
HDFS之SequenceFile和MapFile
Hadoop的HDFS和MapReduce子框架主要是針對大資料檔案來設計的,在小檔案的處理上不但效率低下,而且十分消耗記憶體資源(每一個小檔案佔用一個Block,每一個block的元資料都儲存在namenode的記憶體裡)。解決辦法通常是選擇一個容器,將這些小檔案組織起來統一儲存。HDFS提供了兩種型別的容器,分別是SequenceFile和MapFile。
一、SequenceFile
SequenceFile的儲存類似於Log檔案,所不同的是Log File的每條記錄的是純文字資料,而SequenceFile的每條記錄是可序列化的字元陣列。
SequenceFile可通過如下API來完成新記錄的新增操作:
fileWriter.append(key,value)
可以看到,每條記錄以鍵值對的方式進行組織,但前提是Key和Value需具備序列化和反序列化的功能
Hadoop預定義了一些Key Class和Value Class,他們直接或間接實現了Writable介面,滿足了該功能,包括:
Text 等同於Java中的String
IntWritable 等同於Java中的Int
BooleanWritable 等同於Java中的Boolean
.
.
在儲存結構上,SequenceFile主要由一個Header後跟多條Record組成,如圖所示:
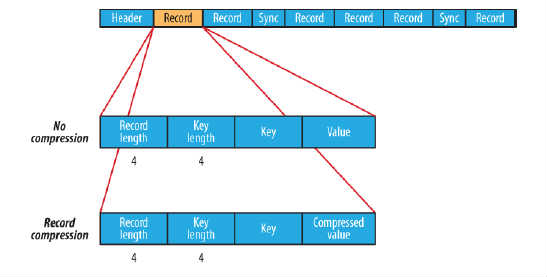
Header主要包含了Key classname,Value classname,儲存壓縮演算法,使用者自定義元資料等資訊,此外,還包含了一些同步標識,用於快速定位到記錄的邊界。
每條Record以鍵值對的方式進行儲存,用來表示它的字元陣列可依次解析成:記錄的長度、Key的長度、Key值和Value值,並且Value值的結構取決於該記錄是否被壓縮。
資料壓縮有利於節省磁碟空間和加快網路傳輸,SeqeunceFile支援兩種格式的資料壓縮,分別是:record compression和block compression。
record compression如上圖所示,是對每條記錄的value進行壓縮
block compression是將一連串的record組織到一起,統一壓縮成一個block,如圖所示:
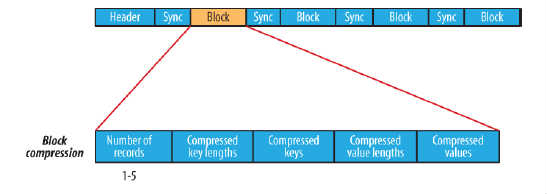
block資訊主要儲存了:塊所包含的記錄數、每條記錄Key長度的集合、每條記錄Key值的集合、每條記錄Value長度的集合和每條記錄Value值的集合
注:每個block的大小是可通過io.seqfile.compress.blocksize屬性來指定的
示例:SequenceFile讀/寫 操作
Configuration conf=new Configuration();
FileSystem fs=FileSystem.get(conf);
Path seqFile=new Path("seqFile.seq");
//Reader內部類用於檔案的讀取操作
SequenceFile.Reader reader=new SequenceFile.Reader(fs,seqFile,conf);
//Writer內部類用於檔案的寫操作,假設Key和Value都為Text型別
SequenceFile.Writer writer=new SequenceFile.Writer(fs,conf,seqFile,Text.class,Text.class);
//通過writer向文件中寫入記錄
writer.append(new Text("key"),new Text("value"));
IOUtils.closeStream(writer);//關閉write流
//通過reader從文件中讀取記錄
Text key=new Text();
Text value=new Text();
while(reader.next(key,value)){
System.out.println(key);
System.out.println(value);
}
IOUtils.closeStream(reader);//關閉read流二、MapFile
MapFile是排序後的SequenceFile,通過觀察其目錄結構可以看到MapFile由兩部分組成,分別是data和index。
index作為檔案的資料索引,主要記錄了每個Record的key值,以及該Record在檔案中的偏移位置。在MapFile被訪問的時候,索引檔案會被載入到記憶體,通過索引對映關係可迅速定位到指定Record所在檔案位置,因此,相對SequenceFile而言,MapFile的檢索效率是高效的,缺點是會消耗一部分記憶體來儲存index資料。
需注意的是,MapFile並不會把所有Record都記錄到index中去,預設情況下每隔128條記錄儲存一個索引對映。當然,記錄間隔可人為修改,通過MapFIle.Writer的setIndexInterval()方法,或修改io.map.index.interval屬性;
另外,與SequenceFile不同的是,MapFile的KeyClass一定要實現WritableComparable介面,即Key值是可比較的。
示例:MapFile讀寫操作
Configuration conf=new Configuration();
FileSystem fs=FileSystem.get(conf);
Path mapFile=new Path("mapFile.map");
//Reader內部類用於檔案的讀取操作
MapFile.Reader reader=new MapFile.Reader(fs,mapFile.toString(),conf);
//Writer內部類用於檔案的寫操作,假設Key和Value都為Text型別
MapFile.Writer writer=new MapFile.Writer(conf,fs,mapFile.toString(),Text.class,Text.class);
//通過writer向文件中寫入記錄
writer.append(new Text("key"),new Text("value"));
IOUtils.closeStream(writer);//關閉write流
//通過reader從文件中讀取記錄
Text key=new Text();
Text value=new Text();
while(reader.next(key,value)){
System.out.println(key);
System.out.println(key);
}
IOUtils.closeStream(reader);//關閉read流注意:使用MapFile或SequenceFile雖然可以解決HDFS中小檔案的儲存問題,但也有一定侷限性,如:
1.檔案不支援複寫操作,不能向已存在的SequenceFile(MapFile)追加儲存記錄
2.當write流不關閉的時候,沒有辦法構造read流。也就是在執行檔案寫操作的時候,該檔案是不可讀取的