
C++編譯連結全過程
今天博文主要討論的問題是:我們編寫的程式程式碼是怎樣執行起來的?到底執行的是什麼內容?平時我們所說的編譯主要包括預編譯、編譯、彙編三部分,這三部分分別都幹什麼工作,主要職能有哪些,接下來我們一步步探討總結。
(一)預編譯
(1)由原始檔“.cpp/.c”生成“.i”檔案,這是在預編譯階段完成的;gcc -E .cpp/.c --->.i
(2)主要功能
- 展開所有的巨集定義,消除“#define”;
- 處理所有的預編譯指令,比如#if、#ifdef等;
- 處理#include預編譯指令,將包含檔案插入到該預編譯的位置;
- 刪除所有的註釋“/**/”、"//"等;
- 新增行號和檔名標識,以便於編譯時編譯器產生除錯用的行號資訊以及錯誤提醒;
- 保留所有的#program編譯指令,原因是編譯器要使用它們;
(3)缺點:不進行任何安全性及合法性檢查
(二)編譯---核心
編譯過程就是把經過預編譯生成的檔案進行一系列語法分析、詞法分析、語義分析優化後生成相應的彙編程式碼檔案。
(1)由“.i”檔案生成“.s”檔案,這是在編譯階段完成的;gcc -S .i --->.s
(2)主要功能
- 詞法分析:將原始碼檔案的字元序列劃分為一系列的記號,一般詞法分析產生的記號有:識別符號、關鍵字、數字、字串、特殊符號(加號、等號);在識別記號的同時也將識別符號放好符號表、將數字、字元放入到文字表等;有一個lex程式可以實現詞法掃描,會按照之前定義好的詞法規則將輸入的字串分割成記號,所以編譯器不需要獨立的詞法掃描器;
- 語法分析:語法分析器將對產生的記號進行語法分析,產生語法樹----就是以表示式尾節點的樹,一步步判斷如何執行表示式操作。下圖為一個語法樹:
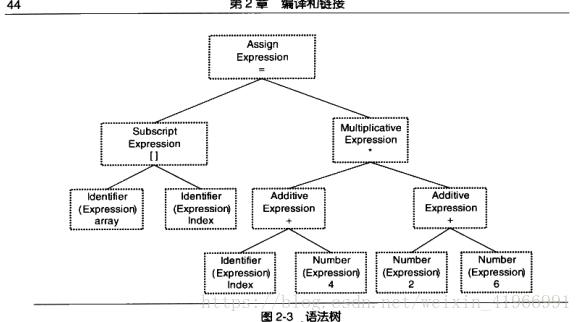
如果存在括號不匹配或者表示式錯誤,編譯器就會報告語法分析階段的錯誤;相同的存在一個yacc程式可以根據使用者輸入的語法規則生成語法樹;
- 語義分析:由語法階段完成分析的並沒有賦予表示式或者其他實際的意義,比如乘法、加法、減法,必須經過語義階段才能賦予其真正的意義;
語義分析主要分為靜態語義和動態語義兩種;靜態語義通常包括宣告和型別的匹配、型別的轉換。比如當一個浮點型的表示式賦值給一個整型的表示式時,其中隱含了一個浮點型到整型轉換的過程。只要存在型別不匹配編譯器會報錯。經過語義分析後的語法樹的所有表示式都有了型別。動態語義分析只有在執行階段才能確定;
- 優化後生成相應的彙編程式碼檔案
- 彙總所有符號
(三)彙編:生成可重定位的二進位制檔案;(.obj檔案)
(1)由“.s”檔案生成的“.obj”檔案;gcc -c .s-->.o;
(2)此檔案中生成符號表,能夠產生符號的有:所有資料都要產生符號、指令只產生一個符號(函式名);
(四)連結
連結階段主要分為兩部分:
(1)合併所有“.obj”檔案的段並調整段偏移和段長度(按照段的屬性合併,屬性可以是“可讀可寫”、“只讀”、“可讀可執行”,合併後將相同屬性的組織在一個頁面內,比較節省空間),合併符號表,進行符號解析完成後給符號分配地址;其中符號解析的意思是:所有.obj符號表中對符號引用的地方都要找到該符號定義的地方。在編譯階段,有資料的地方都是0地址,有函式的額地方都是下一行指令的偏移量-4(由於指標是4位元組);可執行檔案以頁面對齊。
符號重定位舉例:main.c extern int gdata; test.c int gdata = 10;
main.o *UND* gdata -------->test.o gdata //符號重定位
在進行符號解析時要注意只對global符號進行處理,對於local符號不做處理;
(2)符號的重定位(連結核心):將符號分配的虛擬地址寫回原先未分配正確地址的地方
對於資料符號會存準確地址,對於函式符號,相對於存下一行指令的偏移量(從PC暫存器取地址,並且PC中下一行指令的地址)
(五)程式的執行
(1)建立虛擬地址空間到物理空間的對映(建立核心地址對映結構體),建立頁目錄和頁表;
(2)載入程式碼段和資料段
(3)把可執行檔案的入口地址寫到CPU的PC暫存器裡
(六)目標檔案型別
Linux下的ELF檔案主要有以下四種:
(1)可重定位檔案.obj,這種檔案包括資料和指令,可以被連結成為可執行檔案(.exe)或者共享目標檔案(.so),靜態連結庫可以歸為這一類;
(2)可執行檔案.exe,這種檔案包含了可以直接執行的程式,它的代表就是ELF可執行檔案,他們一般都沒有副檔名;
(3)共享目標檔案.so,這種檔案包含了資料和指令,可以在以下兩種情況下使用:一是連結器使用這種檔案與其他可重定位檔案和共享目標檔案連結,二是動態連結器將幾個共享目標檔案與可執行檔案結合,作為程序映像的一部分使用。
(4)核心轉儲檔案,當程序意外終止時,系統可以將該程序的地址空間的內容及種植的一些資訊轉儲到核心檔案中,比如core dump檔案。
(七)可重定位檔案與可執行檔案的結構比較
在編譯連結的全過程中,彙編完成後生成“可重定位的二進位制檔案.obj”,連結階段完成後生成可執行檔案.exe,這兩者有何區別呢?可重定位檔案為什麼不可以執行?接下來將比較這種檔案的結構佈局,以回答上面的疑惑。
當一個程式執行時,作業系統會給程序分配的虛擬地址空間以達到每個程序都有自己獨立的執行空間,但是各個程序空間共享核心空間,在32位下,這個空間大小為4G,在64位下,這個虛擬地址空間為8G;下圖為32為下虛擬地址空間的佈局:

其中核心空間中的ZONE_DMA 直接記憶體訪問,佔16M,用於磁碟與記憶體的檔案資料交換;
ZONE_NORMAL :平時使用的正常的核心空間;
ZONE_HIGHMEM:高階記憶體處理。處理高階記憶體大於1G的資料;(64位沒有)由於此空間非常大以至於對映後的虛擬地址空間不足。
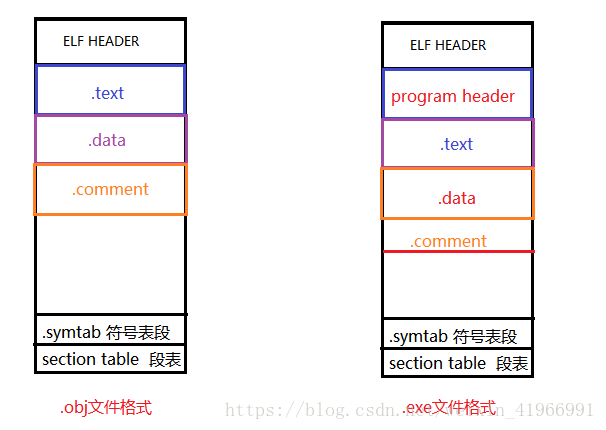
(1)可重定位檔案(.obj)的組織布局和可執行檔案(.exe)組織格式的比較
(1)readelf -h *.o 檢視 .o檔案的檔案頭ELF HEADER資訊,包括class(一般為32位)、data、program header、一些地址記錄、size記錄等;改變(函式入口地址0x0+符號0x0,彙編階段完成後)
readelf -S *.o 檢視section headers 中的內容 包括段的內容、偏移量、屬性等;
objdump -d *.o objdump -S *.o 得到彙編後的機器碼檔案
objdump -t *.o 檢視符號表 objdump -h *.o 檢視.o檔案的各個段(常用的段.data/.text/.bss/.comment)
(2)在虛擬地址空間上存在的.bss段主要儲存未初始化的或者初始化為0的全域性變數或者靜態變數,但是在.obj和.exe中並不存在此段,那麼上述中的資料儲存在檔案的哪裡呢?答案是儲存在了“*.comment*”塊中,這是因為存在強弱資料型別所導致的,請看下圖中所示的情況:
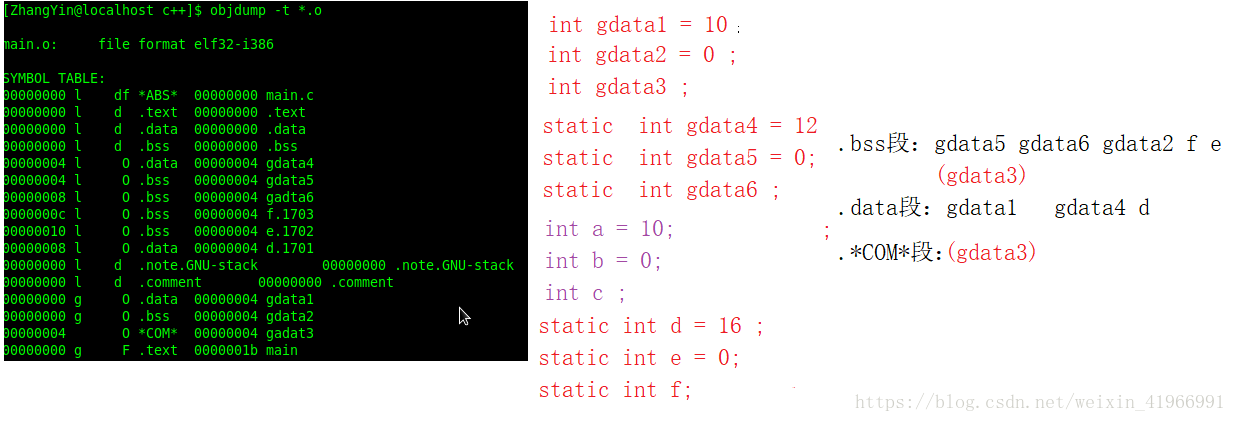
原則上根據.bss的儲存內容可以得知gdata3其空間儲存,但是卻放在了.comment塊中,gdata3是一個弱型別,其原因是由於我們不確定其他檔案是否會存在同名強型別或者大於其位元組數的弱型別出現,造成外檔案的變數引用,因此,先將其存放在*COM*中;強弱型別的區分為:強型別(已經初始化的變數)、弱型別(未初始化的變數)。使用規則是:
在.c檔案中,假如我們同一目錄下的main.c和test.c檔案中兩者優先規則:
(1)兩個檔案中都同時定義了int型別的x變數,那麼在編譯時會提醒有重定義型別;
(2)兩個檔案中強型別和弱型別都存在時,選擇強型別;
(3)兩個檔案中弱型別同時出現時,選擇位元組數大的弱型別;
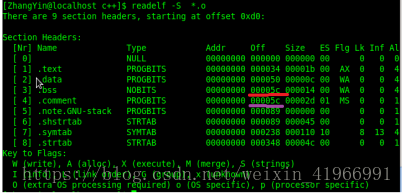
從上圖中看到.obj檔案中的段資訊中.bss 和.comment佔據同一地址,說明.bss段並未佔據檔案空間,只佔據虛擬地址空間;那麼我們如何知道虛擬地址空間中.bss段是否存有資料。請看下圖所示佈局資訊:
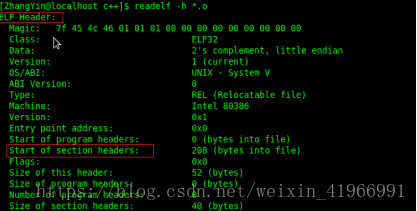
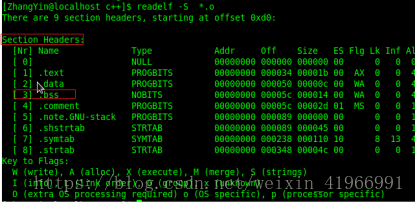
從上面兩幅圖中可以看到用readelf -h *.o可以檢視檔案頭ELF HEADER 資訊,其中包括section header,而通過readelf -S *.o可以檢視到段的所有資訊,從而看到.bss段是否存有資料。
(3)從obj 和exe的組織形式比較中發現,exe檔案比obj多了一個program header 域,可使用readelf -l 可執行檔名 檢視program header域的具體資訊,如下圖所示:

由於我們執行程式只加載資料和指令,並且我們所有的obj檔案和exe檔案都是以“頁”為對齊方式,同時每個頁儲存的內容按照屬性進行分頁儲存,所以program header有兩個載入頁面,只有將資料和指令儲存於頁中才能真正的給符號分配地址從而執行程式。資料有隻讀和只寫、指令有隻讀和執行,故而可以根據這個屬性確定那些段應該放在哪一個頁中,這個屬性以及只能載入資料和指令決定了只存在兩個load頁在磁碟上。到這裡為止,我們已經準備好了這個程式可以執行的所有條件。此時可執行檔案裡的內容按照load的佈局被儲存在磁碟中,那麼如何執行呢?由下面這幅圖來說明:
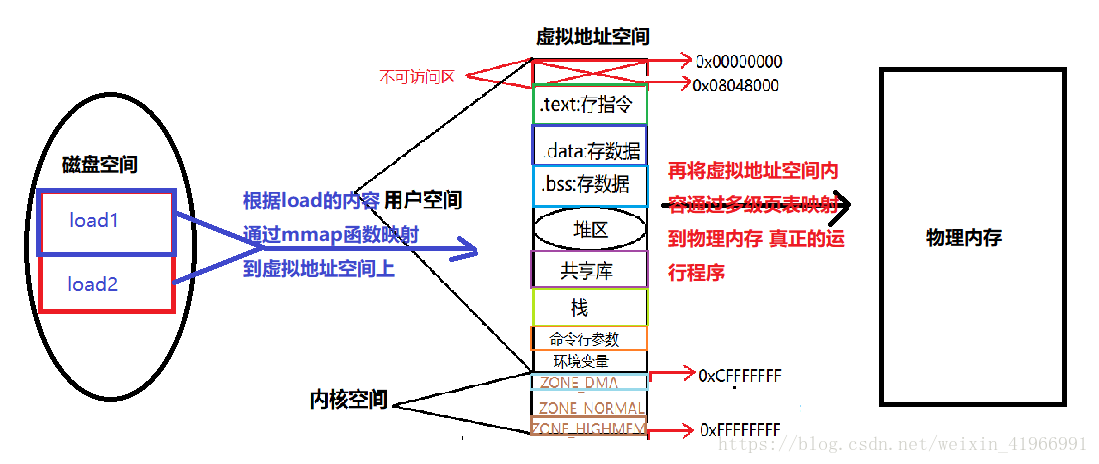
從上圖就可以看出一個程式從編譯連結到執行的全過程。
歡迎大家留言指出不足。