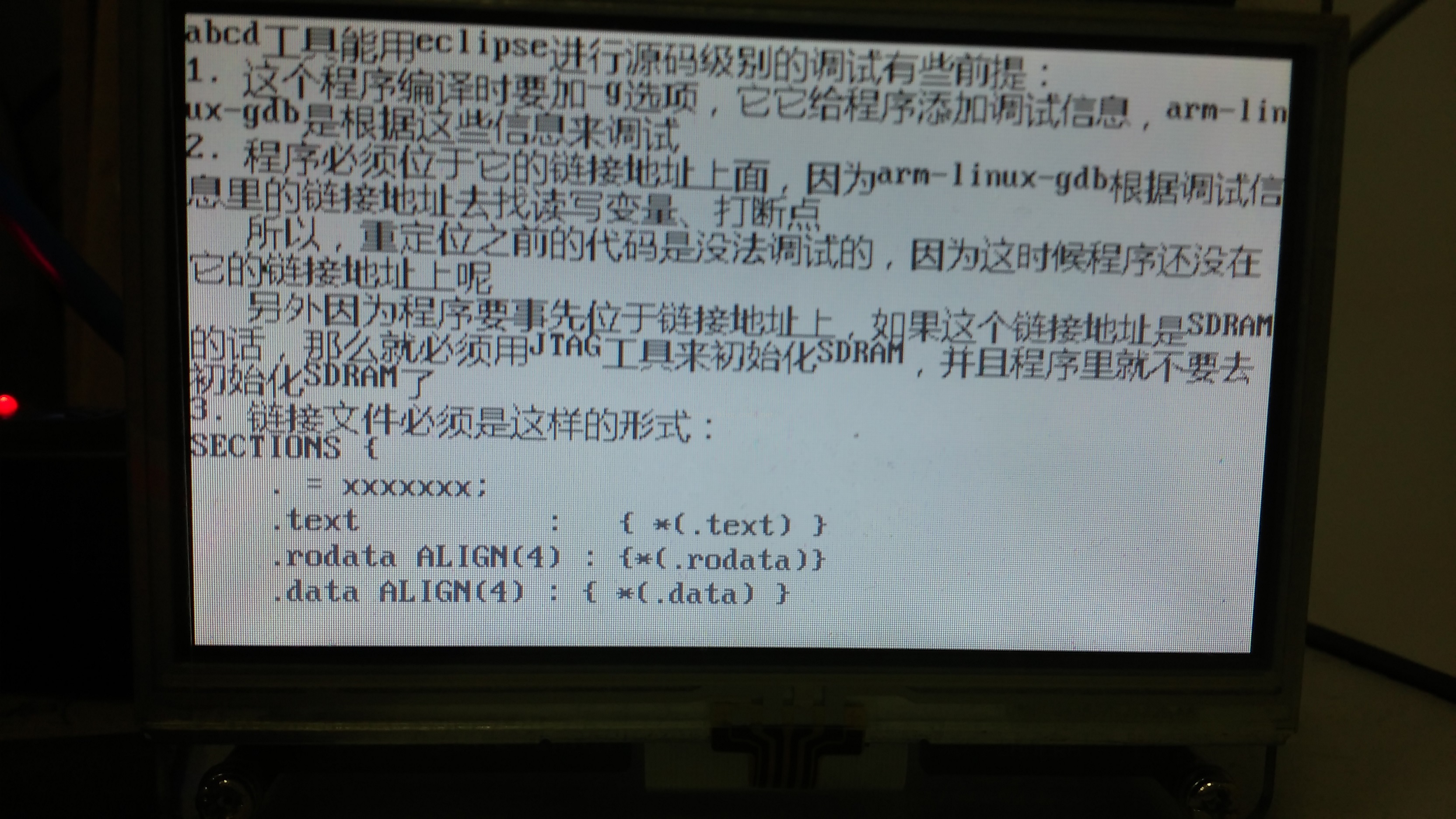
first ptFontOpr: ascii
Enter 'n' to show next page, 'u' to show previous page, 'q' to exit:
液晶顯示的影象:
在函式int ShowOnePage(unsigned char *pucTextFileMemCurPos)的改變字型的語句:ptFontOpr = ptFontOpr->ptNext;後加上列印:
printf("now ptFontOpr: %s\n",ptFontOpr->name);
改變後的周邊語句應該是這樣的:
/* 繼續取出下一個編碼來顯示 */
break;
}
ptFontOpr = ptFontOpr->ptNext;
printf("now ptFontOpr: %s\n",ptFontOpr->name);
}
}
這樣再看看命令./show_file -s 16 -f MSYH.TTF utf8_te的執行:
/digital_photo_frame/04.show_file_mysel # ./show_file -s 16 -f MSYH.TTF utf8_te
st.txt
g_ptEncodingOprForFile: utf-8
first ptFontOpr: ascii
now ptFontOpr: freetype
now ptFontOpr: freetype
now ptFontOpr: freetype
now ptFontOpr: freetype
now ptFontOpr: freetype
now ptFontOpr: freetype
now ptFontOpr: freetype
now ptFontOpr: freetype
-----------------------
說明切換了很多次字型檔,至於為什麼,我們再來看看int ShowOnePage(unsigned char *pucTextFileMemCurPos)函式的執行過程:
int ShowOnePage(unsigned char *pucTextFileMemCurPos)
{
------------------------
printf("g_ptEncodingOprForFile: %s\n",g_ptEncodingOprForFile->name);
printf("first ptFontOpr: %s\n",g_ptEncodingOprForFile->ptFontOprSupportedHead->name);
while (1)
{
//這裡得到一個字 但是得到的編碼並不是返回值而是存在*pdwCode裡 返回的是本次一共處理了檔案裡的多少個位元組資料
iLen = g_ptEncodingOprForFile->GetCodeFrmBuf(pucBufStart, g_pucTextFileMemEnd, &dwCode);
----------------------------------------
ptFontOpr = g_ptEncodingOprForFile->ptFontOprSupportedHead;
while (ptFontOpr)
{
//這裡得到點陣圖資料,就是點陣資料具體參看程式解析說明:
//當獲取結果不對時出錯 也就是字型發現自己不能支援改編碼的時候
iError = ptFontOpr->GetFontBitmap(dwCode, &tFontBitMap);
if (0 == iError)
{
------------------------------
/* 顯示一個字元 */
if (ShowOneFont(&tFontBitMap))
{
return -1;
}
tFontBitMap.iCurOriginX = tFontBitMap.iNextOriginX;
tFontBitMap.iCurOriginY = tFontBitMap.iNextOriginY;
g_pucLcdNextPosAtFile = pucBufStart;
/* 繼續取出下一個編碼來顯示 */
break;
}
ptFontOpr = ptFontOpr->ptNext;
printf("now ptFontOpr: %s\n",ptFontOpr->name);
}
}
return 0;
}
由此可以發現現實一頁這個功能是在while (1)裡的,注意其中的現實下一個字元的推出語句是break;,其將推出while (ptFontOpr),所以沒顯示完一個字元後都會推出到while (1)下繼續執行,而while (1)下又會重新賦值字型ptFontOpr = g_ptEncodingOprForFile->ptFontOprSupportedHead;所以也就是說當發現某個編碼是非ascii碼需要改變,當現實完一個字元後將重新把字型賦值成預定義的ascii字型,這也就是為什麼出現那麼多的now ptFontOpr: freetype列印語句的原因。
從液晶上也是可以看到凡是英文都是用ascii字型來顯示的,也就是16號字型
至此int ShowOnePage(unsigned char *pucTextFileMemCurPos)函式的以後分析完畢
本文使用的原始碼:
http://download.csdn.net/detail/chengdong1314/9285361
,