
使用Crash工具分析 Linux dump檔案
Linux 核心(以下簡稱核心)是一個不與特定程序相關的功能集合,核心的程式碼很難輕易的在偵錯程式中執行和跟蹤。開發者認為,核心如果發生了錯誤,就不應該繼續運 行。因此核心發生錯誤時,它的行為通常被設定為系統崩潰,機器重啟。基於動態儲存器的電氣特性,機器重啟後,上次錯誤發生時的現場會遭到破壞,這使得查詢 核心的錯誤變得異常困難。
核心社群和一些商業公司為此開發了很多種除錯技術和工具,希望可以讓核心的除錯變得簡單。其中一種是單步跟蹤除錯方法,即使用程式碼偵錯程式,一 步步的跟蹤執行的程式碼,通過檢視變數和暫存器的值來分析錯誤發生的原因。這一類的偵錯程式有 gdb,kdb, kgdb。另一種方法是在系統崩潰時,將記憶體儲存起來,供事後進行分析。多數情況下,單步調式跟蹤可以滿足需求,但是單步跟蹤除錯也有缺點。如遇到如下幾 種情況時:
- 錯誤發生在客戶的機器上。
- 錯誤發生在很關鍵的生產機器上。
- 錯誤很難重現。
單步除錯跟蹤方法將無能為力。對於這幾種情況,在核心發生錯誤並崩潰的時候,將記憶體轉儲起來供事後分析就顯得尤為重要。本文接下來將介紹核心 的記憶體轉儲機制以及如何對其進行分析。
由於 Linux 的開放性的緣故,在 Linux 下有好幾種記憶體轉儲機制。下面將對它們分別做簡要的介紹。
LKCD(Linux Kernel Crash Dump) 是 Linux 下第一個核心崩潰記憶體轉儲專案,它最初由 SGI 的工程師開發和維護。它提供了一種可靠的方法來發現、儲存和檢查系統的崩潰。LKCD 作為 Linux 核心的一個補丁,它一直以來都沒有被接收進入核心的主線。目前該專案已經完全停止開發。
Diskdump 是另外一個核心崩潰記憶體轉儲的核心補丁,它由塔高 (Takao Indoh) 在 2004 年開發出來。與 LKCD 相比,Diskdump 更加簡單。當系統崩潰時,Diskdump 對系統有完全的控制。為避免混亂,它首先關閉所有的中斷;在 SMP 系統上,它還會把其他的 CPU 停掉。然後它校驗它自己的程式碼,如果程式碼與初始化時不一樣。它會認為它已經被破壞,並拒絕繼續執行。然後 Diskdump 選擇一個位置來存放記憶體轉儲。Diskdump 作為一個核心的補丁,也沒有被接收進入核心的主線。在眾多的發行版中,它也只得到了 RedHat 的支援。
RedHat 在它的 Linux 高階伺服器 2.1 的版本中,提供了它自己的第一個核心崩潰記憶體轉儲機制:Netdump。 與 LKCD 和 Diskdump 將記憶體轉儲儲存在本地磁碟不同,當系統崩潰時,Netdump 將記憶體轉儲檔案通過網路儲存到遠端機器中。RedHat 認為採用網路方式比採用磁碟保的方式要簡單,因為當系統崩潰時,可以在沒有中斷的情況下使用網絡卡的論詢模式來進行網路資料傳送。同時,網路方式對記憶體轉儲 檔案提供了更好的管理支援。與 Diskdump 一樣,Netdump 沒有被接收進入核心的主線,目前也只有 RedHat 的發行版對 Netdump 提供支援。
Kdump 是一種基於 kexec 的記憶體轉儲工具,目前它已經被核心主線接收,成為了核心的一部分,它也由此獲得了絕大多數 Linux 發行版的支援。與傳統的記憶體轉儲機制不同不同,基於 Kdump 的系統工作的時候需要兩個核心,一個稱為系統核心,即系統正常工作時執行的核心;另外一個稱為捕獲核心,即正常核心崩潰時,用來進行記憶體轉儲的核心。 在本文稍後的內容中,將會介紹如何設定 kump。
MKdump(mini kernel dump) 是 NTT 資料和 VA Linux 開發另一個核心記憶體轉儲工具,它與 Kdump 類似,都是基於 kexec,都需要使用兩個核心來工作。其中一個是系統核心;另外一個是 mini 核心,用來進行記憶體轉儲。與 Kdump 相比,它有以下特點:
- 將記憶體儲存到磁碟。
- 可以將記憶體轉儲映象轉換到 lcrash 支援格式。
- 通過 kexec 啟動時,mini 核心覆蓋第一個核心。
與具有眾多的記憶體轉儲機制一樣,Linux 下也有眾多的記憶體轉儲分析工具,下面將會逐一做簡單介紹。
Lcrash 是隨 LKCD 一起釋出的一個內記憶體儲分析工具。隨著 LKCD 開發的停止,lcrash 的開發也同時停止了。目前它的程式碼已經被合併進入 Crash 工具中。
Alicia (Advanced Linux Crash-dump Interactive Analyzer,高階 Linux 崩潰記憶體轉儲互動分析器 ) 是一個建立在 lcrash 和 Crash 工具之上的一個記憶體轉儲分析工具。它使用 Perl 語言封裝了 Lcrash 和 Crash 的底層命令,向用戶提供了一個更加友好的互動方式和介面。Alicia 目前的開發也已經停滯。
Crash 是由 Dave Anderson 開發和維護的一個記憶體轉儲分析工具,目前它的最新版本是 5.0.0。 在沒有統一標準的記憶體轉儲檔案的格式的情況下,Crash 工具支援眾多的記憶體轉儲檔案格式,包括:
- Live linux 系統
- kdump 產生的正常的和壓縮的記憶體轉儲檔案
- 由 makedumpfile 命令生成的壓縮的記憶體轉儲檔案
- 由 Netdump 生成的記憶體轉儲檔案
- 由 Diskdump 生成的記憶體轉儲檔案
- 由 Kdump 生成的 Xen 的記憶體轉儲檔案
- IBM 的 390/390x 的記憶體轉儲檔案
- LKCD 生成的記憶體轉儲檔案
- Mcore 生成的記憶體轉儲檔案
通過前面的學習,你現在可能已經躍躍欲試了。本文接下來的部分,將以 kdump 為例子,向大家演示如何設定系統、如何產生記憶體轉儲檔案以及如何對記憶體轉儲檔案進行分析。
如前面所述,支援 kdump 的系統使用兩個核心進行工作。目前一些發行版,如 RedHat 和 SUSE 的 Linux 都已經編譯並設定好這兩個核心。如果你使用其他發行版的 Linux 或者想自己編譯核心支援 kdump,那麼可以根據如下介紹進行。
- 使用 root 使用者登入系統。
-
使用 wget 從 Internet 上下載 kexec。
wget http://www.kernel.org/pub/linux/kernel/people/horms/kexec-tools/\
kexec-tools.tar.gz -
解壓並安裝 kexec 到系統中。
# tar xvpzf kexec-tools.tar.gz
# cd kexec-tools-VERSION
# ./configure
# make && make install
-
在 "Processor type and features."選項中啟用"kexec system call"。
CONFIG_KEXEC=y
-
在"Filesystem" -> "Pseudo filesystems." 中啟用"sysfs file system support"。
CONFIG_SYSFS=y
-
在"Kernel hacking."中啟用"Compile the kernel with debug info"。
CONFIG_DEBUG_INFO=Y
-
在"Processor type and features"中啟用"kernel crash dumps"。
CONFIG_CRASH_DUMP=y
-
在"Filesystems" -> "Pseudo filesystems"中啟用"/proc/vmcore support"。
CONFIG_PROC_VMCORE=y
Linux 核心支援多種 CPU 架構,這裡只介紹捕捉核心在 i386 下的配置
-
在"Processor type and features"中啟用高階記憶體支援。
CONFIG_HIGHMEM64G=y
-
在"Processor type and features"中關閉多處理器支援。
CONFIG_SMP=n
-
在"Processor type and features"中啟用"Build a relocatable kernel"。
CONFIG_RELOCATABLE=y
-
在"Processor type and features"->"Physical address where the kernel is loaded"中,為核心設定一個載入起始地址。在大多數的機器上,16M 是一個合適的值。
CONFIG_PHYSICAL_START=0x1000000
- 編譯系統核心和捕捉核心。
- 將重新編譯好的核心新增到啟動引導中,注意不要將捕捉核心新增到啟動引導選單中。
- 給系統核心新增啟動引數"[email protected]",這裡,Y 是為 dump 捕捉核心保留的記憶體,X 是保留部分記憶體的開始位置。在 i386 的機器上,設定"[email protected]"。
- 重啟機器,在啟動選單中選擇新新增的啟動項,啟動新的系統核心。
在系統核心引導完成後,需要將捕捉核心載入到記憶體中。使用 kexec 工具將捕捉核心載入到記憶體:
# kexec -p <dump-capture-kernel-bzImage> \ |
在捕捉核心被載入進入記憶體後,如果系統崩潰開關被觸發,則系統會自動切換進入捕捉核心。觸發系統崩潰的開關有 panic(),die(),die_nmi() 核心函式和 sysrq 觸發事件,可以使用其中任意的一個來觸發核心崩潰。不過,在讓核心崩潰之前,我們還需要做一些安裝設定。
Crash 目前的最新的版本是 5.0.0, 你可以從它的官方網站下載最新的版本。下載完成後對其進行解壓安裝。
# tar -zvxf crash-5.0.0.tar.gz |
現在已經設定好 Kdump 和 crash,現在可以使用前面介紹的系統崩潰開關中的任意一個來引發系統崩潰來生成一個記憶體轉儲檔案,並可以使用 crash 對其進行分析。
首先,觸發系統崩潰,這裡使用 sysrq 觸發事件。
# echo c > /proc/sysrq-trigger |
緊接著,系統會自動啟動捕捉核心。待完全啟動進入捕捉核心後,通過以下命令儲存記憶體轉儲檔案。
# cp /proc/vmcore mydumpfile |
將在當前目錄生成一個 mydumpfile 檔案。
現在有了一個記憶體轉儲檔案,接下來使用 crash 對其進行分析
# crash vmlinux mydumpfile |
這裡 vmlinux 是帶除錯資訊的核心。如果一切正常,將會進入到 crash 中,如圖 1 所示。
圖 1. crash 命令提示符

在該提示符下,可以執行 crash 的內部命令。通過 crash 的內部命令,可以檢視暫存器的值、函式的呼叫堆疊等資訊。在圖 2 中,顯示了執行 bt命令後得到的函式呼叫的堆疊資訊。
圖 2. 函式呼叫堆疊資訊
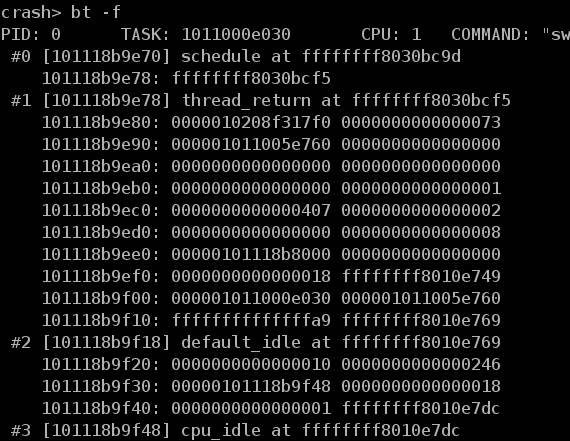
crash 使用 gdb 作為它的內部引擎,crash 中的很多命令和語法都與 gdb 相同。如果你曾經使用過 gdb,就會發現 crash 並不是很陌生。如果想獲得 crash 更多的命令和相關命令的詳細說明,可以使用 crash 的內部命令 help來 獲取。
相關推薦
使用Crash工具分析 Linux dump檔案
前言 Linux 核心(以下簡稱核心)是一個不與特定程序相關的功能集合,核心的程式碼很難輕易的在偵錯程式中執行和跟蹤。開發者認為,核心如果發生了錯誤,就不應該繼續運 行。因此核心發生錯誤時,它的行為通常被設定為系統崩潰,機器重啟。基於動態儲存器的電氣特性,機器重啟後,
使用 Crash 工具分析 Linux dump 檔案
前言 Linux 核心(以下簡稱核心)是一個不與特定程序相關的功能集合,核心的程式碼很難輕易的在偵錯程式中執行和跟蹤。開發者認為,核心如果發生了錯誤,就不應該繼續執行。因此核心發生錯誤時,它的行為通常被設定為系統崩潰,機器重啟。基於動態儲存器的電氣特性,機器重啟後,上次錯誤發生時的現場會遭到破壞,這使得
linux/windows下利用JDK自帶的工具獲取thread dump檔案和heap dump檔案
在上一篇部落格http://blog.csdn.net/aitangyong/article/details/24009283中介紹了dump的一些基本概念,這一篇部落格介紹如何在windows/li
分析java dump檔案
注意,請不要被我誤導,我沒有看其他資料,這是我自己分析的,有些可能是不對的 "DestroyJavaVM" prio=6 tid=0x00316800 nid=0x448 waiting on condition [0x00000000 ..0x00a0fd4c]
例項講解:使用IBM heapAnalyzer分析heap dump檔案步驟
需求動機:解決 OOM( Object Out of Memory)問題以及系統調優 1.如何產生 java heap dump 當 JVM中物件過多, java堆( java heap)耗盡時,就會產生 java heap dump檔案。另外,可以使用工具或命令
利用crash工具分析堆疊宕機問題
1、將/etc/yum.repos.d/centos-*.repo移到別處,新建一個 centos.repo檔案 2、裡面內容填寫如下: [base]] name=ftp-server baseurl=ftp://172.17.62.160/pub/cent
使用GDB分析core dump檔案
到此配置工作完成,下面對core檔案進行分析。 比如我們執行的程式碼出現段錯誤,如下: [[email protected] mywork]# ./testGdb Segmentation fault (core dumped) [[email protected] mywork]#
一次因記憶體覆蓋引起的system dump問題分析,基於linux的crash工具。
關於crash工具 sudo mount system.img the-dir //把system.img掛載到一個目錄,就可以檢視system的檔案了,還用去網上搜什麼解包方法???? 對vmlinux進行反彙編: /home/apuser/mywork/4.4-3.
【取證分析】用linux命令xxd來獲取dump檔案資訊獲得flag
題目連結:https://blog.csdn.net/xiangshangbashaonian/article/details/82747394 拿到一道CTF題目 notepad++開啟如下所示 [email protected]:~/Desktop$ fi
linux core dump 檔案 gdb分析【轉】
core dump又叫核心轉儲, 當程式執行過程中發生異常, 程式異常退出時, 由作業系統把程式當前的記憶體狀況儲存在一個core檔案中, 叫core dump. (linux中如果記憶體越界會收到SIGSEGV訊號,然後就會core dump) 在程式執行的過程中,有
JProfiler工具開啟dump檔案,分析jar包程式記憶體過大後cpu100%
開發的收集車輛資料程式跑了3-5小時,就會出現如下結果發現程式執行記憶體在這幾個紅點波動,在CPU100%出現一段時間內程式會自動結束。後來利用工具命令分析問題得出是因為記憶體不夠導致一直在GC,因為GC Task Thread佔用CPU比較高。具體步驟如下ps -mp 16
Java記憶體Dump檔案檢視和分析工具介紹
1.IBM Memory Analyzer 1)下載地址: https://www6.software.ibm.com/sdfdl/1v2/regs2/awadmin/heapanalyzer/Xa.2/Xb.NoLhAb4A5Mgi2gFYiaC87ef6mY6etlyz
linux kernel crash問題分析解決
kernel crash linux 一,問題場景和環境系統環境:redhat6.4 kernel:2.6.32-358問題:使用iptables給mangle表添加了一條規則,使用nfqueue做為target。當一個http請求命中這個規則之後,機器直接重啟了。偶發性的出了兩次問題,但是卻在重
Linux fsync和fdatasync系統呼叫實現分析(Ext4檔案系統)
參考:https://blog.csdn.net/luckyapple1028/article/details/61413724 在Linux系統中,對檔案系統上檔案的讀寫一般是通過頁快取(page cache)進行的(DirectIO除外),這樣設計的可以延時磁碟IO的操作,從而可以減少磁碟讀
linux工作筆記-linux之間檔案傳輸圖形介面工具gftp
原部落格地址如下: https://blog.csdn.net/w5nner/article/details/21174671 linux系統之間傳輸檔案習慣使用gftp,現寫一下安裝與使用記錄。 安裝: 1、下載gftp原始碼,官網http://
linux下檔案比較工具diff|cmp使用小結
轉自:http://blog.csdn.net/wangjianno2/article/details/50451737,記錄下便於忘記時查詢。 1.diff diff是Unix系統的一個很重要的工具程式。它用來比較兩個文字檔案的差異,是程式碼版本管理的基石之一。 2.diff使用
linux定位應用問題的一些常用命令,特別針對記憶體和執行緒分析的dump命令
1.jps找出程序號,找到對應的程序號後面才好繼續操作 2.linux檢視程序詳細資訊 ps -ef | grep 程序ID 3. dump記憶體資訊 Jmap -dump:format=b,file=YYMMddhhmm
Linux ELF檔案格式分析---objcopy命令的使用
本文轉自:https://blog.csdn.net/xj178926426/article/details/73777611 Linux ELF檔案格式分析—objcopy命令的使用 最近在看《程式設計師的自我修養—連結、裝載與庫》一書,對書中提到的一個小問題,自己做了
Windows下dump檔案生成與分析
一、 生成Dump檔案方式 1.1工作管理員 在程式崩潰後,先不關閉程式,在工作管理員中找到該程式對應的程序。右鍵—>建立轉儲檔案。 此時會在預設的目錄下創建出一個dump檔案。 可以看出,此種方法只適用於程式崩潰但沒有立即自行退出的情況。