
淺談C/C++程式設計中的字元編碼轉換
背景
在寫跨平臺的C/C++程式碼過程中(本文的研究只限於C/C++範疇),經常會遇到中文字串亂碼的問題。比如,同一個原始碼,用MSVC編譯/執行能正常顯示中文字串,但在linux下編譯/執行顯示中文字串就亂碼。
導致這種現象的根源就在於字符集編碼不匹配導致,本文將探索隱藏在程式設計過程中鮮為人知的字符集轉換問題,如果你徹底理解了以下幾個字符集的概念,以及程式設計過程中哪些因素會影響這些字符集,將有助於你從根源上解決亂碼問題。
原始碼字符集:
英文the source character set,是指原始碼檔案是使用何種編碼字符集儲存的。執行字符集:
英文the execution character set,是指原始碼經過編譯、連結後的可執行檔案是使用何種編碼字符集儲存的,程式實際執行時,記憶體中的字串編碼就是執行字符集。執行環境編碼:
是指作業系統(或者當前控制檯環境)用於顯示文字的編碼字符集。
亂碼的根源
原始碼檔案(原始碼字符集)經過編譯/連結,生成可執行檔案(執行字符集),最後程式運行於實際環境中(執行環境編碼)。在這過程中如果有字符集不匹配,最終就無法顯示預期的文字資訊,甚至產生亂碼。
編譯器在編譯原始碼時,會將原始碼字符集轉化為執行字符集,如果編譯器不能正確識別原始碼字符集,就得不到正確的字串資料。
可執行檔案在實際執行環境中執行時,為了在控制檯(或者其他UI)上顯示出字串,就要將執行字符集轉化為執行環境的字符集。如果執行環境的字符集與執行字符集不同,也會導致亂碼。
總結起來,要想使程式不會亂碼,必須滿足:
編譯器準確識別了原始碼字符集,從而得到正確的字串資料(執行字符集)。
執行環境的編碼與執行字符集相同。
字符集
有關字符集的介紹,以下這篇文章講解的很好,大家先看這篇文章,標題是“字符集編碼與 C/C++ 原始檔字元編譯亂彈”,連結地址:http://jimmee.iteye.com/blog/2165685
此處引用其幾個概念的定義:
- C locale
ANSI 釋出的字元編碼標準,編碼空間 0x00-0x7F,佔用1個位元組,上學時學的 C 語言書後面的字元表中就是它,因為使用這個字符集中的字元就已經可以編寫 C 程式原始碼了,所以給這個字符集起一個 locale 名叫 C,所有實現的 C 語言執行時和系統執行時,都應該有這個 C locale,因為它是所有字符集中最小的一個,設定為其它 locale 時可能由於不存在而出錯,但設定 C 一定不會出錯,比如:當 Linux 的 LANG 配置出錯時,所有的 LC_* 變數就會被自動設定為最小的 C locale。
- 單位元組字符集(SBCS - Single-Byte Character Set)
像ASCII、ISO-8859-1 這種用1個位元組編碼的字符集,叫做單位元組字符集(SBCS - Single-Byte Character Set)。
- 多位元組字符集(MBCS - Multi-Byte Character Set)
像GB2312,GBK,GB18030這種用1-2、4個不等位元組編碼的字符集,叫做多位元組字符集(MBCS - Multi-Byte Character Set)。
- GB2312,GBK,GB18030
GB18030:最新漢字編碼字符集,向下相容GBK,GB2312;
GBK:漢字擴充套件編碼,向下相容GB2312, 幷包含BIG5(繁體)全部漢字;
GB2312:簡化漢字編碼字符集;
原始碼字符集
不同工具新建的原始碼檔案編碼格式不同
原始碼都是由不同作業系統的不同編輯工具產生的,不同工具新建的原始碼檔案編碼格式不同,比如拿我電腦來說:
- 在Windows下用VS2010新建的原始碼檔案是GB2312編碼格式。
- 在Windows下用notepad++新建的原始碼檔案是UTF-8編碼格式。
- 在Linux下用VI新建的原始碼檔案是UTF-8格式。
用以下工具可以方便確認檔案的編碼格式
Linux命令file:
# file main.c
main.c: UTF-8 Unicode (with BOM) C program text, with CRLF, LF line terminators
在Windows下,沒有便利的命令可用,可以使用各種編輯工具的“另存為”間接檢視,比如Microsoft Visual Studio 2010選單“檔案 > 高階儲存選項”。或者,如果你的windows下有安裝git,可以開啟git bash按linux的方式檢視。或者,如果你是windows 10版本,也可以利用原生支援的Linux Bash命令列檢視。
檔案編碼格式轉換
Linux下可以使用iconv進行轉化,如
# iconv -f UTF-8 -t GB2312 main.c
Windows很多編輯工具的“另存為”都有轉換編碼格式的選項。比如Microsoft Visual Studio 2010選單“檔案 > 高階儲存選項”。
執行字符集
原始碼編譯成可執行檔案,原始碼字符集會轉換成執行字符集,可執行檔案中的字串常量就是執行字符集,可以通過WinHex、hd 等16進位制檢視工具,對執行檔案進行檢視。可執行檔案中的字串常量位元組流,跟程式執行起來記憶體中的位元組流是一樣的。
先看下編譯器如何識別原始碼檔案,編譯過程中又是如何將原始碼字符集轉化為執行字符集的。拿Microsoft Visual Studio 2010和GCC做舉例。
MSVC(SP1)
識別“原始碼字符集:
原始碼檔案有BOM簽名的,就按BOM的編碼來解析原始檔;否則使用本地Locale字符集解析原始檔(隨系統設定而變)。轉化“執行字符集”:
對於char型別,如果有設定預處理選項“#pragma execution_character_set”,編譯原始碼時,轉換為預編譯所設定的執行字符集;否則使用本地Locale作為執行字符集。對於wchar_t型別,總是使用UTF-16編碼。
注意:#pragma execution_character_set預處理指令是在Microsoft Visual Studio 2010 SP1以上才有,Microsoft Visual Studio 2010要打上SP1補丁才支援。所以程式碼要類似這樣寫:
#if _MSC_VER >= 1600 /* 1600 is Microsoft Visual Studio 2010 */
#pragma execution_character_set("utf-8")
#endif
GCC
GCC的原始碼字符集與執行字符集預設都是UTF-8編碼,也就是說預設情況下GCC都是按UTF-8來解析原始碼,編譯後的執行字符集也是UTF-8。當然GCC也提供改變預設情況的編譯選項(注意是編譯過程中的選項,不是連結過程)。
-finput-charset=charset 用於指定原始碼字符集
-fexec-charset=charset 用於指定執行字符集
除了前兩個選項外,還有一個:
-fwide-exec-charset=charset
以下的測試程式,能佐證上面的觀點:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#if _MSC_VER >= 1600 /* 1600 is Microsoft Visual Studio 2010 */
#pragma execution_character_set("utf-8")
#endif
int main(int argc, char *argv[])
{
char *str = "123漢ABC";
char *p;
printf("%d |", strlen(str));
for(p=str; *p; p++) {
printf(" %.2X", (unsigned char)(*p));
}
printf(" | %s\n", str);
return 0;
}以下表格個欄位含義解釋:
原始碼字符集:使用WinHex檢視原始碼中字串常量位元組流,使用Microsoft Visual Studio 2010選單“檔案 > 高階儲存選項”來轉換原始碼字符集。
執行字符集:使用WinHex檢視可執行檔案中字串常量的位元組流。
是否設定windows預編譯選項:#pragma execution_character_set(“utf-8”)
是否設定Linux編譯選項:-finput-charset和-fexec-charse
紅色顯示的就是“漢”的編碼:“漢”的GBK編碼為BA BA,UTF-8編碼為E6 B1 89
Microsoft Visual Studio 2010編譯器測試資料:
GCC(版本gcc version 4.4.5)測試資料:
執行環境編碼
如果執行環境編碼(字符集)與執行字符集不同,也會導致亂碼,從上面的測試資料中也能看出來這點。為了顯示正確的字元,可以通過修改執行環境編碼(字符集),讓其跟執行字符集保持一致即可。
Windows控制檯執行環境編碼
要檢視windows控制檯當前的執行環境編碼,可以在cmd.exe輸入chcp,或者在cmd.exe標題欄右鍵屬性檢視,顯示結果類似“活動的內碼表: 936”。
如果要修改編碼,可在cmd.exe輸入CHCP [nnn]回車,其中nnn指定的是內碼表的編號。比如將控制檯的字符集改為UTF-8:chcp 65001
內碼表(Code Page)是字符集編碼的別名,也有人稱”內碼錶”。如936是簡體中文(GBK)的內碼表編號,65001是UTF8的內碼表編號。
Linux終端執行環境編碼
我們知道linux系統有六個字元終端(tty1~tty6)和一個圖形桌面(GUI視窗,tty7),從圖形桌面切換到字元終端,只需按快捷鍵CTRL+ALT+F1,或CTRL+ALT+F2……CTRL+ALT+F6。要切換回圖形桌面,只需按快捷鍵CTRL+ALT+F7。
“終端”在歷史早期是屬於硬體裝置,我們現在說的linux終端(Terminal ),主要包括兩種型別:“虛擬終端”和“模擬終端”。
虛擬終端:指的是字元終端tty1~tty6;
模擬終端:指的是圖形桌面中的終端,我更喜歡它的另外一個名稱“終端模擬程式(Terminal Emulation Program)”或者“終端模擬器(Terminal Emulator)”,它是一個程式,明顯的特徵是帶有視窗,如Ubuntu預設的終端模擬器GNOME,還有我們平常在Windows系統中遠端登入(SHH/Telnet等)到linux中用的終端也是終端模擬器。
網上很多資料說linux終端要支援中文,只要修改locale環境變數即可,但這些方法對我都不奏效,不管是在字元終端,還是圖形桌面終端,修改locale不能讓我上面的測試程式在終端中打印出GBK編碼的“漢”字(打印出來都是亂碼)。可能是我我研究的還不夠深入,不過我使用以下這些方法也能讓我打印出GBK編碼的“漢”字,不管這種方法主不主流,那不是本文討論的範疇,我要強調的一件事是:執行環境編碼(字符集)與執行字符集不同,也會導致亂碼,如果兩個字符集一樣,就不會亂碼。
先說說圖形桌面的終端模擬器,終端模擬器要支援中文比較簡單,只要在視窗標題欄選單中設定字元編碼即可。如Ubuntu的圖形桌面預設的終端是,GNOME 桌面的終端模擬器,要改變其字元編碼格式,在選單“終端 > 設定字元編碼”中改變,如下圖所示。Windows下遠端登入的終端模擬器也是如此修改,畢竟他們都是帶有視窗的程式而已,修改起來簡單。
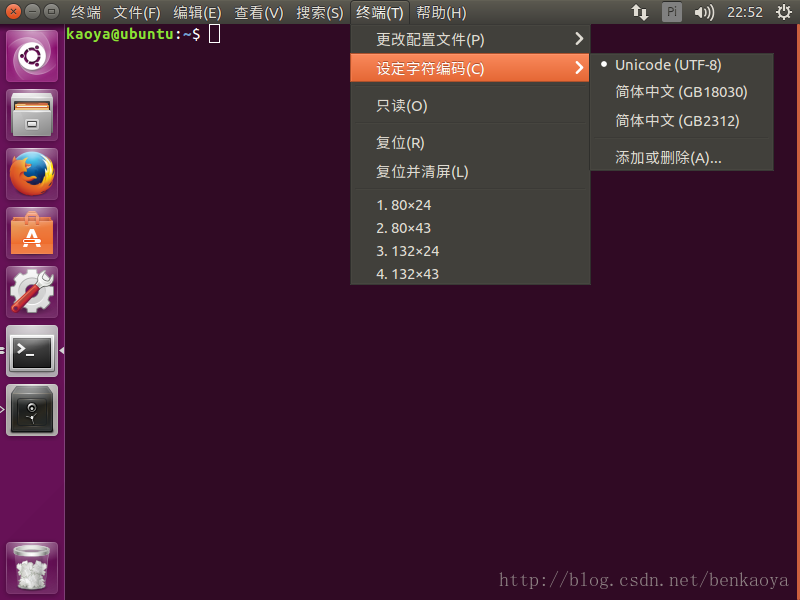
tty1~tty6字元終端要顯示中文就比較麻煩了,幾乎任何一種linux發行版,在tty1~tty6字元終端中都無法正常顯示中文(中文會顯示成亂碼),即使你在圖形桌面(tty7)中已經安裝中文語言支援(已經能夠在終端模擬器中顯示中文),也是沒個卵用。
要在tty1~tty6中顯示中文,就得裝一些中文化介面的軟體,如cce、zhcon或fbterm等。
zhcon是一個工作在Linux控制檯下的多內碼中文平臺。 它能夠在控制檯上顯示簡體中文、繁體中文、日文、韓文等雙位元組字元。它的專案主頁是:http://sourceforge.net/projects/zhcon
下面就拿zhcon舉例(我的環境是Ubuntu環)。
安裝
# sudo apt-get install zhcon
啟動
# zhcon
不帶引數執行zhcon,預設的編碼是gb2312,要utf8編碼就要帶引數:
# zhcon --utf8 --drv=auto