
爬蟲用fiddler抓取網易新聞客戶端手機app內容
阿新 • • 發佈:2019-01-31
一,工具
電腦安卓模擬器:夜神模擬器
抓包工具:fiddler
程式碼:pycharm
二、分析
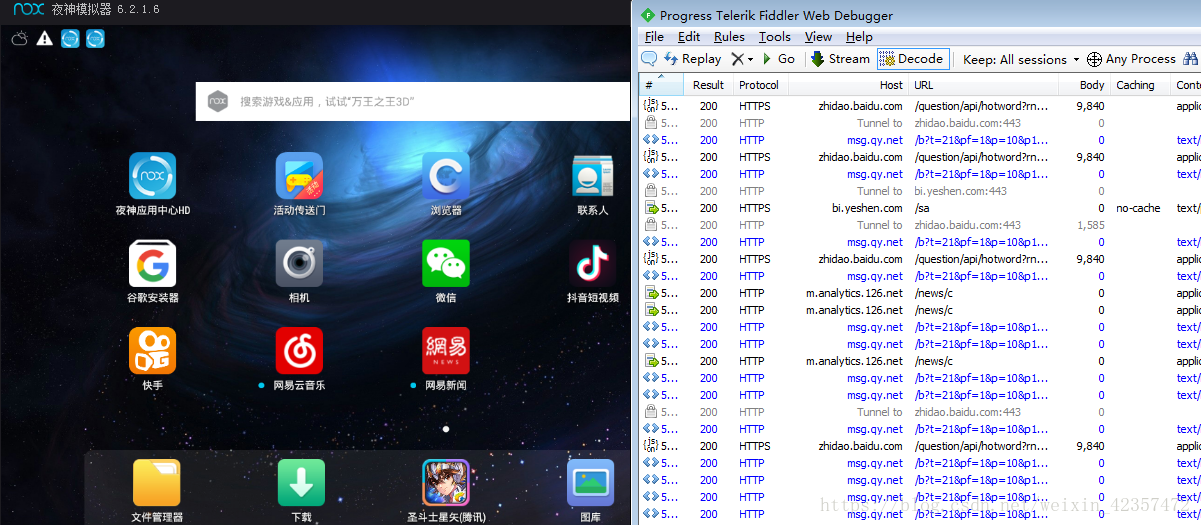
1.首先要設定好fiddler和夜神模擬器的關聯,這個網上很多教程這裡不做介紹
2.開啟網易app,觀察fiddler抓包列表,儘量先清空下然後重新整理網易這樣再次觀察更清晰
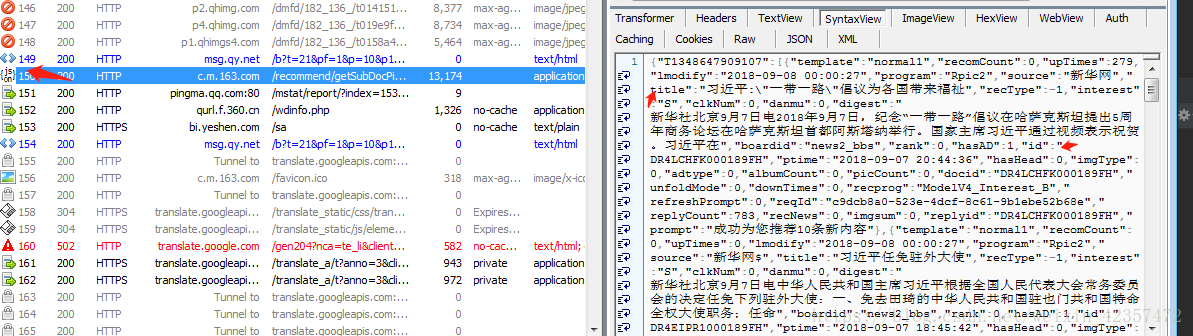
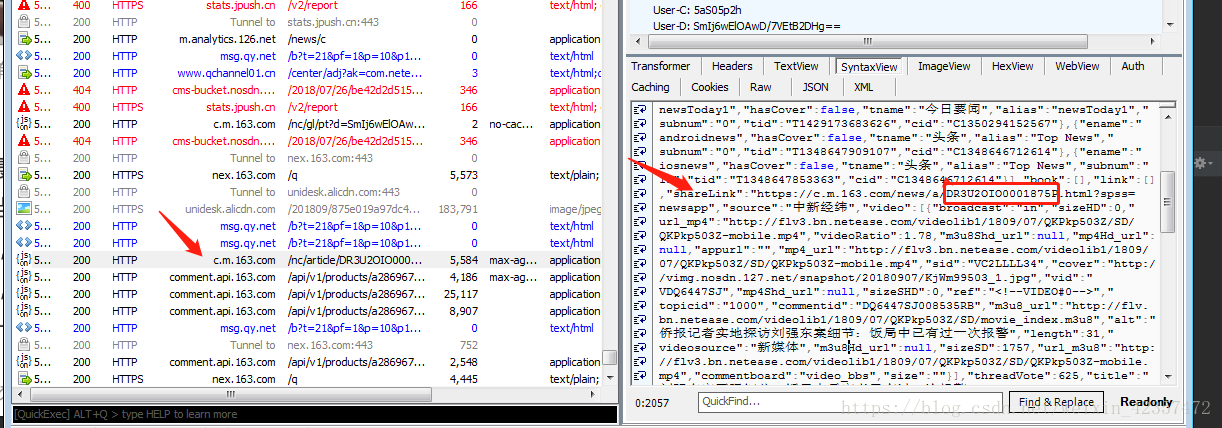
3.找到內容的包,當然這個需要多觀察,看到一個json的api介面
4.分析json資料能看到內容的標題,來源,簡介和新聞內容的跳轉連結的id
5.新聞內容連結還是通過抓包分析就是由具體格式加上id組成
三、程式碼
主要通過簡單的請求和解析出想要的內容,requests請求,json轉出dict,然後就是解析出想要的內容 #效果展示

import requests
import json
url="http://c.m.163.com/recommend/getSubDocPic?tid=T1348647909107&from=toutiao&offset=0&size=10&fn=2&LastStdTime=0&spestr=&prog=&passport=&devId=SmIj6wElOAwD%2F7VEtB2DHg%3D%3D&lat=d7C%2FuQEMvzpJvLOCtGz7eA%3D%3D&lon=jKhXi261wzrUpMyoUJMkXA%3D