
mysql索引一(普通索引)
mysql的索引分為兩大類,聚簇索引、非聚簇索引。聚簇索引是按照資料存放的物理位置為順序的,而非聚簇索引則不同。聚簇索引能夠提高多行檢索的速度、非聚簇索引則對單行檢索的速度很快。
在這兩大類的索引型別下,還可以降索引分為4個小型別:
1,普通索引:最基本的索引,沒有任何限制,是我們經常使用到的索引。
2,唯一索引:與普通索引類似,不同的是,唯一索引的列值必須唯一,但允許為空值。
主鍵索引是特殊的唯一索引,不允許有空值。
3,全文索引:全文索引(FULLTEXT)僅可以適用於MyISAM引擎的資料表,作用於CHAR,VARCHAR、TEXT資料型別的列。
4、組合索引:將幾個列作為一條索引進行檢索,使用最左匹配原則。
下面對以上的幾種索引型別進行實踐:
1,首先建立一個student表,向其中加入了20000條資料。SQL如下:
DROP TABLE IF EXISTS `student`; CREATE TABLE `student` ( `s_id` int(11) NOT NULL AUTO_INCREMENT, `s_name` varchar(100) DEFAULT NULL, `s_age` int(11) DEFAULT NULL, `s_phone` varchar(30) DEFAULT NULL, PRIMARY KEY (`s_id`) ) ENGINE=InnoDB, CHARSET=utf8;
向裡面加入資料的簡單程式碼如下:其中id,name,phone是不重複的,年齡分為10,20,30歲。
package com.crscic.mysql; import java.sql.Connection; import java.sql.DriverManager; import java.sql.SQLException; import java.util.Date; import com.mysql.jdbc.PreparedStatement; public class InsertTest { public static void main(String[] args) throws ClassNotFoundException, SQLException { final String url = "jdbc:mysql://127.0.0.1/test"; final String name = "com.mysql.jdbc.Driver"; final String user = "root"; final String password = "crscic"; Connection conn = null; Class.forName(name);//指定連線型別 conn = DriverManager.getConnection(url, user, password);//獲取連線 if (conn!=null) { System.out.println("獲取連線成功"); insert(conn); }else { System.out.println("獲取連線失敗"); } } public static void insert(Connection conn) { // 開始時間 Long begin = new Date().getTime(); PreparedStatement pst = null; // sql字首 String prefix = "INSERT INTO student (s_id,s_name,s_age,s_phone) VALUES "; try { // 儲存sql字尾 StringBuffer suffix = new StringBuffer(); // 設定事務為非自動提交 conn.setAutoCommit(false); // 比起st,pst會更好些 pst = (PreparedStatement) conn.prepareStatement("");//準備執行語句 // 外層迴圈,總提交事務次數 suffix = new StringBuffer(); // 第j次提交步長 for (int j = 1; j <= 20000; j++) { // 構建SQL字尾 if(j<=1000){ suffix.append("(" + j+","+"'name"+ j +"',10,'"+j+"'),"); }else if(10000<j || j<20000){ suffix.append("(" + j+","+"'name"+ j +"',20,'"+j+"'),"); }else{ suffix.append("(" + j+","+"'name"+ j +"',30,'"+j+"'),"); } } // 構建完整SQL String sql = prefix + suffix.substring(0, suffix.length() - 1); // 新增執行SQL pst.addBatch(sql); // 執行操作 pst.executeBatch(); // 提交事務 conn.commit(); // 清空上一次新增的資料 suffix = new StringBuffer(); } catch (SQLException e) { e.printStackTrace(); }finally{ try { pst.close(); conn.close(); } catch (SQLException e) { e.printStackTrace(); } } // 結束時間 Long end = new Date().getTime(); // 耗時 System.out.println("20000條資料插入花費時間 : " + (end - begin) / 1000 + " s"); System.out.println("插入完成"); } }
先看看不使用普通索引的情況下的查詢情況。
select * from student where s_name='name10000'
可以看到查詢時間是0.013s。
使用explain看一下具體的查詢情況:

分析其中的關鍵資訊:
1,select_type:SIMPLE,表示這是一次簡單的查詢,沒有join,union,沒有中間表
2,type:ALL,表示這次查詢進行了全表查詢
3,key,mysql使用的索引名,null表示此次SQL查詢mysql並沒有使用索引
4,rows,這個最關鍵,表示這個SQL查詢了20179條記錄
接下來,給s_name這一列加上普通索引
alter table student add index s_name(s_name)
可以看到,加了索引之後,查詢時間幾乎為0,速度非常快。
再使用explain檢視一下,如圖:

從分析結果上來看,由於此次SQL對列s_name使用了索引,因此rows只查了1條記錄,大大提升了查詢效率。
什麼情況下建立索引合適?
把索引建立在有大量重複資料的欄位上,並不能有效地提升SQL效率,比如我的s_age的取值為10,20,30,此時對s_age做查詢,未加索引的時候:
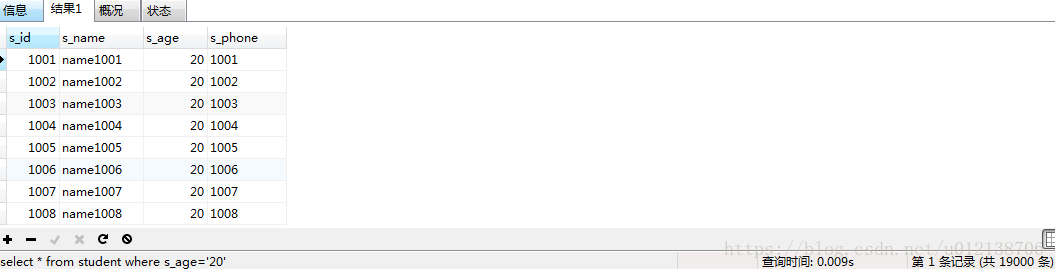
查詢時間是0.009s。下面通過explain看看:

可以看到是查詢了20635條記錄。
下面給s_age加上索引,再次進行查詢:
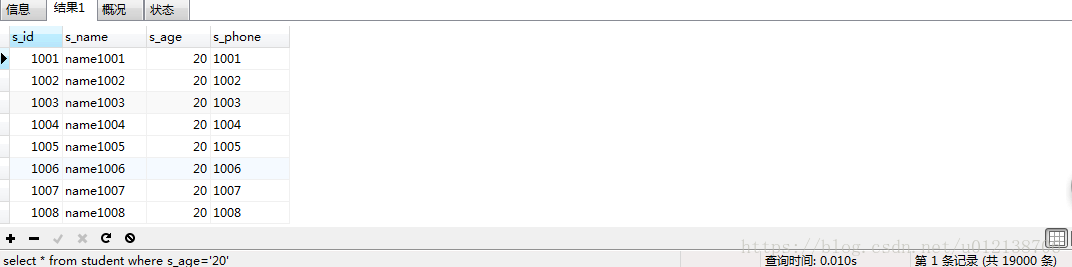
時間反而變為了0.010s,沒有提升查詢效率,反而降低了。通過explain看看具體情況:

發現這次查詢,查詢了9672條記錄。
可能資料比較少,結果對比不是很明顯。在測試期間,在刪除和增加幾次s_age索引的幾次測試中,rows數值不一樣。而且每次刪除之後,第一次查詢,時間都比較長,然後再次直行查詢語句,時間降了很多。留待以後再觀察吧。

這是刪除了s_age索引之後又用explain觀察的的查詢。
下面再增加s_age索引,然後進行觀察:

這裡的rows變成了9719。
需要注意的是:在索引列上使用函式,會使索引失效。
索引和like。
就下面這兩種情況下,沒有用到索引。
explain select * from student where s_name like "%name1001%";
explain select * from student where s_name like "%name1001";結果如圖:

但是萬用字元在結尾的時候,是可以用到索引的。
explain select * from student where s_name like "name1001%";就不上圖了。也就是說,要對索引列使用like,萬用字元只能在結尾,開頭不可以有任何的萬用字元。
本文介紹了普通索引,寫起來才發現問題有那麼多,而且看起來,這還不是全部,其餘的索引型別必須要重新開一篇了。