
Intellij搭建spark開發環境
spark怎麼學習呢?在一無所知的前提下,首先去官網快速瞭解一下spark是幹什麼的,官網在此。然後,安裝開發環境,從wordcount開始學習。第三,上手以後可以學習其他演算法了。最後,不要放棄,繼續深入學習。
那麼,首先解決的就是如何搭建開發環境的問題。
1、確保你的電腦安裝了JDK,以及配置了JAVA_HOME環境變數。
2、安裝Intellij IDEA,下載地址。目前15.0版本對Scala的支援性就很好。
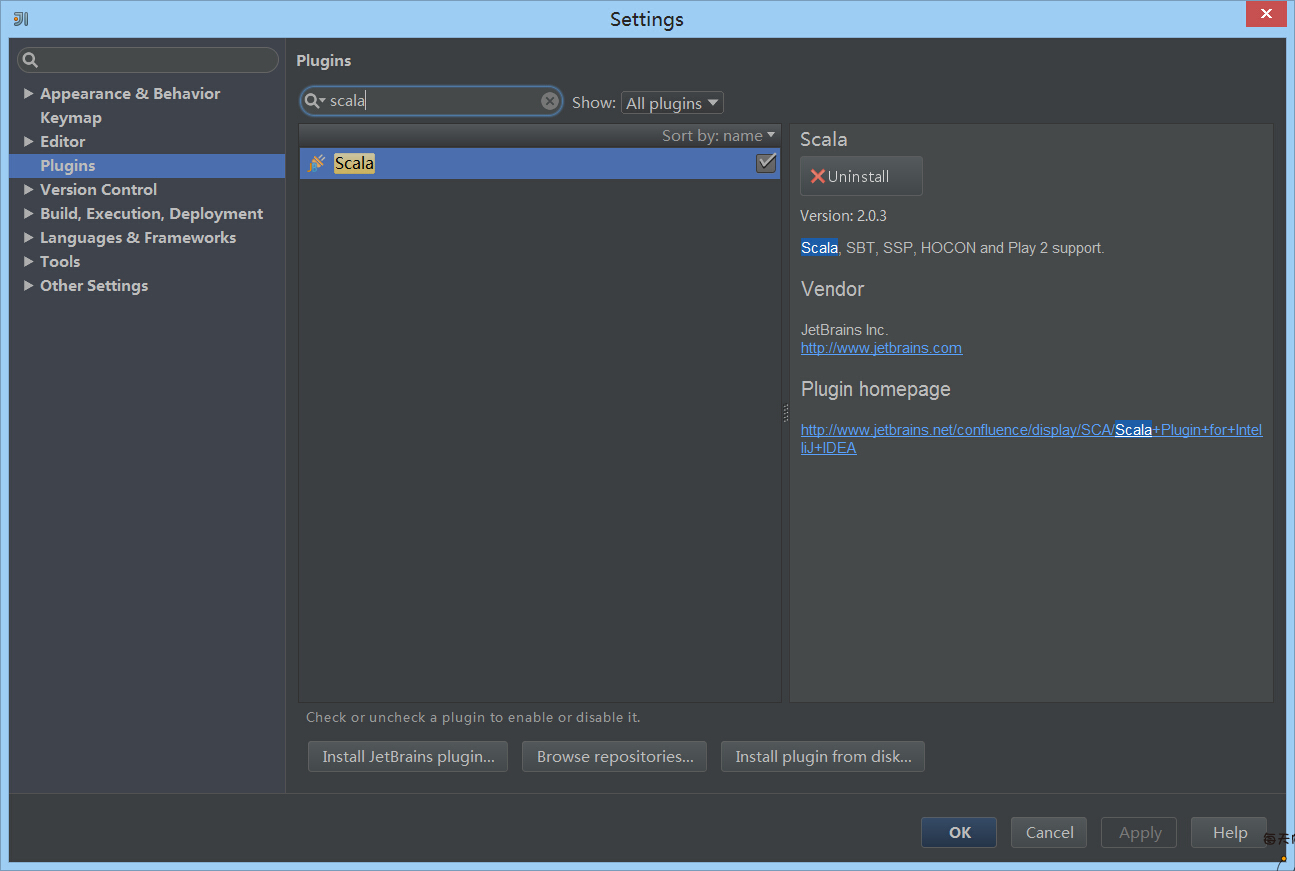
3、安裝scala外掛。在首次使用Intellij的時候會出現安裝外掛的提示,如果錯過了也沒有關係,在setting裡,找到Plugins,輸入scala,安裝即可。
4、搭建spark開發環境。
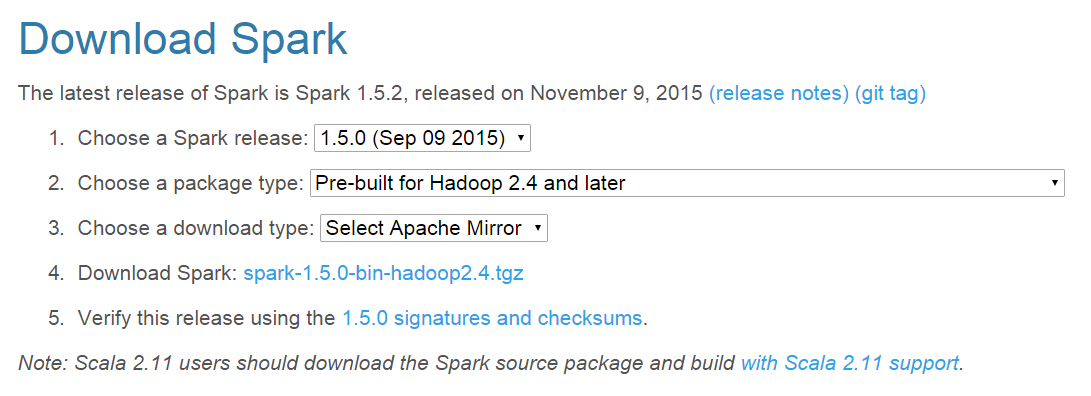
4.1 下載spark的jar包,下載地址。例如我要下載1.5.0版本的spark,hadoop是2.4版本,選項如圖:
4.2 解壓下載的包,我們需要用的是lib下的spark-assembly-1.5.0-hadoop2.4.0.jar這個包。
4.3 新建scala專案,File -> New Project -> scala -> next填寫name和SDK -> finish。
4.4 在專案頁“File” -> “project structure” -> “Libraries”, 點“+”,選java,找到spark-assembly-1.5.0-hadoop2.4.0.jar匯入,這樣就可以編寫spark的scala程式了。
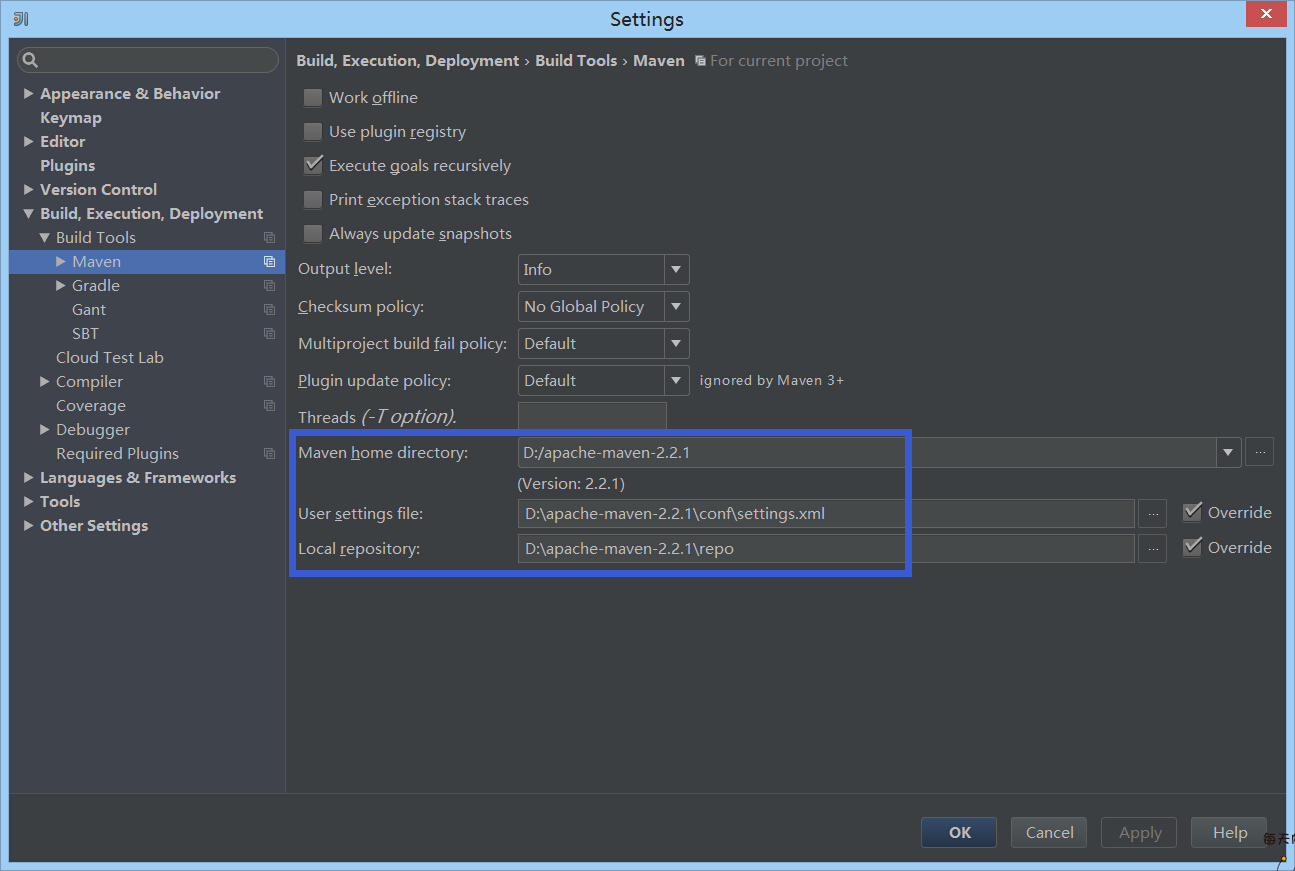
4.5 很多時候我們都需要用到maven或者SBT管理依賴,這裡我用的是maven。Intellij15.0對maven也很有好,只需要簡單配置一下maven倉庫地址即可。
5、開心的coding吧!
插入程式碼
package main.scala
import org.apache.spark.{SparkConf, SparkContext}
object SimpleApp {
def main(args: Array[String]) {
val logFile = "D:/IdeaProjects/spark-test/README.md" // Should be some file on your system 6、打包匯出到叢集執行。
6.1 如果pom.xml檔案中存在hadoop或者spark的依賴,請在打包之前註釋掉。因為叢集已經有包了,註釋掉既能減少包的大小,又能避免某些jar版本衝突。
6.2 Intellij中點選“File - Project Struction - Artifacts - + - Jar - From modules with dependencies…”,填寫modules、Main Class以及路徑等,點選OK生成jar包。
6.3 Intellij中點選“Build- Build artifacts… ”,選擇剛生成的jar包進行build。
6.4 將打包好的jar包上傳到伺服器某路徑下。
6.5 執行提交命令:
spark-submit WhereIsYourJar 其他引數