
mysql 全表掃描、全索引掃描、索引覆蓋(覆蓋索引)
在執行計劃中是Type列,index
full table scan:通過讀物理表獲取資料,順序讀磁碟上的檔案。這種情況會順序讀磁碟上的檔案。
在執行計劃中是Type列,all
covering index:覆蓋索引,如果where條件的列和返回的資料在一個索引中,那麼不需要回查表,那麼就叫覆蓋索引。
在執行計劃中是extra那一列,using index
full index scan vs full table scan
全索引掃描並不一定就比全表掃描好,取決於資料儲存位置。
如果資料在記憶體,那麼這兩種沒有太大區別。
如果資料在磁碟,全表掃描比全索引掃描要好,這是因為,全表掃描是順序讀資料,sequential read,是順序IO
而全索引掃描,可能會產生隨機讀(reandom read),隨機IO,顯然,順序讀要比隨機讀快很多。
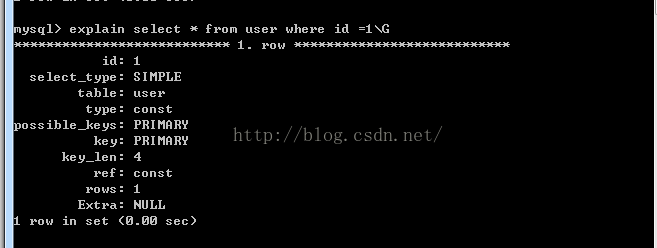
檢視執行計劃的樣例
相關推薦
mysql 在表中新加欄位、修改欄位
新增欄位 在某個欄位之後新加一個欄位: ALTER TABEL xxx ADD column_name VARCHAR(64) NOT NULL DEFAULT '' COMMENT '' AFTER xxx; 修改欄位 ALTER TABEL xxx MODIFY co
mysql 全表掃描、全索引掃描、索引覆蓋(覆蓋索引)
full index scan:全索引掃描,查詢時,遍歷索引樹來獲取資料行。如果資料不是密集的會產生隨機IO 在執行計劃中是Type列,index full table scan:通過讀物理表獲取資料
造成MySQL全表掃描的原因
記錄 添加 its 工程師 review 全表掃描 字段 count 查詢條件 全表掃描是數據庫搜尋表的每一條記錄的過程,直到所有符合給定條件的記錄返回為止。通常在數據庫中,對無索引的表進行查詢一般稱為全表掃描;然而有時候我們即便添加了索引,但當我們的SQL語句寫的不合理的
MyBatis實戰之對映器 SSM框架之批量增加示例(同步請求jsp檢視解析) mybatis的批量更新例項 造成MySQL全表掃描的原因 SSM框架實戰之整合EhCache
對映器是MyBatis最強大的工具,也是我們使用MyBatis時用得最多的工具,因此熟練掌握它十分必要。MyBatis是針對對映器構造的SQL構建的輕量級框架,並且通過配置生成對應的JavaBean返回給呼叫者,而這些配置主要便是對映器,在MyBatis中你可以根據情況定義動態SQL來滿足不同場景的需要,它比
Mysql避免全表掃描的sql查詢優化
對查詢進行優化,應儘量避免全表掃描,首先應考慮在 where 及 order by 涉及的列上建立索引: 嘗試下面的技巧以避免優化器錯選了表掃描: 使用ANALYZE TABLE tbl_
當掃描的資料超過了全表的17%就不使用索引
看到一篇博文說,當查詢掃描的資料超過了全表的20%,優化器就不使用索引,而是做全表掃描。這個我之前還不知道,於是也想測試一下。我的MySQL 版本 5.7.24 。 表結構: mysql> show create table t_1; CREATE TABLE `t_1` (
MySQL查詢優化之避免全表掃描
原文地址:https://dev.mysql.com/doc/refman/5.7/en/table-scan-avoidance.html 譯文: 8.2.1.20 避免全表掃描 當MySQL使用全表掃描來解析查詢時,EXPLAIN的輸出結果中將在type列顯示ALL。這種情況通常發生
索引 vs 全表掃描
之前我們介紹了第一個檔案格式: 在這個檔案格式裡,資料沒有排序,順序儲存,我們只提供了查詢所有資料的介面,當我們想進行值過濾時,比如查詢大於10的資料,需要將所有資料遍歷一遍,如果把這個檔案看做一個只有一列的表,這種查詢方式就叫全表掃描。 磁碟結構和
表裡有索引,為什麼還都是全表掃描?
這是有CBO根據執行計劃的成本決定的 exec dbms_stats.gather_table_stats(ownname='test',tabname=>'dept',cascade=>true); 用/*+ index(table_name index_
Mysql怎麼樣避免全表掃描,sql查詢優化
對查詢進行優化,應儘量避免全表掃描,首先應考慮在 where 及 order by 涉及的列上建立索引: 嘗試下面的技巧以避免優化器錯選了表掃描: 使用ANALYZE TABLE tbl_name為掃描的表更新關鍵字分佈。 對掃描的表使用FORCE INDEX告知My
oracle select 走索引?走全表掃描?
1. 對返回的行無任何限定條件,即沒有where 子句 2. 未對資料表與任何索引主列相對應的行限定條件 例如:在City-State-Zip列建立了三列複合索引,那麼僅對State列限定條件不能使用這個索引,因為State不是索引的主列。 3. 對索引的主列有限定條件,但是在條件表示式裡使用以下表達式
oracle 全表掃描和索引掃描
1) 全表掃描(Full Table Scans, FTS) 為實現全表掃描,Oracle讀取表中所有的行,並檢查每一行是否滿足語句的WHERE限制條件。Oracle順序地讀取分配給表的每個資料塊,直到讀到表的最高水線處(high water mark, HWM
mysql-優化-避免全表掃描
對查詢進行優化,應儘量避免全表掃描,首先應考慮在 where 及 order by 涉及的列上建立索引: 嘗試下面的技巧以避免優化器錯選了表掃描:使用ANALYZE TABLE tbl_name為掃描的表更新關鍵字分佈。對掃描的表使用FORCE INDEX告知MySQL,相對
避免全表掃描的sql優化
設計 結束 edate bstr 需要 表達 大量數據 第一個 關鍵字 摘抄自:http://www.cnblogs.com/jameslif/p/6406167.html 對查詢進行優化,應盡量避免全表掃描,首先應考慮在where 及order by 涉及的列上建立索引
ORACLE sql調優之記錄一次trim函數引發的大表全表掃描
oracle trim 全表掃描 sql 調優 2017年8月14日,一地市oracle相關的調度程序ETL抽取速度奇慢,sql語句每次執行平均時間要9秒左右,如果所示:該調度過程涉及的sql語句如下:select count(*) from (SELECT rtrim(
項目owner看這裏,MaxCompute全表掃描新功能,給你“失誤”的機會
業務需求 機會 表數據 人的 人員 做了 設置 cli ssi 摘要: MaxCompute發布了“ALIAS 命令”,提供了在不修改代碼的前提下,在MapReduce或自定義函數(UDF) 代碼中,通過某個固定的資源名讀取不同資源(數據)的需求。隨著社會數據收集手段的不斷
關係型資料庫全表掃描分片詳解
導讀:資料匯流排(DBus)專注於資料的實時採集與實時分發,可以對IT系統在業務流程中產生的資料進行匯聚,經過轉換處理後成為統一JSON的資料格式(UMS),提供給不同資料使用方訂閱和消費,充當數倉平臺、大資料分析平臺、實時報表和實時營銷等業務的資料來源。在上一篇關於DBus的文章中,我們主要介紹了在DBus
Oracle 檢查資料庫有哪些表頻繁進行全表掃描
select a.object_name, a.sql_id, b.sql_text, max(b.executions) executions, max(b.last_active_time) last_active_time, b.first_load_time from v$sql_plan a,
8、mysql資料庫多表查詢(資料並集、內連線、左連結、右連結、全連線)
目錄 1 內連線 場景:A和B資料 的交集 2 左連結 場景1:得到 “AB交集後和A“ 的並集 (得到A的所有資料+滿足某一條件的B的資料) 場景2:得到A減去AB的交集 (A中所有資料減去同時滿足B某一條件的資料) 3 右連結 場景1:得到“A
scala操作Hbas -全表掃描
package com.blm.util import javax.ws.rs.core.Response.Status.Family import org.apache.hadoop.hbase.{CellUtil, HBaseConfiguration, TableName} im