
虛擬機器搭建haddoop、zookeeper、hbase叢集
安裝jdk
開啟一個虛擬機器,右鍵單擊桌面選擇Open in Terminal,進入編輯介面:
1.假設使用者名稱是wxx(獲取root許可權)
(1)使wxx成為sudoer
su
cd /etc
vi sudoers
i 進入編輯狀態
在root ALL=(ALL) ALL的下一行編輯
wxx ALL=(ALL) ALL
按ESC鍵
按Shift + :
輸入wq!
(2)建立hadoop資料夾
cd
mkdir hadoop
將jdk-7u79-linux-x64安裝包複製到hadoop檔案目錄下(與windows環境下類似)。
(3)解壓jdk-7u79-linux-x64.gz檔案
cd
cd hadoop
tar -zxvf jdk-7u79-linux-x64.gz
(4)設定jdk環境變數
cd
cd hadoop
su
gedit /etc/profile
進入後在最後一行新增以下指令:
export JAVA_HOME=/home/wxx/hadoop/jdk1.7.0_79
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
點選儲存後關閉,輸入以下指令使jdk生效:
source /etc/profile
(5)檢查jdk是否安裝成功
java -version
成功後顯示如下資訊:
java version"1.7.0_79"
Java(TM) SE RuntimeEnvironment (build 1.7.0_79-b15)
Java HotSpot(TM) 64-Bit ServerVM (build 24.79-b02, mixed mode)
四、建立叢集
1.克隆虛擬機器
將已經安裝好jdk的虛擬機器克隆兩個,建立三個虛擬機器的叢集。
2.修改後hostname
su
vi /etc/sysconfig/network
將三個虛擬機器分別命名master、slave1、slave2
如圖:(完成後重啟虛擬機器reboot)
3.將三個虛擬機器的ip地址相互連線
首先必須確保虛擬機器聯網,如果NET模式連不上網,則選中橋接模式。
網路通暢後執行以下操作:
(1)分別對三個虛擬機器執行指令ifconfig,檢視各虛擬機器ip地址
(2)在master中執行以下指令
su
cd /etc
gedit /etc/hosts
進入編輯介面後按“IP地址 hostname”填寫資訊,如圖:
填寫完後按Save按鈕,關閉編輯頁。
(3)將配置好的檔案複製到slave1、slave2中
在master中執行以下指令:
scp /etc/hosts [email protected]:/etc/
scp /etc/hosts [email protected]:/etc/
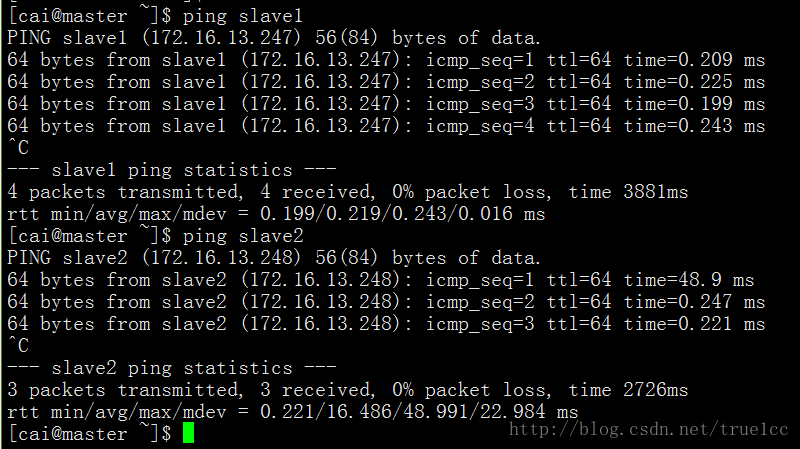
(4)檢查各虛擬機器是否互聯
在master中執行以下指令:
ping slave1
ping slave2
連通後顯示如下:
4.配置SSH無金鑰登入
(1)關閉防火牆
對每個虛擬機器進行如下操作:
su
chkconfig iptables off
執行後重啟虛擬機器: reboot
(2)關閉防火牆後在master下執行以下指令:
cd
ssh-keygen –t rsa
cd .ssh
cat id_rsa.pub >> authorized_keys
chmod 600 authorized_keys
scp authorized_keys [email protected]:~/.ssh/
scp authorized_keys [email protected]:~/.ssh/
(3)檢查無金鑰登入是否成功
ssh slave1
ssh slave2
ssh master
成功後顯示如下:

5.安裝並配置hadoop-2.6.4(在master中)
(1)將hadoop-2.6.4.tar.gz安裝包複製到hadoop檔案目錄下(與windows環境下類似)。
(2)解壓hadoop-2.6.4.tar.gz
cd
cd hadoop
tar -zxvf hadoop-2.6.4.tar.gz
(3)配置hadoop-2.6.4的各項檔案
cd
cd hadoop/hadoop-2.6.4
cd etc/hadoop
gedit hadoop-env.sh
在最後一行新增:export JAVA_HOME=/home/wxx/hadoop/jdk1.7.0_79
gedit core-site.xml
新增程式碼:
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
<final>true</final>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/wxx/hadoop/tmp</value>
</property>
<property>
<name>ds.default.name</name>
<value>hdfs://master:54310</value>
<final>true</final>
</property>
gedit hdfs-site.xml
新增程式碼:
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/wxx/hadoop/dfs/name</value>
<final>true</final>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/wxx/hadoop/dfs/data</value>
<final>true</final>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
gedit mapred-site.xml
(注意:必須先複製mapred-site.xml.template檔案更名為mapred-site.xml)
新增程式碼:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
gedit yarn-site.xml
新增程式碼:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
gedit master
新增程式碼:
master
gedit slaves
新增程式碼:
master
slave1
slave2
(4)將配置好的檔案複製到slave1、slave2中
cd
cd hadoop
scp -r hadoop-2.6.4 slave1:~/hadoop
scp -r hadoop-2.6.4 slave2:~/hadoop
(5)啟動叢集
cd
cd hadoop/hadoop-2.6.4
bin/hdfs namenode -format
// 格式化namenode
sbin/start-dfs.sh //如果不能執行就是許可權問題需要給安裝目錄開通許可權
sbin/start-yarn.sh
sbin/hadoop-daemon.sh start secondarynamenode
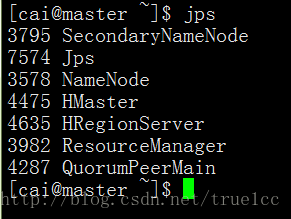
(6)檢查叢集情況
jps (master 出現這幾個說明安裝成功!!!)
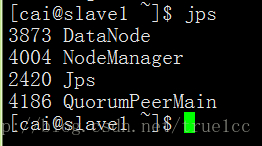
jps(slave1、slave2 出現一下出現下圖)
1、先安裝zookeeper,再安裝hbase,重中之重是先把三個主機的防火牆關掉,不然你會發現怎麼都搞不定的;
root賬戶下,
service iptables stop(關閉防火牆立即生效,但重啟後無效)
chkconfig iptables off(關閉防火牆重啟生效,但不會立即生效)
建議兩條命令都執行一遍,當然之前關過的,不必擔心了。
2、tar -zxvf zookeeper-*.gz(*是版本號,自己補齊) ,
然後在conf目錄下,
1) cp zoo-simple.cfg zoo.cfg
2) mkdirdata
3) touchdata/myid (myid檔案裡寫上server序號)
4) gedit zoo.cfg
改dataDir=/home/cc/hadoop/zookeeper-3.4.9/data/ (安裝目錄)
在尾部新增三行:
server.0=master:2888:3888
server.1=slave1:2888:3888
server.2=slave2:2888:3888
這裡的2888是leader的port,3888是follower的port。可以是其他值。
5)然後
#scp -r ~/zookeeper-*slave1:~/hadoop
scp -r ~/zookeeper-3.4.9slave1:~/hadoop
#scp -r ~/zookeeper-*slave2:~/hadoop
scp -r ~/zookeeper-3.4.9slave2:~/hadoop
6)需要在/home/cc/hadoop/zookeeper-3.4.9/data/myid(myid是新建的)
master裡面myid寫0
slave1裡面myid寫1
slave2裡面myid寫2
3、安裝hbase,
tar -zxvf hbase-*.gz,
①在conf/hbase-env.sh中,新增
export JAVA_HOME=/home/cc/hadoop/jdk1.8.0_121/(你的JDK目錄)還有
export HBASE_MANAGES_ZK=false
這句話的意思是不使用hbase自帶的zookeeper,其實這兩句話
都是有的,被註釋了,但取值可能是不一樣的;
②在conf/hbase-site.xml中
configuration標籤之間新增如下程式碼:
<property>
<name>hbase.rootdir</name>
<value>hdfs://master:9000/hbase</value>
<!--hbase目錄的位置,開啟之後,你會發現eclipse的hadoop目錄裡邊多了個hbase目錄-->
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
<!--分散式叢集-->
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>master:2181,slave1:2181,slave2:2181</value>
<!--這是叢集裡邊的機器-->
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
<!---->
</property>
③在conf/regionservers檔案裡邊寫入
master
slave1
slave2
兩個從屬機的名稱,這個是連線遠端伺服器的名單,因為,我們一般是在master上開啟hbase的,要遠端連線另外兩臺的。
④同樣的
#scp -r ~/hbase-* slave1:~/hadoop
scp -r hbase-1.2.5 slave1:~/hadoop
#scp -r ~/hbase-* slave2:~/hadoop
scp -r hbase-1.2.5 slave2:~/hadoop
(注意替換)
!!!配置zookeeper、hbase的PATH,
vi /etc/profile(3個虛擬機器一起新增)
新增
exportJAVA_HOME=/home/cc/hadoop/jdk1.8.0_121
exportPATH=$JAVA_HOME/bin:$PATH
exportCLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
exportHADOOP_HOME=/home/cc/hadoop/hadoop-2.6.5/
exportPATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
exportZOOKEEPER_HOME=/home/cc/hadoop/zookeeper-3.4.9/
exportPATH=$ZOOKEEPER_HOME/bin:$PATH
exportHBASE_HOME=/home/cc/hadoop/hbase-1.2.5/
exportPATH=$HBASE_HOME/bin:$PATH
scp -r /etc/profile slave1:/etc/profile
scp -r /etc/profile slave2:/etc/profile
source /etc/profile
重啟
4、啟動叢集,啟動順序hadoop->zookeeper->hbase
1)start-all.sh(啟動hadoop叢集)
2)zkServer.sh start(每臺機器都要執行該命令)然後你可以檢視
zkServer.sh status (會顯示是leader還是follower,(我的是slave1是leader,哪個是leader不要緊的)然後執行)
// zkCli.sh -server master:2181,slave1:2181,slave2:2181(2181是zookeeper的監聽埠)
3)start-hbase.sh (可能要等上一分鐘)
4)jps
出現:
3650 DataNode
3986 ResourceManager
3812 SecondaryNameNode
4421 QuorumPeerMain
4744 Jps
3544 NameNode
4571 HMaster
4700 HRegionServer
4094 NodeManager
5)hbaseshell
出現:(成功!!!)
2017-04-1719:29:25,502 WARN [main]util.NativeCodeLoader: Unable to load native-hadoop library for your platform...using builtin-java classes where applicable
SLF4J:Class path contains multiple SLF4J bindings.
SLF4J:Found binding in[jar:file:/home/cc/hadoop/hbase-1.2.5/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J:Found binding in[jar:file:/home/cc/hadoop/hadoop-2.6.5/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J:See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J:Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
HBaseShell; enter 'help<RETURN>' for list of supported commands.
Type"exit<RETURN>" to leave the HBase Shell
Version1.2.5, rd7b05f79dee10e0ada614765bb354b93d615a157, Wed Mar 1 00:34:48 CST 2017
hbase(main):001:0>
相關推薦
虛擬機器搭建haddoop、zookeeper、hbase叢集
安裝jdk 開啟一個虛擬機器,右鍵單擊桌面選擇Open in Terminal,進入編輯介面: 1.假設使用者名稱是wxx(獲取root許可權) (1)使wxx成為sudoer su cd /etc vi sudoers i
階段總結——用虛擬機器搭建一個高可用負載均衡叢集架構
搭建一個高可用負載均衡叢集架構出來,並執行三個站點,具體需求如下。 ------------------------------------------------------------------------------------------ 基礎: 1 設計你認為合理的架構,用visio把架構圖
hadoop、zookeeper及hbase的啟動關閉
ado bsp nbsp serve star 目錄 per slave -h hadoop 啟動:進入到hadoop目錄,sbin/start-all.sh 關閉:sbin/stop-all.sh zookeeper 啟動:進入到zook
三、Java虛擬機器自動記憶體管理機制、物件建立及記憶體分配
1、物件是如何建立: 步驟: (1)、虛擬機器遇到new <類名>的指令---->根據new的引數是否在常量池中定位一個類的符號引用 (2)、檢測該符號引用代表的類是否已經被載入、解析、和初始化。(如果沒有則
mysql、flume、zookeeper、kafka快速搭建
準備做實時資料計算。 資料來源為mysql的20張表吧。通過flume解析binlog日誌,然後sink到kafka,由sparkstreaming消費,實時處理業務資料生成目標資料寫到我們的mysql中。 一.mysql搭建 0. 檢查是否已安裝並刪除已安裝的包
二、Java虛擬機器自動記憶體管理機制、執行時資料區域深入瞭解
執行時資料區域: (1)、程式計數器 a、定義:是一塊較小的記憶體空間,可以看作是當前執行緒所執行的位元組碼的行號指示器。 b、執行緒私有:因為多執行緒是通過執行緒輪流切換並且分配處理器執行時間的方式來實現的,任何時刻,
一個虛擬機器部署多個tomcat、tomcat啟動慢問題
(一) 、一個虛擬機器內部署連個tomcat 以tomcat8為例: 1、解壓tomcat的tar包到兩個不同的資料夾: /usr/local/tomcat8-1 /usr/local/tomcat8-2 2、配置 /etc/profile 在 /etc/p
VMware14 安裝CentOS7 實現宿主機ping通虛擬機器、虛擬機器ping通宿主機、虛擬機器能上網且能ping通百度
本文旨在通過通過虛擬機器VMware14來安裝CentOS7 系統,並配置固定IP來實現在Windows系統中使用Linux環境。 本文目錄: 0、本機環境 1、VMware14 初始化 1.1、安裝VMware14
VMware Workstation虛擬機器找不到IP、虛擬機器不能正常啟動
之前碰到好多次如題所示的問題,也在網上找了許多教程。最後總結只需一個方法基本全部可以解決。1)右擊我的電腦->管理->服務和應用程式->服務在“服務”裡找到和VMware相關的程序,將VMware NAT Service、VMware DHCP Servic
XenAPI中查詢虛擬機器或主機的CPU、記憶體等一些資訊
因為公司需要做這方面的介面所以自己在網上查了好久才發現方法做了出來,其中遇到了不少的坑寫一下以便以後再次遇到。 1、首先在xenAPI給的一些介面中雖然有關於這方面的介面但是現在的版本不能直接得到,如果直接呼叫VM_guest_metrics中的方法返回的資料是空的。
Java虛擬機器(四)——物件的建立、儲存和定位
物件的建立 Java是一門面向物件的程式語言,Java 程式執行過程中無時無刻都有物件被創建出來,在語言層面上,建立物件(例如克隆,反序列化)通常僅僅是一個new關鍵字而已,例如下面的語句。 Object obj = new Object(); 其實
多臺虛擬機器搭建zookeeper叢集
一、什麼是zookeeper(摘自百度百科) ZooKeeper是一個分散式的,開放原始碼的分散式應用程式協調服務,是Google的Chubby一個開源的實現,是Hadoop和Hbase的重要元件。它是一個為分散式應用提供一致性服務的軟體,提供的功能包括:配置維護、域名服務
Mac 虛擬機器Parallels Desktop安裝win7 、win10系統
mac上非常優秀的虛擬機器 Parallels Desktop 13,那麼如何安裝windows系統呢,今天博主給大家演示一下win7 旗艦版和win 10的安裝過程。mac上非常優秀的虛擬機器 Parallels Desktop 13裡邊內含win7 旗艦版的安裝過程和wi
【Linux】虛擬機器+Ubuntu14.04安裝版本、分割槽筆記
1.虛擬機器與Linux系統版本 VM12+ubuntu14.04.1或ubuntu14.04.2 VM12: 因為付費。需要自己尋找下載安裝 Ubuntu14: 官方下載列表 ubuntu14.04.1官網下載連結 ubuntu14.04.
virtualbox虛擬機器使用筆記-安裝、增強功能、網路、usb裝置、共享目錄
》。 9.設定vbox的usb裝置 這部分主要摘自 http://forum.ubuntu.org.cn/viewtopic.php?f=65&t=164209 照著做就行了 ------------------------------------------* 為virtualbox開啟usb裝置支
在linux上基於KVM虛擬機器搭建lamp
1.準備網路拓撲圖實現基於KVM的虛擬化,需要三臺kvm虛擬機器,分別安裝mysql,php-fpm,httpd,其次,需要在安裝php-fpm上安裝php-mysql,用來使php能夠連線上mysql資料庫,同時需要兩個虛擬網橋,以及一個物理橋用來保證外部與php-fpm伺服器的連線,同時保證mysql伺服
nginx 虛擬機器搭建設定配置檔案
server{ charset utf-8; client_max_body_size 128M; listen 80; server_name demo.com; root /Users/playcrab/www/demo; index index.php index.html; acces
【轉】【Redis】分散式鎖的幾種使用方式(redis、zookeeper、資料庫)
https://blog.csdn.net/u010963948/article/details/79006572?utm_source=blogxgwz9 https://blog.csdn.net/qq_37606901/article/details/79569250?utm_source
虛擬機器環境下使用java訪問hbase進行表操作2
1:建立student表,表結構包含info和course兩個列族 java程式碼: package myhbase; import java.io.IOException; import org.apache.hadoop.conf.Configuration; //匯入hadoop和h
虛擬機器環境下使用java訪問hbase進行表操作3
該篇內容是承接2的: 1. public static void deleTable(String myTableString)throws IOException{ 2. &n