
gensim的word2vec如何得出詞向量(python)
首先需要具備gensim包,然後需要一個語料庫用來訓練,這裡用到的是skip-gram或CBOW方法,具體細節可以去查查相關資料,這兩種方法大致上就是把意思相近的詞對映到詞空間中相近的位置。
語料庫test8下載地址:
這個語料庫是從http://blog.csdn.net/m0_37681914/article/details/73861441這篇文章中找到的。
檢查語料是否需要做預處理:
將資料下載好了解壓出來,在做詞向量之前我們需要了解資料的儲存結構,判斷它是否滿足gensim包裡word2vec函式對輸入資料的形式要求。word2vec函式的輸入最好是一整篇文字,不含標點符號以及換行符。那麼我們應該檢查test8資料是否符合。然而雙擊開啟test8是行不通的,因為檔案過大。那麼就需要我們用程式開啟它。程式碼如下:
with open('/text8','r',encoding='utf-8') as file:
for line in file.readlines():
print(line)程式會返回警告,記憶體不夠,打印不出來。明顯是因為有一行內容太多導致的。可以進行如下驗證:
with open('/text8','r',encoding='utf-8') as file:
for line in file.readlines():
print(len(line))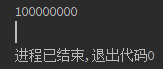
輸出只有一個值,表示資料只有一行,且顯示這一行有100000000個字元長度。由於檔案內資料結構一致,那麼我們沒有必要將資料全部輸出來看,只需要輸出一部分就知道它的資料結構,那麼修改程式碼如下:
a = 0
b = 0
with open('/text8','r',encoding='utf-8') as file:
line = file.read()
for char in line:
b+=1
print(char,end='')
if b-a == 100:
a = b
print('\n')
if a == 5000:
break我們輸出前5000個字元來看看,並且每100個字元換一行。
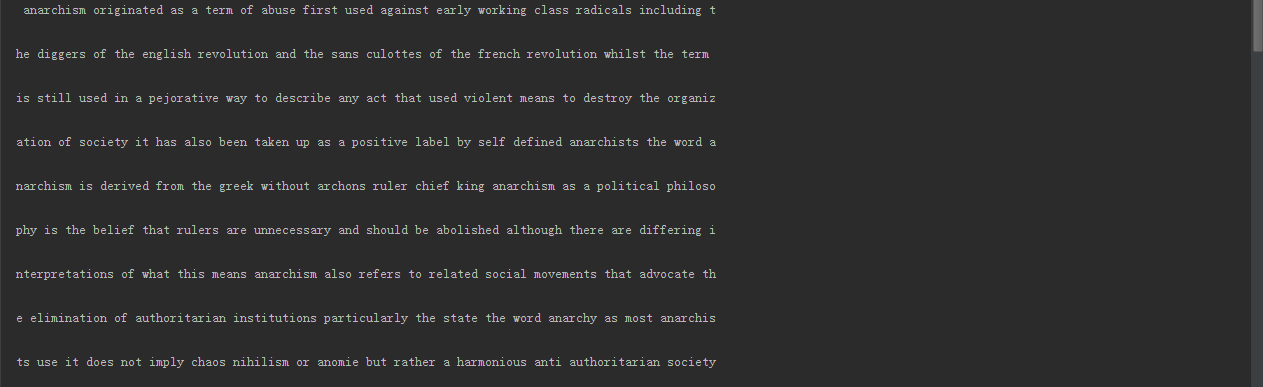
這裡只是開頭一部分,可以看到資料完全沒有標點符號,且之前驗證過所有資料都是在同一行,表示沒有換行符。那麼我們無需對資料進行預處理。接下來是資料處理部分。
資料處理部分:
from gensim.models import word2vec
import logging
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
sentences = word2vec.Text8Corpus('/text8')
model = word2vec.Word2Vec(sentences, sg=1, size=100, window=5, min_count=5, negative=3, sample=0.001, hs=1, workers=4)
model.save('/text82.model')
print(model['man'])logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
這一行表示我們的程式會輸出日誌資訊,形式(format)為日期(asctime):資訊級別(levelname):日誌資訊(message),資訊級別為正常資訊(logging.INFO)。關於logging的知識,大家可以去自行學習。https://www.cnblogs.com/bjdxy/archive/2013/04/12/3016820.html點選開啟連結

上圖就是輸出的日誌資訊。實際工作中,我們也可以不加這個日誌,但這麼做的前提是我們確定程式一定正確,不會出錯,因為一旦出錯我們就需要根據日誌資訊來推斷錯誤發生的可能。
將語料庫儲存在sentence中
sentences = word2vec.Text8Corpus('/text8')
生成詞向量空間模型
model = word2vec.Word2Vec(sentences, sg=1, size=100, window=5, min_count=5, negative=3, sample=0.001, hs=1, workers=4)
這裡講下引數含義:
class gensim.models.word2vec.Word2Vec(sentences=None,size=100,alpha=0.025,window=5, min_count=5,max_vocab_size=None, sample=0.001,seed=1, workers=3,min_alpha=0.0001, sg=0, hs=0, negative=5, cbow_mean=1,hashfxn=<built-in function hash>,iter=5,null_word=0, trim_rule=None, sorted_vocab=1, batch_words=10000)引數:1.sentences:可以是一個List,對於大語料集,建議使用BrownCorpus,Text8Corpus或·ineSentence構建。2.sg: 用於設定訓練演算法,預設為0,對應CBOW演算法;sg=1則採用skip-gram演算法。3.size:是指輸出的詞的向量維數,預設為100。大的size需要更多的訓練資料,但是效果會更好. 推薦值為幾十到幾百。4.window:為訓練的視窗大小,8表示每個詞考慮前8個詞與後8個詞(實際程式碼中還有一個隨機選視窗的過程,視窗大小<=5),預設值為5。5.alpha: 是學習速率6.seed:用於隨機數發生器。與初始化詞向量有關。
7.min_count: 可以對字典做截斷. 詞頻少於min_count次數的單詞會被丟棄掉, 預設值為5。8.max_vocab_size: 設定詞向量構建期間的RAM限制。如果所有獨立單詞個數超過這個,則就消除掉其中最不頻繁的一個。每一千萬個單詞需要大約1GB的RAM。設定成None則沒有限制。
9.sample: 表示 取樣的閾值,如果一個詞在訓練樣本中出現的頻率越大,那麼就越會被取樣。預設為1e-3,範圍是(0,1e-5)10.workers:引數控制訓練的並行數。11.hs: 是否使用HS方法,0表示不使用,1表示使用 。預設為012.negative: 如果>0,則會採用negativesamp·ing,用於設定多少個noise words13.cbow_mean: 如果為0,則採用上下文詞向量的和,如果為1(default)則採用均值。只有使用CBOW的時候才起作用。14.hashfxn: hash函式來初始化權重。預設使用python的hash函式
15.iter: 迭代次數,預設為5。16.trim_rule: 用於設定詞彙表的整理規則,指定那些單詞要留下,哪些要被刪除。可以設定為None(min_count會被使用)或者一個接受()並返回RU·E_DISCARD,uti·s.RU·E_KEEP或者uti·s.RU·E_DEFAU·T的函式。17.sorted_vocab: 如果為1(defau·t),則在分配word index 的時候會先對單詞基於頻率降序排序。18.batch_words:每一批的傳遞給執行緒的單詞的數量,預設為10000
這裡再把生成的空間模型儲存下來,以便下次使用。
model.save('/text8.model')
下次使用就不在需要載入語料庫和生成模型了。只需要:
''' sentences = word2vec.Text8Corpus('/text8') model = word2vec.Word2Vec(sentences, sg=1, size=100, window=5, min_count=5, negative=3, sample=0.001, hs=1, workers=4) model.save('/text8.model') ''' model = word2vec.Word2Vec.load('/text8.model')
最後是檢視某個詞的詞向量:
print(model['man'])
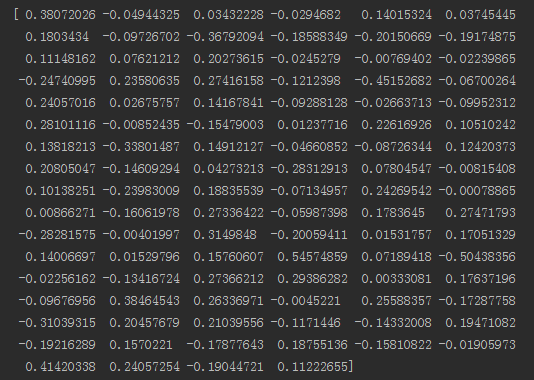
當然model函式還可以做更多的事情,比如檢視兩個詞的相似度等等,想知道的請自行百度