
NLTK學習之一:簡單文字分析
nltk的全稱是natural language toolkit,是一套基於python的自然語言處理工具集。
1 NLTK的安裝
nltk的安裝十分便捷,只需要pip就可以。
pip install nltk在nltk中集成了語料與模型等的包管理器,通過在python直譯器中執行
>>> import nltk
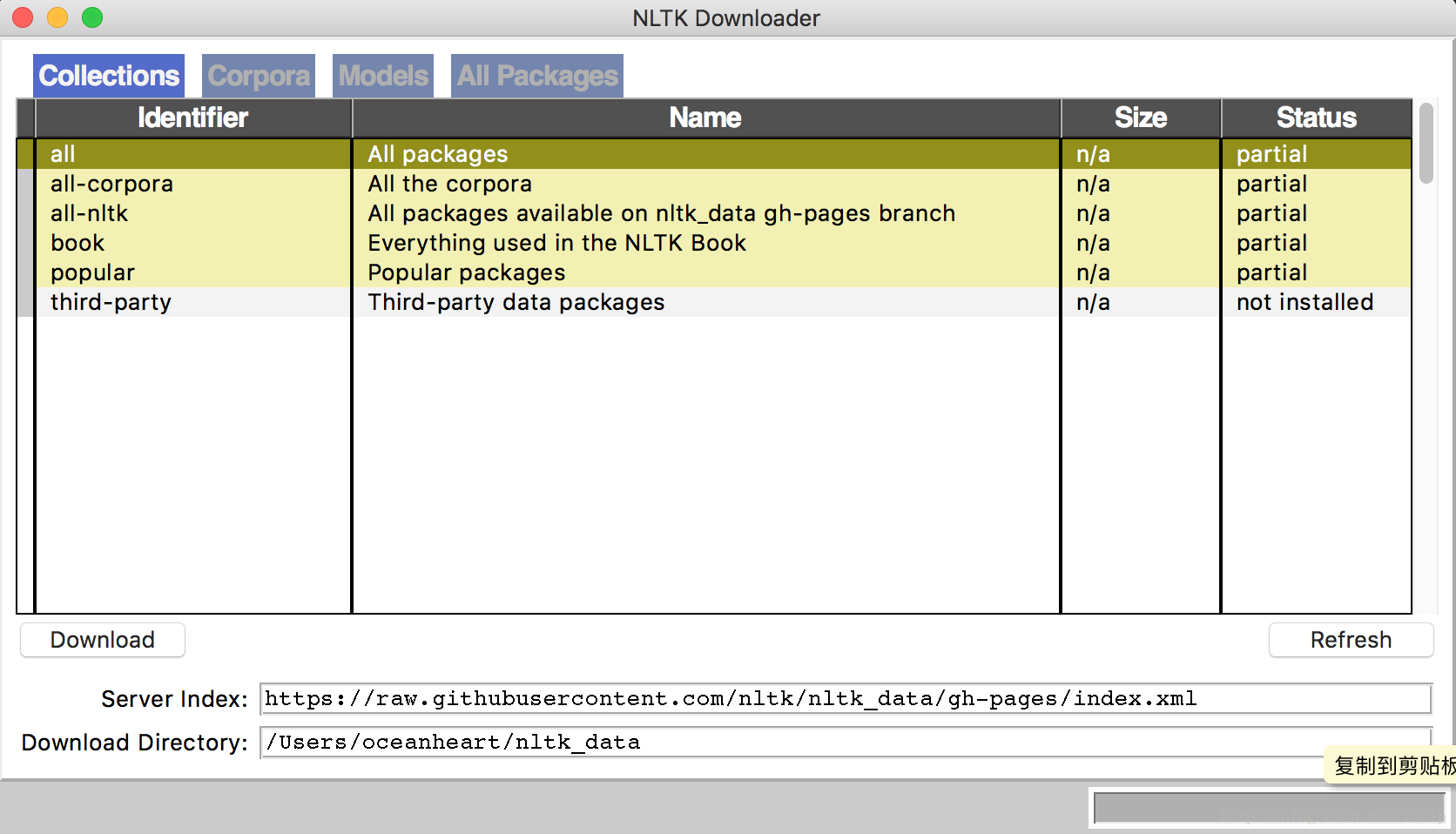
>>> nltk.download()便會彈出下面的包管理介面,在管理器中可以下載語料,預訓練的模型等。
2 對文字進行簡單的分析
2.1 Text類介紹
nltk.text.Text()類用於對文字進行初級的統計與分析,它接受一個詞的列表作為引數。Text類提供了下列方法。
| 方法 | 作用 |
|---|---|
| Text(words) | 物件構造 |
| concordance(word, width=79, lines=25) | 顯示word出現的上下文 |
| common_contexts(words) | 顯示words出現的相同模式 |
| similar(word) | 顯示word的相似詞 |
| collocations(num=20, window_size=2) | 顯示最常見的二詞搭配 |
| count(word) | word出現的詞數 |
| dispersion_plot(words) | 繪製words中文件中出現的位置圖 |
| vocab() | 返回文章去重的詞典 |
nltk.text.TextCollection類是Text的集合,提供下列方法
| 方法 | 作用 |
|---|---|
| nltk.text.TextCollection([text1,text2,]) | 物件構造 |
| idf(term) | 計算詞term在語料庫中的逆文件頻率,即 |
| tf(term,text) | 統計term在text中的詞頻 |
| tf_idf(term,text) | 計算term在句子中的tf_idf,即tf*idf |
2.2 示例
下面我們對青春愛情小說《被遺忘的時光》做下簡單的分析。首先載入文字:
import ntlk
import jieba
raw=open('forgotten_times.txt').read()
text=nltk.text.Text(jieba.lcut(raw))對於言情小說,先看下風花雪月這樣的詞出現的情況
print text.concordance(u'風花雪月')輸出如下:
>>> Displaying 2 of 2 matches:
彼時 校園 民謠 不復 大熱 了 , 但 處身 校園 , 喜歡 吟唱 風花雪月 的 感性 青年 還是 喜歡 藉此 抒懷 。 邵伊敏 平常 聽 英語歌 較
的 眼睛 看 的 是 自己 , 迷戀 的 卻 多半 只是 少女 心中 的 風花雪月 , 而 迷戀 過後 不可避免 不是 失望 就是 幻滅 。 他 將 目光再看下作者對於某些同義詞的使用習慣
print text.common_contexts([u'一起',u'一同'])輸出如下:
>>> 爺爺奶奶_生活 在_時下面看下文章常用的二詞搭配
text.collocations()輸出
出入境 管理處; 沃爾沃 XC90; 慢吞吞 爬起來; 沒交過 男朋友; 邵伊敏 回頭一看; 戴維凡 哭笑不得; 沒想到 邵伊敏; 邵伊敏 第二天; 邵伊敏 沒想到檢視關心的詞在文中出現的位置
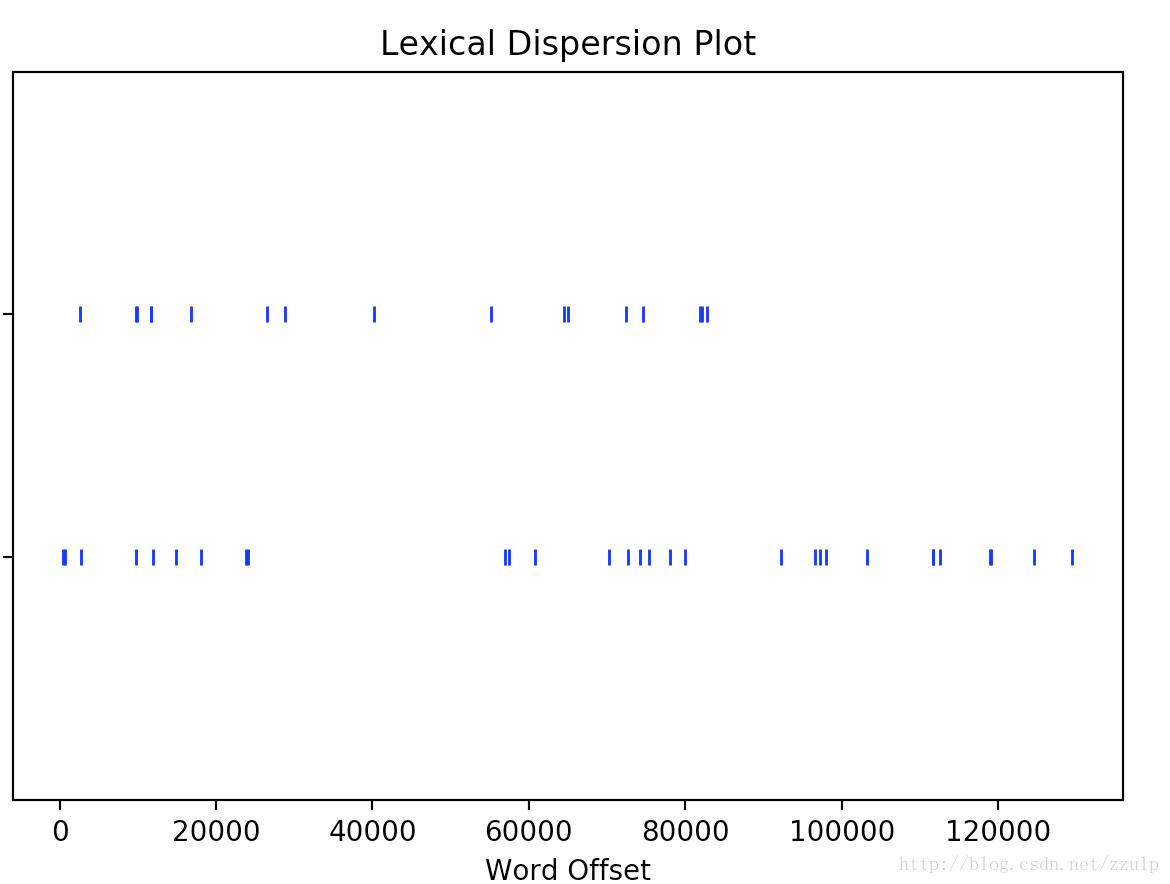
text.dispersion_plot([u'校園',u'大學'])輸出如下圖:
3 對文件用詞進行分佈統計
3.1 FreqDist類介紹
這個類主要記錄了每個詞出現的次數,根據統計資料生成表格,或繪圖。其結構很簡單,用一個有序詞典進行實現。所以dict型別的方法在此類也是適用的。如keys()等。
| 方法 | 作用 |
|---|---|
| B() | 返回詞典的長度 |
| plot(title,cumulative=False) | 繪製頻率分佈圖,若cumu為True,則是累積頻率分佈圖 |
| tabulate() | 生成頻率分佈的表格形式 |
| most_common() | 返回出現次數最頻繁的詞與頻度 |
| hapaxes() | 返回只出現過一次的詞 |
3.2 示例
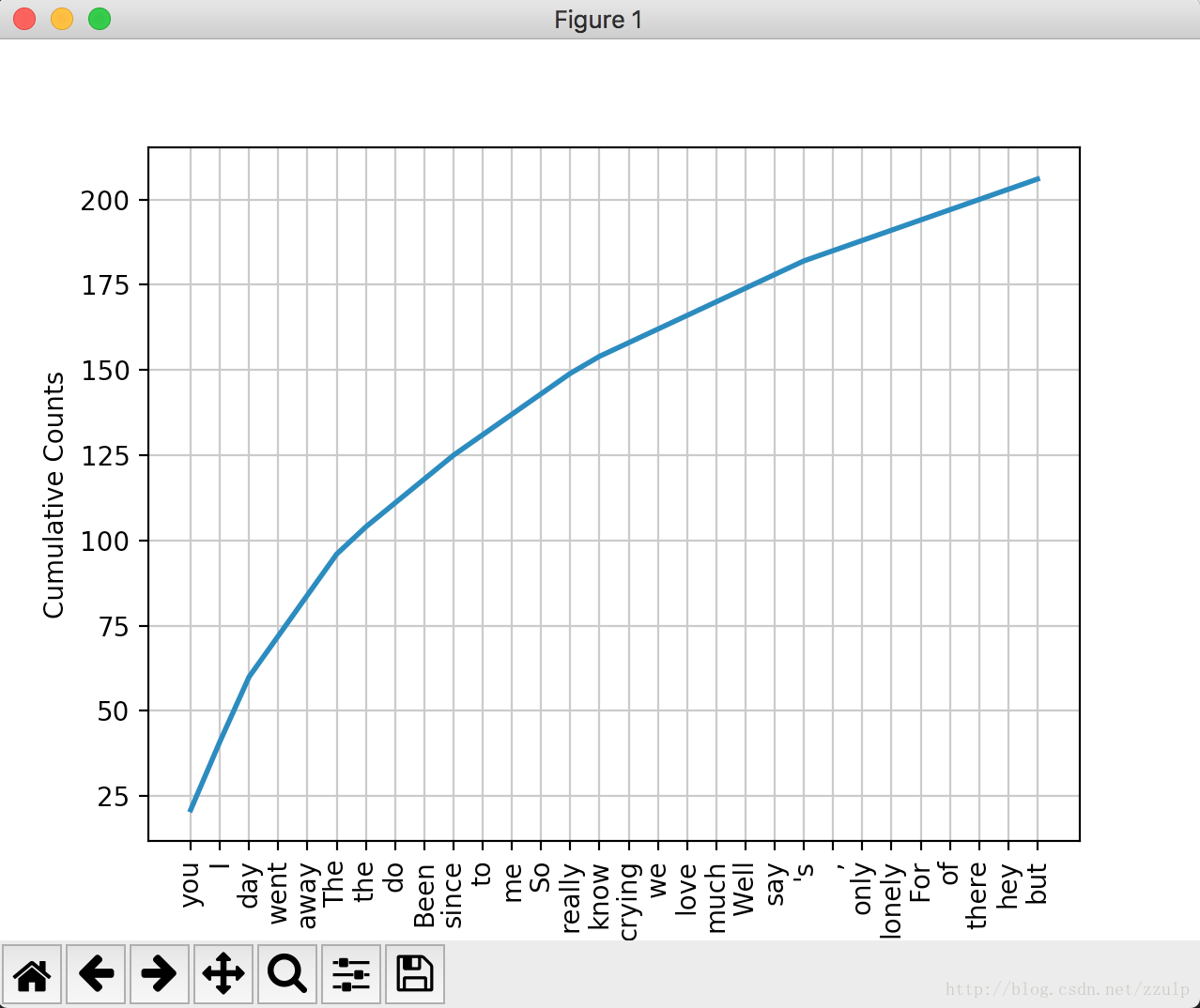
對歌曲《The day you went away》的歌詞進行分析。
text = open('corpus/the_day_you_went_away.txt').read()
fdist = nltk.FreqDist(nltk.word_tokenize(text))
fdist.plot(30,cumulative=True)程式碼第二行呼叫了word_tokenize()函式,此函式的作用是基於空格/標點等對文字進行分詞,返回分詞後的列表。如果要處理中文,需要三方的分詞器先處理,之後才能使用nltk進行處理。執行輸出分佈圖如下:
4 nltk自帶的語料庫
在nltk.corpus包下,提供了幾類標註好的語料庫。見下表:
| 語料庫 | 說明 |
|---|---|
| gutenberg | 一個有若干萬部的小說語料庫,多是古典作品 |
| webtext | 收集的網路廣告等內容 |
| nps_chat | 有上萬條聊天訊息語料庫,即時聊天訊息為主 |
| brown | 一個百萬詞級的英語語料庫,按文體進行分類 |
| reuters | 路透社語料庫,上萬篇新聞方檔,約有1百萬字,分90個主題,並分為訓練集和測試集兩組 |
| inaugural | 演講語料庫,幾十個文字,都是總統演說 |
更多語料庫,可以用nltk.download()在下載管理器中檢視corpus。
4.1語料庫處理
| 方法明 | 說明 |
|---|---|
| fileids() | 返回語料庫中檔名列表 |
| fileids[categories] | 返回指定類別的檔名列表 |
| raw(fid=[c1,c2]) | 返回指定檔名的文字字串 |
| raw(catergories=[]) | 返回指定分類的原始文字 |
| sents(fid=[c1,c2]) | 返回指定檔名的語句列表 |
| sents(catergories=[c1,c2]) | 按分類返回語句列表 |
| words(filename) | 返回指定檔名的單詞列表 |
| words(catogories=[]) | 返回指定分類的單詞列表 |
5 文字預處理
NLP在獲取語料之後,通常要進行文字預處理。英文的預處理包括:分詞,去停詞,提取詞幹等步驟。中文的分詞相對於英文更復雜一些,也需要去停詞。但沒有提取詞幹的需要。
對於英文去停詞的支援,在corpus下包含了一個stopword的停詞庫。
對於提取詞詞幹,提供了Porter和Lancaster兩個stemer。另個還提供了一個WordNetLemmatizer做詞形歸併。Stem通常基於語法規則使用正則表示式來實現,處理的範圍廣,但過於死板。而Lemmatizer實現採用基於詞典的方式來解決,因而更慢一些,處理的範圍和詞典的大小有關。
porter = nltk.PorterStemmer()
porter.stem('lying') #'lie'
lema=nltk.WordNetLemmatizer()
lema.lemmatize('women') #'woman'