
Hadoop2.x 讓你真正明白yarn
阿新 • • 發佈:2019-02-01
問題導讀
1.hadoop1.x中mapreduce框架與yarn有什麼共同點?
2.它們有什麼不同點?
3.yarn中有哪些改變?
4.yarn中有哪些術語?

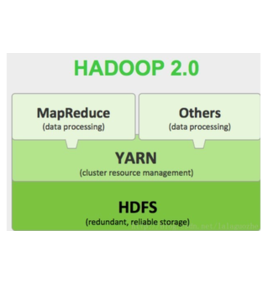
yarn是比較難懂的一個地方,也是很重要的一個元件,不止hadoop使用yarn,spark,storm也可以使用yarn。因此yarn的理解是非常重要的。如果剛開始學習,其實還是挺難懂的。因為很多的概念比較抽象。
如果一時理解不了,也是正常的,這時候就需要我們不斷的接觸和思考,不斷的找資料,強化,通過時間,慢慢就能熟記並且理解。下面是個人總結,希望對大家有所幫助。
相同點
hadoop2.x的發展是由於hadoop1.x的問題造成的。
那麼是什麼問題造成的。比較流行的說法是jobtracker的問題,比如單點故障,任務過重。我們知道了除了Jobtracker,同時還有一個TaskTracker。我們看下圖:

上圖中,有一個JobTracker,多個TaskTracker。
Yarn比較
我們在來看yarn
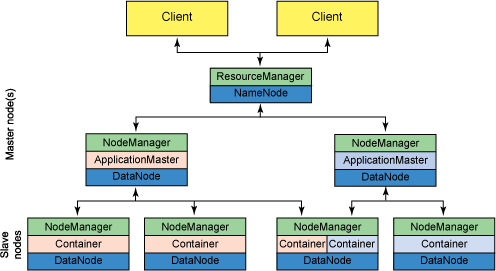
我們看到有一個ResourceManager,多個NodeManager。
也就是說hadoop1.x mapreduce框架與hadoop2.x yarn,他們的框架相同之處,都是分散式的。
再次總結相同處:
JobTracker一個,TaskTracker多個
resourceManager一個,NodeManager多個
不同點
既然他們框架結構是相同的,那麼到底是什麼原因,淘汰JobTracker機制。
這時候我們就需要看看JobTracker到底幹了哪些事情。
再看上圖:JobTacker概述
JobTacker其承擔的任務有:接受任務、計算資源、分配資源、與DataNode進行交流。
在hadoop中每個應用程式被表示成一個作業,每個作業又被分成多個任務,JobTracker的作業控制模組則負責作業的分解和狀態監控。
*最重要的是狀態監控:主要包括TaskTracker狀態監控、作業狀態監控和任務狀態監控。主要作用:容錯和為任務排程提供決策依據。
TaskTracker概述
TaskTracker是JobTracker和Task之間的橋樑:一方面,從JobTracker接收並執行各種命令:執行任務、提交任務、殺死任務等;另一方面,將本地節點上各個任務的狀態通過心跳週期性彙報給JobTracker。TaskTracker與JobTracker和Task之間採用了RPC協議進行通訊
TaskTracker的功能:
1.彙報心跳:Tracker週期性將所有節點上各種資訊通過心跳機制彙報給JobTracker。這些資訊包括兩部分:
*機器級別資訊:節點健康情況、資源使用情況等。
*任務級別資訊:任務執行進度、任務執行狀態等。
2.執行命令:JobTracker會給TaskTracker下達各種命令,主要包括:啟動任務(LaunchTaskAction)、提交任務(CommitTaskAction)、殺死任務(KillTaskAction)、殺死作業(KillJobAction)和重新初始化(TaskTrackerReinitAction)。
資源slot概述
slot不是CPU的Core,也不是memory chip,它是一個邏輯概念,一個節點的slot的數量用來表示某個節點的資源的容量或者說是能力的大小,因而slot是 Hadoop的資源單位。
hadoop中什麼是slots
http://www.aboutyun.com/forum.php?mod=viewthread&tid=7562
yarn詳解
Yarn的基本思想是拆分資源管理的功能,作業排程/監控到單獨的守護程序
這裡面出現了很多名詞:
ResourceManager,NodeManager,ApplicationMaster,Container,同樣下面亦是yarn結構圖。
ResourceManager是全域性的,負責對於系統中的所有資源有最高的支配權。
ApplicationMaster 每一個job有一個ApplicationMaster 。
NodeManager,NodeManager是基本的計算框架。
NodeManager 是客戶端框架負責 containers, 監控他們的資源使用 (cpu, 記憶體, 磁碟, 網路) 和上報給 ResourceManager/Scheduler.
ApplicationMaster首先它是一個框架庫,它的功能官網說的不夠系統,大意,由於NodeManager 執行和監控任務需要資源,所以通過ApplicationMaster與ResourceManager溝通,獲取資源。換句話說,ApplicationMaster起著中間人的作用。
轉換為更專業的術語:AM負責向ResourceManager索要NodeManager執行任務所需要的資源容器,更具體來講是ApplicationMaster負責從Scheduler申請資源,以及跟蹤這些資源的使用情況以及任務進度的監控。
ResourceManager有兩個元件:排程器和應用程式管理器。
排程器(Scheduler)是可插拔的,比如有Fair Scheduler、Capacity Scheduler等,當然排程器也可以自定義。
更多相關內容:
Hadoop YARN配置引數剖析(4)—Fair Scheduler、Capacity Scheduler相關引數
http://www.aboutyun.com/forum.php?mod=viewthread&tid=5864
應用程式管理器
負責接收提交的任務,指定ApplicationMaster申請資源(container) ,協調並提供在ApplicationMaster容器失敗時的重啟功能。
而下圖也是官網提供內容,大家可以參考下。

總結
為了更好的理解,我們就需要跟hadoop1.x比較:
為何要使用yarn。
我們看到JobTracker的功能被分散到各個程序中包括ResourceManager和NodeManager:
比如監控功能,分給了NodeManager,和Application Master。
ResourceManager裡面又分為了兩個元件:排程器及應用程式管理器。
也就是說Yarn重構後,JobTracker的功能,被分散到了各個程序中。同時由於這些程序可以被單獨部署所以這樣就大大減輕了單點故障,及壓力。
同時我們還看到Yarn使用了Container,而hadoop1.x中使用了slot。slot存在的缺點比如只能map或則reduce用。Container則不存在這個問題。這也是Yarn的進步。
參考資源:
hadoop入門:第六章YARN文件概述
http://www.aboutyun.com/forum.php?mod=viewthread&tid=17338
http://hadoop.apache.org/docs/r2.7.2/hadoop-yarn/hadoop-yarn-site/YARN.html
http://www.2cto.com/kf/201311/260826.html
1.hadoop1.x中mapreduce框架與yarn有什麼共同點?
2.它們有什麼不同點?
3.yarn中有哪些改變?
4.yarn中有哪些術語?
yarn是比較難懂的一個地方,也是很重要的一個元件,不止hadoop使用yarn,spark,storm也可以使用yarn。因此yarn的理解是非常重要的。如果剛開始學習,其實還是挺難懂的。因為很多的概念比較抽象。
如果一時理解不了,也是正常的,這時候就需要我們不斷的接觸和思考,不斷的找資料,強化,通過時間,慢慢就能熟記並且理解。下面是個人總結,希望對大家有所幫助。
相同點
hadoop2.x的發展是由於hadoop1.x的問題造成的。
那麼是什麼問題造成的。比較流行的說法是jobtracker的問題,比如單點故障,任務過重。我們知道了除了Jobtracker,同時還有一個TaskTracker。我們看下圖:
上圖中,有一個JobTracker,多個TaskTracker。
Yarn比較
我們在來看yarn
我們看到有一個ResourceManager,多個NodeManager。
也就是說hadoop1.x mapreduce框架與hadoop2.x yarn,他們的框架相同之處,都是分散式的。
再次總結相同處:
JobTracker一個,TaskTracker多個
resourceManager一個,NodeManager多個
不同點
既然他們框架結構是相同的,那麼到底是什麼原因,淘汰JobTracker機制。
這時候我們就需要看看JobTracker到底幹了哪些事情。
再看上圖:JobTacker概述
JobTacker其承擔的任務有:接受任務、計算資源、分配資源、與DataNode進行交流。
在hadoop中每個應用程式被表示成一個作業,每個作業又被分成多個任務,JobTracker的作業控制模組則負責作業的分解和狀態監控。
*最重要的是狀態監控:主要包括TaskTracker狀態監控、作業狀態監控和任務狀態監控。主要作用:容錯和為任務排程提供決策依據。
TaskTracker概述
TaskTracker是JobTracker和Task之間的橋樑:一方面,從JobTracker接收並執行各種命令:執行任務、提交任務、殺死任務等;另一方面,將本地節點上各個任務的狀態通過心跳週期性彙報給JobTracker。TaskTracker與JobTracker和Task之間採用了RPC協議進行通訊
TaskTracker的功能:
1.彙報心跳:Tracker週期性將所有節點上各種資訊通過心跳機制彙報給JobTracker。這些資訊包括兩部分:
*機器級別資訊:節點健康情況、資源使用情況等。
*任務級別資訊:任務執行進度、任務執行狀態等。
2.執行命令:JobTracker會給TaskTracker下達各種命令,主要包括:啟動任務(LaunchTaskAction)、提交任務(CommitTaskAction)、殺死任務(KillTaskAction)、殺死作業(KillJobAction)和重新初始化(TaskTrackerReinitAction)。
資源slot概述
slot不是CPU的Core,也不是memory chip,它是一個邏輯概念,一個節點的slot的數量用來表示某個節點的資源的容量或者說是能力的大小,因而slot是 Hadoop的資源單位。
hadoop中什麼是slots
http://www.aboutyun.com/forum.php?mod=viewthread&tid=7562
yarn詳解
Yarn的基本思想是拆分資源管理的功能,作業排程/監控到單獨的守護程序
這裡面出現了很多名詞:
ResourceManager,NodeManager,ApplicationMaster,Container,同樣下面亦是yarn結構圖。
ResourceManager是全域性的,負責對於系統中的所有資源有最高的支配權。
ApplicationMaster 每一個job有一個ApplicationMaster 。
NodeManager,NodeManager是基本的計算框架。
NodeManager 是客戶端框架負責 containers, 監控他們的資源使用 (cpu, 記憶體, 磁碟, 網路) 和上報給 ResourceManager/Scheduler.
ApplicationMaster首先它是一個框架庫,它的功能官網說的不夠系統,大意,由於NodeManager 執行和監控任務需要資源,所以通過ApplicationMaster與ResourceManager溝通,獲取資源。換句話說,ApplicationMaster起著中間人的作用。
轉換為更專業的術語:AM負責向ResourceManager索要NodeManager執行任務所需要的資源容器,更具體來講是ApplicationMaster負責從Scheduler申請資源,以及跟蹤這些資源的使用情況以及任務進度的監控。
ResourceManager有兩個元件:排程器和應用程式管理器。
排程器(Scheduler)是可插拔的,比如有Fair Scheduler、Capacity Scheduler等,當然排程器也可以自定義。
更多相關內容:
Hadoop YARN配置引數剖析(4)—Fair Scheduler、Capacity Scheduler相關引數
http://www.aboutyun.com/forum.php?mod=viewthread&tid=5864
應用程式管理器
負責接收提交的任務,指定ApplicationMaster申請資源(container) ,協調並提供在ApplicationMaster容器失敗時的重啟功能。
而下圖也是官網提供內容,大家可以參考下。
總結
為了更好的理解,我們就需要跟hadoop1.x比較:
為何要使用yarn。
我們看到JobTracker的功能被分散到各個程序中包括ResourceManager和NodeManager:
比如監控功能,分給了NodeManager,和Application Master。
ResourceManager裡面又分為了兩個元件:排程器及應用程式管理器。
也就是說Yarn重構後,JobTracker的功能,被分散到了各個程序中。同時由於這些程序可以被單獨部署所以這樣就大大減輕了單點故障,及壓力。
同時我們還看到Yarn使用了Container,而hadoop1.x中使用了slot。slot存在的缺點比如只能map或則reduce用。Container則不存在這個問題。這也是Yarn的進步。
參考資源:
hadoop入門:第六章YARN文件概述
http://www.aboutyun.com/forum.php?mod=viewthread&tid=17338
http://hadoop.apache.org/docs/r2.7.2/hadoop-yarn/hadoop-yarn-site/YARN.html
http://www.2cto.com/kf/201311/260826.html