
Python Numpy計算各類距離
詳細:
1.閔可夫斯基距離(Minkowski Distance)
2.歐氏距離(Euclidean Distance)
3.曼哈頓距離(Manhattan Distance)
4.切比雪夫距離(Chebyshev Distance)
5.夾角餘弦(Cosine)
6.漢明距離(Hamming distance)
7.傑卡德相似係數(Jaccard similarity coefficient)
8.貝葉斯公式
(1)閔氏距離的定義:
兩個n維變數A(x11,x12,…,x1n)與 B(x21,x22,…,x2n)間的閔可夫斯基距離定義為:
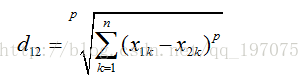
其中p是一個變引數。
當p=1時,就是曼哈頓距離
當p=2時,就是歐氏距離
當p→∞時,就是切比雪夫距離
根據變引數的不同,閔氏距離可以表示一類的距離。
np.linalg.norm #是適合使用這個公式2.歐氏距離(Euclidean Distance)
歐氏距離(L2範數)是最易於理解的一種距離計算方法,源自歐氏空間中兩點間的距離公式(如圖1.9)。
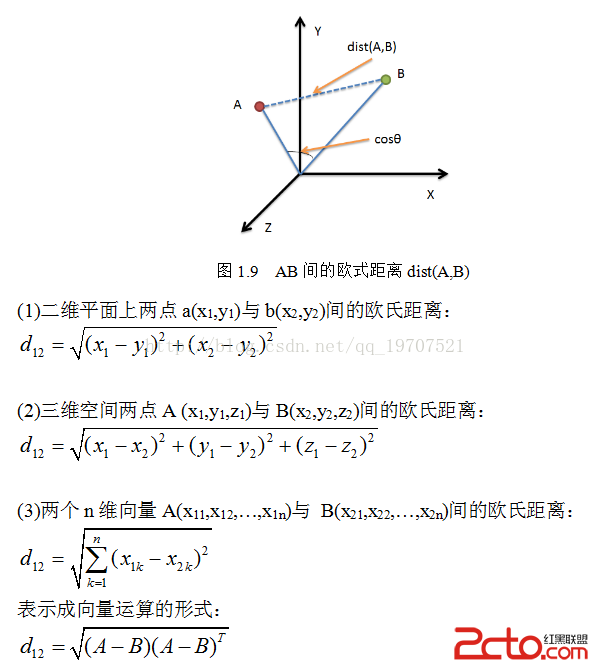
(4) python實現歐式距離公式的:
vector1 = np.array([1,2,3]) vector2 = np.array([4,5,6]) op1=np.sqrt(np.sum(np.square(vector1-vector2))) op2=np.linalg.norm(vector1-vector2) print(op1) print(op2) #輸出: #5.19615242271 #5.19615242271
3.曼哈頓距離(Manhattan Distance)
從名字就可以猜出這種距離的計算方法了。想象你在曼哈頓要從一個十字路口開車到另外一個十字路口,駕駛距離是兩點間的直線距離嗎?顯然不是,除非你能穿越大樓。實際駕駛距離就是這個“曼哈頓距離”(L1範數)。而這也是曼哈頓距離名稱的來源,曼哈頓距離也稱為城市街區距離(City Block distance)(如圖1.10)。
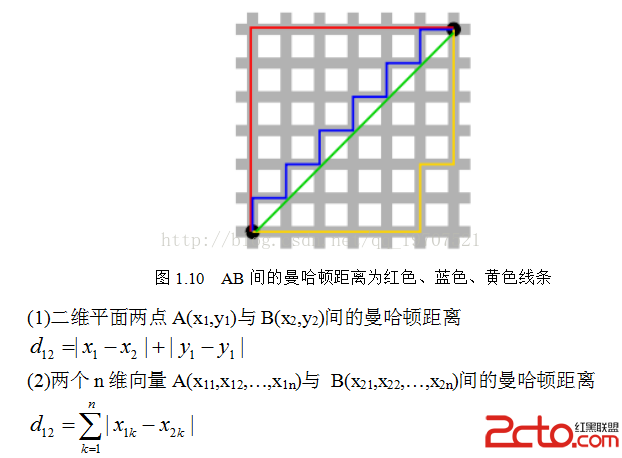
vector1 = np.array([1,2,3]) vector2 = np.array([4,5,6]) op3=np.sum(np.abs(vector1-vector2)) op4=np.linalg.norm(vector1-vector2,ord=1) #輸出 #9 #9.0
4.切比雪夫距離(Chebyshev Distance)
國際象棋玩過麼?國王走一步能夠移動到相鄰的8個方格中的任意一個(如圖1.11)。那麼國王從格子(x1,y1)走到格子(x2,y2)最少需要多少步?自己走走試試。你會發現最少步數總是max(| x2-x1| , |y2-y1| ) 步。有一種類似的一種距離度量方法叫切比雪夫距離(L∞範數)。
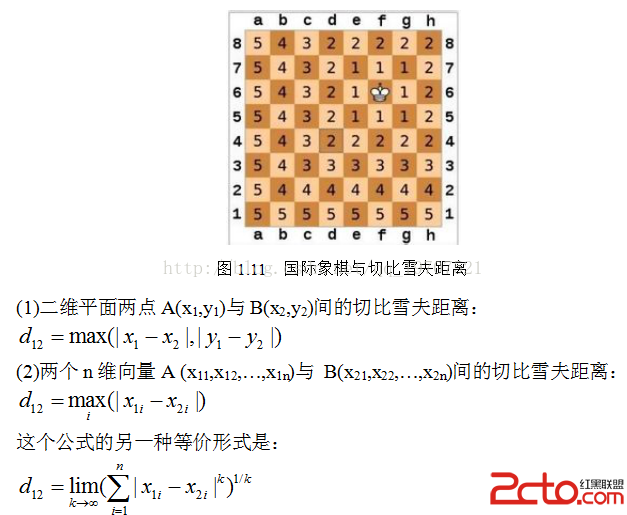
(3) Python實現切比雪夫距離:
vector1 = np.array([1,2,3])
vector2 = np.array([4,7,5])
op5=np.abs(vector1-vector2).max()
op6=np.linalg.norm(vector1-vector2,ord=np.inf)
print(op5)
print(op6)
#輸出:
#5
#5.05. 夾角餘弦(Cosine)
幾何中夾角餘弦可用來衡量兩個向量方向的差異,機器學習中借用這一概念來衡量樣本向量之間的差異(如圖1.12)。
(1)在二維空間中向量A(x1,y1)與向量B(x2,y2)的夾角餘弦公式:
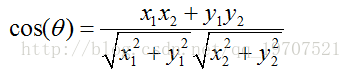
(2) 兩個n維樣本點A (x11,x12,…,x1n)與 B(x21,x22,…,x2n)的夾角餘弦
類似的,對於兩個n維樣本點A(x11,x12,…,x1n)與 B(x21,x22,…,x2n),可以使用類似於夾角餘弦的概念來衡量它們間的相似程度。
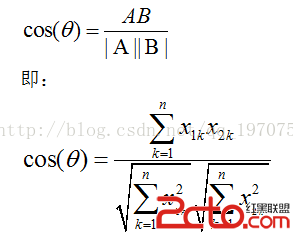
夾角餘弦取值範圍為[-1,1]。夾角餘弦越大表示兩個向量的夾角越小,夾角餘弦越小表示兩向量的夾角越大。當兩個向量的方向重合時夾角餘弦取最大值1,當兩個向量的方向完全相反夾角餘弦取最小值-1。
(3)python實現夾角餘弦
vector1 = np.array([1,2,3])
vector2 = np.array([4,7,5])
op7=np.dot(vector1,vector2)/(np.linalg.norm(vector1)*(np.linalg.norm(vector2)))
print(op7)
#輸出
#0.929669680201
6. 漢明距離(Hamming distance)
(1)漢明距離的定義
兩個等長字串s1與s2之間的漢明距離定義為將其中一個變為另外一個所需要作的最小替換次數。例如字串“1111”與“1001”之間的漢明距離為2。
應用:資訊編碼(為了增強容錯性,應使得編碼間的最小漢明距離儘可能大)。
(2) python實現漢明距離:
v1=np.array([1,1,0,1,0,1,0,0,1])
v2=np.array([0,1,1,0,0,0,1,1,1])
smstr=np.nonzero(v1-v2)
print(smstr) # 不為0 的元素的下標
sm= np.shape(smstr[0])[0]
print( sm )
#輸出
#(array([0, 2, 3, 5, 6, 7]),)
#6
7. 傑卡德相似係數(Jaccard similarity coefficient)
(1) 傑卡德相似係數
兩個集合A和B的交集元素在A,B的並集中所佔的比例,稱為兩個集合的傑卡德相似係數,用符號J(A,B)表示。
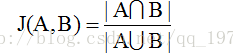
(2) 傑卡德距離
與傑卡德相似係數相反的概念是傑卡德距離(Jaccard distance)。傑卡德距離可用如下公式表示:
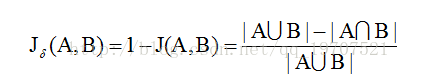
傑卡德距離用兩個集合中不同元素佔所有元素的比例來衡量兩個集合的區分度。
(3) 傑卡德相似係數與傑卡德距離的應用
可將傑卡德相似係數用在衡量樣本的相似度上。
樣本A與樣本B是兩個n維向量,而且所有維度的取值都是0或1。例如:A(0111)和B(1011)。我們將樣本看成是一個集合,1表示集合包含該元素,0表示集合不包含該元素。
P:樣本A與B都是1的維度的個數
q:樣本A是1,樣本B是0的維度的個數
r:樣本A是0,樣本B是1的維度的個數
s:樣本A與B都是0的維度的個數
那麼樣本A與B的傑卡德相似係數可以表示為:
這裡p+q+r可理解為A與B的並集的元素個數,而p是A與B的交集的元素個數。
而樣本A與B的傑卡德距離表示為:
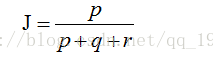
(4) Python實現傑卡德距離:
import scipy.spatial.distance as dist
v1=np.array([1,1,0,1,0,1,0,0,1])
v2=np.array([0,1,1,0,0,0,1,1,1])
matv=np.array([v1,v2])
print(matv)
ds=dist.pdist(matv,'jaccard')
print(ds)
#輸出
#[[1 1 0 1 0 1 0 0 1] [0 1 1 0 0 0 1 1 1]]
# [ 0.75]8. 經典貝葉斯公式
原: P(AB)=P(A | B)·P(B)=P(B | A)·P(A)
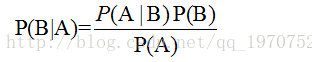
本例,我們不去研究黃色的蘋果與黃色的梨有什麼差別。而承認其統計規律:蘋果是紅色的概率是0.8,蘋果是黃色的概率就是1-0.8=0.2,而梨是黃色的概率是0.9,將其作為先驗概率。有了這個先驗概率,就可以利用抽樣,即任取一個水果,前提是抽樣對總體的概率分佈沒有影響,通過它的某個特徵來劃分其所屬的類別。黃色是蘋果和梨共有的特徵,因此,既有可能是蘋果也有可能是梨,概率計算的意義在於得到這個水果更有可能的那一種。
條件: 10個蘋果10個梨子
用數學的語言來表達,就是已知:
# P(蘋果)=10/(10+10),P(梨)=10/(10+10),P(黃色|蘋果)=20%,P(黃色|梨)=90%,P(黃色)= 20% * 0.5 + 90% * 0.5 = 55%# = P(黃色|梨)P(梨)/P(黃色)
# = 81.8%