
關於排序演算法的一點知識——例項和虛擬碼
1. 插入排序
將待排序的資料分成兩個區域:有序區和無序區,每次將一個無序區中的資料按其大小插入到有序區中的適當位置,直到所有無序區中的資料都插入完成為止。
設待排序列為:12,8,10,14,6,2,排序過程如下圖:
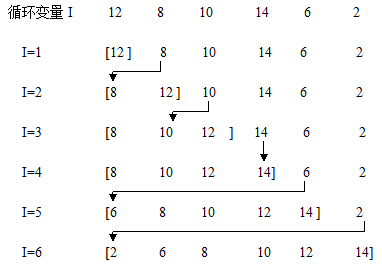
虛擬碼如下:
procedure insertsort(n:integer); var i,j:integer; begin for i:=2 to n do begin a[0]:=a[i]; j:=i-1; while a[j]>a[0] do {決定運算次數和移動次數} begin a[j+1]:=a[j]; j:=j-1; end; a[j+1]:=a[0]; end; end;
演算法分析:
(1)穩定性:穩定
(2)時間複雜度:
①原始資料正序,總比較次數:n-1
②原始資料逆序,總比較次數:
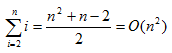
③原始資料無序,第i趟平均比較次數=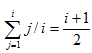
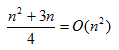
④可見,原始資料越趨向正序,比較次數和移動次數越少。
(3)空間複雜度:僅需一個單元A[O]
2. 氣泡排序
最多進行n-1趟排序,每趟排序時,從底部向上掃描,一旦發現兩個相鄰的元素不符合規則,則交換。我們發現,第一趟排序後,最小值在A[1],第二趟排序後,較小值在
待排序資料:53 33 19 53 3 63 82 20 19 39
第一趟排序:3 53 33 19 53 19 63 82 20 39
第二趟排序:3 19 53 33 19 53 20 63 82 39
第三趟排序:3 19 19 53 33 20 53 39 63 82
第四趟排序:3 19 19 20 53 33 39 53 63 82
第五趟排序:沒有反序資料,排序結束。
注意:也可以從上往下掃描,第一趟後,最大值在A[10],次大的值在A[9]。
虛擬碼:
procedure Bubble(n:integer);;
var temp,i,j:integer;
change:boolean;
begin
for i:=1 to n-1 do
begin
change:=false;
for j:=n-1 downto i do
if a[j]>a[j+1] then
begin
change:=true;
temp:=a[j]; a[j]:=a[j+1]; a[j+1]:=temp;
end;
if not(change) then exit;
end;
end;演算法分析:
(1)穩定性:穩定
(2)時間複雜度:
①原始資料正序,需一趟排序,比較次數n-1=O(n)
②原始資料反序,需n-1趟排序,比較次數
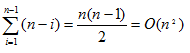
③一般情況下,雖然不一定需要n-1趟排序,但由於每次資料位置的改變需要3次移動操作,因此,總時間複雜度高於直接插入排序。
(3)空間複雜度:僅需一箇中間變數
(4)改進方法:每趟排序時,記住最後一次發生交換的位置,則該位置之前的記錄均已有序。
3. 快速排序
在A[1..n]中任取一個數據元素作為比較的“基準”(不妨記為X),將資料區劃分為左右兩個部分:A[1..i-1]和A[i+1..n],且A[1..i-1]≤X≤A[i+1..n](1≤i≤n),當A[1..i-1]和A[i+1..n]非空時,分別對它們進行上述的劃分過程,直至所有資料元素均已排序為止。
示例如下:待排序資料: 67 67 14 52 29 9 90 54 87 71
X=67 i j
掃描j i j
交換 54 67 14 52 29 9 90 67 87 71
掃描i i j
交換 54 67 14 52 29 9 67 90 87 71
j=i,結束 ij
第一趟排序後:54 67 14 52 29 9 [67] 90 87 71
第二趟排序後: 9 29 14 52 [54] 67 [67] 71 87 [90]
第三趟排序後:[9] 29 14 52 [54 67 67 71] 87 [90]
第四趟排序後:[9] 14 [29] 52 [54 67 67 71 87 90]
第五趟排序後:[9 14 29 52 54 67 67 71 87 90]
虛擬碼:
procedure quicksort(low,high:integer);
var temp,x,i,j:integer;
begin
if low<high then
begin
x:=a[low]; i:=low; j:=high;
while i<j do
begin
while (j>i) and (a[j]>=x) do j:=j-1; {j左移}
temp:=a[i]; a[i]:=a[j]; a[j]:=temp;
i:=i-1;
while (j>i) and (a[i]<=x) do i:=i+1; {i右移}
temp:=a[i]; a[i]:=a[j]; a[j]:=temp;
j:=j-1;
end;
quicksort(low,i-1);
quicksort(i+1,high);
end;
end;演算法分析:
(1)穩定性:不穩定
(2)時間複雜度:每趟排序所需的比較次數為待排序區間的長度-1,排序趟數越多,佔用時間越多。
①最壞情況:每次劃分選取的基準恰好都是當前序列中的最小(或最大)值,劃分的結果A[low..i-1]為空區間 或A[i+1..high]是空區間,且非空區間長度達到最大值。這種情況下,必須進行n-1趟快速排序,第i次趟區間長度為n-i+1,總的比較次數達到最大值:n(n-1)/2=O(n2)
②最好情況:每次劃分所取的基準都是當前序列中的“中值”,劃分後的兩個新區間長度大致相等。共需lgn趟快速排序,總的關鍵字比較次數:O(nlgn)
③基準的選擇決定了演算法效能。經常採用選取low和high之間一個隨機位置作為基準的方式改善效能。
(3)空間複雜度:快速排序在系統內部需要一個棧來實現遞迴,最壞情況下為O(n),最佳情況下為O(lgn)。
4.希爾排序
任取一個小於n的整數S1作為增量,把所有元素分成S1個組。所有間距為S1的元素放在同一個組中。
第一組:{A[1],A[S1+1],A[2*S1+1],……}
第二組:{A[2],A[S1+2],A[2*S1+2],……}
第三組:{A[3],A[S1+3],A[2*S1+3],……}
……
第s1組:{A[S1],A[2*S1],A[3*S1],……}
先在各組內進行直接插人排序;然後,取第二個增量S2(<S1)重複上述的分組和排序,直至所取的增量St=1(St<St-1<St-2<…<S2<S1),即所有記錄放在同一組中進行直接插入排序為止。
示例:
虛擬碼:
procedure shell(n:integer);
var s,k,i,j:integer;
begin
s:=n;
repeat
s:=round(s/2); {設定增量S遞減}
for k:=1 to s do {對S組資料分別排序}
begin
i:=k+s; {第二個待排序資料}
while i<=n do {當i>n時,本組資料排序結束}
begin
a[0]:=a[i];
j:=i-s; {約定步長為S}
while (a[j]>a[0]) and (j>=k) do
begin
a[j+s]:=a[j];
j:=j-s;
end;
a[j+s]:=a[0];
i:=i+s;
end;
end;
until s=1;
end; 演算法分析
(1)穩定性:不穩定
(2)時間複雜度:
① Shell排序的執行時間依賴於增量序列。如例項所示,選擇增量系列為5-2-1的比較次數。
② 在直接插入排序中,資料越趨向於有序,比較和移動次數越少,Shell排序的目的則是增加這種有序趨勢。雖然看起來重複次數較多,需要多次選擇增量,但開始時,增量較大,分組較多,但由於各組的資料個數少,則比較次數累計值也小,當增量趨向1時,組內資料增多,而所有資料已經基本接近有序狀態,因此,Shell的時間效能優於直接插入排序。
(3)空間複雜度:僅需一個單元A[O]
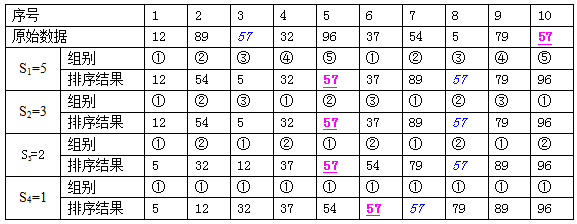
5. 直接選擇排序
選擇排序的基本思想是:每一趟從待排序的資料中選出最小元素,順序放在已排好序的資料最後,直到全部資料排序完畢。
示例如下圖:
虛擬碼:
procedure select(n:integer);
var temp,k,i,j:integer;
begin
for i:=1 to n-1 do
begin
k:=i;
for j:=i+1 to n do
if a[j]<a[k] then k:=j;
if k<>i then
begin
a[0]:=a[i]; a[i]:=a[k]; a[k]:=a[0];
end;
end;
end; 演算法分析
(1)穩定性:不穩定
(2)時間複雜度:O(n2)
(3)空間複雜度:僅需一箇中間單元A[0]
6. 堆排序
堆排序是一種樹形選擇排序,在排序過程中,將A[1..n]看成是完全二叉樹的順序儲存結構,利用完全二叉樹中雙親結點和孩子結點之間的內在關係來選擇最小的元素。根據堆中根節點的關鍵字大小,分為大根堆和小根堆。
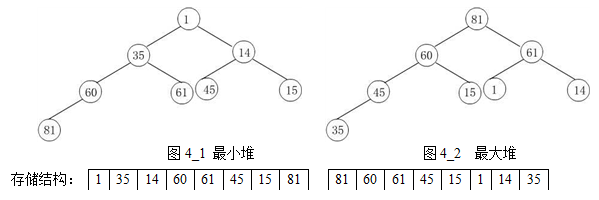
主要是有個步驟:(1)調整堆;(2)選擇、交換、調整。
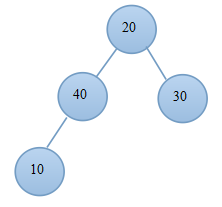
例子:

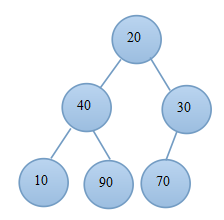
(1.1) 原始陣列 (1.2)原始堆
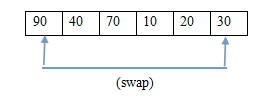
(2.1)交換 (2.2)調整後的堆
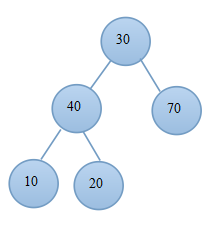
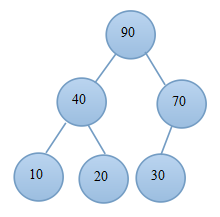
(3.1)交換後 (3.2)當前堆
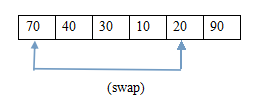
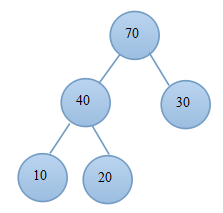
(4.1)交換 (4.2)調整後的堆
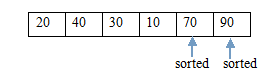
(5.1)交換後 (5.2)當前堆
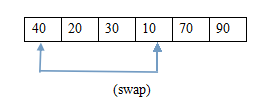
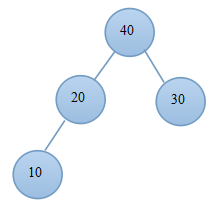
(6.1)交換 (6.2)調整後的堆
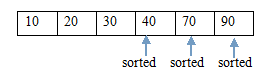
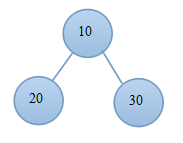
(7.1)交換後 (7.2)當前堆
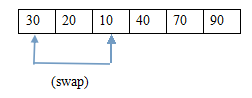

(8.1)交換 (8.2)調整後的堆
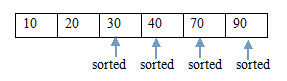
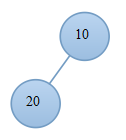
(9.1)交換後 (9.2)當前堆

(10.1)交換 (10.2)調整後的堆
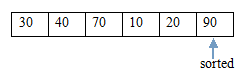
(11.1)交換後,得到結果
虛擬碼:
procedure editheap(i:integer; s:integer); {堆的調整}
var j:integer;
begin
if 2*i<=s then {如果該結點為葉子,則不再繼續調整}
begin
a[0]:=a[i]; j:=i;
if a[2*i]>a[0] then begin a[0]:=a[2*i]; j:=2*i; end;
if (2*i+1<=s) and (a[2*i+1]>a[0]) then
begin a[0]:=a[2*i+1]; j:=2*i+1; end; {獲取最大值}
if j<>i then
begin
a[j]:=a[i]; a[i]:=a[0]; {更新子樹結點}
editheap(j,s); {調整左右孩子}
end;
end;
end; procedure buildheap; {堆的建立}
var i,j:integer;
begin
for i:=n div 2 downto 1 do {從後往前,依次調整}
begin
a[0]:=a[i]; j:=i;
if a[2*i]>a[0] then begin a[0]:=a[2*i]; j:=2*i; end;
if (2*i+1<=n) and (a[2*i+1]>a[0]) then
begin a[0]:=a[2*i+1]; j:=2*i+1; end;
if j<>i then
begin
a[j]:=a[i]; a[i]:=a[0];
editheap(j,n);
end;
end;
end; procedure heapsort(n:integer); {堆排序}
var k,i,j:integer;
begin
buildheap;
for i:=n downto 2 do
begin
a[0]:=a[i]; a[i]:=a[1]; a[1]:=a[0];
editheap(1,i-1);
end;
end;演算法分析:
(1)穩定性:不穩定。
(2)時間複雜度:堆排序的時間,主要由建立初始堆和反覆調整堆這兩部分的時間開銷構成,它們均是通過呼叫editheap函式實現的。堆排序的最壞時間複雜度為O(nlgn)。堆排序的平均效能較接近於最壞效能。由於建初始堆所需的比較次數較多,所以堆排序不適宜於記錄數較少的檔案。
(3)空間複雜度:O(1)
7. 歸併排序
歸併是指將若干個已排序的子檔案合併成一個有序的檔案。這裡只講二路歸併,即兩兩合併。
設有兩個有序(升序)序列儲存在同一陣列中相鄰的位置上,不妨設為A[l..m],A[m+1..h],將它們歸併為一個有序數列,並存儲在A[l..h]。為了減少資料移動次數,不妨採用一個臨時工作陣列C,將中間排序結果暫時儲存在C陣列中,等歸併結束後,再將C陣列值複製給A。
第1趟歸併排序時,將數列A[1..n]看作是n個長度為1的有序序列,將這些序列兩兩歸併,若n為偶數,則得到[n/2]個長度為2的有序序列;若n為奇數,則最後一個子序列不參與歸併。第2趟歸併則是將第1趟歸併所得到的有序序列兩兩歸併。如此反覆,直到最後得到一個長度為n的有序檔案為止。
虛擬碼:
procedure merge(l,m,h:integer);
var p1,p2,p3,j:integer;
begin
if m<n then
begin
if h>n then h:=n;
p1:=l; p2:=m+1;
p3:=l;
while (p1<=m) and (p2<=h) do
begin
if a[p1]<=a[p2] then
begin
c[p3]:=a[p1]; p1:=p1+1;
end
else begin
c[p3]:=a[p2]; p2:=p2+1;
end;
p3:=p3+1;
end;
if p1>m then
for j:=p2 to h do begin c[p3]:=a[j]; p3:=p3+1;
end;
if p2>h then
for j:=p1 to m do begin c[p3]:=a[j]; p3:=p3+1;
end;
for j:=l to h do a[j]:=c[j];
end;
end;procedure mergesort;
var i,s,k:integer;
begin
s:=1;
while s<n do</span>
begin
i:=1;
repeat
merge(s*(i-1)+1,s*i,s*(i+1));
i:=i+2;
until i>n;
s:=s*2;
end;
end;演算法分析:
(1)穩定性:穩定。
(2)儲存結構要求:用順序儲存結構,也易於在連結串列上實現。
(3)時間複雜度:長度為n的數列,需進行[log2n]趟二路歸併,每趟歸併的時間為O(n),故其時間複雜度無論是在最好情況下還是在最壞情況下均是O(nlog2n)。
(4)空間複雜度:需要一個輔助陣列來暫存兩有序序列歸併的結果,故其輔助空間複雜度為O(n)。