
fasttext原理複習與程式碼實現
阿新 • • 發佈:2019-02-01
一:fasttext原理
fastText簡而言之,就是把文件中所有詞通過lookup table變成向量,取平均後直接用線性分類器得到分類結果。fastText和ACL-15上的deep averaging network [1] (DAN,如下圖)非常相似,區別就是去掉了中間的隱層。兩篇文章的結論也比較類似,也是指出對一些簡單的分類任務,沒有必要使用太複雜的網路結構就可以取得差不多的結果。


有兩個tricks,文章使用了Hierarchical softmax(分層softmax)和n-gram features
1:Hierarchical softmax


就是類別較多時,通過構建一個Huffman編碼樹來加速softmax layer的計算,和之前word2vec中的trick是相同的
並且時間複雜度為O(hlog2(k));
2: N-gram features

只用unigram的話會丟掉word order資訊,所以通過加入N-gram features進行補充,用hashing來減少N-gram的儲存。

二:fasttext程式碼實現例子
1:詞向量模型學習
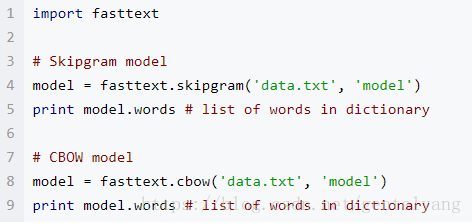
文字分類
classifier=fasttext.supervised('data.train.txt','model')
data.train.txt是一個含有訓練句子,每行加上標籤的文字檔案,預設情況下,假設標籤的話,字首
字串_label_.
輸出model.bin 和model.vec
