
初探推薦演算法:基於使用者的協同過濾演算法
阿新 • • 發佈:2019-02-02
基於使用者的協同過濾演算法
一、基本思路
在一個推薦場景,你需要給使用者推薦一些商品,基本思路是:
(1)找到和目標使用者興趣相似的使用者集合。
(2)找到這個集合中的使用者喜歡的,且目標使用者沒有聽說過的物品推薦給目標使用者。
二、相似度度量
可以有許多不同的方式用於度量,常見的有Jaccard公式,餘弦相似度等等。
餘弦相似度公式如下:
N(u) 表示使用者u給過正反饋的商品集合,所謂正反饋就是使用者傾向於喜歡該物品。N(v)表示使用者v給過正反饋的商品集合。分子表示使用者u和使用者v都喜歡的物品集合。
三、實驗設計
資料集:GroupLens提供的MovieLens資料集(http://www.grouplens.org/node/73)
本次實驗採用1m資料集,該資料集包含了6000多使用者對4000多部電影的100多萬個評分。本實驗討論的是TopN問題,因此對於評分不予討論。
3.1 評測指標
將資料集劃分成訓練集和測試集,對於訓練集的每一個使用者,利用協同過濾演算法向其推薦商品,若推薦結果中的某個商品在測試集中的該使用者的記錄中出現了,則代表該結果是真正例。下面公式的R(u)表示對使用者u推薦的商品集合,T(u)表示使用者u在測試集上喜歡的物品集合。
3.1.1 召回率
3.1.2 準確率
3.1.3 覆蓋率
覆蓋率反映了推薦演算法發掘長尾的能力,說明推薦演算法越能將長尾中的物品推薦給使用者。下面的公式表示的就是最終的推薦列表中包含多大比例的商品。I表示所有商品的集合。
3.1.4 新穎性
新穎的推薦是指給使用者推薦那些他們以前沒有聽說過的物品,最簡單的評測方法就是利用推薦結果的平均流行度。
3.1.5測評指標的程式碼實現
# 名 稱: evaluate
# 功 能: 計算評測指標
# 參 數: trainset, 訓練集
# testset, 測試集
# moviepopularity, 商品的流行度
# numofmovies, 所有電影的數量
# usersim, 相似使用者matrix
# K, 演算法選擇K個相似使用者
# N, 演算法最終選擇N個商品
# 返 回 值: precision, 準確率 recall, 召回率,coverage,覆蓋率 popularity, 新穎度
# 修 改: 2018/5/29
def evaluate(trainset,testset,moviepopularity,numofmovies,usersim,K,N):
print('Evaluation start...')
hit = 0
TPFN = 0
TPFP = 0
allrecmovies = set()
popular_sum = 0
index= 0
print("starting evaluate...")
print("total number of users is: " + str(len(trainset)))
for user in trainset.keys():
index +=1
if index % 200000 ==0:
print("evaluate..." + str(index) + str(len(trainset)))
# 協同過濾演算法對使用者user的推薦結果
rec_movies = recommend(usersim,trainset,user,K,N)
if user not in testset.keys():
continue
testmovies = testset[user]
for rec_movie,_ in rec_movies:
# R(u)∩T(U)的情況
if rec_movie in testmovies:
# 真正例
hit+=1
allrecmovies.add(rec_movie)
# 計算平均流行度,使用log是為了使均值比較穩定,moviepopularity裡面儲存的是每個電影被正反饋操作的次數。
popular_sum += math.log(1 + moviepopularity[rec_movie])
# 所有的正例
TPFN += len(testmovies)
# 所有推薦給使用者的商品數量
TPFP += N
# 準確率
precision = hit * 1.0/ TPFP
# 召回率
recall = hit *1.0 /TPFN
# 覆蓋率
coverage = len(allrecmovies) / (1.0 * numofmovies)
# 流行度
popularity = popular_sum / (1.0 * TPFP)
print('precision=%.4f\trecall=%.4f\tcoverage=%.4f\tpopularity=%.4f' %
(precision, recall, coverage, popularity))
return precision,recall,coverage,popularity3.2 具體步驟
3.2.1 獲得訓練集和測試集
# 名 稱: produceData
# 功 能: 獲得訓練集和測試集
# 參 數: filepath, 檔案路徑
# pivot, 隨機概率
# 返 回 值: trainset, 訓練集
# testset 測試集
# 修 改:2018/5/29
def produceData(filepath,pivot=0.7):
trainset={}
testset={}
file = open(filepath,'r')
lines = file.readlines()
l = len(lines)
print("Number of data is" + str(l))
for i in range(l):
if i%100000==0:
print("loading data......" + str(i) + '/' + str(l))
user,movie,ranting,_ = lines[i].split('\n')[0].split('::')
if random.random() < pivot:
trainset.setdefault(user,{})
trainset[user][movie] = ranting
else:
testset.setdefault(user,{})
testset[user][movie] = ranting
return trainset,testset3.2.2 獲得movie-user以及moviepopularity
該步是為了獲取以movie為key,user為value的字典,以及每部電影的popularity。
# 名 稱: FindRelativeDict
# 功 能: 獲得相關字典
# 參 數: trainset 訓練集
# 返 回 值: movie2user, {'movie':users}字典
# moviepopularity, {'movie': popularity}字典
# 修 改: 2018/5/29
def FindRelativeDict(trainset):
movie2user = {}
moviepopularity ={}
for user,movies in trainset.items():
for movie in movies:
if movie not in movie2user.keys():
movie2user[movie] = set()
movie2user[movie].add(user)
if movie not in moviepopularity.keys():
moviepopularity[movie] = 0
# popularity 定義為電影被所有使用者給過正反饋的次數
moviepopularity[movie] += 1
return movie2user,moviepopularity3.2.3 計算相似使用者dict
在這裡運用到上面的使用者相似度度量的餘弦相似度公式。
# 名 稱: FindUserSimilarity
# 功 能: 計算使用者相似性字典
# 參 數: trainset 訓練集
# movie2user {'movie':users}字典
# 返 回 值: usersim 相似使用者矩陣 {'user':{'similar_user': 相似程度}}
# 修 改: 2018/5/29
def FindUserSimilarity(trainset,movie2user):
usersim = {}
for movie,users in movie2user.items():
for u in users:
usersim.setdefault(u,defaultdict(int))
for v in users:
if u==v:
continue
else:
usersim[u][v] +=1
print( "starting calculate the similarity matrix of users...")
index=0
for u,simiusers in usersim.items():
for v,count in simiusers.items():
index+=1
if index % 300000 == 0:
print("calculating...." + str(index))
usersim[u][v] = count / math.sqrt(
len(trainset[u]) * len(trainset[v]))
return usersim3.2.4 對某使用者進行推薦
# 名 稱: recommand
# 功 能: 給某使用者推薦N件商品
# 參 數: usersim 相似使用者字典
# trainset 訓練集
# user 使用者
# K 在推薦時選取K個最接近的相似使用者
# N 最終選取N件商品給使用者
# 返 回 值: recommendres 推薦的商品字典
# 修 改: 2018/5/29
def recommend(usersim,trainset,user,K,N):
userrec = {}
currentmovies = trainset[user]
for similar_user, similarity_factor in sorted(usersim[user].items(),
key=itemgetter(1), reverse=True)[0:K]:
for movie in trainset[similar_user]:
if movie in currentmovies:
continue
userrec.setdefault(movie,0)
userrec[movie] += similarity_factor
recommendres = sorted(userrec.items(), key=itemgetter(1), reverse=True)[0:N]
return recommendres實驗結果
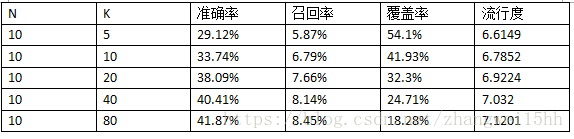
可以發現隨著K的增加,準確率,召回率,流行度會隨之升高,但是覆蓋率變差,這是因為隨著K的增加,該演算法會傾向於推薦熱門的物品,而對長尾物品的推薦越來越少,因此造成了覆蓋率的降低。