
Visual Genome資料集介紹
Visual Genome資料集
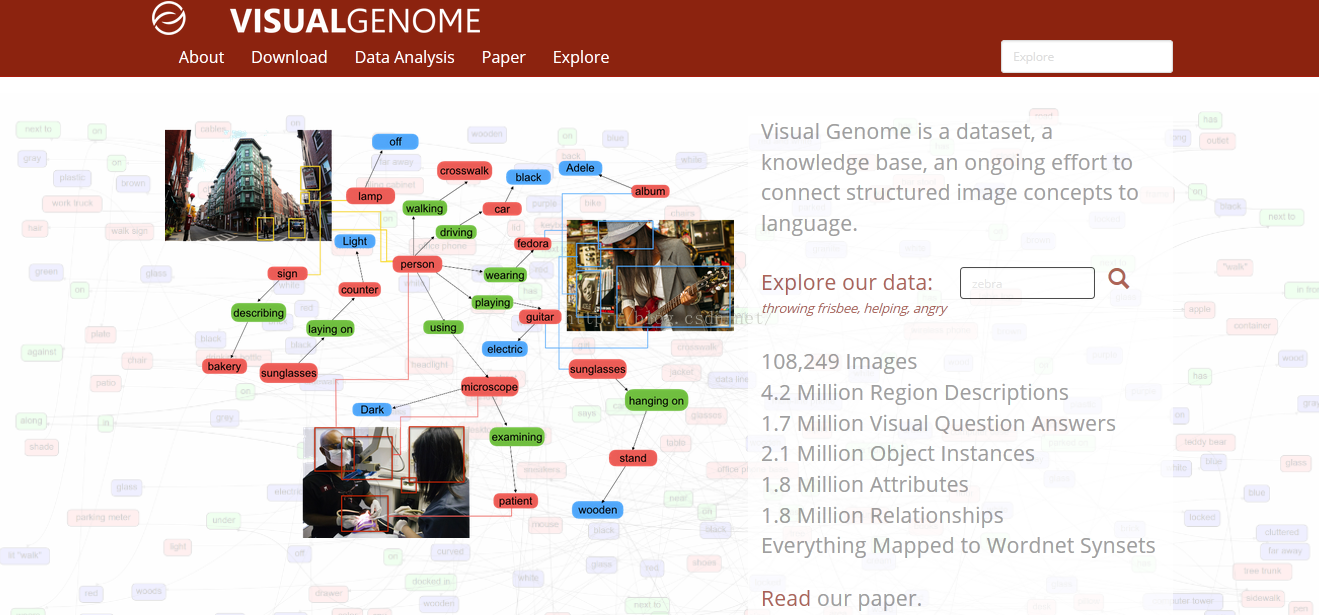
Visual Genome資料集,是由斯坦福大學人工智慧實驗室主任李菲菲與幾位同事合作開發的。
一、作者的初衷是什麼?為什麼要設計出這樣一個數據集?
1.作者在視覺領域研究了多年,一直致力於尋求最好的演算法,來達到更好的效果。但是受人類對於世界的認識過程的啟發,作者認為,教計算機理解圖片,其實和教兒童認識世界的過程是類似的。兒童的眼睛就類似一對生物相機,3歲時他已經瀏覽過數億張真實世界的影象,這是一個非常龐大的訓練資料集。
由此作者認為,不去一味的尋找演算法,轉而考慮如何構建一個豐富的資料集,或許可以有更好的效果。
2.計算機視覺的行程,最初是感知任務,例如影象分類等,能夠達到給影象貼上標籤的效果。要讓計算機更加智慧,就要過渡到認知來實現。認知不僅僅識別出影象,還要理解圖片。
目前多數資料集是針對感知任務,並沒有針對認知任務做出更多拓展。缺乏一個數據集。
3.一張圖片有豐富的場景,但很難用一個句子完全描述。現在的資料庫例如 Flickr 30K 和 MS-COCO 專注於對影象進行高層次的描述。
對影象進行認知,作者傾向於,對影象區域化分割,不同區域進行詳細描述,對於 Visual Genome 資料集裡的每一張圖片,收集了圖片中不同區域的 42 種描述,提供了更加密集和完全的影象描述。這樣,一張影象上就會存在豐富的註釋描述。因此,提出了一個自己設計的新的資料集。
二、資料集的設計思想
為了更徹底的理解影象,論文提到三個關鍵元素,需要新增到資料集中。整體來看,這三個關鍵點的實現如下:
1、將視覺概念落實到語義層面
這個落實grounding在文中反覆提到,包括其他幾篇論文也多次提到。從文章來看,grounding就是對圖片中的每一個關鍵部分,都要對應有詳細的描述。每一個物件,關係,屬性,都要在圖片中用邊界框標定出來,得到對應的座標,邊界框和文字是一一對應。
2、基於多區域圖片的更加完整描述和問答
更加完整的描述和問答,在論文主要提到的是,採用crowdsource策略,大量人工密集註釋。並通過投票策略等,對這些描述問答做篩選,保證準確性。因此,可以說Visual Genome是首個提供物體的互動和屬性的詳細標籤,將視覺概念落實到語義層面的資料集。
3、對圖片各個組成的形式化表示
形式化表示,在論文中具體表現在,通過將註釋詞彙對映到wordnet中規範化;對每個區域構建一個組織關係圖的形式;將一張圖片上的所有區域圖,聯結起來,構成一個完整的場景圖。
三、Visual Genome資料集有什麼構成?
VisualGenome 資料集包括 7 個主要部分:
l 區域描述
l 物件
l 屬性
l 關係
l 區域圖
l 場景圖
l 問答對
要對影象進行理解的研究,論文從收集描述和問答對開始。文字沒有任何長度和詞彙的限制。然後從描述中提取物件、屬性和關係。這些物件、屬性和關係一起構造了場景圖
2.1 多區域和對它們的描述
在真實世界中,一個簡單的總結,往往不足以描述圖片的所有內容和互動。相反,一個自然的擴充套件方法是,對影象的不同區域進行分別描述。在 Visual Genome 中,收集了對影象不同區域的描述,每一個區域都由邊框進行座標限定。不同的區域之間,允許有高度的重複,而描述會有所不同。資料集中平均對每一張圖片有 42 種區域描述。每一個描述都是一個短語包含著從 1 到 16 個單詞長度,以描述這個區域。
2.2 多個物體與它們的邊框
在資料集中,平均每張圖片包含21個物體,每個物體周圍有一個邊框。不僅如此,每個物體在WordNet中都有一個規範化的ID。
舉例來說,man和person,會被對映到man.n.03。相似的,person被對映到person.n.01。隨後,由於存在上位詞man.n.03,這兩個概念就可以加入person.n.01中了。這是一個重要的標準化步驟,以此避免同一個物體有多個名字(比如,man,person,human),也能在不同圖片間,實現資訊互聯
詞彙標準化的好處,不同圖片間可實現互聯。至於為何要實行按互聯?
我覺得在人類真實認知過程中,我們總會不自覺的,對不同場景進行相互關聯,以利於更好的學習理解。作者這樣設計,就是完全模擬人類的認知。如何利用互聯,更好的學習?
2.3 屬性
VisualGenome中,平均每張圖片有16個屬性。一個物體可以有0個或是更多的屬性。屬性可以是顏色(比如yellow),狀態(比如standing),等等。提取這些物體自身的屬性。從短語“yellow fire hydrant”裡,可提取到了“fire hydrant”有“yellow”屬性。和物體一樣,將屬性在WordNet中規範化;比如,yellow被對映到yellow.s.01。
2.4 一組關係
“關係”將兩個物體關聯到一起。例如,從區域描述“man jumping over fire hydrant”中,可提取到物體man和物體fire hydrant之間的關係是jumping over。這些關係是從一個物體(也叫主體)指向另一個物體(也叫客體)的。
在這個例子裡,主體是man,他正在對客體fire hydrant表現出jumping over的關係。每個關係也在WordNet中有規範化的synset ID:jumping被對映到jump.a.1。資料集中的每張圖片平均包含18個關係。
2.5 一組區域圖
將從區域描述中提取的物體、屬性、以及關係結合在一起,每42個區域創造一幅有向圖表徵。每幅區域圖都是對於圖片的一部分所做的結構化表徵。區域圖中的節點代表物體、屬性、以及關係。物體與它們各自的屬性相連,而關係則從一個物體指向另一個物體。連線兩個物體的箭頭,從主體物體指向關係,再從關係指向其他物體。
2.6 全景圖
區域圖是一張圖片某一區域的表徵,而將它們融合在一起,就得到一幅能表徵整張圖片的全景圖。全景圖是所有區域圖的拼合,包括每個區域描述中所有的物體、屬性、以及關係。
通過這個方式,能夠以更連貫的方式,連結起多個層次的全景資訊。例如,某幅圖中,左邊的區域是“fire hydrantis yellow”,而中間的區域描述是“man is jumping over thefire hydrant”。這樣就可以將它們拼合在一起,得到的是“man is jumping over a yellow firehydrant”。
2.7 問答
資料集中,每張圖片都有兩類問答:基於整張圖片的隨意問答(freeform QAs),以及基於選定區域的區域問答(region-based QAs)。
每張圖片收集有6個不同型別的問題:what,where,how,when,who,以及why。每張圖片的問題都包含了這6個型別,每個型別至少有1個問題。區域問答,是通過區域描述來收集的。例如,我們通過“黃色消防栓”的描述收集到了這個區域問答:
“問:消防栓是什麼顏色的?;答:黃色”。
區域問答對能夠獨立地研究如何優先運用NLP和視覺來回答問題。