
Hadoop2.7.3 mapreduce(五)詳解
一、為什麼使用Mapreduce?
MapReduce是為了解決傳統HPC框架在面對海量資料時擴充套件困難而產生的。
MapReduce致力於解決大規模資料處理的問題,利用區域性性原理將整個問題分而治之。 MapReduce叢集由普通PC機構成,為無共享式架構。在處理之前,將資料集分佈至各個節點。處理時,每個節點就近讀取本地儲存的資料處理(Map),將處理後的資料進行合併(Combine)、排序(Shuffle and Sort)後再分發(至Reduce節點),避免了大量資料的傳輸,提高了處理效率。無共享式架構的另一個好處是配合複製(Replication)策略,叢集可以具有良好的容錯性,一部分節點的宕機對叢集的正常工作不會造成影響。
MapReduce提供了一種平行計算的模型
二、MapReduce的優點
1. 易於程式設計
將所有並行程式均需要關注的設計細節抽象成公共模組並交由系統實現,而使用者只需專注於自己的應用程式邏輯實現,這樣簡化了分散式程式設計且提高了開發效率。
2. 良好的擴充套件性
通過新增機器以達到線性擴充套件叢集能力的目的。
3. 高容錯性
在分散式環境下,隨著叢集規模的增加,叢集中的故障率(這裡的“故障”包括磁碟損壞、機器宕機、節點間通訊失敗等硬體故障和壞資料或者使用者程式Bug產生的軟體故障)會顯著增加,進而導致任務失敗和資料丟失的可能性增加。 Hadoop 通過計算遷移或者資料遷移等策略提高叢集的可用性與容錯性。
三、MapReduce的缺點
1. 延時較高
不適應實時應用的需求。
2. 對隨機訪問的處理能力不足
其是一種線性的程式設計模型。適用於順序處理資料。
四、MapReduce的組成
1. 程式設計模型
MapReduce為使用者提供了非常易用的程式設計介面,使用者只需要考慮如何使用MapReduce模型描述問題,實現幾個簡單的hook函式即可實現一個分散式程式;
MapReduce可程式設計元件
MapReduce提供了5個可程式設計元件,如下圖所示,實際上可程式設計元件全部屬於回撥介面。當用戶按照約定實現這幾個介面後,MapReduce執行時環境會自動呼叫以實現使用者定製的效果。
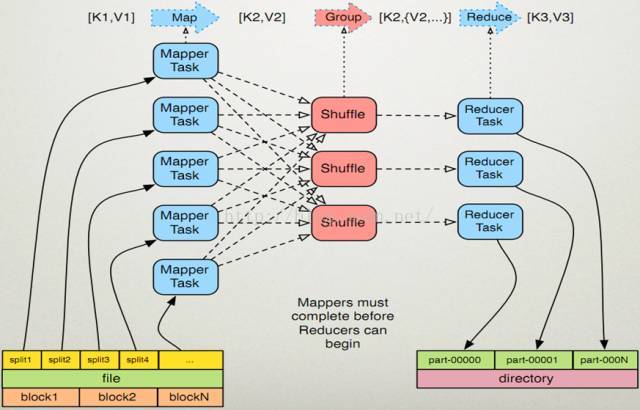
(1)InputFormat:主要用於描述輸入資料的格式,其按照某個策略將輸入資料切分成若干個Split,併為Mapper提供輸入資料,將Split解析成一個個Key/Value對
(2)Mapper:對Split傳入的key1/value1對進行處理,產生新的鍵值key2/value2對。 即Map:(k1,v1) → (k2,v2) 。
(3)Partitioner:作用是對Mapper產生的中間結果進行分割槽,以便將Key有耦合關係的資料交給同一個Reducer處理,它直接影響Reduce階段的負載均衡。
(4)Reducer:以Map的輸出作為輸入,對其進行排序和分組,再進行處理產生新的資料集。即Reducer:(k2,list(v2)) → (k3, v3)。
(5)OutputFormat:主要用於描述輸出資料的格式,它能夠將使用者提供的Key/Value對寫入特定格式的檔案中。
程式設計模型執行流程
(1)作業提交後 InputFormat按照既定策略將輸入資料切分成若干個Split;
(2)各Map任務節點上根據分配的Split元資訊獲取相應資料並將其迭代解析成一個個key1/value1對;
(3)迭代的key1/value1對由Mapper處理為新的key2/value2對;
(4)新的key2/value2對先進行排序,然後由Partitioner將有耦合關係的資料分到同一個Reducer上進行處理,中間資料存入本地磁碟;
(5)各Reduce任務節點根據到已有的Map節點上遠端獲取資料(只獲取屬於該Reduce的資料,該過程稱為Shuffle);
(6)對資料進行排序,並進行分組(將相同Key的資料分為一組);
(7)迭代Key/Value對,並由Reducer合併處理為新的key3/value3對;
(8)新的key3/value3對由OutputFormat儲存到輸出檔案中。
2. 資料處理引擎
由MapTask和ReduceTask組成,分別負責Map階段邏輯和Reduce階段邏輯的處理;
MapReduce資料處理引擎
在MapReduce計算框架中, 一個Job被劃分成Map和Reduce兩個計算階段,它們分別由多個Map Task和Reduce Task組成。 這兩種服務構成了MapReduce資料處理引擎。如下圖所示:
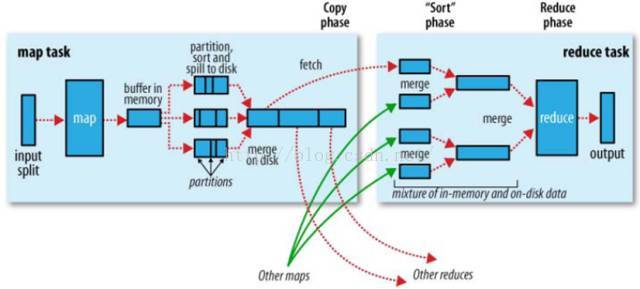
MapTask的整體計算流程共分為5個階段:
1. Read 階段
MapTask通過使用者編寫的RecordReader,從輸入InputSplit中解析出一個個Key/Value;
2. Map 階段
將解析出的Key/Value交給使用者編寫的Map函式處理,併產生一系列新的Key/Value;
3. Collect 階段
Map函式生成的Key/Value通過呼叫Partitioner進行分片,並寫入一個環形記憶體緩衝區中;
4. Spill階段
即"溢寫",當環形緩衝區滿後,MapReduce會將資料寫到本地磁碟上, 生成一個臨時檔案;
5. Combine階段
所有資料處理完成後,MapTask對所有臨時檔案進行一次合併, 以確保最終只會生成一個數據檔案。
Reduce Task的整體計算流程共分為5個階段:
1. Shuffle階段
Reduce Task從各個Map Task上遠端拷貝一片資料,並針對某一片資料,如其大小超過一定閾值則寫到磁碟上,否則直接放到記憶體中;
2. Merge階段
在遠端拷貝資料的同時,Reduce Task啟動了三個後臺執行緒對記憶體和磁碟上的檔案進行合併,以防止記憶體使用過多或磁碟上檔案過多;
3. Sort階段
採用了基於排序的策略將Key相同的資料聚在一起.由於各個Map Task已經實現對自己的處理結果進行了區域性排序,因此Reduce Task只需對所有資料進行一次歸併排序即可;
4. Reduce階段
將每組資料依次交給使用者編寫的Reduce函式處理;
5. Write階段
Reduce函式將計算結果寫到HDFS上。
3. 執行時環境
用以執行MapReduce程式,並行程式執行的諸多細節,如分發、合併、同步、監測等功能均交由執行框架負責,使用者無須關心這些細節。
五、MapReduce版本對比
MapReduce 主要分為兩個大版本 MRv1和 MRv2。之所以出現MRv2, 是因為MRv1具有如下的侷限性:
1. 擴充套件性差
在MRvl中,JobTracker同時兼備了資源管理和作業控制兩個功能,這成為系統的一個最大瓶頸,嚴重製約了hadoop叢集擴充套件性(業界總結出MRv1只能支援4000節點主機的上限);
2. 可靠性差
MRvl採用了 Master/Slave結構。其中,Master存在單點故障問題,一旦它出現故障將導致整個叢集不可用;
3. 資源利用率低
MRvl採用了基於槽位的資源分配模型,槽位是一種粗粒度的資源劃分單位,通常一個任務不會用完槽位對應的資源,且其他任務也無法使用這些空閒資源。此外,Hadoop將槽位分為Map Slot和Reduce Slot兩種,且不允許它們之間共享,常常會導致一種槽位資源緊張而另外一種閒置(比如一個作業剛剛提交時,只會執行Map Task,此時Reduce Slot閒置);
4. 無法支援多種計算框架
隨著網際網路高速發展,MapReduce這種基於磁碟的離線計算框架已經不能滿足應用要求,從而出現了一些新的計算框架,包括記憶體計算框架、流式計算框架和迭代式計算框架等,而MRvl不能支援多種計算框架並存。
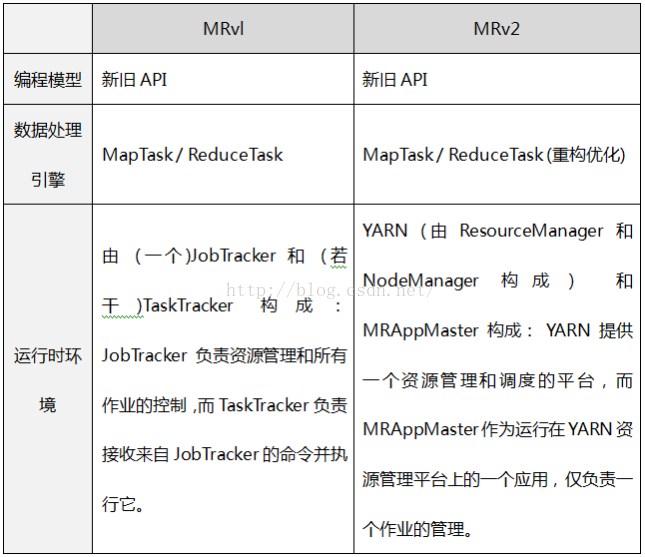
簡言之,MRvl僅是一個獨立的離線計算框架, 而MRv2則是運行於YARN之上的MapReduce應用, 每個作業都有一個應用ApplicationMaster。