
Hadoop2.6.0配置引數檢視小工具
前言
使用Hadoop進行離線分析或者資料探勘的工程師,經常會需要對Hadoop叢集或者mapreduce作業進行效能調優。也許你知道通過瀏覽器訪問http://master:18088/conf來檢視配置資訊,如下圖所示:
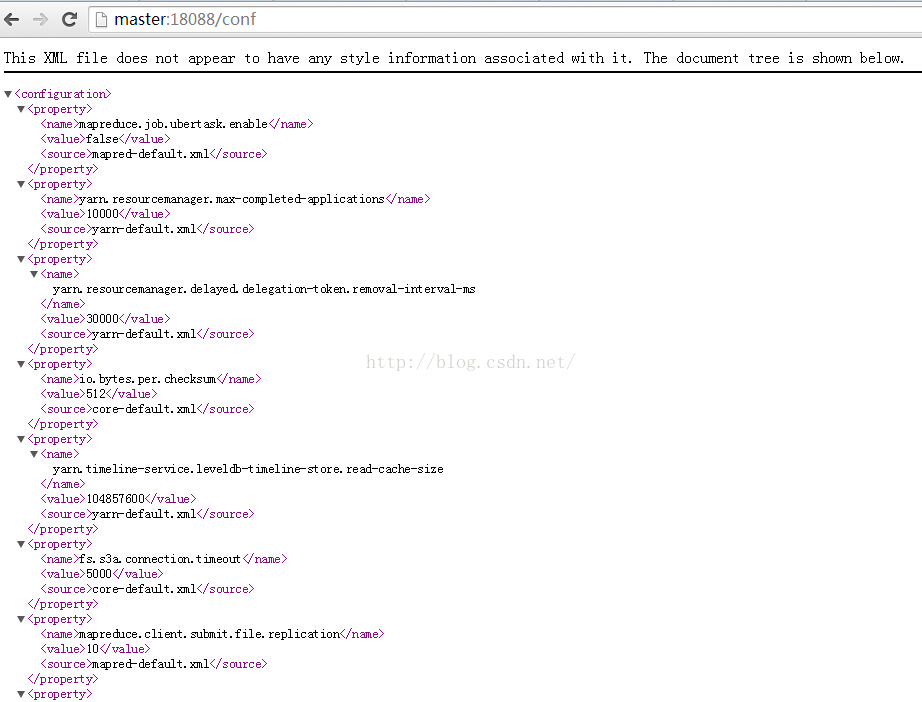
但是當Linux工程師們只面對命令列時,如何檢視呢?而且如果運維工程師根據叢集狀況及執行歷史使用shell、Python、ruby等指令碼寫些運維程式碼,甚至動態調整叢集引數時,該怎麼辦呢?效能調優的前提是需要能準確知道目前針對Hadoop叢集或者mapreduce作業配置的引數。在MySQL中可以通過以下命令查詢引數值:
也可以使用以下命令查詢引數值:SHOW VARIABLES LIKE 'some_parameter'
SELECT @@session.some_parameter
SELECT @@global.some_parameter可惜的是Hadoop沒有提供類似的方式,這對於在Linux系統下檢視引數進而修改引數增加了成本和負擔。儘管我們可以
本文將針對這一需求,基於Hadoop開發一個簡單實用的工具查詢檢視各種引數。
準備工作
首先在Hadoop叢集的Master節點的個人目錄下建立workspace目錄用於儲存開發的Hadoop應用程式碼,命令如下:
進入workspace目錄,開始編輯HadoopConfDisplay.java程式碼:mkdir workspace
為便於大家使用,我把程式碼都列出來,這其實也是借鑑了網上別人的一些內容:
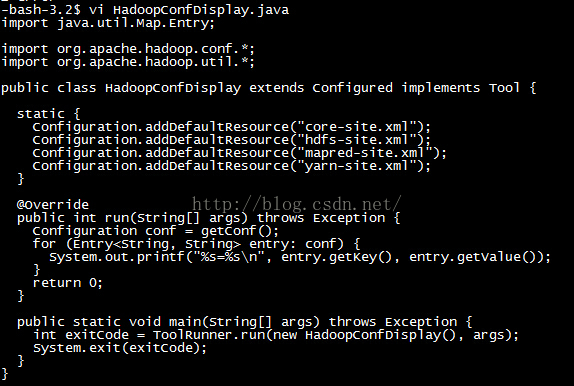
import java.util.Map.Entry; import org.apache.hadoop.conf.*; import org.apache.hadoop.util.*; public class HadoopConfDisplay extends Configured implements Tool { static { Configuration.addDefaultResource("core-site.xml"); Configuration.addDefaultResource("hdfs-site.xml"); Configuration.addDefaultResource("mapred-site.xml"); Configuration.addDefaultResource("yarn-site.xml"); } @Override public int run(String[] args) throws Exception { Configuration conf = getConf(); for (Entry<String, String> entry: conf) { System.out.printf("%s=%s\n", entry.getKey(), entry.getValue()); } return 0; } public static void main(String[] args) throws Exception { int exitCode = ToolRunner.run(new HadoopConfDisplay(), args); System.exit(exitCode); } }
在Hadoop的根目錄下建立myclass,此目錄用於儲存個人開發的Hadoop應用程式碼編譯後的class或者jar包。我本地的目錄為/home/jiaan.gja/install/hadoop-2.6.0/myclass/
由於HadoopConfDisplay中使用了hadoop-common-2.6.0.jar中的類,所以編譯HadoopConfDisplay.java時需要指定classpath。同時將編譯後的class輸出到/home/jiaan.gja/install/hadoop-2.6.0/myclass/目錄下。執行命令如下:

進入myclass目錄,將編譯好的HadoopConfDisplay的class打到jar包裡:
jar cvf mytest.jar *
成果驗證
經過以上準備,最終我們生成了mytest.jar包檔案,現在到了驗證輸出Hadoop配置引數的時候。輸入以下命令:
hadoop jar mytest.jar HadoopConfDisplay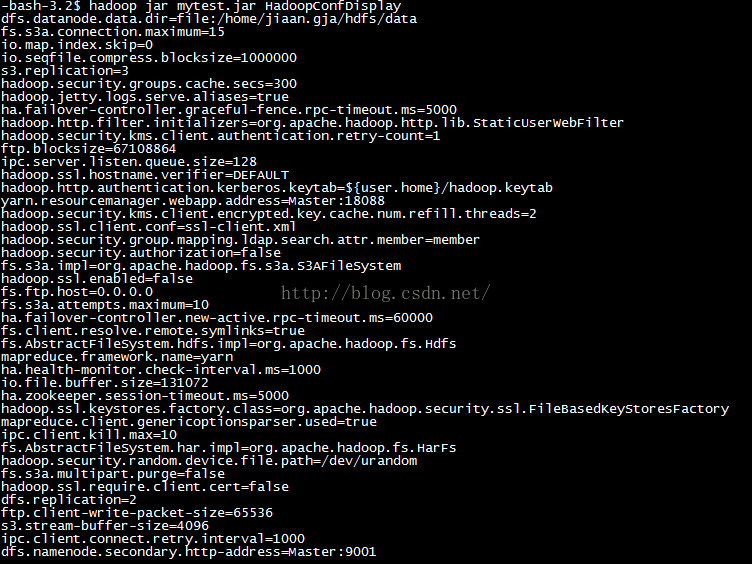
由於引數的確很多,這裡只展示了其中的一部分資訊。這裡顯示的資訊雖然很多,可是會發現很多引數並沒有包括進來,比如:
mapreduce.job.ubertask.enable
mapreduce.job.ubertask.maxreduces
mapreduce.job.ubertask.maxmaps
完善
還記得本文剛開始說的通過web介面檢視Hadoop叢集引數的內容嗎?我在我個人搭建的叢集(有關叢集的搭建可以參照《Linux下Hadoop2.6.0叢集環境的搭建》)上訪問http://master:18088/conf頁面時,可以找到以上缺失的引數如下所示:
<configuration>
<property>
<name>mapreduce.job.ubertask.enable</name>
<value>false</value>
<source>mapred-default.xml</source>
</property>
<!-- 省略其它引數屬性 -->
<property>
<name>mapreduce.job.ubertask.maxreduces</name>
<value>1</value>
<source>mapred-default.xml</source>
</property>
<!-- 省略其它引數屬性 -->
<property>
<name>mapreduce.job.ubertask.maxmaps</name>
<value>9</value>
<source>mapred-default.xml</source>
</property>
<!-- 省略其它引數屬性 -->
</configuration>import java.util.Map.Entry;
import org.apache.hadoop.conf.*;
import org.apache.hadoop.util.*;
public class HadoopConfDisplay extends Configured implements Tool {
static {
Configuration.addDefaultResource("core-default.xml");
Configuration.addDefaultResource("yarn-default.xml");
Configuration.addDefaultResource("mapred-default.xml");
Configuration.addDefaultResource("core-site.xml");
Configuration.addDefaultResource("hdfs-site.xml");
Configuration.addDefaultResource("mapred-site.xml");
Configuration.addDefaultResource("yarn-site.xml");
}
@Override
public int run(String[] args) throws Exception {
Configuration conf = getConf();
for (Entry<String, String> entry: conf) {
System.out.printf("%s=%s\n", entry.getKey(), entry.getValue());
}
return 0;
}
public static void main(String[] args) throws Exception {
int exitCode = ToolRunner.run(new HadoopConfDisplay(), args);
System.exit(exitCode);
}
}最後我們按照之前的方式編譯打包為mytest.jar,再執行命令驗證的結果如下圖所示:

之前缺失的引數都出來了,呵呵!
這下大家可以愉快的進行效能調優了。
後記:個人總結整理的《深入理解Spark:核心思想與原始碼分析》一書現在已經正式出版上市,目前京東、噹噹、天貓等網站均有銷售,歡迎感興趣的同學購買。
