
Java 爬蟲入門(網易雲音樂和知乎例項)
最近公司趕專案,過上了996的生活,週日還要陪老婆,實在沒時間靜下來寫點東西,於是導致了swift編寫2048的第三篇遲遲沒有開工,在此說聲抱歉,儘量抽時間在這週末補出來。
首先來介紹下爬蟲的作用,爬蟲主要用於大批量抓取網站中我們所需資料,其實就是模擬出http請求,之後解析分析所得的資料獲取我們需要的資訊的這麼一個過程。
由於網上已經有很多現成的爬蟲框架了,這裡就不重複造輪子了,先給大家說一下原理,大家可以自己嘗試寫一個,至於具體實現這篇只帶來一個框架的使用例項,讓大家可以根據例子快速寫出所需的爬蟲。
爬蟲的關鍵在於分析我們所需要的資料,分析的越透徹,就可以寫出效率越高的爬蟲,比如我們需要爬出網易雲音樂中播放量超過七百萬的歌單
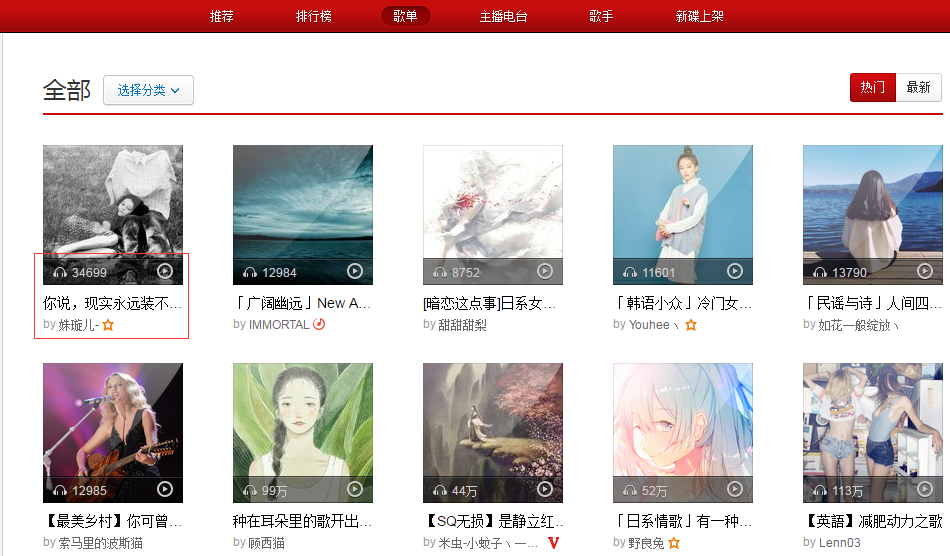
我們所需元素為:歌單名稱、歌單鏈接、歌單播放量,可以看到頁面中這幾個元素都是有的,那麼接下來我們就可以直接通過HttpClient的get方法抓取這個頁面,url:http://music.163.com/discover/playlist,抓取之後分析兩點:
- 每一個歌單區域,每個歌單區域都是一個
- 標籤,我們取出
- 標籤中的播放量,判斷是否大於七百萬,大於則放入我們的結果集中。
- 下面的翻頁按鈕區域,抓取翻頁按鈕區域裡的url,加入我們的任務佇列中,我們的執行緒會持續從佇列中獲取url來進行抓取並分析,並執行步驟1
分析過程做完了,接下來我們來看下技術實現,這裡就不具體寫程式碼了,因為前面說過本篇不重複造輪子,只會介紹一個用現有框架做的例項,放在後面,這裡先介紹下實現方式,大家可以自己嘗試下。
- 首先我們需要一個任務佇列,佇列中存放需要處理的url
- 建立一個執行緒池,從任務佇列中獲取url並進行分析,如果佇列為空就等待
- 執行緒池取到url後模擬請求(HttpClient、jodd的HttpRequest等均可,看自己選擇),獲取返回資料
- 對返回資料進行正則匹配,匹配到需繼續分析的url則將其放入佇列中,並執行喚醒執行緒操作
- 匹配到我們所需資料則加入結果集,可寫檔案可存庫也可直接輸出,看自己需要。
這樣就大概完成了一個爬蟲的核心部分,這裡需要注意的一點是第四步需做一定的去重工作,可以減少總請求的數量,提高效率。
接下來看一個具體框架的例項,這裡使用的是國內的黃億華先生共享的webmagic框架,其主頁地址為:
接下來來看一個具體例項,這裡我要抓取知乎旅行話題下關注量超過3萬,且內容中包含5次以上“吃”字的。那麼首先我們開啟旅行頁:
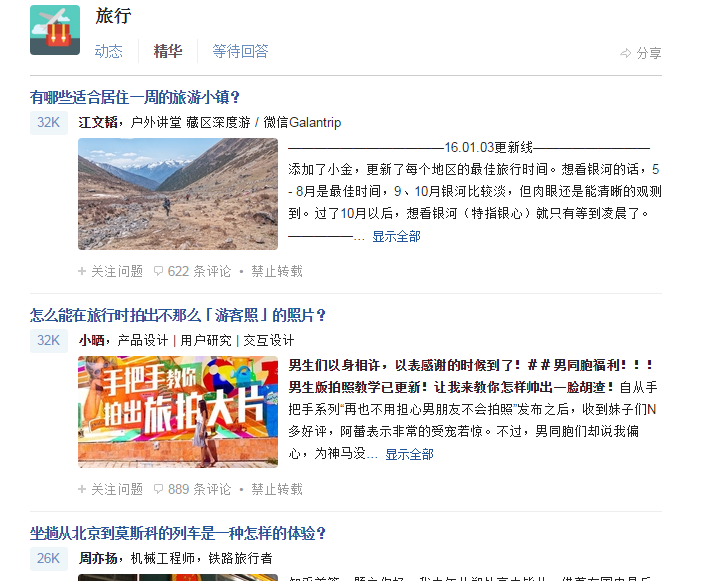
可以看到,本頁有很多的問題,但是沒有問題的關注數,那麼我們點開一個問題看下問題頁:
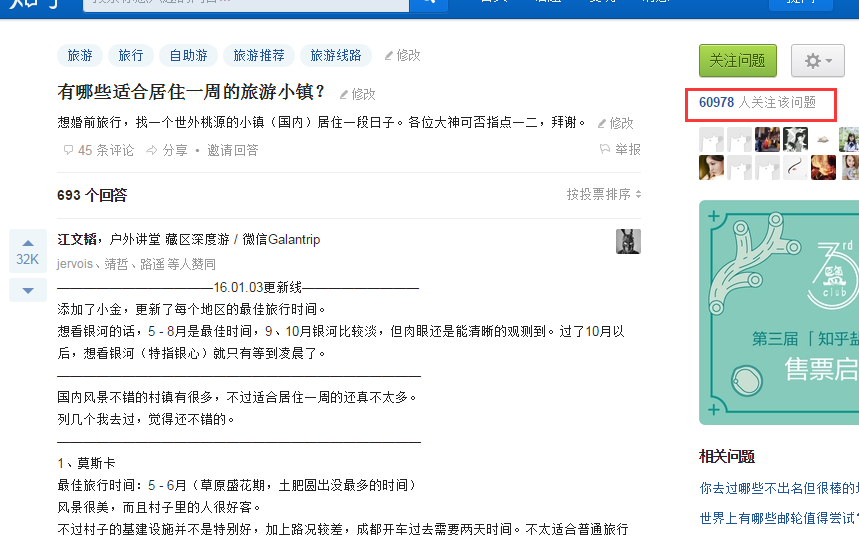
可以看到,右邊紅框中有我們需要的關注數這個資訊,chrome下F12檢視網頁原始碼,分析出裡面的dom結構,可以得到如下思路:
接下來看具體每一步的實現:
一:新建maven工程,新增maven依賴
這一步不多介紹,這裡貼出pom.xml中的配置。當然如果你不使用maven,可以到http://webmagic.io/ 中下載現有的jar包。
<dependencies>
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-core</artifactId>
<version>0.5.3</version>
</dependency>
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-extension</artifactId>
<version>0.5.3</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.21</version>
</dependency>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>19.0</version>
</dependency>
</dependencies>其中的webmagic-core和webmagic-extension就是黃億華先生共享的webmagic框架,下面倆依賴是webmagic框架中需要依賴的外部依賴包,當然如果是自己下的jar包,後面兩個jar包也要加到自己的工程目錄中
二:編寫具體實現
由於這裡用的現有框架,所以實現程式碼很簡單,就一個類:
package org.white.spider;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
* <p>知乎爬蟲</p>
* @author mr. white
* @version v 0.1 ZhihuTravelProcessor.java
* @Date 2016/4/19 20:55
*/
public class ZhihuTravelProcessor implements PageProcessor {
private static final String FOCUS_BEGIN_STR = "</button> ";
private static final String FOCUS_END_STR = " 人關注該問題";
private Site site = Site.me().setCycleRetryTimes(5).setRetryTimes(5)
.setSleepTime(500).setTimeOut(3 * 60 * 1000)
.setUserAgent("Mozilla/5.0 (Windows NT 6.1; WOW64; rv:38.0) Gecko/20100101 Firefox/38.0")
.addHeader("Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8")
.addHeader("Accept-Language", "zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3").setCharset("UTF-8");
private static Map<String, String> eatMap = new HashMap<String, String>();
public void process(Page page) {
page.addTargetRequests(
page.getHtml().links().regex("(https://www.zhihu.com/topic/19551556/top-answers\\?page=\\d+)").all());
page.addTargetRequests(page.getHtml().links().regex("(https://www.zhihu.com/question/\\d+)").all());
if (page.getUrl().regex("(https://www.zhihu.com/question/\\d+)").match()) {
List<String> playCountList = page.getHtml()
.xpath("//div[@class='zm-side-section-inner zg-gray-normal']/html()").all();
if (playCountList.size() == 1) {
String focusStr = playCountList.get(0);
long focus = Long.parseLong(focusStr.substring(
focusStr.indexOf(FOCUS_BEGIN_STR) + FOCUS_BEGIN_STR.length(), focusStr.indexOf(FOCUS_END_STR)));
if (focus > 30000) {
List<String> eatList = page.getHtml()
.xpath("//div[@class='zm-item-rich-text js-collapse-body']/html()").regex("吃").all();
List<String> titleList = page.getHtml().xpath("//title/html()").all();
if (eatList.size() > 5) {
eatMap.put(page.getUrl().toString(), titleList.get(0));
}
}
}
}
}
public static void main(String[] args) {
Spider.create(new ZhihuTravelProcessor()).addUrl("https://www.zhihu.com/topic/19551556/top-answers").thread(5)
.run();
System.out.println("====================================total===================================");
for (String s : eatMap.keySet()) {
System.out.println("title:" + eatMap.get(s));
System.out.println("href:" + s);
}
}
public Site getSite() {
return site;
}
}
上述就是具體實現,都很簡單,這裡就不具體解釋了,大家可以自己寫了跑一下看看,其中關於webmagic的東西可以參考文件:http://webmagic.io/docs/zh/ 裡面寫的很詳細。
今天就到這裡了,大家有什麼問題歡迎提出。
我的部落格:blog.scarlettbai.com
我的公眾號:讀書健身程式設計
