
資訊增益與資訊增益率詳解
熟悉決策樹演算法的人都知道ID3以及C4.5兩種演算法,當然也非常清楚資訊增益以及資訊增益率兩個概念。
資訊增益:節點M的資訊熵E1與其全部子節點資訊熵之和E2的差。
資訊增益率:節點資訊增益與節點分裂資訊度量的比值。
資訊增益是ID3演算法的基礎,資訊增益率是C4.5演算法的基礎。同時,C4.5是ID3演算法的改進版,改進了某些情況下,決策樹構建過程中過擬合的問題。
首先說一下資訊增益:
在網上,我們可以輕鬆找到資訊增益的計算公式,乍一看,公式極為簡單,只是兩個熵減一下,但實際上,當我們去程式碼實現時,卻可能會遇到,究竟該如何計算Entropy(S)跟Gain(S,A)的問題。
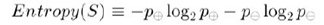
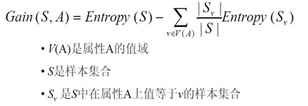
S是樣本集合這句話描述的並不清晰,對於初學決策樹模型的人來說,把S說成所有位於節點M的樣本的集合,或許更為恰當。
之所以這麼說,是因為下圖
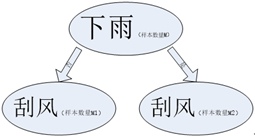
同樣是颳風的屬性,但是,樣本的數量卻發生的變化,這在決策樹的構建過程中是經常遇到的現象。
屬性會重複出現?有些人或許會感到不解,但是看weka使用J48跑測試樣例的結果,大家或許就能明瞭了。

在一條從上往下的路徑中,petalwidth屬性出現了兩次呢。
許多剛剛學習決策樹的人很難理解為什麼計算一個節點的時候需要用到樣本(誤以為是整個樣本)集合,其實這裡的樣本集合指的是,當前在某個節點N上的樣本集合SN;
使用數學話的形式表述資訊增益前,定義幾個常用的變數,使用變數表示節點A上的樣本集合,使用
表示在節點A的全部樣本中屬於類別Ci的樣本數量,使用NAm表示在節點A選擇屬性m的樣本數量,用
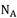
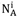
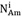
這樣我們可以表示出節點A的熵為,注意,這裡直接使用了概率公式替換了前面公式中的p;
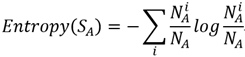
節點A的屬性有M個,所以Gain(S,A)即可表述成如下形式
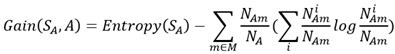
有了資訊增益的實際表示式之後,我們再根據資訊增益率的描述寫出資訊增益率的表示式:
資訊增益比率實際在資訊增益的基礎上,又將其除以一個值,這個值一般被成為分裂資訊量,是將屬性可選值m作為劃分,計算節點上樣本總的資訊熵。
大家可以在網上找到如下公式:
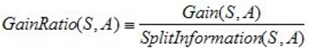
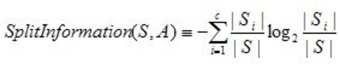
必須說,直接去寫S很容易誤導人,所以我將公式重寫了一下,如下:
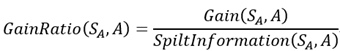
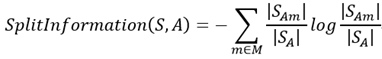
然後,我們將之前定義的變數代入到公式中,可以得到GainRatio(SA,A)的最終表示式:
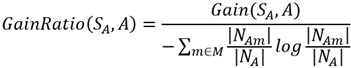
即:
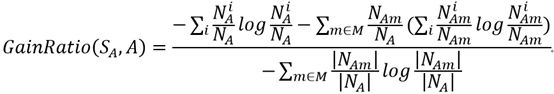
大家一定要注意,計算節點熵和計算節點分類資訊量的時候,樣本的劃分標準一個是類別,一個是節點的可選屬性!!
最後的公式可能有點複雜,但是如果一點一點拼湊起來的話,其實很簡單,以此勉勵。