
影象配準】基於灰度的模板匹配演算法(一):MAD、SAD、SSD、MSD、NCC、SSDA、SATD演算法
簡介:
本文主要介紹幾種基於灰度的影象匹配演算法:平均絕對差演算法(MAD)、絕對誤差和演算法(SAD)、誤差平方和演算法(SSD)、平均誤差平方和演算法(MSD)、歸一化積相關演算法(NCC)、序貫相似性檢測演算法(SSDA)、hadamard變換演算法(SATD)。下面依次對其進行講解。
MAD演算法
介紹
平均絕對差演算法(Mean Absolute Differences,簡稱MAD演算法),它是Leese在1971年提出的一種匹配演算法。是模式識別中常用方法,該演算法的思想簡單,具有較高的匹配精度,廣泛用於影象匹配。
設S(x,y)是大小為mxn的搜尋影象,T(x,y)

演算法思路
在搜尋圖S中,以(i,j)為左上角,取MxN大小的子圖,計算其與模板的相似度;遍歷整個搜尋圖,在所有能夠取到的子圖中,找到與模板圖最相似的子圖作為最終匹配結果。
MAD演算法的相似性測度公式如下。顯然,平均絕對差D(i,j)越小,表明越相似,故只需找到最小的D(i,j)即可確定能匹配的子圖位置:
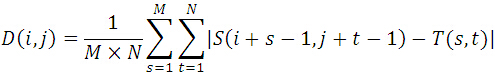
其中:
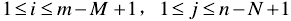
演算法評價:
優點:
①思路簡單,容易理解(子圖與模板圖對應位置上,灰度值之差的絕對值總和,再求平均,實質:是計算的是子圖與模板圖的L1
②運算過程簡單,匹配精度高。
缺點:
①運算量偏大。
②對噪聲非常敏感。
——————————————————————————————————————————————————————————————————————————————
SAD演算法
介紹
絕對誤差和演算法(Sum of Absolute Differences,簡稱SAD演算法)。實際上,SAD演算法與MAD演算法思想幾乎是完全一致,只是其相似度測量公式有一點改動(計算的是子圖與模板圖的L1距離),這裡不再贅述。
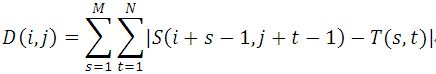
演算法實現
由於文章所介紹的幾個演算法非常相似,所以本文僅列出SAD
MATLAB程式碼
- %%
- %絕對誤差和演算法(SAD)
- clear all;
- close all;
- %%
- src=imread('lena.jpg');
- [a b d]=size(src);
- if d==3
- src=rgb2gray(src);
- end
- mask=imread('lena_mask.jpg');
- [m n d]=size(mask);
- if d==3
- mask=rgb2gray(mask);
- end
- %%
- N=n;%模板尺寸,預設模板為正方形
- M=a;%代搜尋影象尺寸,預設搜尋影象為正方形
- %%
- dst=zeros(M-N,M-N);
- for i=1:M-N %子圖選取,每次滑動一個畫素
- for j=1:M-N
- temp=src(i:i+N-1,j:j+N-1);%當前子圖
- dst(i,j)=dst(i,j)+sum(sum(abs(temp-mask)));
- end
- end
- abs_min=min(min(dst));
- [x,y]=find(dst==abs_min);
- figure;
- imshow(mask);title('模板');
- figure;
- imshow(src);
- hold on;
- rectangle('position',[x,y,N-1,N-1],'edgecolor','r');
- hold off;title('搜尋圖');
輸出結果
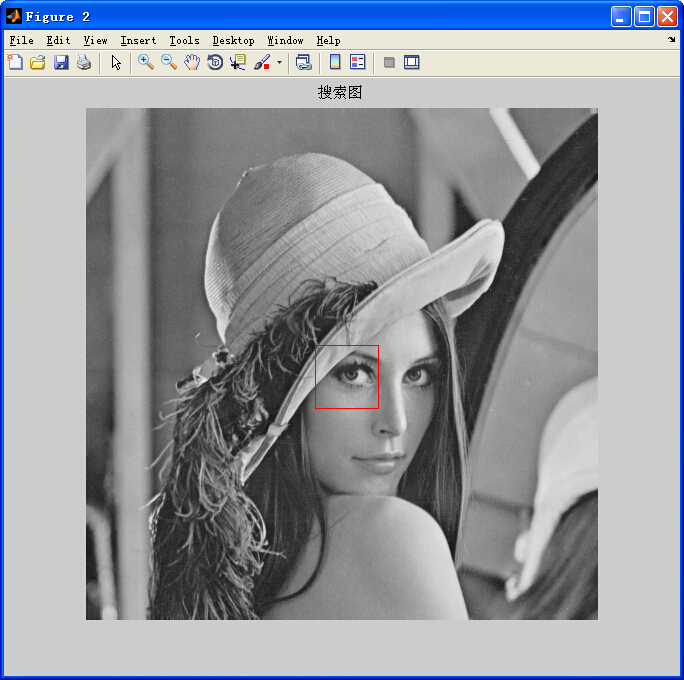
——————————————————————————————————————————————————————————————————————————————
SSD演算法
誤差平方和演算法(Sum of Squared Differences,簡稱SSD演算法),也叫差方和演算法。實際上,SSD演算法與SAD演算法如出一轍,只是其相似度測量公式有一點改動(計算的是子圖與模板圖的L2距離)。這裡不再贅述。
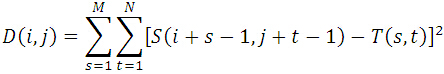
——————————————————————————————————————————————————————————————————————————————
MSD演算法
平均誤差平方和演算法(Mean Square Differences,簡稱MSD演算法),也稱均方差演算法。實際上,MSD之餘SSD,等同於MAD之餘SAD(計算的是子圖與模板圖的L2距離的平均值),故此處不再贅述。
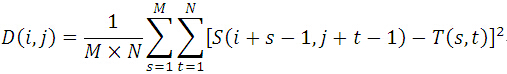
————————————————————————————————————————————————————————————————————————————————
NCC演算法
歸一化積相關演算法(Normalized Cross Correlation,簡稱NCC演算法),與上面演算法相似,依然是利用子圖與模板圖的灰度,通過歸一化的相關性度量公式來計算二者之間的匹配程度。
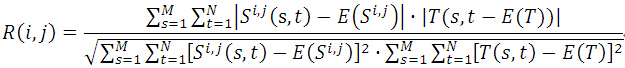
其中,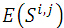

————————————————————————————————————————————————————————————————————————
SSDA演算法
序貫相似性檢測演算法(Sequential Similiarity Detection Algorithm,簡稱SSDA演算法),它是由Barnea和Sliverman於1972年,在文章《A class of algorithms for fast digital image registration》中提出的一種匹配演算法,是對傳統模板匹配演算法的改進,比MAD演算法快幾十到幾百倍。
與上述演算法假設相同:S(x,y)是mxn的搜尋圖,T(x,y)是MxN的模板圖,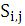
顯然: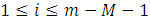

SSDA演算法描述如下:
①定義絕對誤差:
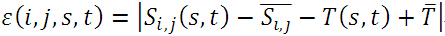
其中,帶有上劃線的分別表示子圖、模板的均值:
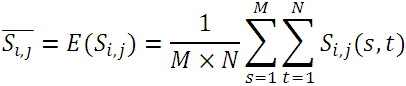

實際上,絕對誤差就是子圖與模板圖各自去掉其均值後,對應位置之差的絕對值。
②設定閾值Th;
③在模板圖中隨機選取不重複的畫素點,計算與當前子圖的絕對誤差,將誤差累加,當誤差累加值超過了Th時,記下累加次數H,所有子圖的累加次數H用一個表R(i,j)來表示。SSDA檢測定義為:
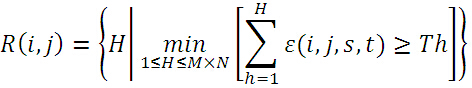
下圖給出了A、B、C三點的誤差累計增長曲線,其中A、B兩點偏離模板,誤差增長得快;C點增長緩慢,說明很可能是匹配點(圖中Tk相當於上述的Th,即閾值;I(i,j)相當於上述R(i,j),即累加次數)。
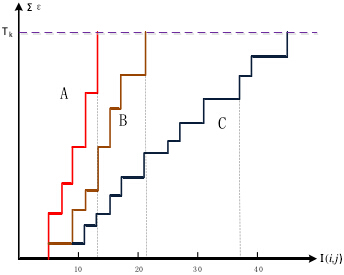
④在計算過程中,隨機點的累加誤差和超過了閾值(記錄累加次數H)後,則放棄當前子圖轉而對下一個子圖進行計算。遍歷完所有子圖後,選取最大R值所對應的(i,j)子圖作為匹配影象【若R存在多個最大值(一般不存在),則取累加誤差最小的作為匹配影象】。
由於隨機點累加值超過閾值Th後便結束當前子圖的計算,所以不需要計運算元圖所有畫素,大大提高了演算法速度;為進一步提高速度,可以先進行粗配準,即:隔行、隔離的選取子圖,用上述演算法進行粗糙的定位,然後再對定位到的子圖,用同樣的方法求其8個鄰域子圖的最大R值作為最終配準影象。這樣可以有效的減少子圖個數,減少計算量,提高計算速度。
——————————————————————————————————————————————————————————————————————
SATD演算法
hadamard變換演算法(Sum of Absolute Transformed Difference,簡稱SATD演算法),它是經hadamard變換再對絕對值求和演算法。hadamard變換等價於把原影象Q矩陣左右分別乘以一個hadamard變換矩陣H。其中,hardamard變換矩陣H的元素都是1或-1,是一個正交矩陣,可以由MATLAB中的hadamard(n)函式生成,n代表n階方陣。
SATD演算法就是將模板與子圖做差後得到的矩陣Q,再對矩陣Q求其hadamard變換(左右同時乘以H,即HQH),對變換都得矩陣求其元素的絕對值之和即SATD值,作為相似度的判別依據。對所有子圖都進行如上的變換後,找到SATD值最小的子圖,便是最佳匹配。
MATLAB實現:
- %//*****************************************
- %//Copyright (c) 2015 Jingshuang Hu
- %//@filename:demo.m
- %//@datetime:2015.08.20
- %//@author:HJS
- %//@e-mail:[email protected]
- %//@blog:http://blog.csdn.net/hujingshuang
- %//*****************************************
- %%
- %//SATD模板匹配演算法-哈達姆變換(hadamard)
- clear all;
- close all;
- %%
- src=double(rgb2gray(imread('lena.jpg')));%//長寬相等的
- mask=double(rgb2gray(imread('lena_mask.jpg')));%//長寬相等的
- M=size(src,1);%//搜尋圖大小
- N=size(mask,1);%//模板大小
- %%
- hdm_matrix=hadamard(N);%//hadamard變換矩陣
- hdm=zeros(M-N,M-N);%//儲存SATD值
- for i=1:M-N
- for j=1:M-N
- temp=(src(i:i+N-1,j:j+N-1)-mask)/256;
- sw=(hdm_matrix*temp*hdm_matrix)/256;
- hdm(i,j)=sum(sum(abs(sw)));
- end
- end
- min_hdm=min(min(hdm));
- [x y]=find(hdm==min_hdm);
- figure;imshow(uint8(mask));
- title('模板');
- figure;imshow(uint8(src));hold on;
- rectangle('position',[y,x,N-1,N-1],'edgecolor','r');
- title('搜尋結果');hold off;
- %//完
輸出結果:

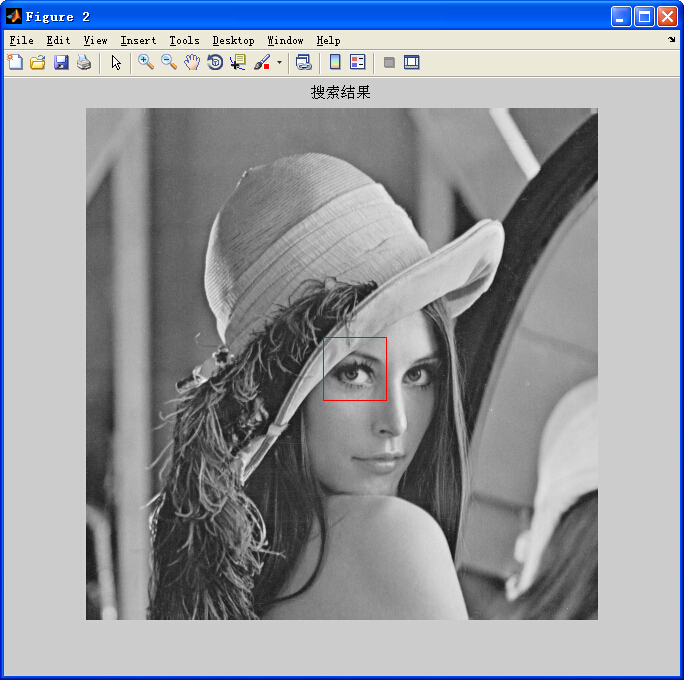
—————————————————————————————————————————————————————————————————————
OK,介紹完畢,以上便是幾種常見的基於灰度的模板匹配演算法。
參考文獻:
2、趙啟, 影象匹配演算法研究[D], 2013.
3、丁慧珍, 抗任意角度旋轉灰度匹配方法研究[D], 2006.
4、陳皓, 馬彩文等, 基於灰度統計的快速模板匹配演算法[J], 光子學報, 2009.
5、楊小岡等, 基於相似度比較的影象灰度匹配演算法研究[J], 系統工程與電子技術, 2005.
相關推薦
影象配準】基於灰度的模板匹配演算法(一):MAD、SAD、SSD、MSD、NCC、SSDA、SATD演算法
簡介: 本文主要介紹幾種基於灰度的影象匹配演算法:平均絕對差演算法(MAD)、絕對誤差和演算法(SAD)、誤差平方和演算法(SSD)、平均誤差平方和演算法(MSD)、歸一化積相關演算法(NCC)、序貫相似性檢測演算法(SSDA)、hadamard變換演算法(
【影象配準】基於灰度的模板匹配演算法(三):劃分強度一致法(PIU)
簡介: 前面幾篇文章介紹了一些比較基本的基於灰度的影象配准算法: 本文將介紹一種類似的相似度測量演算法,叫做劃分強度一致法(Partitioned Intensity Uniformity,PI
【Python-GPU加速】基於Numba的GPU計算加速(一)基本
Numba是一個可以利用GPU/CPU和CUDA 對python函式進行動態編譯,大幅提高執行速度的加速工具包。 利用修飾器@jit,@cuda.jit,@vectorize等對函式進行編譯 JIT:即時編譯,提高執行速度 基於特定資料型別
【Docker】基於例項專案的叢集部署(一)安裝環境搭建
叢集 叢集具有三高特點: 高效能 高負載 高可用 現在的環境中,經常會用到叢集,如資料庫叢集。如,我們在主機上部署資料庫節點,形成叢集。 安裝環境與配置 在Docker中部署叢集,首先要安裝Linux環境,這裡我們使用VMware虛擬機
影象演算法(一):最近鄰插值,雙線性插值,三次插值
最近在複習影象演算法,對於一些簡單的影象演算法進行一個程式碼實現,由於找工作比較忙,具體原理後期補上,先上程式碼。今天先給出最近鄰插值,雙線性插值,三次插值。 1.最近鄰插值 原始圖中影響點數為1 (1)程式碼 # include<iostream>
【caffe】在windows平臺中安裝caffe(一):基礎安裝及簡單測試
基礎配置 本文中的配置:win10 + vs2015 + python2.5 + cmake3.12 + git2.15 + CUDA8.0 + cuDNN-8.0-5 在進行windows下的caffe安裝前,一定要把以上的這些軟體安裝好,並加入系統路徑中。
重拾演算法(一):演算法效率分析(空間複雜度和時間複雜度)
前言: 演算法效率分析分為兩種:第一種是時間效率,第二種是空間效率。時間效率被稱為時間複雜度,而空間效率被稱作空間複雜度。 時間複雜度主要衡量的是一個演算法的執行速度,而空間複雜度主要衡量一個演算法所需要的額外空間,在計算機發展的早期,計算機的儲存容量很小。所以對空間複雜
【Unity3D基礎教程】給初學者看的Unity教程(一):GameObject,Compoent,Time,Input,Physics
Unity3D重要模組的類圖 最近剛剛完成了一個我個人比較滿意的小專案:【深入Cocos2d-x】使用MVC架構搭建遊戲Four,在這個遊戲中,我使用了自己搭建的MVC架構來製作一個遊戲,做到了比較好的SoC(關注點分離)。但是苦於Cocos2d-x沒有一個比較完善的編輯器,所以我開始學習另一個非常流行
【怎樣寫程式碼】函數語言程式設計 -- Lambda表示式(一):引出
如果喜歡這裡的內容,你能夠給我最大的幫助就是轉發,告訴你的朋友,鼓勵他們一起來學習。 If you like the content here, you can give me the greatest help is forwarding, tell you
【三星官方教程】如何為Gear VR 開發應用(一):開發環境搭建(轉)
三星GearVR已經成為第一個成熟的移動VR平臺,並擁有目前全球最大也是最穩定的移動VR使用者群體。基於GearVR的應用越來越多,本文將為開發者介紹如何用Unity為Gear VR開發一個360度圖片檢視器。 搭建開發環境(Windows OS) 在開始用Uni
資料結構與演算法(一):帶你瞭解時間複雜度和空間複雜度到底是什麼?
1. 前言 演算法(Algorithm)是指用來操作資料、解決程式問題的一組方法。對於同一個問題,使用不同的演算法,也許最終得到的結果是一樣的,但在過程中消耗的資源和時間卻會有很大的區別。那麼我們應該如何去衡量不同演算法之間的優劣呢? 主要還是從演算法所佔用的「時間」和「空間」兩個維度去考量。 時間
基於sinc的音訊重取樣(一):原理
我在前面的文章《音訊開原始碼中重取樣演算法的評估與選擇 》中說過sinc方法是較好的音訊重取樣方法,缺點是運算量大。https://ccrma.stanford.edu/~jos/resample/ 給出了sinc方法的原理文件和軟體實現。以前是使用這個演算法,沒太關注原理和實現細節。去年(2020年)由於專
cuda練習(一):使用cuda將rbg影象轉為灰度影象
建立工程 使用cmake建立工程,CMakeLists.txt如下: cmake_minimum_required(VERSION 2.8) project(image_process) find_package(OpenCV REQUIRED) #會去找F
【轉載】基於rasa的對話系統搭建(上)
生成模型 efi 實體類 total ted twisted -m serve feature 文章介紹使用rasa nlu和 rasa core 實現一個電信領域對話系統demo,實現簡單的業務查詢辦理功能,更完善的實現需要
基於cnn的影象二分類演算法(一)
本演算法是基於tensorflow,使用python語言進行的一種影象分類演算法,參考於谷歌的mnist手寫識別,包括以下幾個模組:影象讀取,影象處理,影象增強。卷積神經網路部分包括:卷積層1,匯合層1(部分文獻也有叫池化層的),卷積層2,匯合層2,全連線層1,全連線層2,共
基於詞彙樹的影象檢索(一):詞彙樹
從今天起準備把我的畢設的實現細節寫到部落格裡面,一方面寫一遍加深記憶,另一方面如果哪天忘記了查起來也方便 畢設題目是基於詞彙樹的無序影象集檢索和支撐結構生成,其實提出詞彙樹那篇文章(Scalable Recognition with a Vocabulary Tree[1
【Docker】基於例項專案的叢集部署(三)Linux基礎命令
Linux系統作為優秀的企業級伺服器系統,有多處優點: 可靠的安全性 良好的穩定性 完善的網路功能 多使用者任務 豐富的軟體支援 跨平臺的硬體支援 目錄結構 我們可以通過以下結構瞭解Linux的目錄作用: 命令操作
【Docker】基於例項專案的叢集部署(二)部署專案例項介紹與搭建
部署專案簡介 我們要部署的專案是人人網的一個基於前後端分離的專案:renren-fast。 你可以在這裡對該專案進行下載,並對相關介紹文件進行了解: https://www.renren.io/community/project https://www.renren.io/guide
【NLP】基於機器學習角度談談CRF(三)
作者:白寧超 2016年8月3日08:39:14 【摘要】:條件隨機場用於序列標註,資料分割等自然語言處理中,表現出很好的效果。在中文分詞、中文人名識別和歧義消解等任務中都有應用。本文源於筆者做語句識別序列標註過程中,對條件隨機場的瞭解,逐步研究基於自然語言處理方面的應用。成文主要源於自然語言處理
【C++】基於“stringstream+getline”實現字串分割(split)
哇... 最近在練習C++程式設計,遇到一個題目需要用到字串分割(類似python的split函式)。C++並沒有提供關於這個函式的功能,所以要自己實現。 就在此時,看到字串流 stringstream 這個高階的類,功能非常強大,如數字與字串之間的轉換。 本文只介紹基於“