
大資料學習階段及內容簡單介紹(二)
大資料學習階段(二)
之前已經寫過一篇《大資料學習階段及內容簡單介紹(一)》,簡單介紹了大資料裡面一些有關Java基礎、Linux基礎、離線計算Hadoop、序列化技術Avro、序列化技術ProtoBuf、協調服務Zookeeper、資料倉庫Hive、資料庫Hbase、日誌採集Flume、分散式釋出訂閱訊息系統Kafka、Sqoop的內容以及知識點,除了以上知識點還需要掌握什麼呢?
- Storm
- SSM
- Scala
- Spark
實時處理Storm
(由於之前寫過有關Storm的相關部落格,內容由前部落格直接copy過來)
一、Storm簡介
Storm是一個免費並開源的分散式實時計算系統。利用Storm可以很容易做到可靠地處理無限的資料流,像Hadoop批量處理大資料一樣,Storm可以實時處理資料。
Storm 很簡單,可用於任意程式語言。Apache Storm 採用 Clojure 開發。Storm 有很多應用場景,包括實時資料分析、聯機學習、持續計算、分散式 RPC、ETL 等。
hadoop(大資料分析領域無可爭辯的王者)專注於批處理。這種模型對許多情形(比如為網頁建立索引)已經足夠,但還存在其他一些使用模型,它們需要來自高度動態的來源的實時資訊。為了解決這個問題,就得藉助 Nathan Marz 推出的 storm(現在已經被Apache孵化)storm 不處理靜態資料,但它處理連續的流資料。
storm特點:
程式設計簡單:開發人員只需要關注應用邏輯,而且跟Hadoop類似,Storm提供的程式設計原語也很簡單
高效能,低延遲:可以應用於廣告搜尋引擎這種要求對廣告主的操作進行實時響應的場景。
分散式:可以輕鬆應對資料量大,單機搞不定的場景
可擴充套件: 隨著業務發展,資料量和計算量越來越大,系統可水平擴充套件
容錯:單個節點掛了不影響應用
訊息不丟失:保證訊息處理
storm與hadoop的比較:
1.Storm用於實時計算,Hadoop用於離線計算。
2. Storm處理的資料儲存在記憶體中,源源不斷;Hadoop處理的資料儲存在檔案系統中,一批一批。
3. Storm的資料通過網路傳輸進來;Hadoop的資料儲存在磁碟中。
4. Storm與Hadoop的程式設計模型相似

二、Storm叢集架構
Storm叢集採用主從架構方式,主節點是Nimbus,從節點是Supervisor,有關排程相關的資訊儲存到ZooKeeper叢集中,架構如下圖所示:

Nimbus
Storm叢集的Master節點,負責分發使用者程式碼,指派給具體的Supervisor節點上的Worker節點,去執行Topology對應的元件(Spout/Bolt)的Task。
Supervisor
Storm叢集的從節點,負責管理執行在Supervisor節點上的每一個Worker程序的啟動和終止。通過Storm的配置檔案中的supervisor.slots.ports配置項,可以指定在一個Supervisor上最大允許多少個Slot,每個Slot通過埠號來唯一標識,一個埠號對應一個Worker程序(如果該Worker程序被啟動)。
Worker
執行具體處理元件邏輯的程序。Worker執行的任務型別只有兩種,一種是Spout任務,一種是Bolt任務。
Task
worker中每一個spout/bolt的執行緒稱為一個task. 在storm0.8之後,task不再與物理執行緒對應,不同spout/bolt的task可能會共享一個物理執行緒,該執行緒稱為executor。
ZooKeeper
用來協調Nimbus和Supervisor,如果Supervisor因故障出現問題而無法執行Topology,Nimbus會第一時間感知到,並重新分配Topology到其它可用的Supervisor上執行
三、Storm程式設計模型
Strom在執行中可分為spout與bolt兩個元件,其中,資料來源從spout開始,資料以tuple的方式傳送到bolt,多個bolt可以串連起來,一個bolt也可以接入多個spot/bolt.執行時原理如下圖:
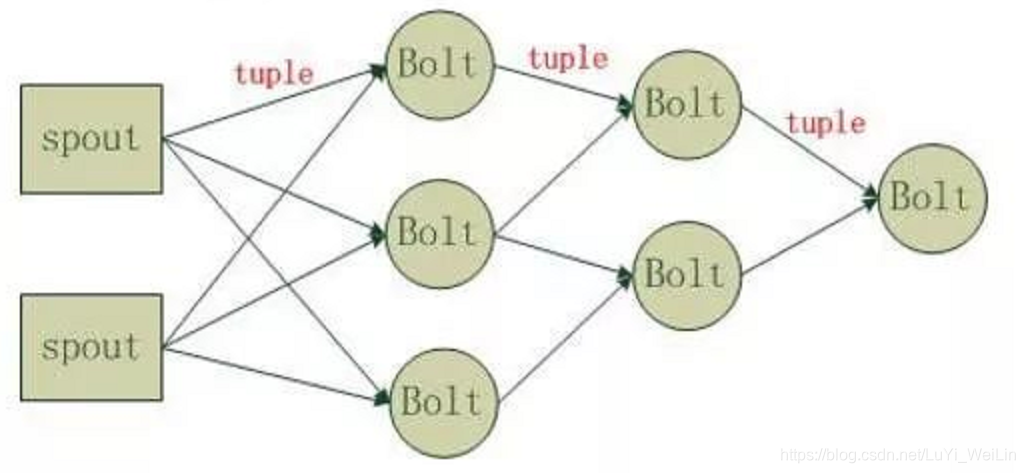
Topology:Storm中執行的一個實時應用程式的名稱。將 Spout、 Bolt整合起來的拓撲圖。定義了 Spout和 Bolt的結合關係、併發數量、配置等等。
Spout:在一個topology中獲取源資料流的元件。通常情況下spout會從外部資料來源中讀取資料,然後轉換為topology內部的源資料。
Bolt:接受資料然後執行處理的元件,使用者可以在其中執行自己想要的操作。
Tuple:一次訊息傳遞的基本單元,理解為一組訊息就是一個Tuple。
Stream:Tuple的集合。表示資料的流向。
四、Topology執行
在Storm中,一個實時應用的計算任務被打包作為Topology釋出,這同Hadoop的MapReduce任務相似。但是有一點不同的是:在Hadoop中,MapReduce任務最終會執行完成後結束;而在Storm中,Topology任務一旦提交後永遠不會結束,除非你顯示去停止任務。計算任務Topology是由不同的Spouts和Bolts,通過資料流(Stream)連線起來的圖。一個Storm在叢集上執行一個Topology時,主要通過以下3個實體來完成Topology的執行工作:
(1). Worker(程序)
(2). Executor(執行緒)
(3). Task
下圖簡要描述了這3者之間的關係:
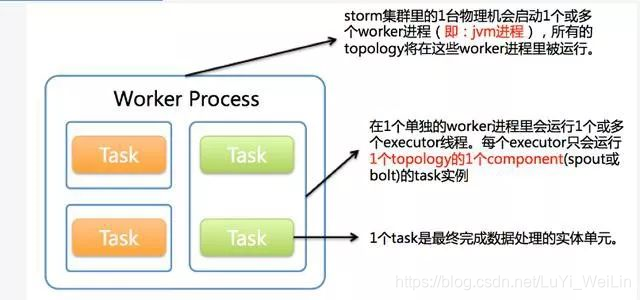
1個worker程序執行的是1個topology的子集(注:不會出現1個worker為多個topology服務)。1個worker程序會啟動1個或多個executor執行緒來執行1個topology的component(spout或bolt)。因此,1個執行中的topology就是由叢集中多臺物理機上的多個worker程序組成的。
executor是1個被worker程序啟動的單獨執行緒。每個executor只會執行1個topology的1個component(spout或bolt)的task(注:task可以是1個或多個,storm預設是1個component只生成1個task,executor執行緒裡會在每次迴圈裡順序呼叫所有task例項)。
task是最終執行spout或bolt中程式碼的單元(注:1個task即為spout或bolt的1個例項,executor執行緒在執行期間會呼叫該task的nextTuple或execute方法)。topology啟動後,1個component(spout或bolt)的task數目是固定不變的,但該component使用的executor執行緒數可以動態調整(例如:1個executor執行緒可以執行該component的1個或多個task例項)。這意味著,對於1個component存在這樣的條件:#threads<=#tasks(即:執行緒數小於等於task數目)。預設情況下task的數目等於executor執行緒數目,即1個executor執行緒只執行1個task。
總體的Topology處理流程圖為:

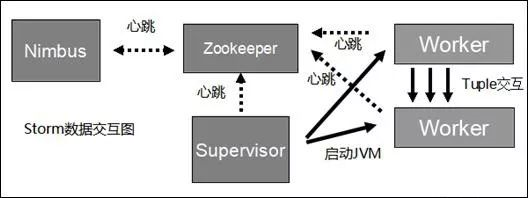
下圖是Storm的資料互動圖,可以看出兩個模組Nimbus和Supervisor之間沒有直接互動。狀態都是儲存在Zookeeper上,Worker之間通過Netty傳送資料。Storm與Zookeeper之間的互動過程,暫時不細說了。重要的一點:storm所有的元資料資訊儲存在Zookeeper中!
五、Storm Streaming Grouping
Storm中最重要的抽象,應該就是Stream grouping了,它能夠控制Spot/Bolt對應的Task以什麼樣的方式來分發Tuple,將Tuple發射到目的Spot/Bolt對應的Task
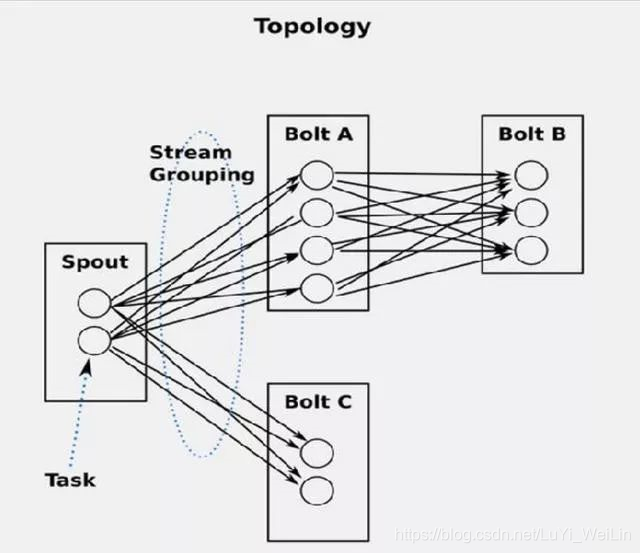
目前,Storm Streaming Grouping支援如下幾種型別:
Shuffle Grouping :隨機分組,儘量均勻分佈到下游Bolt中
將流分組定義為混排。這種混排分組意味著來自Spout的輸入將混排,或隨機分發給此Bolt中的任務。shuffle grouping對各個task的tuple分配的比較均勻。
Fields Grouping :按欄位分組,按資料中field值進行分組;相同field值的Tuple被髮送到相同的Task
這種grouping機制保證相同field值的tuple會去同一個task,這對於WordCount來說非常關鍵,如果同一個單詞不去同一個task,那麼統計出來的單詞次數就不對了。“if the stream is grouped by the “user-id” field, tuples with the same “user-id” will alwaysGo to the same task”. —— 小示例
All grouping :廣播
廣播發送, 對於每一個tuple將會複製到每一個bolt中處理。
Global grouping :全域性分組,Tuple被分配到一個Bolt中的一個Task,實現事務性的Topology。
Stream中的所有的tuple都會發送給同一個bolt任務處理,所有的tuple將會發送給擁有最小task_id的bolt任務處理。
None grouping :不分組
不關注並行處理負載均衡策略時使用該方式,目前等同於shuffle grouping,另外storm將會把bolt任務和他的上游提供資料的任務安排在同一個執行緒下。
Direct grouping :直接分組 指定分組
由tuple的發射單元直接決定tuple將發射給那個bolt,一般情況下是由接收tuple的bolt決定接收哪個bolt發射的Tuple。這是一種比較特別的分組方法,用這種分組意味著訊息的傳送者指定由訊息接收者的哪個task處理這個訊息。 只有被宣告為Direct Stream的訊息流可以宣告這種分組方法。而且這種訊息tuple必須使用emitDirect方法來發射。訊息處理者可以通過TopologyContext來獲取處理它的訊息的taskid (OutputCollector.emit方法也會返回taskid)。
另外,Storm還提供了使用者自定義Streaming Grouping介面,如果上述Streaming Grouping都無法滿足實際業務需求,也可以自己實現,只需要實現backtype.storm.grouping.CustomStreamGrouping介面,該介面重定義瞭如下方法:
List chooseTasks(int taskId, List values)
上面幾種Streaming Group的內建實現中,最常用的應該是Shuffle Grouping、Fields Grouping、Direct Grouping這三種,使用其它的也能滿足特定的應用需求。
六、可靠性
(1)、spout的可靠性
spout會記錄它所發射出去的tuple,當下遊任意一個bolt處理失敗時spout能夠重新發射該tuple。在spout的nextTuple()傳送一個tuple時,為實現可靠訊息處理需要給每個spout發出的tuple帶上唯一ID,並將該ID作為引數傳遞給SpoutOutputCollector的emit()方法:collector.emit(new Values(“value1”,“value2”), tupleID);
實際上Values extends ArrayList
保障過程中,每個bolt每收到一個tuple,都要向上遊應答或報錯,在tuple樹上的所有bolt都確認應答,spout才會隱式呼叫ack()方法表明這條訊息(一條完整的流)已經處理完畢,將會對編號ID的訊息應答確認;處理報錯、超時則會呼叫fail()方法。
(2)、bolt的可靠性
bolt的可靠訊息處理機制包含兩個步驟:
a、當發射衍生的tuple,需要錨定讀入的tuple
b、當處理訊息時,需要應答或報錯
可以通過OutputCollector中emit()的一個過載函式錨定或tuple:collector.emit(tuple, new Values(word)); 並且需要呼叫一次this.collector.ack(tuple)應答。
JavaWeb基礎SSM
首先簡單介紹一下SSM是什麼
Spring
Spring是一個開源框架,Spring是於2003 年興起的一個輕量級的Java 開發框架,由Rod Johnson 在其著作Expert One-On-One J2EE Development and Design中闡述的部分理念和原型衍生而來。它是為了解決企業應用開發的複雜性而建立的。Spring使用基本的JavaBean來完成以前只可能由EJB完成的事情。然而,Spring的用途不僅限於伺服器端的開發。從簡單性、可測試性和鬆耦合的角度而言,任何Java應用都可以從Spring中受益。 簡單來說,Spring是一個輕量級的控制反轉(IoC)和麵向切面(AOP)的容器框架。
SpringMVC
Spring MVC屬於SpringFrameWork的後續產品,已經融合在Spring Web Flow裡面。Spring MVC 分離了控制器、模型物件、分派器以及處理程式物件的角色,這種分離讓它們更容易進行定製。
其中:DispatcherServlet分發器程式、HandlerMapping對映處理器、ViewResolver檢視解析器這些只需要配置就可以,我們只需要寫controller控制器、View檢視即可

MyBatis
MyBatis 本是apache的一個開源專案iBatis, 2010年這個專案由apache software foundation 遷移到了google code,並且改名為MyBatis 。MyBatis是一個基於Java的持久層框架。iBATIS提供的持久層框架包括SQL Maps和Data Access Objects(DAO)MyBatis 消除了幾乎所有的JDBC程式碼和引數的手工設定以及結果集的檢索。MyBatis 使用簡單的 XML或註解用於配置和原始對映,將介面和 Java 的POJOs(Plain Old Java Objects,普通的 Java物件)對映成資料庫中的記錄。
目標:可以利用Maven整合SSM框架
大家可以參考:https://blog.csdn.net/gebitan505/article/details/44455235/
Scala基礎
首先,為什麼要學習scala語言,因為spark絕大部分底層原始碼是scala編寫的。後期我們會學習到spark,所以要掌握相關的scala基礎。
Scala 是一種有趣的語言。它一方面吸收繼承了多種語言中的優秀特性,一方面又沒有拋棄 Java 這個強大的平臺,它執行在 Java 虛擬機器 (Java Virtual Machine) 之上,輕鬆實現和豐富的 Java 類庫互聯互通。它既支援面向物件的程式設計方式,又支援函數語言程式設計。它寫出的程式像動態語言一樣簡潔,但事實上它確是嚴格意義上的靜態語言。Scala 就像一位武林中的集大成者,將過去幾十年計算機語言發展歷史中的精萃集於一身,化繁為簡,為程式設計師們提供了一種新的選擇。
scala相關知識點,大家可以參考(後期會補上相關scala基礎的部落格):
https://blog.csdn.net/caiandyong/article/details/49276369
Spark
Spark是整個BDAS的核心元件,是一個大資料分散式程式設計框架,不僅實現了MapReduce的運算元map 函式和reduce函式及計算模型,還提供更為豐富的運算元,如filter、join、groupByKey等。是一個用來實現快速而同用的叢集計算的平臺。
Spark將分散式資料抽象為彈性分散式資料集(RDD),實現了應用任務排程、RPC、序列化和壓縮,併為執行在其上的上層元件提供API。其底層採用Scala這種函式式語言書寫而成,並且所提供的API深度借鑑Scala函式式的程式設計思想,提供與Scala類似的程式設計介面。
spark相關基礎大家可以參考:
https://blog.csdn.net/vinfly_li/article/details/79396821