
查詢:group by和having
現在一使用者表`user`,資料如下:
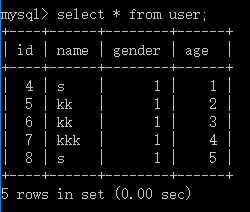
1.查出名稱`name`重複的記錄
mysql> select name, count(*) as name_count from user group by name having name_count > 1;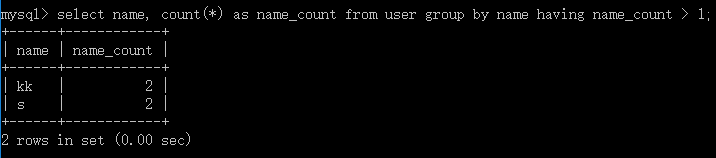
2.查出年齡`age`大於1,名稱`name`有多少種情況,分組:
mysql> select age, name, count(*) as cnt from user where age > 1 group by name;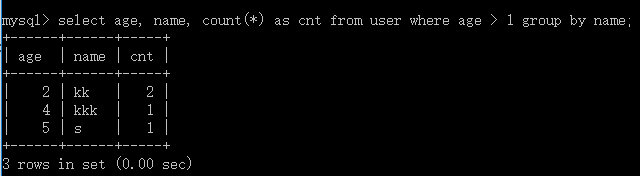
3.查出年齡`age`大於1,名稱`name`重複的記錄
mysql> select age, name, count(*) as cnt from user where age > 1 group by name having cnt > 1;

...
相關推薦
查詢:group by和having
現在一使用者表`user`,資料如下:1.查出名稱`name`重複的記錄mysql> select name, count(*) as name_count from user group by
group by 和 having子句
列名 2010年 article 入職 maximum 標準 imu taf 分組查詢 GROUP BY語法可以根據給定數據列的每個成員對查詢結果進行分組統計,最終得到一個分組匯總表。 select子句中的列名必須為分組列或列函數,列函數對於group by
SQL之group by 和 having
包含 where lan tool 必知必會 平均工資 bin view IT 轉自:mysql必知必會——GROUP BY和HAVING GROUP BY語法可以根據給定數據列的每個成員對查詢結果進行分組統計,最終得到一個分組匯總表。 sele
mysql分組查詢group by 與having
select a.run_id,a.user_id,b.dept_id, count(*) as jishu from flow_run_prcs as a,user as b where a.US
SQL Server的GROUP BY和HAVING子句
在介紹GROUP BY 和 HAVING 子句前,我們必需先講講sql語言中一種特殊的函式:聚合函式,例如SUM, COUNT, MAX, AVG等。這些函式和其它函式的根本區別就是它們一般作用在多條記錄上。 SELECT SUM(population) FROM bbc
Postgresql中的分組函式(group by 和 having)
在通過了WHERE過濾器之後,生成的輸出表可以繼續用GROUP BY 子句進行分組,然後用HAVING子句刪除一些分組行。 Sql程式碼 SELECT select_list FROM ... [WHERE ...] GROUP BY grou
SQL語句中 group by 和 having 的用法
聚合函式:例如SUM, COUNT, MAX, AVG等。這些函式和其它函式的根本區別就是它們一般作用在多條記錄上。 having是分組(group by)後的篩選條件,分組後的資料組內再篩選 where則是在分組前篩選 簡單來說,group by 相當於
SQL語句Group By和Having需要注意的地方
SQL語句Group By、Having Group By語句需要注意的地方 select vend_id,count(*) as num_prods from products group by vend_id; GROUP BY子句可以
sql語句中GROUP BY 和 HAVING的使用 count()
在介紹GROUP BY 和 HAVING 子句前,我們必需先講講sql語言中一種特殊的函式:聚合函式, 例如SUM, COUNT, MAX, AVG等。這些函式和其它函式的根本區別就是它們一般作用在多條記錄上。 SELECT SUM(population) FROM bbc
sql語句中 group by 和 having 的使用
group by name :意為對name進行分組(name表示屬性) group by name having 條件A :意為對name分組後,再根據條件A進行刪選 例子: 表table name course score A
oracle學習筆記(聚合函式以及group by 和having 的用法)
今天學習了聚合函式以及group by 的用法。
SQL系列四——分組(group by和having)
首先,建立資料表如下: 1、資料分組(GROUP BY): SQL中資料可以按列名分組,搭配聚合函式十分實用。 例,統計每個班的人數: SELECT student_class,COUNT(ALL student_name) AS 總人數 FROM t_stud
MySQL——關於MySQL分組查詢group by和order by獲取最新時間內容的方法
假如現在有一張表table,如下: 如果我們想查詢出來zhang和wang最新日期的記錄 如果我們直接使用: SELECT * FROM table GROUP BY name ORDER BY
sql中的group by 和 having 用法解析(張高偉)
--sql中的group by 用法解析: -- Group By語句從英文的字面意義上理解就是“根據(by)一定的規則進行分組(Group)”。 --它的作用是通過一定的規則將一個數據集劃分成若干個小的區域,然後針對若干個小區域進行資料處理。 --注意:group by 是先排序後分組; --舉例子說明:
SQL復雜查詢語句-SELECT * FROM cs WHERE score>70 GROUP BY s_id HAVING COUNT(*)>1
規範 des 刪除索引 表數 _id 需求 null rop 其他 如果同時存在where,group by,的時候的執行順序應該是這樣的: 1,首先where後面添加條件把數據進行了過濾,返回一個結果集 2,然後group by將上面返回的結果集進行分組,返回一個結果集
MYSQL查詢語句 group by 與having count()講解--玉米都督
在介紹GROUP BY 和 HAVING 子句前,我們必需先講講sql語言中一種特殊的函式:聚合函式, 例如SUM, COUNT, MAX, AVG等。這些函式和其它函式的根本區別就是它們一般作用在多條記錄上。 SELECT S
【Mysql】利用group by附帶having進行聚類查詢
聚類查詢所針對的物件是表的其中一列,譬如如下的testtable表,要查出username這一列中,各個項所出現的次數,則用到聚類查詢 顯然,聚類查詢之後,得到的結果必須與id,number這兩列半點關係都沒有。因此,也就是正如上門,所說,聚類查詢所針對的物件是表的其中一
資料庫查詢去重group by和distinct的理解
前言 在使用mysql時,有時需要查詢出某個欄位不重複的記錄,雖然mysql提供 有distinct這個關鍵字來過濾掉多餘的重複記錄只保留一條,但往往只用它來返回不重複記錄的條數,而不是用它來返回不重記錄的所有值。其原因是 distinct只能返回它的目標欄位
group by, where, having的使用方法和之間區別
select 後的欄位,必須要麼包含在group by中,要麼包含在having後的聚合函式裡。(?) 1、group by是分組查詢,一般group by是和聚合函式配合使用 group by有一個原則,就是select後面的所有列中,沒有使用聚合函式的列,必
GROUP BY 和 ORDER BY一起使用時,要註意的問題!
聚合 pan csdn under line order 註意 net asp 轉:http://blog.csdn.net/haiross/article/details/38897835 註意:ORDER BY 子句中的列必須包含在聚合函數或 GROUP BY 子句中。