
大資料離線分析工具Hive簡單介紹
Hive是Facebook為了解決海量日誌資料的分析而開發的,後來開源給了Apache軟體基金會,可見Apache軟體基金會是個神奇的組織,我們之前學過的很多開源工具都有Apache軟體基金會的身影。
官網定義:
The Apache Hive ™ data warehouse software facilitates reading, writing, and managing large datasets residing in distributed storage using SQL.
此處版本是Hive-1.0.0
Hive的幾個特點
- Hive最大的特點是通過類SQL來分析大資料,而避免了寫MapReduce程式來分析資料,這樣使得分析資料更容易。
- 資料是儲存在HDFS上的,Hive本身並不提供資料的儲存功能
- Hive是將資料對映成資料庫和一張張的表,庫和表的元資料資訊一般存在關係型資料庫上(比如MySQL)。
- 資料儲存方面:它能夠儲存很大的資料集,並且對資料完整性、格式要求並不嚴格。
- 資料處理方面:因為Hive語句最終會生成MapReduce任務去計算,所以不適用於實時計算的場景,它適用於離線分析。
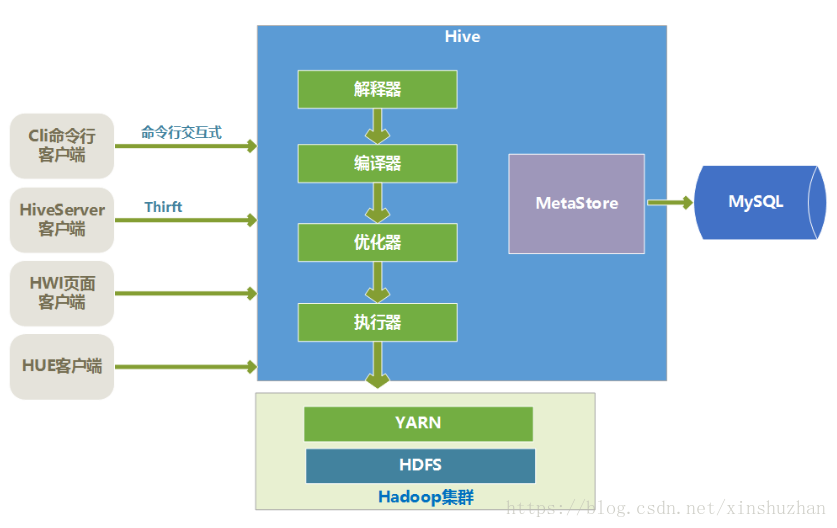
Hive的核心
Hive的核心是驅動引擎,驅動引擎由四部分組成:
- 直譯器:直譯器的作用是將HiveSQL語句轉換為語法樹(AST)。
- 編譯器:編譯器是將語法樹編譯為邏輯執行計劃。
- 優化器:優化器是對邏輯執行計劃進行優化。
- 執行器:執行器是呼叫底層的執行框架執行邏輯執行計劃。
Hive的底層儲存
Hive的資料是儲存在HDFS上的,Hive中的庫和表可以看做是對HDFS上的資料做的一個對映。所以HVIE必須執行在一個Hadoop的叢集上的
Hive語句執行過程
Hive中的執行器,是將最終要執行的MapReduce程式放到YARN上以一系列Job的方式去執行。
Hive的元資料儲存
Hive的元資料是一般是儲存在MySQL這種關係型資料庫上的,Hive和MySQL之間通過MetaStore服務互動。

- Hive客戶端
Hive有很多種客戶端。
- cli命令列客戶端:採用互動視窗,用hive命令列和Hive進行通訊。
- HiveServer2客戶端:用Thrift協議進行通訊,Thrift是不同語言之間的轉換器,是連線不同語言程式間的協議,通過JDBC或者ODBC去訪問Hive。
- HWI客戶端:hive自帶的一個客戶端,但是比較粗糙,一般不用。
- HUE客戶端:通過Web頁面來和Hive進行互動,使用的比較多。
基本的資料型別

DDL語法
建立資料庫
建立一個數據庫會在HDFS上建立一個目錄,Hive裡資料庫的概念類似於程式中的名稱空間,用資料庫來組織表,在大量Hive的情況下,用資料庫來分開可以避免表名衝突。Hive預設的資料庫是default。
建立資料庫例子:
hive> create database if not exists user_db;檢視資料庫定義
hive> describe database user_db;
OK
user_db hdfs://bigdata-51cdh.chybinmy.com:8020/user/hive/warehouse/user_db.db hadoop USERuser_db是資料庫名
hdfs://bigdata-51cdh.chybinmy.com:8020/user/hive/warehouse/userdb.db 是userdb庫對應的儲存資料的HDFS上的根目錄。
檢視資料庫列表
hive> show databases;
OK
user_db
default建立資料庫
hive> create table if not exists userinfo
> (
> userid int,
> username string,
> cityid int,
> createtime date
> )
> row format delimited fields terminated by '\t'
> stored as textfile;
OK
Time taken: 2.133 seconds建立分割槽表
Hive查詢一般是掃描整個目錄,但是有時候我們關心的資料只是集中在某一部分資料上,比如我們一個Hive查詢,往往是隻是查詢某一天的資料,這樣的情況下,可以使用分割槽表來優化,一天是一個分割槽,查詢時候,Hive只掃描指定天分割槽的資料。
普通表和分割槽表的區別在於:一個Hive表在HDFS上是有一個對應的目錄來儲存資料,普通表的資料直接儲存在這個目錄下,而分割槽表資料儲存時,是再劃分子目錄來儲存的。一個分割槽一個子目錄。主要作用是來優化查詢效能。
create table user_action_log
(
companyId INT comment '公司ID',
userid INT comment '銷售ID',
originalstring STRING comment 'url',
host STRING comment 'host',
absolutepath STRING comment '絕對路徑',
query STRING comment '引數串',
refurl STRING comment '來源url',
clientip STRING comment '客戶端Ip',
cookiemd5 STRING comment 'cookiemd5',
timestamp STRING comment '訪問時間戳'
)
partitioned by (dt string)
row format delimited fields terminated by ','
stored as textfile;這個例子中,這個日誌表以dt欄位分割槽,dt是個虛擬的欄位,dt下並不儲存資料,而是用來分割槽的,實際資料儲存時,dt欄位值相同的資料存入同一個子目錄中,插入資料或者匯入資料時,同一天的資料dt欄位賦值一樣,這樣就實現了資料按dt日期分割槽儲存。
當Hive查詢資料時,如果指定了dt篩選條件,那麼只需要到對應的分割槽下去檢索資料即可,大大提高了效率。所以對於分割槽表查詢時,儘量新增上分割槽欄位的篩選條件。
建立桶表
桶表也是一種用於優化查詢而設計的表型別。建立通表時,指定桶的個數、分桶的依據欄位,hive就可以自動將資料分桶儲存。查詢時只需要遍歷一個桶裡的資料,或者遍歷部分桶,這樣就提高了查詢效率。舉例:
create table user_leads
(
leads_id string,
user_id string,
user_id string,
user_phone string,
user_name string,
create_time string
)
clustered by (user_id) sorted by(leads_id) into 10 buckets
row format delimited fields terminated by '\t'
stored as textfile;對這個例子的說明:
clustered by是指根據userid的值進行雜湊後模除分桶個數,根據得到的結果,確定這行資料分入哪個桶中,這樣的分法,可以確保相同userid的資料放入同一個桶中。而經銷商的訂單資料,大部分是根據user_id進行查詢的。這樣大部分情況下是隻需要查詢一個桶中的資料就可以了。
sorted by 是指定桶中的資料以哪個欄位進行排序,排序的好處是,在join操作時能獲得很高的效率。
into 10 buckets是指定一共分10個桶。
在HDFS上儲存時,一個桶存入一個檔案中,這樣根據user_id進行查詢時,可以快速確定資料存在於哪個桶中,而只遍歷一個桶可以提供查詢效率