
效能監控總結
目錄
-
1 引言
-
1.1 編寫目的
-
1.2 適用物件和範圍
-
1.3 參考文件
-
2 業務指標監控
-
2.1 監控指標
-
2.2 監控工具
-
3 作業系統指標監控
-
3.1 Linux
-
3.2 Windows
-
4 應用中介軟體指標監控
-
4.1 Tomcat
-
4.2 JBoss
-
4.3 IIS監控
-
4.4 JVM
-
4.5 .NET CLR
-
5 資料庫指標監控
-
5.1 MySQL
-
5.2 SQLServer
-
5.3 MonogoDB
-
5.4 Redis
-
6 前端指標監控
-
6.1 監控指標說明
-
6.2 監控工具
1 引言
1.1 編寫目的
本文件主要目標是規範使用效能測試過程中需監控的各項技術指標,描述各指標項的具體含義,並給出相應的監控工具與方法說明。本文件將作為測試監控的指導性規範,用以選取監控關注指標,使用監控工具。
1.2 適用物件和範圍
監控指標及監控工具適用於使用效能測試進行效能測試專案技術質量評價依據。 預期讀者為測試管理人員、測試實施人員、技術支援人員、專案質量管理人員、專案管理人員等系統技術質量相關人員。
1.3 參考文件
相關的指標定義及解釋可以參照:
2 業務指標監控
2.1 監控指標
業務指標主要包括併發使用者數、響應時間、處理能力,成功率這四個指標,目前大部分壓測工具都能將這些指標放在壓測工具裡面。
2.2 監控工具
2.2.1 效能測試
效能測試分散式壓測工具,將相關業務指標整合在平臺上。
2.2.2 後臺日誌
通過後臺日志log,採用分析工具也可進行分析得出TPS,響應時間等。
3 作業系統指標監控
3.1 Linux
3.1.1 監控指標說明
| 指標型別 | 指標名稱 | 指標描述 |
|---|---|---|
| CPU | CPU utilization | CPU 的使用時間百分比 |
| System mode CPU utilization | 在系統模式下使用 CPU 的時間百分比 | |
| User mode CPU utilization | 在使用者模式下使用 CPU 的時間百分比 | |
| Memory | Page-in rate | 每秒鐘讀入到實體記憶體中的頁數 |
| Page-out rate | 每秒鐘寫入頁面檔案和從實體記憶體中刪除的頁數 | |
| Paging rate | 每秒鐘讀入實體記憶體或寫入頁面檔案的頁數 | |
| Disk | Disk rate | 磁碟傳輸速率 |
3.1.2 監控工具
3.1.2.1 效能測試
效能測試壓測工具監控作業系統指標主要有:
CPU%:所有CPU資源利用率
網路流量:每秒入網出網多少Kb
磁碟:每秒讀寫多少Kb
3.1.2.2 命令
Linux提供豐富的命令進行監控,針對CPU、Memory、I/O等有一些列命令及引數進行監控。具體如下:
top : 整體檢視資源情況。
sar :CPU資源消耗
vmstat:記憶體相關消耗
iostat: 磁碟相關消耗
………
具體用法和引數,可以參照聯機幫助(man top等)。
3.1.2.3 Shell
可以將以上命令通過shell來包裝,每隔多少秒監控一次,總共監控多少次,將監控結果寫到檔案裡面。
例如:下面shell就是將CPU Load每隔3秒寫到檔案裡面。
while true ; do uptime | awk -F' average: ' '{print $2}' ;sleep 3;done >> `hostname`_`date +%Y%m%d_%H%M`.uptime
3.1.2.4 nmon
-
Nmon安裝 將 nmonXXX.tar.gz 檔案複製到計算機。如果使用 FTP,請記住使用二進位制模式。
解壓該檔案,執行 gzip -d nmonXXX.tar.gz
提取該檔案,執行tar xvf nmonXXX.tar -
Nmon實時監控 登陸要監控的系統,進入nmon安裝目錄中
輸入命令nmon,執行 nmon(如root使用者可能需要輸入./nmon).顯示的起始螢幕及CPU等資訊。如圖:
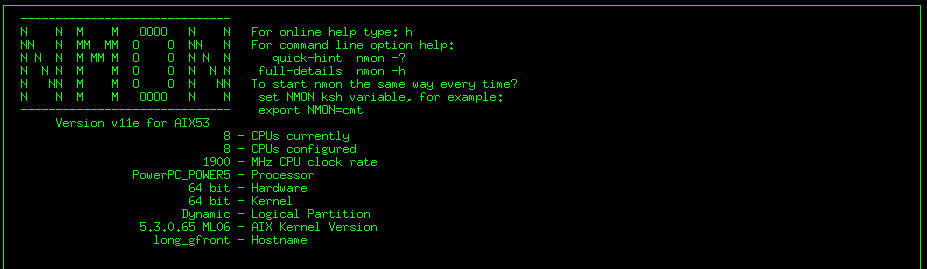
依次按c,m,d即可顯示CPU,記憶體,磁碟等資訊。如圖:
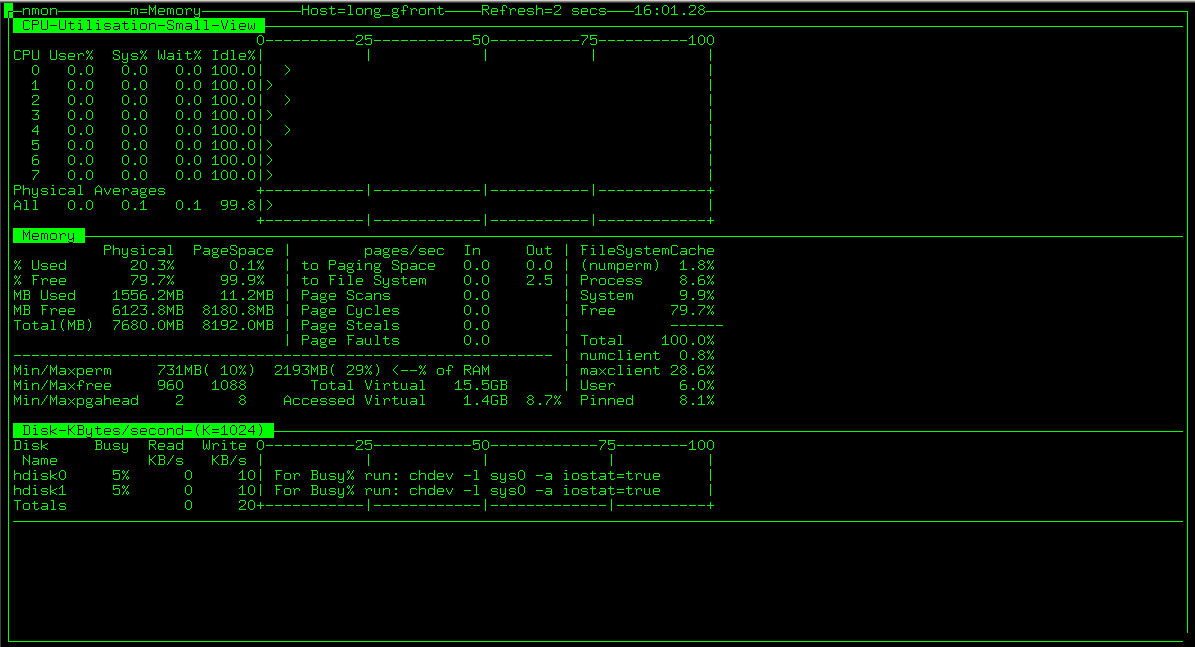
Nmon執行時的鍵盤命令
| 命令 | 說明 |
|---|---|
| c | 提供關於物理CPU使用的詳細資訊 |
| m | 提供記憶體使用的詳細資訊:系統(核心)和程序,活動虛擬記憶體 |
| d | 提供關於磁碟,磁碟型別大小,可用空間,卷組,介面卡等更詳細的資訊 |
| t | 當前程序詳細情 |
| P | Paging space 使用情況 |
| k | 顯示核心資訊 |
| + | Nmon 結果儲存為檔案 |
- Nmon 結果儲存為檔案 nmon -f -s 60 -c 30(每60s收集一次資料,共收集30次) nmon.sh 賦執行許可權:chmod +x nmon.sh 執行nmon.sh 即可執行.
3.2 Windows
3.2.1 監控指標說明
提供的監控指標比較豐富,包括CPU、記憶體、網路、磁碟以及每個程序的資源。
3.2.2 監控工具
3.2.2.1 效能測試
同3.1.2.1 效能測試
3.2.2.2 資源管理器
Windows作業系統自帶的windows資源管理器,在工作列裡面點選右鍵,啟動工作管理員:
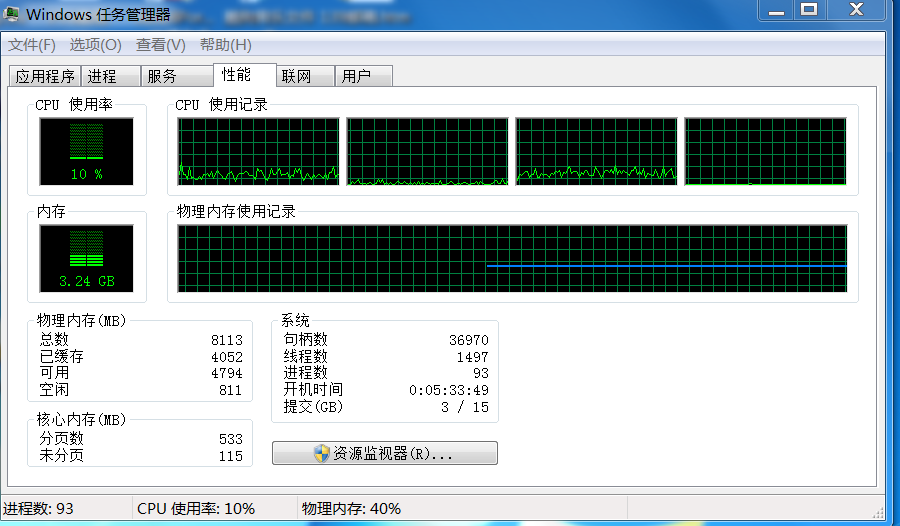
點選效能面板,再點選資源監視器:
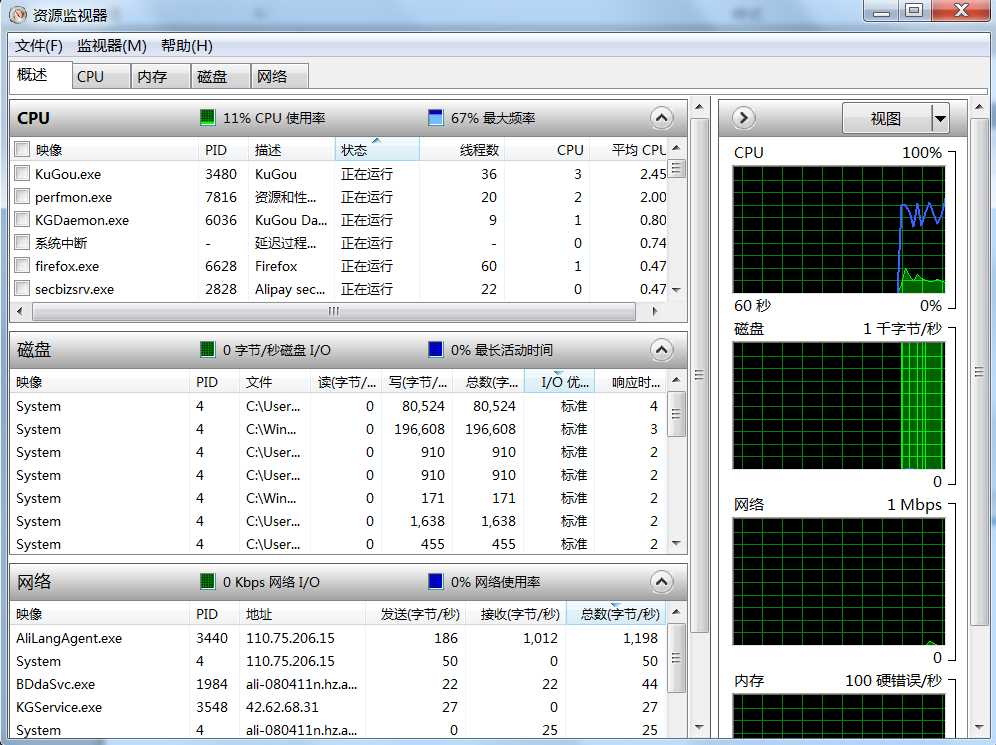
3.2.2.3 效能監視器
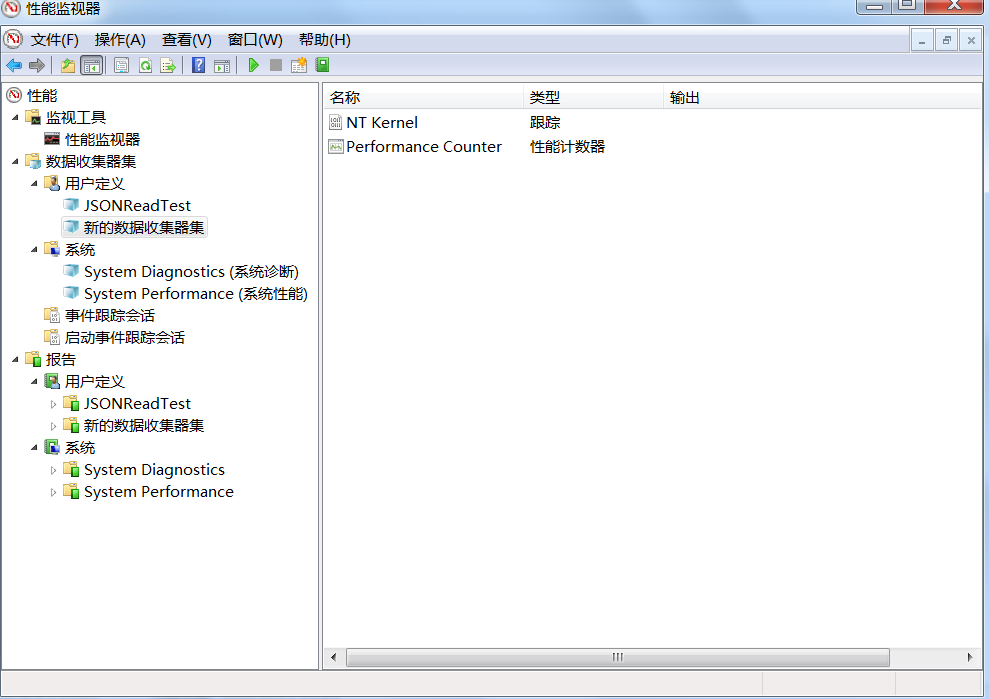
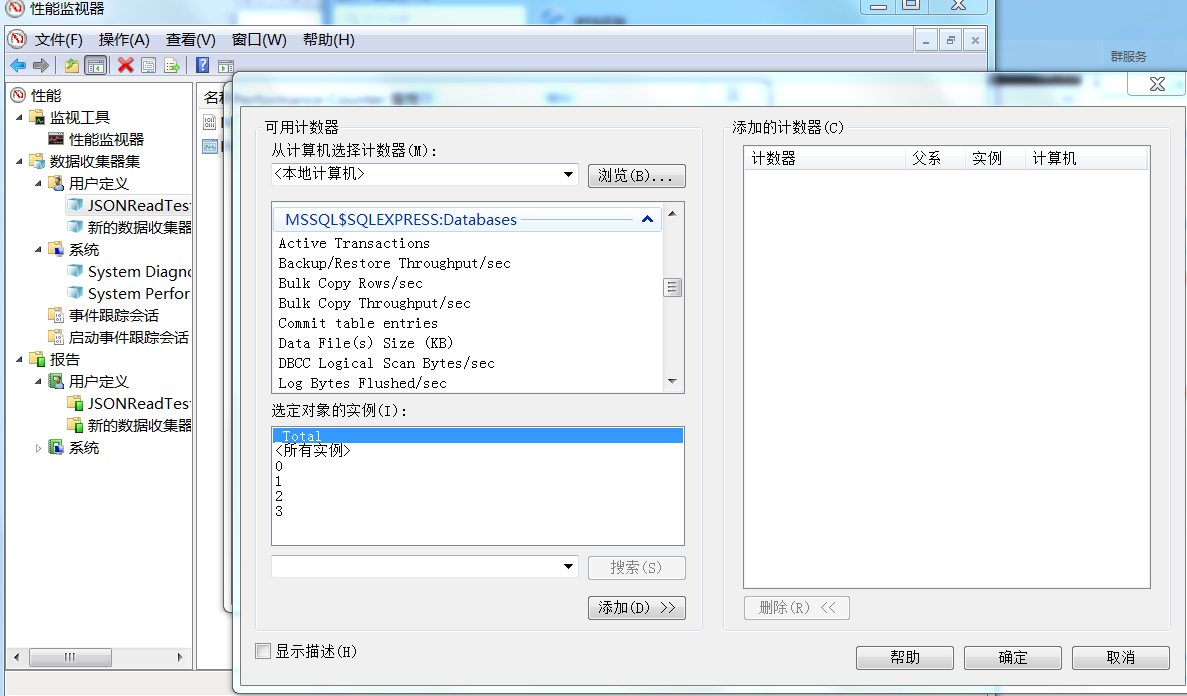
Windows有自帶的效能監視器,可以指定相關的監控指標進行監控,將結果儲存為檔案,從windows控制面板->管理工具->效能監視器->新建資料蒐集器,新增你感興趣的指標計數器。
4 應用中介軟體指標監控
4.1 Tomcat
4.1.1 監控指標說明
Tomcat主要監控執行緒工作狀態、請求數、 會話數、執行緒數、虛擬主機、JAVA虛擬機器記憶體佔用情況。
4.1.2 監控工具
4.1.2.1 Tomcat提供的manager
通過使用Applications Manager(又稱opManager)來進行監控。
使用這種方式,所監控Tomcat必須執行manager應用,預設情況下,該應用總是執行在伺服器中的。
-
增 加Manager Role: 訪問manager應用的使用者的角色許可權必須是 manager. 修改<TOMCAT_HOME>/conf目錄下的tomcat-users.xml檔案,在<tomcat-users>節點 下新增一個user節點,即可建立一個使用者。Tomcat版本不同配置也有差異,5.x和6.x建立的使用者角色應為manager,7.x建立的使用者角色 為manager-jmx,舉例如下:
-
在5.x和6.x中建立一個manager角色的使用者,使用者名稱為admin,密碼為chenfeng: <user username="admin" password="chenfeng" roles="manager"/>
-
在 7.x中建立一個manager角色的使用者,使用者名稱為admin,密碼為xxxxx: <user username="admin" password="chenfeng" roles="manager-jmx,manager-script,manager-status"/> 修改配置後,需要重新啟動 Tomcat 伺服器。連線manager時將使用者名稱/密碼指定為admin/xxxxxxxx
-
4.1.2.2 Probe
-
vi /usr/local/tomcat/conf//tomcat-users.xml -
<?xml version='1.0' encoding='utf-8'?> -
<tomcat-users> -
<role rolename="manager"/> -
<role rolename="standard"/> -
<role rolename="tomcat"/> -
<role rolename="admin"/> -
<role rolename="role1"/> -
<user username="tomcat" password="tomcat" roles="tomcat"/> -
<user username="both" password="tomcat" roles="tomcat,role1"/> -
<user username="probe" password="probe" roles="admin,manager"/> -
<user username="role1" password="tomcat"roles="role1"/> -
</tomcat-users>
-
設定環境變數,獲取伺服器狀態 # vi /etc/profile JAVA_OPTS=-Dcom.sun.management.jmxremote export JAVA_OPTS
-
重啟動伺服器
4.1.2.3 JConsole
Linux 系統下,需要修改 tomcat主目錄\bin\ catalina.sh檔案 增加一行 CATALINA_OPTS="$JAVA_OPTS -Djava.rmi.server.hostname=218.28.198.188 -Dcom.sun.management.jmxremote.port=9527 -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false" 然後使用JConsole就可以監控Tomcat。 點選%JAVA_HOME%\bin下的jconsole.exe即可
4.1.2.4 JProfile
- 安裝 首先到http://www.ej-technologies.com/download/overview.html 上 下載 linux 和 windows版本的安裝檔案. 將 linux版本的檔案(jprofiler_linux_7_0_1.sh),上傳到伺服器上, 將其安裝。 安裝命令: sh jprofile_linux_7_0_1.sh –c 即可。 Windows版本安裝忽略,一路next即可.
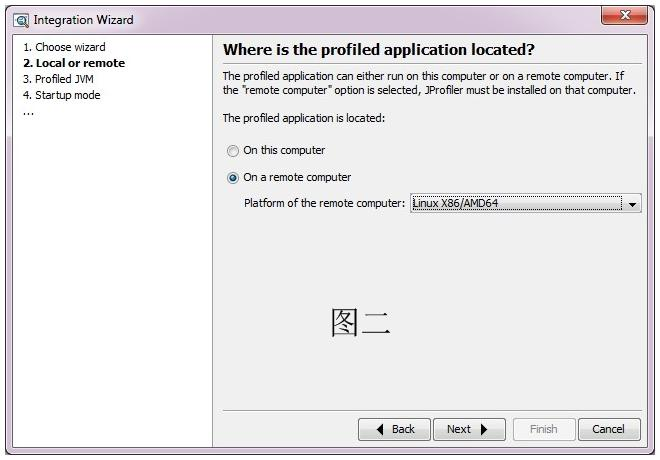
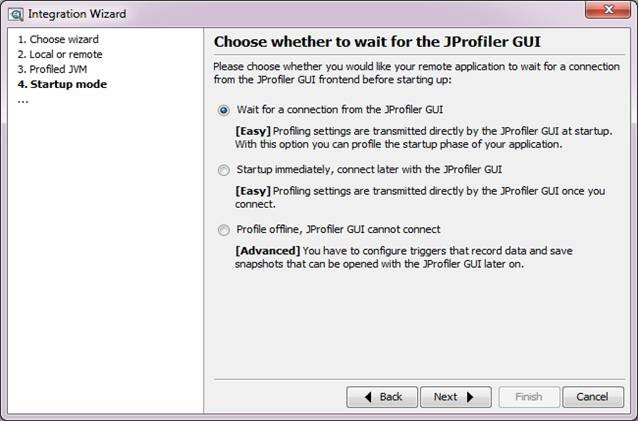
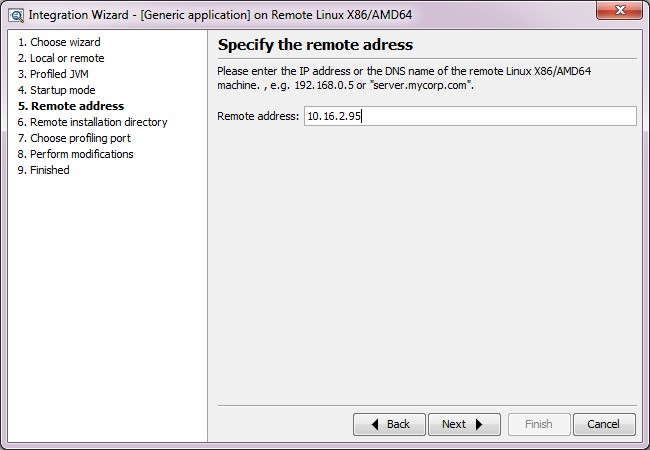
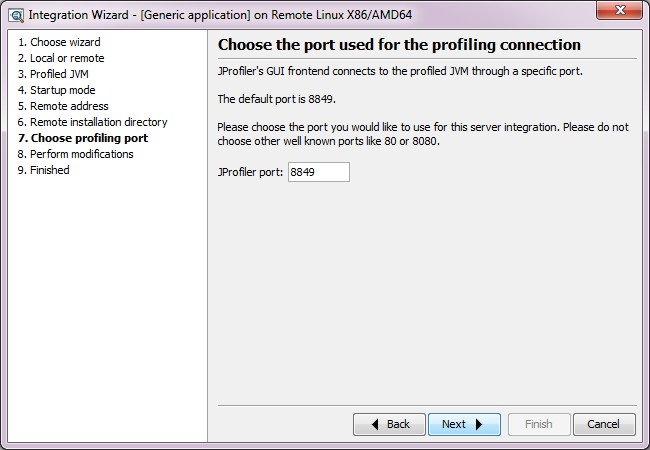
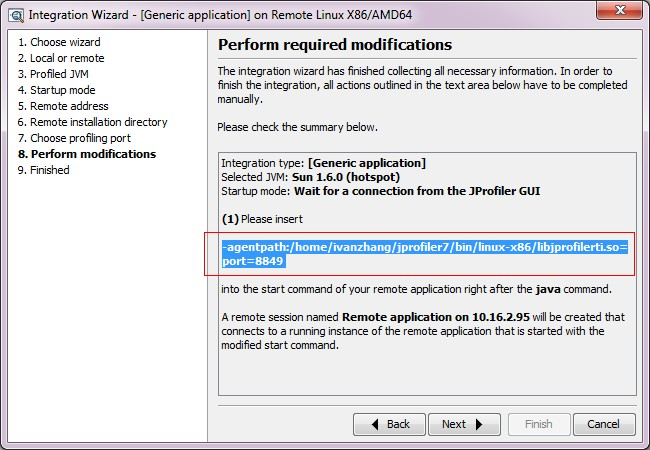
- 按照上圖 設定伺服器上需要監控的應用啟動引數, 如上內容是:
- agentpath:/home/ivanzhang/jprofile7/bin/linux-86/libjprofilerti.so=port=8849 將其加入到應用的啟動指令碼

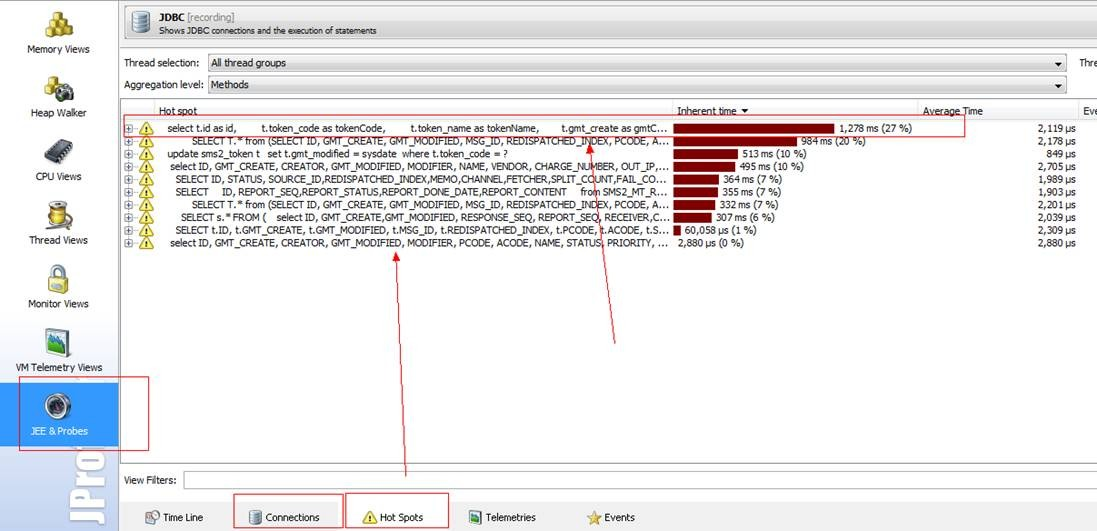
設 置好之後, 伺服器上的應用,會等待你客戶端連線上以後,才真正啟動應用。 Jprofile連線上之後,則可以看到一下介面了, 它可以幫助你分析記憶體資訊,執行緒資訊,jdbc連線等等, 以下是監控本地開發機的應用情況,可以看到,哪個執行緒在跑哪些SQL,由哪些方法呼叫的。

4.2 JBoss
4.2.1 監控指標說明
JBoss主要監控執行緒工作狀態、請求數、 會話數、執行緒數、虛擬主機、JAVA虛擬機器記憶體佔用情況。
4.2.2 監控工具
4.2.2.1 JBoss管理控制檯
如果需要監控jboss的系統資源,如:jboss的基本配置情況,jvm的利用率,執行緒池的使用情況,可以使用web-console進行監控。
- 配置web-console 具體方法同jmx-console,就是位置不同,具體方法參考jmx-console配置:
- jboss-web xml 、 web.xml 在$JBOSS_HOME/vcom/deploy/management/console-mgr.sar/web-console.war/WEB-INF下;
- login-config.xml還是原來的那個,把application-policy名為$webConsoleDomain的部分改成你需要的web-console;
-
web- console-users.properties、web-console-roles.properties定義了訪問 web-console的使用者、使用者角色,具體位置,使用find /jboss -name web-console-users.properties 找到以後可以修改使用者名稱、密碼。
4.2.2.2 Probe
具體可以參照4.1.2.2 Probe
4.2.2.3 JConsole
具體可以參照4.1.2.3 JConsole
4.2.2.4 JProfile
具體可以參照4.1.2.4 JProfile
4.3 IIS監控
4.3.1 監控指標說明
主要針對會話、事務、快取、記憶體、執行緒池等進行監控,具體如下:
- ASP Session Duration 最近進行的會話所持續的時間(以毫秒為單位)。
- ASP Sessions Current 正在使用服務的會話數。
- IIS Global Total Files Cached 新增到 WWW 和 FTP 服務的快取的檔案總數。
- Web Total Not Found Errors 由於未找到所請求的文件,Web 服務無法滿足的請求數;通常以 HTTP 404 錯誤程式碼方式向客戶端報告。
- ASP Transactions Committed 已提交的事務數。
- ASP Transactions Pending 正在處理的事務數。
- ASP Transactions/Sec 每秒啟動的事務數。
- IIS Global URI Cache Hits URI 快取中的成功查詢總數。
- IIS Global URI Cache Hits % URI 快取命中數佔全部快取請求的比率。
- IIS Global URI Cache Misses URI 快取中的未成功查詢總數
4.3.2 監控工具
4.3.2.1 整合的效能監視器
在效能監視器裡面新增IIS應用計數器即可。
4.4 JVM
4.4.1 監控指標說明
JVM關注的指標主要是java虛擬機器記憶體年輕代、年老代堆大小以及GC頻率及回收時間。 JVM堆記憶體結構如下:
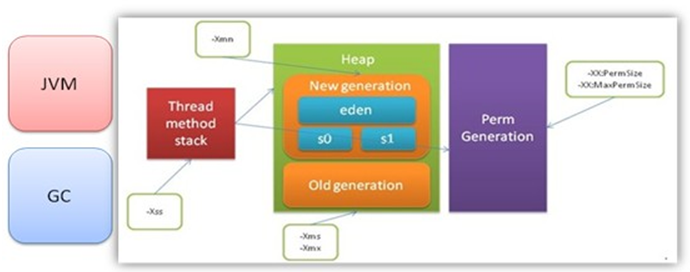
- Young(年 輕代) 年輕代分三個區。一個Eden區,兩個 Survivor區。大部分物件在Eden區中生成。當Eden區滿時,還存活的物件將被複制到Survivor區(兩個中的一個),當這個 Survivor區滿時,此區的存活物件將被複制到另外一個Survivor區,當這個Survivor區也滿了的時候,從第一個Survivor區複製 過來的並且此時還存活的物件,將被複制“年老區(Tenured)”。需要注意,Survivor的兩個區是對稱的,沒先後關係,所以同一個區中可能同時 存在從Eden複製過來物件,和從前一個Survivor複製過來的物件,而複製到年老區的只有從第一個Survivor去過來的物件。而 且,Survivor區總有一個是空的。
- Tenured(年老代) 年老代存放從年輕代存活的物件。一般來說年老代存放的都是生命期較長的物件。
- Perm(持 久代) 用 於存放靜態檔案,如今Java類、方法等。持久代對垃圾回收沒有顯著影響,但是有些應用可能動態生成或者呼叫一些class,例如Hibernate等, 在這種時候需要設定一個比較大的持久代空間來存放這些執行過程中新增的類。持久代大小通過-XX:MaxPermSize=進行設定。 發生在年輕代的垃圾回收叫做GC/Minor GC,發生在年老代和永久代的垃圾回收叫做Full GC.
4.4.2 監控工具
4.4.2.1 JVM自帶的jstat
- jstat -gc pid 可以顯示gc的資訊,檢視gc的次數,及時間。 其中最後五項,分別是young gc的次數,young gc的時間,full gc的次數,full gc的時間,gc的總時間。
- jstat -gccapacity pid 可以顯示,VM記憶體中三代(young,old,perm)物件的使用和佔用大小,如:PGCMN顯示的是最小perm的記憶體使用量,PGCMX顯示的是 perm的記憶體最大使用量, PGC是當前新生成的perm記憶體佔用量,PC是但前perm記憶體佔用量。 其他的可以根據這個類推, OC是old內純的佔用量。
- jstat -gcutil pid 統計gc資訊統計。
- jstat -gcnew pid 年輕代物件的資訊。
- jstat -gcnewcapacity pid 年輕代物件的資訊及其佔用量。
- jstat -gcold pid old代物件的資訊。
- jstat -gcoldcapacity pid old代物件的資訊及其佔用量。
- jstat -gcpermcapacity pid perm物件的資訊及其佔用量。
- jstat -class pid 顯示載入class的數量,及所佔空間等資訊。
- jstat -compiler pid 顯示VM實時編譯的數量等資訊。
- jstat -printcompilation pid 當前VM執行的資訊。 Jstat顯示的資訊中一些術語的中文解釋:
- S0C:年輕代中第一個survivor(倖存區)的容量 (位元組)
- S1C:年輕代中第二個survivor(倖存區)的容量 (位元組)
- S0U:年輕代中第一個survivor(倖存區)目前已使用空間 (位元組)
- S1U:年輕代中第二個survivor(倖存區)目前已使用空間 (位元組)
- EC:年輕代中Eden(伊甸園)的容量 (位元組)
- EU:年輕代中Eden(伊甸園)目前已使用空間 (位元組)
- OC:Old代的容量 (位元組)
- OU:Old代目前已使用空間 (位元組)
- PC:Perm(持久代)的容量 (位元組)
- PU:Perm(持久代)目前已使用空間 (位元組)
- YGC:從應用程式啟動到取樣時年輕代中gc次數
- YGCT:從應用程式啟動到取樣時年輕代中gc所用時間(s)
- FGC:從應用程式啟動到取樣時old代(全gc)gc次數
- FGCT:從應用程式啟動到取樣時old代(全gc)gc所用時間(s)
- GCT:從應用程式啟動到取樣時gc用的總時間(s)
- NGCMN:年輕代(young)中初始化(最小)的大小 (位元組)
- NGCMX:年輕代(young)的最大容量 (位元組)
- NGC:年輕代(young)中當前的容量 (位元組)
- OGCMN:old代中初始化(最小)的大小 (位元組)
- OGCMX:old代的最大容量 (位元組)
- OGC:old代當前新生成的容量 (位元組)
- PGCMN:perm代中初始化(最小)的大小 (位元組)
- PGCMX:perm代的最大容量 (位元組)
- PGC:perm代當前新生成的容量 (位元組)
- S0:年輕代中第一個survivor(倖存區)已使用的佔當前容量百分比
- S1:年輕代中第二個survivor(倖存區)已使用的佔當前容量百分比
- E:年輕代中Eden(伊甸園)已使用的佔當前容量百分比
- O:old代已使用的佔當前容量百分比
- P:perm代已使用的佔當前容量百分比
- S0CMX:年輕代中第一個survivor(倖存區)的最大容量 (位元組)
- S1CMX :年輕代中第二個survivor(倖存區)的最大容量 (位元組)
- ECMX:年輕代中Eden(伊甸園)的最大容量 (位元組)
- DSS:當前需要survivor(倖存區)的容量 (位元組)(Eden區已滿)
- TT: 持有次數限制
- MTT : 最大持有次數限制
4.4.2.2 shell
將jstat中感興趣的相關指標通過shell儲存為檔案,例如以下shell是每隔2秒鐘將jstat監控的資訊儲存到檔案中。
while true;do /usr/local/java/bin/jstat -gcutil `/usr/local/java/bin/jps | grep -v 'Jps' | grep -v 'Jstat' | egrep 'OrderPlatformLauncher|Bootstrap|TcpServerLauncher'| awk '{print $1}'` | grep -v 'S0' | awk '{print strftime("%m-%d-%H:%M:%S",systime()),$0}';sleep 2;done >> `hostname`_`date +%Y%m%d_%H%M`.jstat
4.4.2.3 jmap
jmap命令可以獲得執行中的jvm的堆的快照,從而可以離線分析堆,以檢查記憶體洩漏,檢查一些嚴重影響效能的大物件的建立,檢查系統中什麼物件最多,各種物件所佔記憶體的大小等等
命令格式 jmap [options] pid -dump:[live,]format=b,file=<filename> --dump堆到檔案,live指明是活著的物件,file指定檔名。
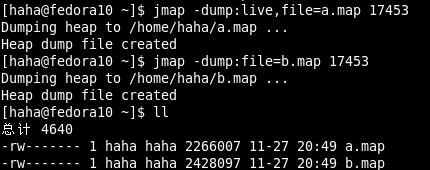
因為在dump:live前會進行full gc,因此不加live的堆大小要大於加live堆的大小 -finalizerinfo 列印等待回收物件的資訊
-heap 列印堆總結
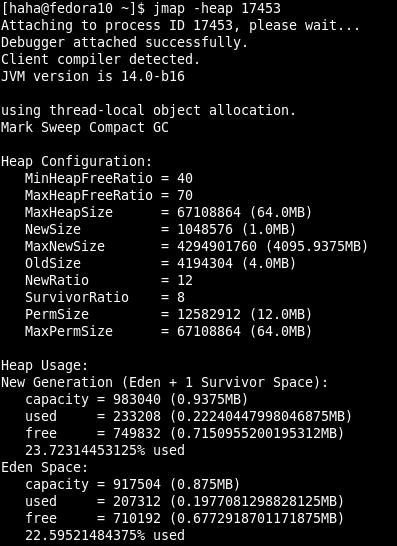
-histo[:live] 列印堆的物件統計,包括物件數、記憶體大小等等
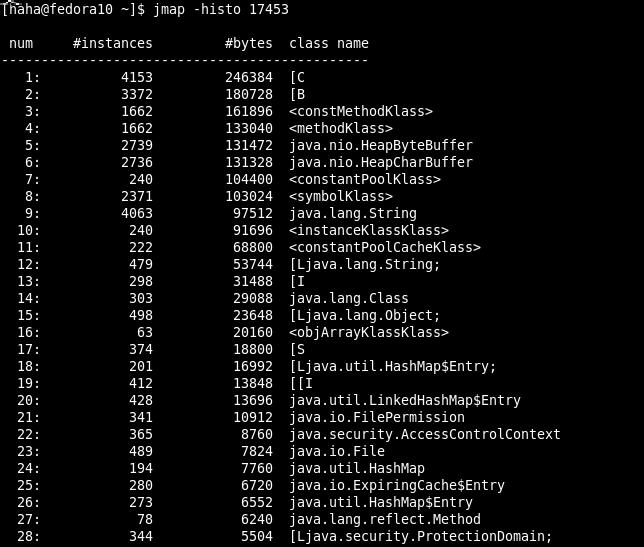
-permstat 列印java堆perm區的classloader統計
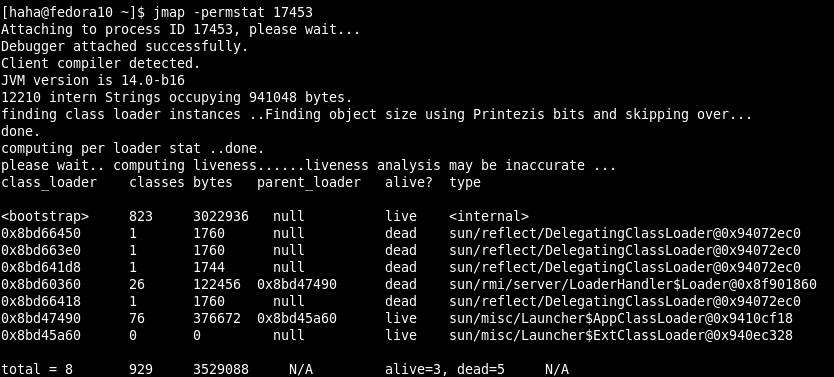
-F 強制,在jmap -dump或jmap -histo中使用,如果pid沒有相應的回覆 -J 提供jvm選項,如:-J-Xms256m
4.4.2.4 jstack
- 介紹 jstack用於打印出給定的java程序ID或core file或遠端除錯服務的Java堆疊資訊,如果是在64位機器上,需要指定選項"-J-d64",Windows的jstack使用方式只支援以下的這種方式:
jstack [-l] pid
如 果java程式崩潰生成core檔案,jstack工具可以用來獲得core檔案的java stack和native stack的資訊,從而 可以輕鬆地知道java程式是如何崩潰和在程式何處發生問題。另外,jstack工具還可以附屬到正在執行的java程式中,看到當時執行的java程式 的java stack和native stack的資訊, 如果現在執行的java程式呈現hung的狀態,jstack是非常有用的。 - 命令格式
jstack [ option ] pid
jstack [ option ] executable core
jstack [ option ] [[email protected]]remote-hostname-or-IP - 常用引數說明
- options:
executable Java executable from which the core dump was produced.
(可能是產生core dump的java可執行程式)
core 將被列印資訊的core dump檔案
remote-hostname-or-IP 遠端debug服務的主機名或ip
server-id 唯一id,假如一臺主機上多個遠端debug服務 - 基本引數:
-F當’jstack [-l] pid’沒有相應的時候強制列印棧資訊
-l長列表. 列印關於鎖的附加資訊,例如屬於java.util.concurrent的ownable synchronizers列表.
-m列印java和native c/c++框架的所有棧資訊.
-h | -help列印幫助資訊
pid 需要被列印配置資訊的java程序id,可以用jps查詢. - 使用示例
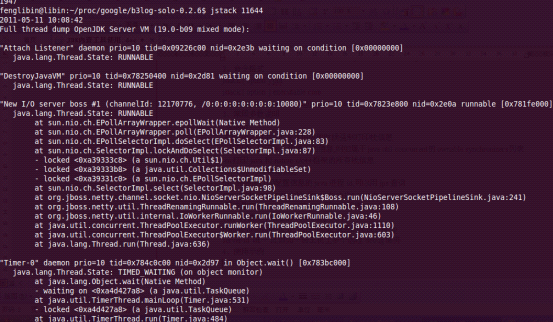
4.4.2.5 JProfile
JProfile也可以監控JVM,並且以圖形化的方式進行展示,方便資訊的檢視及分析。具體可以參照4.1.2.4章節。
4.4.2.6 JConsole
JConsole也可以監控JVM,並且以圖形化的方式進行展示,方便資訊的檢視及分析。具體可以參照4.1.2.3章節。
4.5 .NET CLR
4.5.1 監控指標說明
.NET CLR是有微軟開發的一臺虛擬平臺,支援C#/C++/VB等,此虛擬平臺功能類似於JVM. .NET CLR主要功能如下:
- 平臺無關
- 跨語言整合
- 自動記憶體管理
- 版本控制
- 安全 .NET CLR Memory計數器如下:
效能計數器 說明
| 指標 | 解釋 |
|---|---|
| # Bytes in all Heaps(所有堆中的位元組數) | 顯示以下計數器值的總和,此計數器指示在垃圾回收堆上分配的當前記憶體(以位元組為單位)。 |
| # GC Handles(GC 處理數目) | 顯示正在使用的垃圾回收處理的當前數目。 |
| # Gen 0 Collections(第 2 級回收次數) | 顯示自應用程式啟動後第 0 級物件(即最年輕、最近分配的物件)被垃圾回收的次數。 |
| # Gen 1 Collections(第 2 級回收次數) | 顯示自應用程式啟動後對第 1 級物件進行垃圾回收的次數。 |
| # Gen 2 Collections(第 2 級回收次數) | 顯示自應用程式啟動後對第 2 級物件進行垃圾回收的次數。此計數器在第 2 級垃圾回收(也稱作完整垃圾回收)結束時遞增。 |
| # Induced GC(引發的 GC 的數目) | 顯示由於對 GC.Collect 的顯式呼叫而執行的垃圾回收的峰值次數。讓垃圾回收器對其回收的頻率進行微調是切實可行的。 |
| # of Pinned Objects(釘住的物件的數目) | 顯示上次垃圾回收中遇到的釘住的物件的數目。釘住的物件是垃圾回收器不能移入記憶體的物件。 |
| # of Sink Blocks in use(正在使用的接收塊的數目) | 顯示正在使用的同步塊的當前數目。同步塊是為儲存同步資訊分配的基於物件的資料結構。 |
| # Total committed Bytes(提交位元組的總數) | 顯示垃圾回收器當前提交的虛擬記憶體量(以位元組為單位)。提交的記憶體是在磁碟頁面檔案中保留的空間的實體記憶體。 |
| # Total reserved Bytes(保留位元組的總數) | 顯示垃圾回收器當前保留的虛擬記憶體量(以位元組為單位)。保留記憶體是為應用程式保留(但尚未使用任何磁碟或主記憶體頁)的虛擬記憶體空間。 |
| % Time in GC(GC 中時間的百分比) | 顯示自上次垃圾回收週期後執行垃圾回收所用執行時間的百分比。 |
| Allocated Bytes/second(每秒分配的位元組數) | 顯示每秒在垃圾回收堆上分配的位元組數。 |
| Finalization Survivors(完成時存留物件數目) | 顯示因正等待完成而從回收後保留下來的進行垃圾回收的物件的數目。如果這些物件保留對其他物件的引用,則那些物件也保留下來,但此計數器不對它們計數。 |
| Gen 0 heap size(第 2 級堆大小) | 顯示在第 0 級中可以分配的最大位元組數;它不指示在第 0 級中當前分配的位元組數。 |
| Gen 0 Promoted Bytes/Sec(從第 1 級提升的位元組數/秒) | 顯示每秒從第 0 級提升到第 1 級的位元組數。記憶體在從垃圾回收保留下來後被提升。 |
| Gen 1 heap size(第 2 級堆大小) | 顯示第 1 級中的當前位元組數;此計數器不顯示第 1 級的最大大小。 |
| Gen 1 Promoted Bytes/Sec(從第 1 級提升的位元組數/秒) | 顯示每秒從第 1 級提升到第 2 級的位元組數。在此計數器中不包括只因正等待完成而被提升的物件。 |
| Gen 2 heap size(第 2 級堆大小) | 顯示第 2 級中當前位元組數。不直接在此代中分配對。 |
| Large Object Heap size(大物件堆大小) | 顯示大物件堆的當前大小(以位元組為單位)。垃圾回收器將大於 20 KB 的物件視作大物件並且直接在特殊堆中分配大物件; |
| Promoted Finalization-Memory from Gen 0(從第 1 級提升的完成記憶體) | 顯示只因等待完成而從第 0 級提升到第 1 級的記憶體的位元組數。 |
| Promoted Finalization-Memory from Gen 1(從第 1 級提升的完成記憶體) | 顯示只因等待完成而從第 1 級提升到第 2 級的記憶體的位元組數。 |
| Promoted Memory from Gen 0(從第 1 級提升的記憶體) | 顯示在垃圾回收後保留下來並且從第 0 級提升到第 1 級的記憶體的位元組數。 |
| Promoted Memory from Gen 1(從第 1 級提升的記憶體) | 顯示在垃圾回收後保留下來並且從第 1 級提升到第 2 級的記憶體的位元組數。 |
4.5.2 監控工具
4.5.2.1 整合的效能監視器
Windows效能監視器中,可以將.NET CLR Memory中相關的計數器加入到監控中。
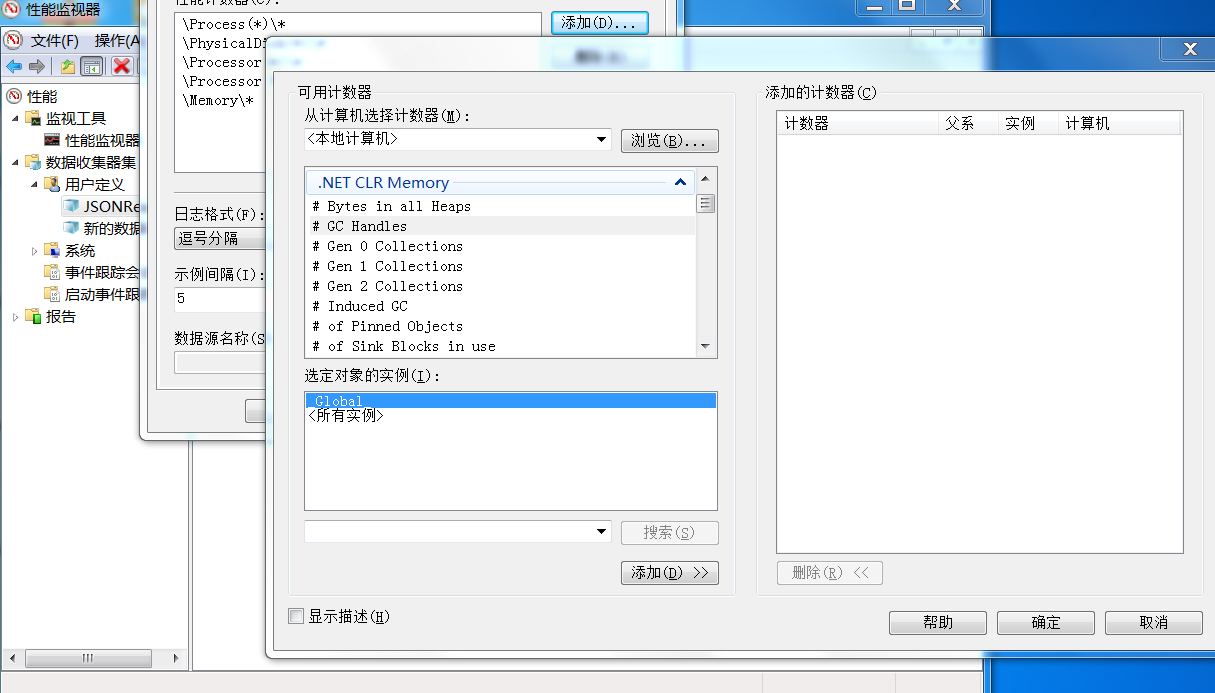
4.5.2.2 .NET Memory Profiler
Profiler可以除錯4種類型的.NET程式,分別為:
- 桌面應用程式
- WPF程式
- ASP.NET程式
- .NET Service程式 對應選擇軟體的檔案選單如下
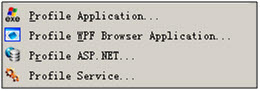
Profler除錯共有三種方式選擇:
- 啟動跟蹤(Profiler Application)
選定對應的除錯方式,如除錯桌面程式,選中Profiler Application,然後選擇需要啟動的執行檔案,Profiler將作為宿主程式啟動程式開始實時監控記憶體. - 附加程序(Attach Process)
將Profiler附加到指定的程序上,此時不能實時監控記憶體情況,只能夠收集記憶體映象. - 匯入記憶體映象(Import Memory Dump)
可以選擇dmp為字尾的記憶體映象檔案,比如Windbg以及DebugDiag匯出的映象檔案,此時不能實時監控記憶體情況,只能夠收集記憶體映象且不能跟蹤非託管資源.
具體操作如下: - 啟動程式
首先,選擇需要除錯型別,選擇 Profiler Application,選擇好需要啟動的程式exe檔案.
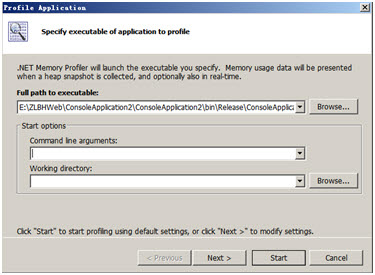
如果需要設定啟動引數,則設定好命令列引數以及工作目錄.
選擇”Next”進行收集資料的一些選項設定,一般直接按”Star”按鈕開始除錯程式.
- 收集資料
選擇選單欄的收集按鈕,收集堆資料,第一個為收集全部堆上的資料,第二個為只收集第0代的資料.

- 重新啟動和停止
除錯完畢後通過停止按鈕跟蹤程式,通過啟動按鈕重新啟動上一次的除錯程式. -
檢視收集資料
Profiler上有6個頁卡,分別為: -
Type/Resource 型別/資源頁卡
- Type/Resource Details型別/資源明細頁卡
- Instance Details 例項明細頁卡
- Call Stacks/Methods呼叫堆疊頁卡
- Navtive Memory 本地記憶體頁卡
- Real-Time-實時跟蹤頁卡
5 資料庫指標監控
5.1 MySQL
5.1.1 監控指標說明
主要針對SQL耗時、吞吐量(QPS/TPS)、命中率、鎖等待等指標進行監控。
5.1.2 監控工具
5.1.2.1 命令
- 效率低下SQL
mysqldumpslow -s at -t 20 host-slow.log - #mysql qps查詢 QPS = Questions(or Queries) / Seconds
mysql -u root -p123456 -e 'SHOW /!50000 GLOBAL / STATUS LIKE "Questions"'
mysql -u root -p123456 -e 'SHOW /!50000 GLOBAL / STATUS LIKE "Queries"' - #mysql Key Buffer 命中率
key_buffer_read_hits = (1 - Key_reads / Key_read_requests) 100% key_buffer_write_hits= (1 - Key_writes / Key_write_requests) 100%
mysql -u root -p123456 -e 'SHOW /!50000 GLOBAL / STATUS LIKE "Key%"' - #mysql Innodb Buffer 命中率
innodb_buffer_read_hits=(1-Innodb_buffer_pool_reads/ Innodb_buffer_pool_read_requests) 100%
mysql -u root -p123456 -e 'SHOW /!50000 GLOBAL */ STATUS LIKE "Innodb_buffer_pool_read%"' - #mysql Query Cache 命中率
Query_cache_hits= (Qcache_hits / (Qcache_hits + Qcache_inserts)) 100%
mysql -u root -p123456 -e 'SHOW /!50000 GLOBAL */ STATUS LIKE "Qcache%"' - #mysql Table Cache 狀態量
mysql -u root -p123456 -e 'SHOW /!50000 GLOBAL / STATUS LIKE "Open%"' - #mysql Thread Cache 命中率
Thread_cache_hits = (1 - Threads_created / Connections) 100% 正常來說,Thread Cache 命中率要在 90% 以上才算比較合理。
mysql -u root -p123456 -e 'SHOW /!50000 GLOBAL */ STATUS LIKE "Thread%"' - #mysql 鎖定狀態
鎖定狀態包括表鎖和行鎖兩種,我們可以通過系統狀態變數獲得鎖定總次數,鎖定造成其他執行緒等待的次數,以及鎖定等待時間資訊
mysql -u root -p123456 -e 'SHOW /!50000 GLOBAL / STATUS LIKE "%lock%"'
5.1.2.2 iDBCloud
- 在阿里雲RDS管理控制檯,點選登陸資料庫

- 輸入例項名、使用者名稱和密碼
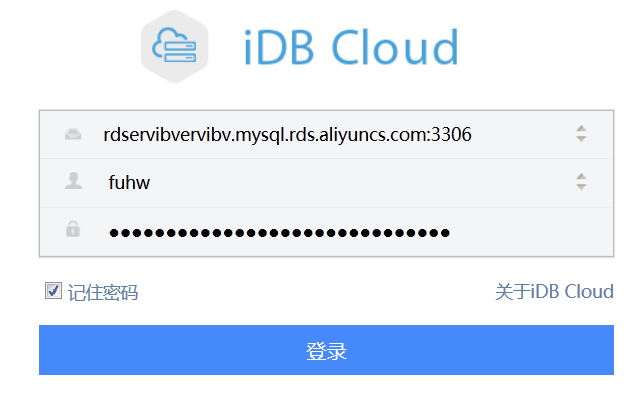
- 點選例項效能
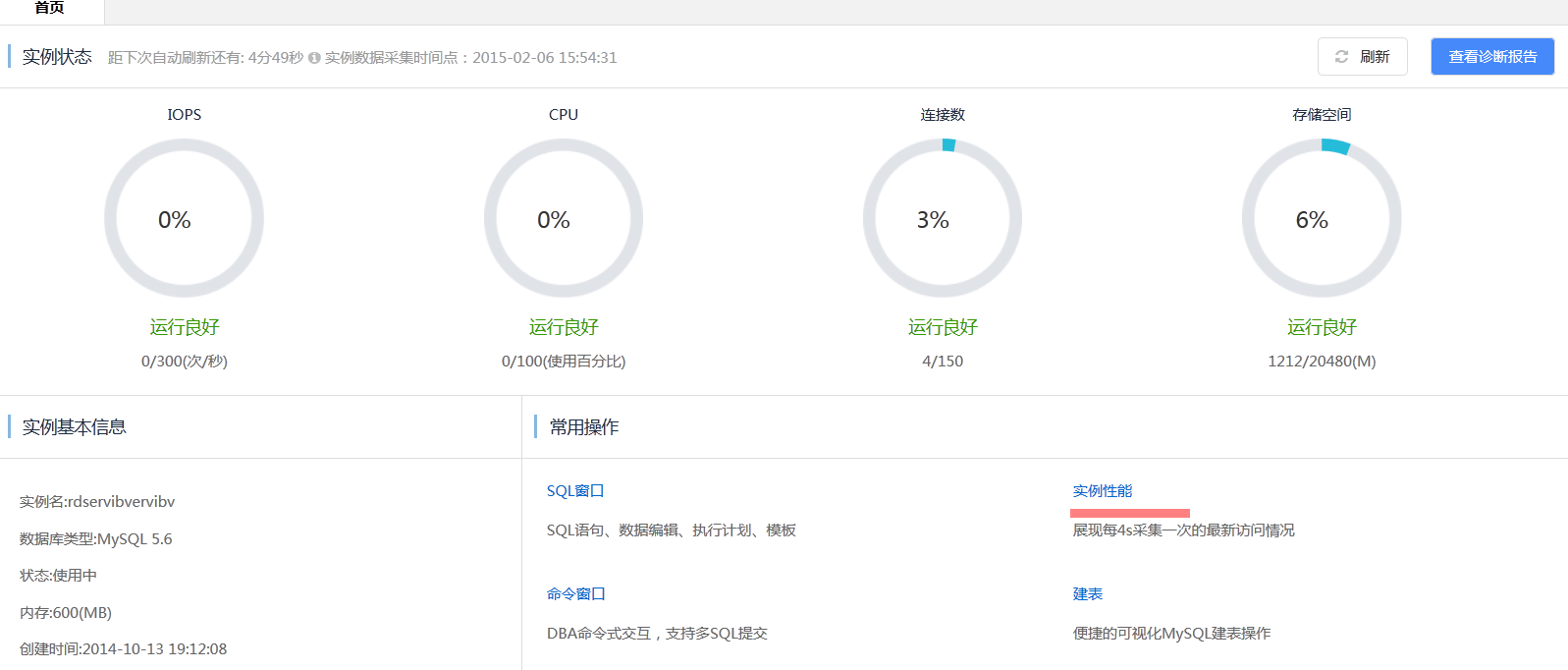
- 點選例項效能
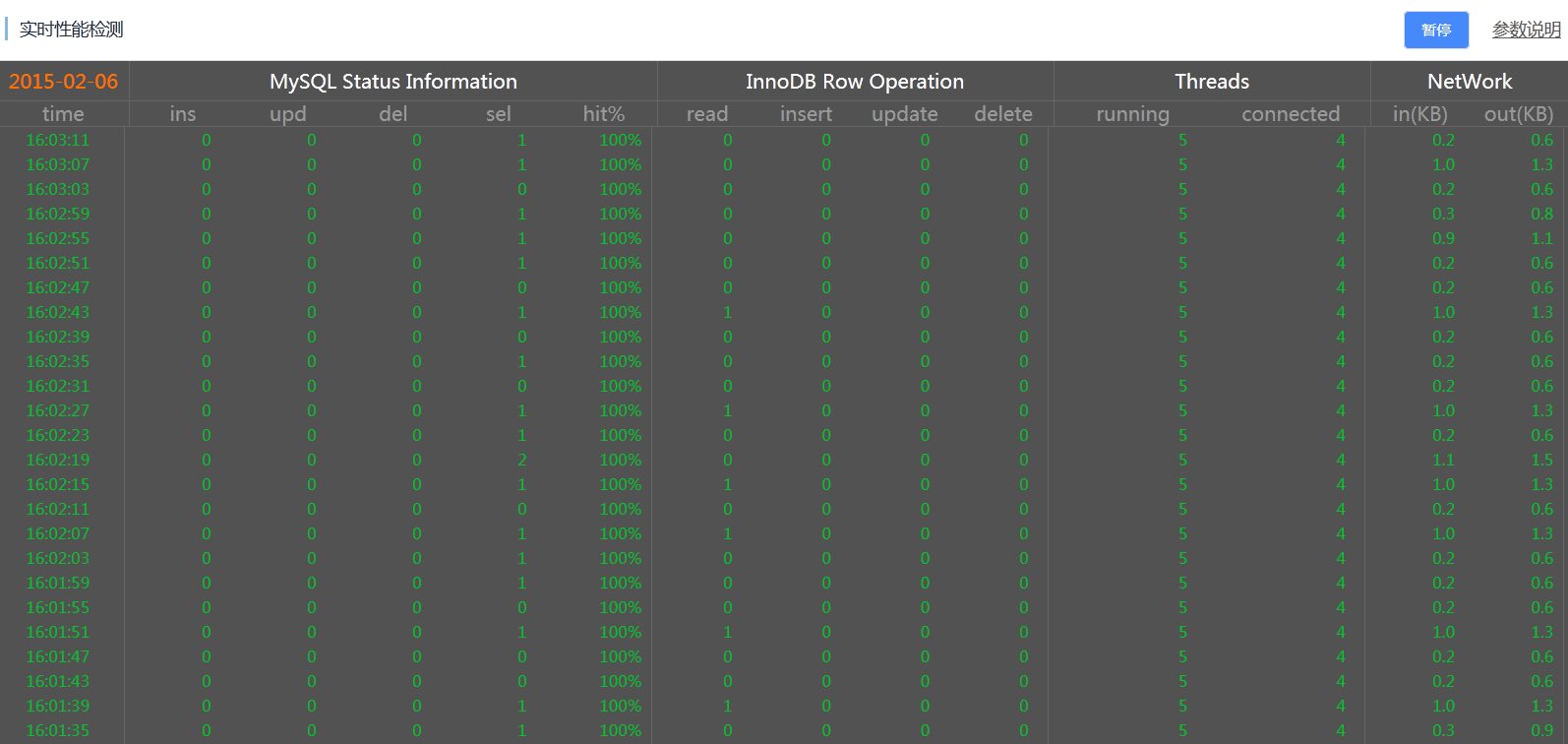
MySQL Status Inoformation : MySQL狀態資訊
【ins】表示insert語句每秒執行次數
【upd】表示update語句每秒執行次數
【del】表示delete語句每秒執行次數
【sel】表示select語句每秒執行次數
【hit%】表示快取命中率,主要指innodb_buffer_pool的命中率
InnoDB Row Operation : InnoDB儲存引擎行操作
【read】表示InnoDB儲存引擎表的讀取記錄行數
【insert】表示InnoDB儲存引擎表的寫入記錄行數
【update】表示InnoDB儲存引擎表的更新記錄行數
【delete】表示InnoDB儲存引擎表的寫入記錄行數
Thread : 連線數相關
【running】表示活躍的連線數,即正在執行sql的連線
【connected】表示連線在例項上的空閒連線,即未執行sql的連線
Network : 網路流量,單位為KB
【in】表示進入例項的網路流量
【out】表示流出例項的網路流量
5.1.2.3 PHPMyAdmin
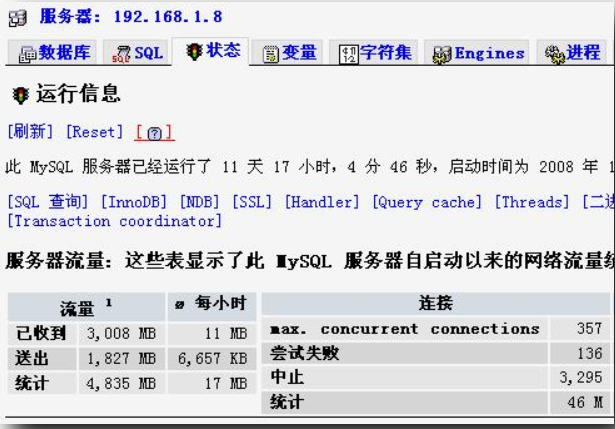
phpMyAdmin 是Mysql的管理工具。相比一些Mysql客戶端的GUI管理工具(如“MySQL Administrator”),phpMyAdmin是Web模式的。phpMyAdmin 是以PHP為基礎,以Web-Base方式架構在網站主機上的MySQL的資料庫管理工具。
在phpMyAdmin直接點選狀態,可以檢視SQL查詢,InnoDB,Cache,執行緒等狀態資訊。
5.1.2.4 效能測試
通過效能測試RDS監控,可以監控當前活躍連線數、IOPS、TPS、磁碟容量、QPS。
5.2 SQLServer
5.2.1 監控指標說明
| 監控項 | 解釋 |
|---|---|
| 連線數 | 當前總連線數 |
| 快取命中率 | 快取命中率 |
| 平均每秒全表掃描數 | 平均每秒全表掃描次數 |
| 每秒SQL編譯 | 例項中每秒編譯的SQL語句數 |
| 每秒檢查點寫入Page數 | 每秒檢查點寫入Page數 |
| 每秒登入次數 | 每秒登入次數 |
| 每秒鎖超時次數 | 每秒鎖超時次數 |
| 每秒死鎖次數 | 每秒死鎖次數 |
| 每秒鎖等待次數 | 每秒鎖等待次數 |
| 網路流量 | SQL Server例項平均每秒鐘輸入和輸出的流量。單位為KB。 |
| QPS/TPS | 平均每秒SQL語句執行次數和事務數。 |
| CPU使用率 | RDS例項CPU使用率(佔作業系統總數) |
| IOPS | RDS例項的IOPS(每秒IO請求次數) |
| 磁碟空間 | RDS例項空間佔用 |
5.2.2 監控工具
5.2.2.1 SQLServer活動監視器
SQL Server 資料庫提供了專門的工具對資料庫的活動進行監控,這個工具稱為“活動監視器”。使用活動監視器可以獲取與資料庫引擎相關的使用者連線狀態及其所儲存的鎖等有用資訊。
- 開啟活動監視器
- 開啟SQL Server Management Studio並連線到資料庫引擎伺服器。
- 在“物件資源管理器”視窗中,展開“管理”節點。
- 雙擊“活動監視器”節點,開啟“活動監視器”對話方塊,如圖1所示。
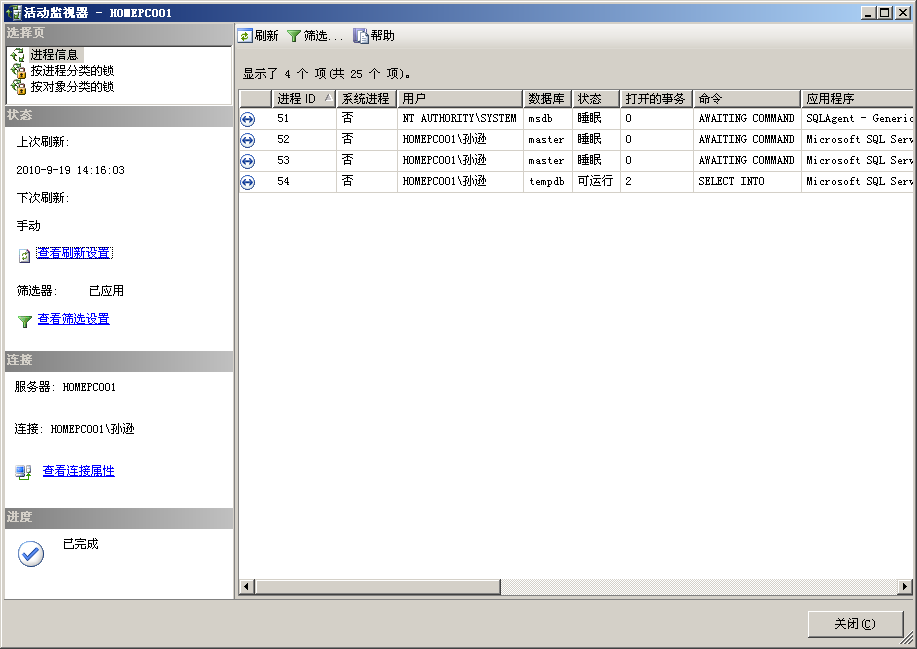
該“活動監視器”對話方塊包含3組選項,分別是“程序資訊”選項、“按程序分類的鎖”選項和“按物件分類的鎖”選項。
“程序資訊”選項:包含有關連線到資料庫的資訊
“按程序分類的鎖”選項:顯示按連線對鎖進行排序
“按物件分類的鎖”選項:顯示按物件名稱對鎖進行排序
- 檢視當前程序的屬性
使用者可以使用“程序資訊”選項:檢視當前程序的屬性。
使用者可以通過對話方塊頂部的“篩選器”按鈕,開啟“篩選設定”對話方塊,如圖2所示。
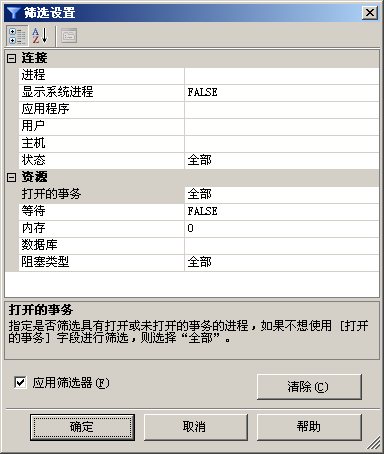
應用篩選器可以減少顯示的資訊量。對資料庫鎖定問題進行故障排除時,可以使用“活動監視器”終止死鎖或無響應的程序。
- 檢視某一個程序的詳細資訊
若要檢視某一個程序的詳細資訊,可以右擊某一程序,在彈出的快捷選單中選擇“詳細資訊”命令,開啟“程序詳細資訊”對話方塊。
5.2.2.2 SQLServer Profile
SQL Server Profiler(事件探查器)是SQL跟蹤的圖形使用者介面,用於監視SQL Server 資料庫引擎或SQL Server Analysis Services(分析服務)的例項。使用者可以捕獲有關每個事件的資料,並將其儲存到檔案或表中供以後分析。
- 建立跟蹤
使用者可以使用SQL Server Profiler工具建立跟蹤,具體過程如下: - 依次選擇“開始”|“所有程式”|“Microsoft SQL Server”|“效能工具”|“SQL Server Profiler”,開啟事件探查器。
- 開啟“檔案”選單,選擇“新建跟蹤”命令,並連線到SQL Server例項。此時,將顯示“跟蹤屬性”對話方塊,如圖所示:
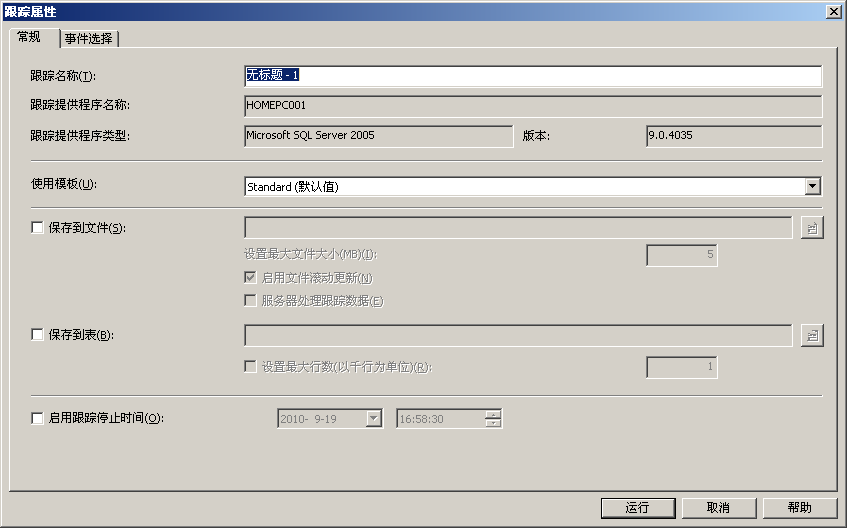
- 在“跟蹤名稱”文字框中輸入跟蹤的名稱。在“使用模板”下拉列表框中,為此跟蹤選擇一個跟蹤模板。如果不想使用模板,則選擇“空白”選項。
- 設定全域性跟蹤選項 使用者可以設定應用於SQL Server 2005 Profiler的全域性選項,具體操作如下:
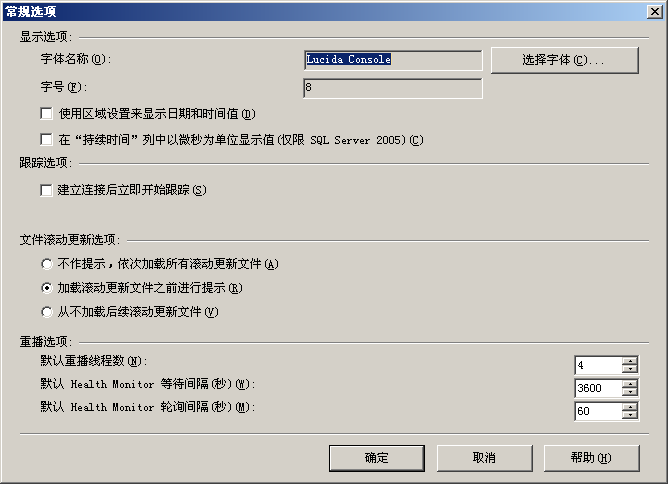
- 依次選擇“開始”|“所有程式”|“Microsoft SQL Server 2005”|“效能工具”|“SQL Server Profiler”,開啟事件探查器。
- 依次選擇“工具”|“選項”命令,開啟“常規選項”對話方塊,如圖所示:
- 指定跟蹤檔案的事件和資料列
使用者可以使用SQL Server Profiler指定跟蹤的事件類和資料列,具體操作過程如下: - 依次選擇“開始”|“所有程式”|“Microsoft SQL Server”|“效能工具”|“SQL Server Profiler”,開啟事件探查器。
- 依次選擇“檔案”|“新建跟蹤”命令,或者在正在執行跟蹤時,選擇“檔案”|“屬性”命令,開啟“跟蹤屬性”選項卡。
- 選擇“事件選擇”選項卡,如圖所示:
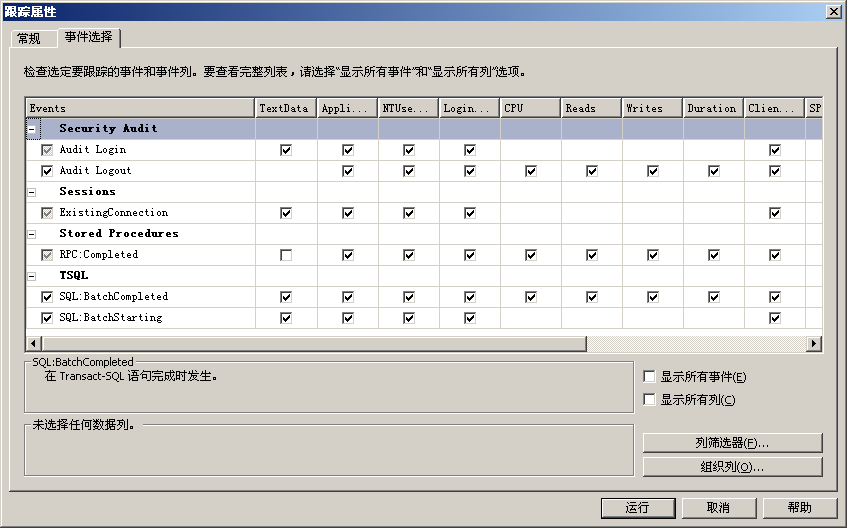
“事 件選項”選項卡包含一個網格控制元件,網格控制元件是包含所有可跟蹤事件類的表。每個事件類在表中佔一行。根據使用者所連線的伺服器的型別和版本的不同,事件類會略 有不同。事件類是由網格的“Events”列進行標識,並按事件類別進行分組。其餘列則列出每個事件類可以返回的資料列。
- 將跟蹤結果儲存到表
使用者可以使用SQL Server Profiler將跟蹤結果儲存到資料庫表,具體操作過程如下:
依 次選擇“開始”|“所有程式”|“Microsoft SQL Server ”|“效能工具”|“SQL Server Profiler”,開啟事件探查器。在“檔案”選單上,選擇“新建跟蹤”命令,並連線到SQL Server例項。此時,將顯示“跟蹤屬性”對話方塊。輸入跟蹤的名稱,然後選中“儲存到表”複選框。彈出“連線到伺服器”對話方塊,連線到將包含跟蹤表的 SQL Server 2005資料庫伺服器例項。在“目標表”對話方塊中,從“資料庫”列表中選擇相應的資料庫,所有者,輸入表的名稱,如圖所示:
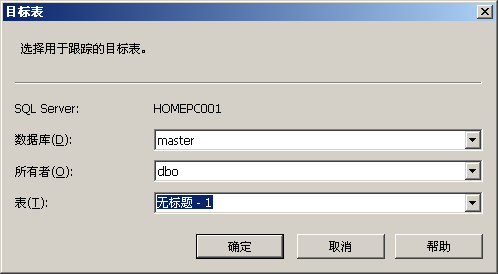
完成設定後,單擊“確定”按鈕,返回“跟蹤屬性”對話方塊。
5.2.2.3 效能監視器
系統性能監視器可以用於監視系統資源的使用率。它使用計數器形式收集和檢視伺服器資源(如處理器和記憶體使用的情況)和許多SQL Server 2005資源(如鎖和事務)的實時效能資料。
- 執行系統性能監視器
系 統監視器使用遠端過程呼叫從SQL Server 2005收集資訊。擁有執行系統監視器的Windows許可權的任何使用者都可以使用系統監視器來監視SQL Server 2005。與所有效能監視器工具一樣,使用系統監視器監視SQL Server 2005時,效能方面會受到一些影響。特定例項中的實際影響取決於硬體平臺、計數器數量以及所選更新間隔。但是,將系統監視器與SQL Server 2005整合可以儘量減少對效能的影響。 - SQL Server 2005效能物件
SQL Server 2005資料庫提供了一組針對性能的資料物件,供使用者監視SQL Server 2005時使用。當監視SQL Server 2005和Windows作業系統以調查與效能有關的問題時,請關注3個主要方面:磁碟活動、處理器使用率和記憶體使用量。這些效能物件在系統的“效能監視 器”工具的“新增計數器”對話方塊的“效能物件”下拉列表框中可以找到。
5.2.2.4 iDBCloud
參照5.1.2.2 iDBCloud.
5.3 MonogoDB
5.3.1 監控指標說明
主要監控如下指標:
- inserts/s 每秒插入次數
- query/s 每秒查詢次數
- update/s 每秒更新次數
- delete/s 每秒刪除次數
- getmore/s 每秒執行getmore次數
- command/s 每秒的命令數,比以上插入、查詢、更新、刪除的綜合還多,還統計了別的命令
- flushs/s 每秒執行fsync將資料寫入硬碟的次數。
- mapped/s 所有的被mmap的資料量,單位是MB,
- vsize 虛擬記憶體使用量,單位MB
- res 實體記憶體使用量,單位MB
- faults/s 每秒訪問失敗數(只有Linux有),資料被交換出實體記憶體,放到swap。不要超過100,否則就是機器記憶體太小,造成頻繁swap寫入。此時要升級記憶體或者擴充套件
- locked % 被鎖的時間百分比,儘量控制在50%以下吧
- idx miss % 索引不命中所佔百分比。如果太高的話就要考慮索引是不是少了
- q t|r|w 當Mongodb接收到太多的命令而資料庫被鎖住無法執行完成,它會將命令加入佇列。這一欄顯示了總共、讀、寫3個佇列的長度,都為0的話表示mongo毫無壓力。高併發時,一般佇列值會升高。
- 慢查,效率低下的查詢
5.3.2 監控工具
5.3.2.1 MonogoStat命令
mongostat是mongdb自帶的狀態檢測工具,在命令列下使用。它會間隔固定時間獲取mongodb的當前執行狀態,並輸出。如果你發現數據庫突然變慢或者有其他問題的話,你第一手的操作就考慮採用mongostat來檢視mongo的狀態。
5.3.2.2 Profiler
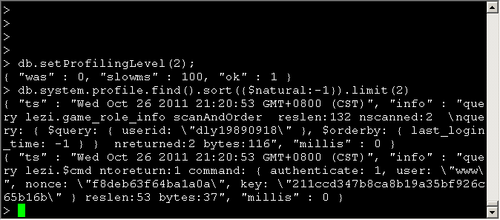
類似於MySQL的slow log, MongoDB可以監控所有慢的以及不慢的查詢。
Profiler預設是關閉的,你可以選擇全部開啟,或者有慢查詢的時候開啟。 例如:
-
> use test -
switched to db test -
> db.setProfilingLevel(2); -
{"was" : 0 , "slowms" : 100, "ok" : 1} // "was" is the old setting -
> db.getProfilingLevel()
檢視Profiler日誌:
-
> db.system.profile.find().sort({$natural:-1}) -
{"ts" : "Thu Jan 29 2009 15:19:32 GMT-0500 (EST)" , "info" : -
"query test.$cmd ntoreturn:1 reslen:66 nscanned:0 query: { profile: 2 } nreturned:1 bytes:50" , -
"millis" : 0} ...
3個欄位的意義ts:時間戳、info:具體的操作、millis:操作所花時間,毫秒。
5.3.2.3 使用profiler
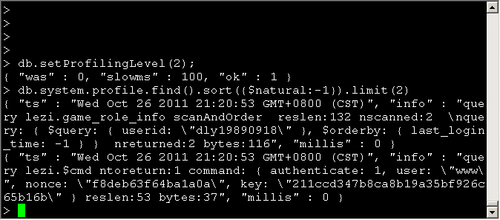
類似於MySQL的slow log, MongoDB可以監控所有慢的以及不慢的查詢。
Profiler預設是關閉的,你可以選擇全部開啟,或者有慢查詢的時候開啟。
-
> use test -
switched to db test -
> db.setProfilingLevel(2); -
{"was" : 0 , "slowms" : 100, "ok" : 1} // "was" is the old setting -
> db.getProfilingLevel()
檢視Profile日誌
-
> db.system.profile.find().sort({$natural:-1}) -
{"ts" : "Thu Jan 29 2009 15:19:32 GMT-0500 (EST)" , "info" : -
"query test.$cmd ntoreturn:1 reslen:66 nscanned:0 query: { profile: 2 } nreturned:1 bytes:50" , -
"millis" : 0} ...
3個欄位的意義ts:時間戳、info:具體的操作、millis:操作所花時間,毫秒
注意,造成慢查詢可能是索引的問題,也可能是資料不在記憶體造成因此磁碟讀入造成。
5.3.2.4 使用Web控制檯
Mongodb自帶了Web控制檯,預設和資料服務一同開啟。他的埠在Mongodb資料庫伺服器埠的基礎上加1000,如果是預設的Mongodb資料服務埠(Which is 27017),則相應的Web埠為28017
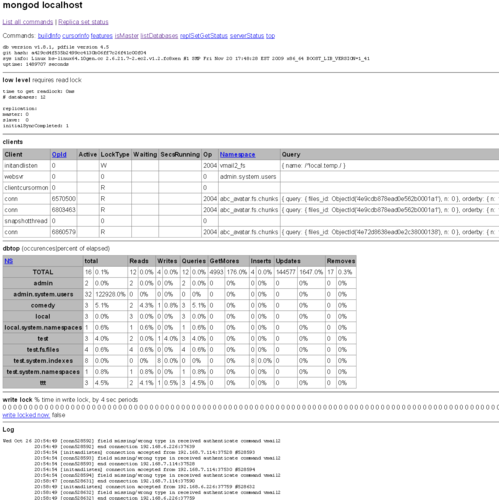
這個頁面可以看到
- 當前Mongodb的所有連線
- 各個資料庫和Collection的訪問統計,包括:Reads, Writes, Queries, GetMores ,Inserts, Updates, Removes
- 寫鎖的狀態
- 以及日誌檔案的最後幾百行(CentOS+10gen yum 安裝的mongodb預設的日誌檔案位於/var/log/mongo/mongod.log)
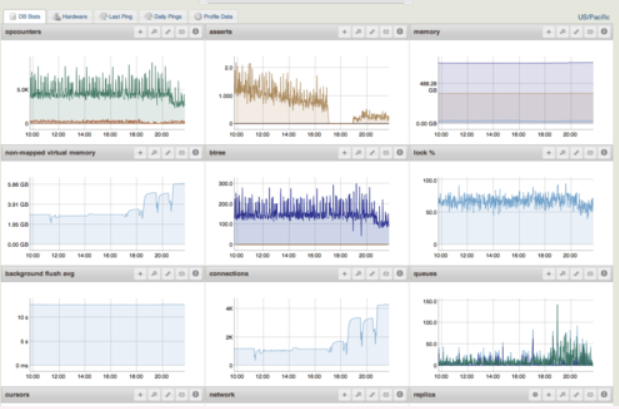
5.3.2.5 MongoDB Monitoring Service
MongoDB Monitoring Service(MMS)是Mongodb廠商提供的監控服務,可以在網頁和Android客戶端上監控你的MongoDB狀況。
5.4 Redis
5.4.1 監控指標說明
Redis主要監空Server、Clients、Memory、Persistence、Stats、Replication、CPU、Keyspace 8大部分,具體如下:
-
Server
redis_version:2.8.8 # Redis 的版本
redis_git_sha1:00000000
redis_git_dirty:0
redis_build_id:bf5d1747be5380f
redis_mode:standalone
os:Linux 2.6.32-220.7.1.el6.x86_64 x86_64
arch_bits:64
multiplexing_api:epoll
gcc_version:4.4.7 #gcc版本
process_id:49324 # 當前 Redis 伺服器程序id
run_id:bbd7b17efcf108fdde285d8987e50392f6a38f48
tcp_port:6379
uptime_in_seconds:1739082 # 執行時間(秒)
uptime_in_days:20 # 執行時間(天)
hz:10
lru_clock:1734729
config_file:/home/s/apps/RedisMulti_video_so/conf/zzz.conf -
Clients
connected_clients:1 #連線的客戶端數量
client_longest_output_list:0
client_biggest_input_buf:0
blocked_clients:0 -
Memory
used_memory:821848 #Redis分配的記憶體總量
used_memory_human:802.59K
used_memory_rss:85532672 #Redis分配的記憶體總量(包括記憶體碎片)
used_memory_peak:178987632
used_memory_peak_human:170.70M #Redis所用記憶體的高峰值
used_memory_lua:33792
mem_fragmentation_ratio:104.07 #記憶體碎片比率
mem_allocator:tcmalloc-2.0 -
Persistence
loading:0
rdb_changes_since_last_save:0 #上次儲存資料庫之後,執行命令的次數
rdb_bgsave_in_progress:0 #後臺進行中的 save 操作的數量
rdb_last_save_time:1410848505 #最後一次成功儲存的時間點, rdb_last_bgsave_status:ok
rdb_last_bgsave_time_sec:0
rdb_current_bgsave_time_sec:-1
aof_enabled:0 #redis是否開啟了aof
aof_rewrite_in_progress:0
aof_rewrite_scheduled:0
aof_last_rewrite_time_sec:-1
aof_current_rewrite_time_sec:-1
aof_last_bgrewrite_status:ok
aof_last_write_status:ok -
Stats
total_connections_received:5705 #執行以來連線過的客戶端的總數量
total_commands_processed:204013 #執行以來執行過的命令的總數量
instantaneous_ops_per_sec:0
rejected_connections:0
sync_full:0
sync_partial_ok:0
sync_partial_err:0
expired_keys:34401 #執行以來過期的 key 的數量
evicted_keys:0 #執行以來刪除過的key的數量
keyspace_hits:2129 #命中key 的次數
keyspace_misses:3148 #沒命中key 的次數
pubsub_channels:0 #當前使用中的頻道數量
pubsub_patterns:0 #當前使用中的模式數量
latest_fork_usec:4391 -
Replication
role:master #當前例項的角色master還是slave
connected_slaves:0
master_repl_offset:0
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0 -
CPU
used_cpu_sys:1551.61
used_cpu_user:1083.37
used_cpu_sys_children:2.52
used_cpu_user_children:16.79 -
Keyspace
db0:keys=3,expires=0,avg_ttl=0 #各個資料庫的 key 的數量及生存週期
5.4.2 監控工具
5.4.2.1 redis-faina
-
cd /opt/test -
git clone https://github.com/Instagram/redis-faina.git -
cd redis-faina/ -
redis-cli -p 6379 MONITOR | head -n 100 | ./redis-faina.py --redis-version=2.4
測試結果如下:
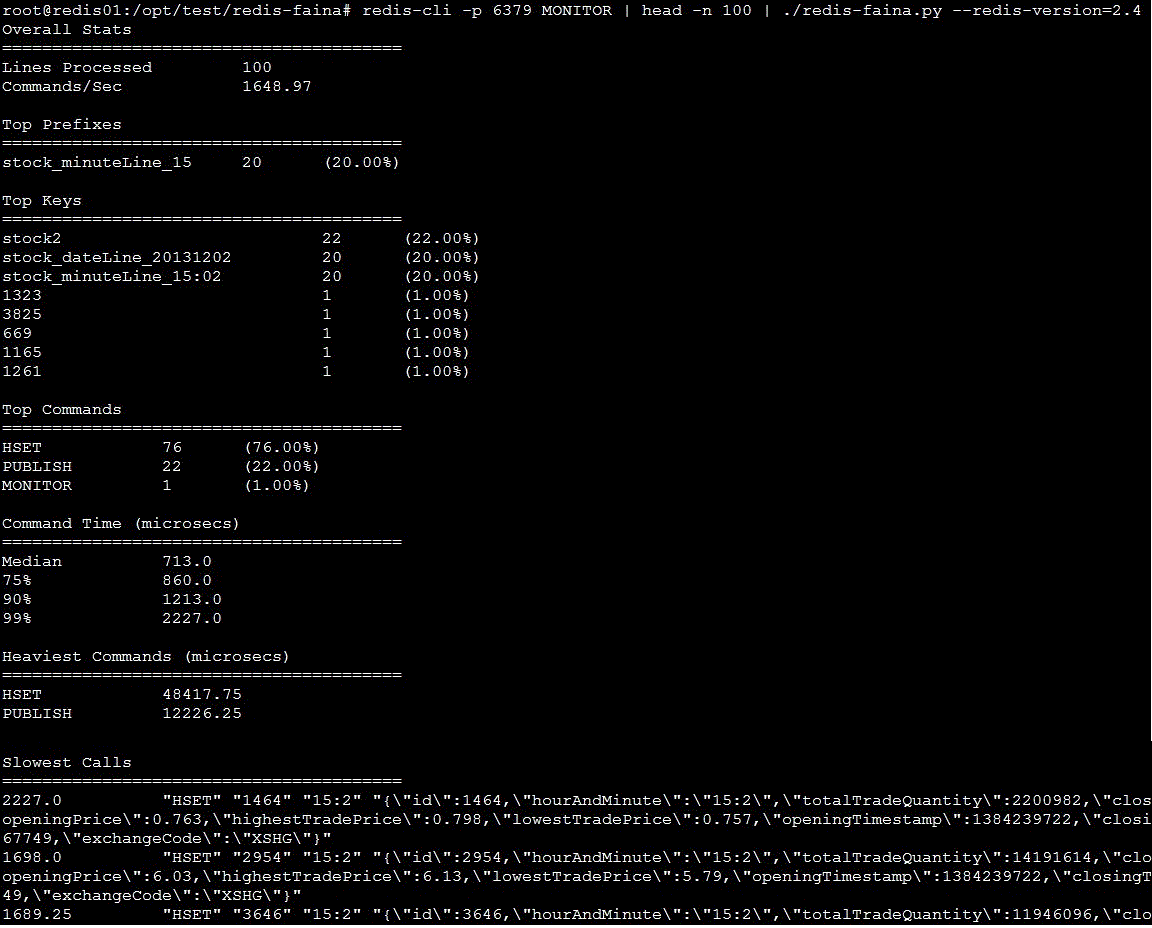
可以看到一些實時的資料,並且有一定的統計資料,可以作為一個命令列工具使用。推薦使用,不過redis版本要大於2.4。
5.4.2.2 redis-live
-
cd /root -
git clone https://github.com/nkrode/RedisLive.git -
cd RedisLive/src ###修改redis-live.conf檔案 { -
"RedisServers": [ { -
"server": "10.20.111.188", -
"port" : 6379 -
} ], -
"DataStoreType" : "redis", "RedisStatsServer": -
{ -
"server" : "10.20.111.188", -
"port" : 6380}, -
"SqliteStatsStore" : -
{ -
"path": "to your sql lite file" -
} }
修改完畢
啟動監控服務,每30秒監控一次 ./redis-monitor.py --duration=30 ###再次開啟一個終端,進入/root/RedisLive/src目錄,啟動web服務 ./redis-live.py 在瀏覽器輸入: http://10.20.111.188:8888/index.html 即可看到下圖:
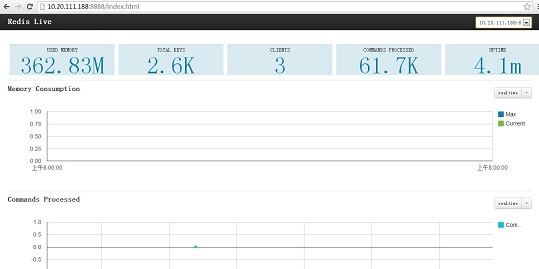
一個web介面,可以同時監控多個redis例項,做集中監控比較好。
5.4.2.3 redis-stat
用ruby寫成的監控redis的程式,基於info命令獲取資訊,而不是通過monitor獲取資訊,效能應該比monitor要好。
官網:https://github.com/junegunn/redis-stat
執行環境安裝:
apt-get install ruby
apt-get install rubygems
redis-stat安裝:
cd /root
git clone https://github.com/junegunn/redis-stat.git
cd /root/redis-stat/bin ###./redis-stat --help 可以看到使用幫助
./redis-stat 1
redis-stat的具體用法
-
usage: redis-stat [HOST[:PORT] ...] [INTERVAL [COUNT]] -
-a, --auth=PASSWORD Password -
-v, --verbose Show more info -
--style=STYLE Output style: unicode|ascii -
--no-color Suppress ANSI color codes -
--csv=OUTPUT_CSV_FILE_PATH Save the result in CSV format -
--server[=PORT] Launch redis-stat web server (default port: 63790) -
--daemo Daemonize redis-stat. Must used with --server option. -
--version Show version --help
redis-stat命令列模式:
-
redis-stat -
redis-stat 1 -
redis-stat 1 10 -
redis-stat --verbose -
redis-stat localhost:6380 1 10 -
redis-stat localhost localhost:6380 localhost:6381 5 -
redis-stat localhost localhost:6380 1 10 --csv=/tmp/output.csv --verbose -
redis-stat web模式: -
redis-stat --server -
redis-stat --verbose --server=8080 5 -
redis-stat --server --daemon
效果如下:
執行web模式
-
cd /root/redis-stat/bin -
./redis-stat --server=8080 5 --daemon
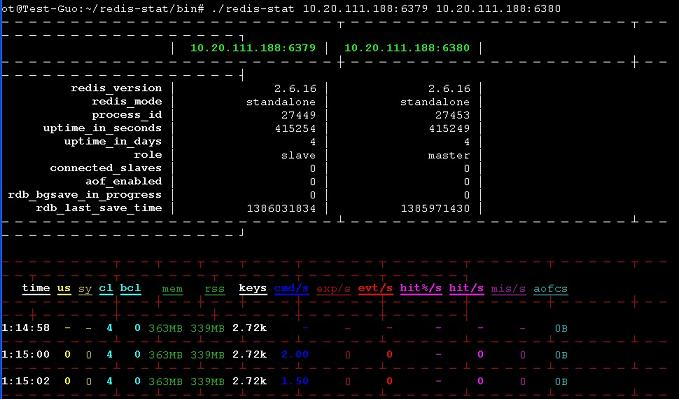
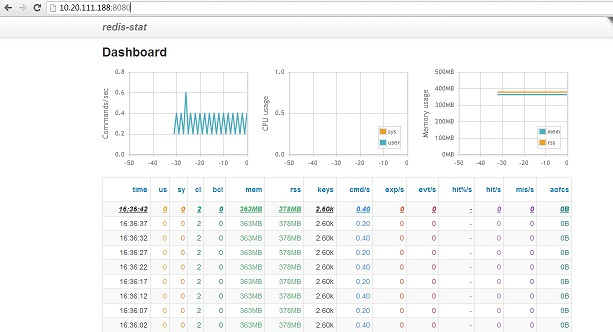
不錯的工具,既有命令列又有web介面,可以放到後臺執行,資料比redis-live感覺直觀 ,ruby開發的,唯一的缺點是如果同時監控多個redis例項,不能單獨顯示每一個例項的資料資訊,貌似是總和。
5.4.2.4 redis-monitor
6 前端指標監控
6.1 監控指標說明
前端指標主要包括頁面展示、網路所花的時間以及前端有哪些地方需要優化。
6.2 監控工具
6.2.1 FireBug
Firebug是firefox下的一個擴充套件,能夠除錯所有網站語言,如Html,Css等,但FireBug最吸引我的就是javascript除錯功能,使用起來非常方便,而且在各種瀏覽器下都能使用(IE,Firefox,Opera, Safari)。
Firebug主要功能有:CSS除錯、CSS尺標、網路監視器、JS偵錯程式、Console 控制檯、修改HTML、DOM檢視器。
6.2.2 YSlow
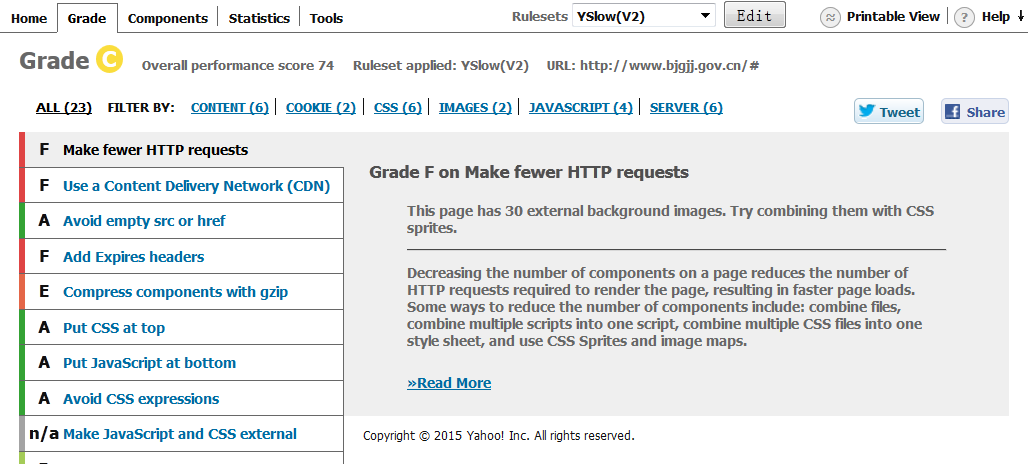
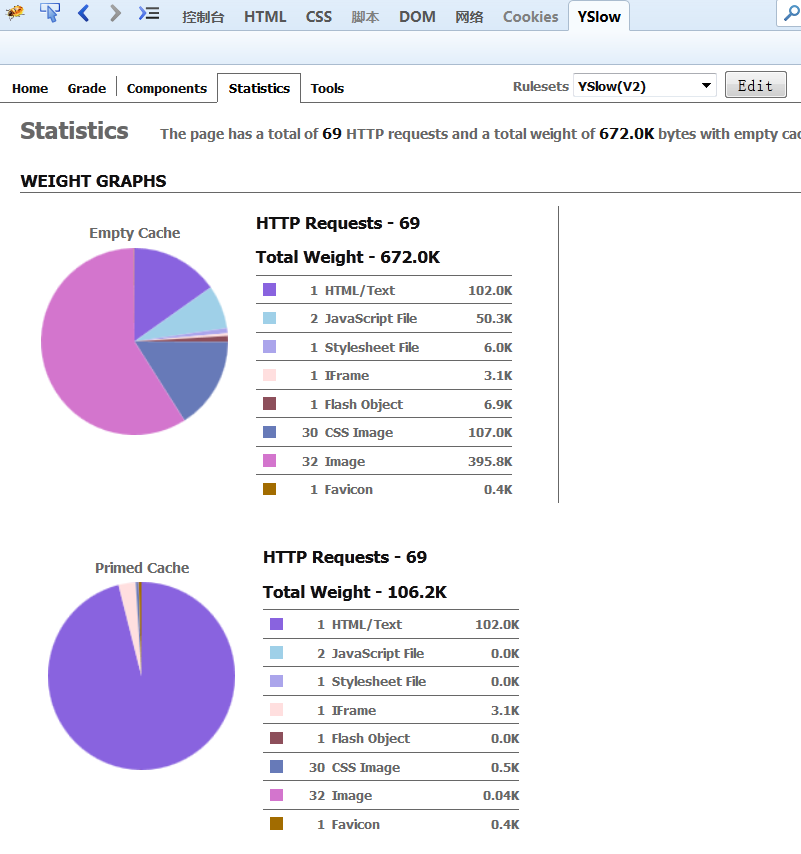
YSlow可以對網站的頁面進行分析,並告訴你為了提高網站效能,如何基於某些規則而進行優化。 安裝YSlow必須首先先安裝 Firebug,然後下載YSlow,再對其安裝。
YSlow可以分析任何網站,併為每一個規則產生一個整體報告,如果頁面可以進行優化,則YSlow會列出具體的修改意見。
相關推薦
效能監控總結
目錄 1 引言 1.1 編寫目的 1.2 適用物件和範圍 1.3 參考文件 2 業務指標監控 2.1 監控指標 2.2 監控工具 3 作業系統指標監控 3.1 Linux
深入理解Java虛擬機器總結一虛擬機器效能監控工具與效能調優(三)
深入理解Java虛擬機器總結一虛擬機器效能監控工具與效能調優(三) JDK的命令列工具 JDK的視覺化工具 效能調優 JDK的命令列工具 主要有以下幾種: jps (Java Process Status Tool): 虛擬機器程序
ORACLE生產中效能監控中總結的經驗
ORACLE資料庫在我們部署之後,往往會隨著系統的升級,資料量的增大以及設計的缺陷導致系統的效能會出現不穩定,資源爭用,阻塞等一系列的問題。會導致系統的可用性變得越來越低。所以為了保證系統的長期穩定可靠,高效能的工作,我們就需要對資料庫進行相應
BW效能監控利器——ST13總結
題記:BW的小工具,ST13,近來每每使用,都頗有感慨,故總結如下,以備後用 1、Process Chain:ST13--->BW-TOOLS-->Process Chain An
SqlServer效能監控和優化總結
如何監視和檢視sql server的效能 http://jingyan.baidu.com/article/a378c9609af34eb32828303a.html 開啟sql server studio management 開啟"工具"-"sql server pro
開發完第一版前端效能監控系統後的總結(無程式碼)
(無論何時我都是一個實踐派) 說起前端效能監控系統,絕大部分人應該不陌生,也許你正在使用,又或者你只是聽說過。總之它就是這樣頻繁的出現在我們的工作之中。 那麼做一個前端效能監控系統,我們應該統計一些什麼維度的資訊呢?那些資料真正對於我們有用呢?它適用的場景又有哪些呢?有很多的問題需要回答,再做之前我們應該回
RPC電源監控總結
去掉 傳輸 試用 border font 執行 成功 遇見 宋體 首先說一下監控機箱的監控原理。 設備的信息傳輸是通過tcp或者udp傳輸十六進制的數然後進行解析,傳輸數據。 比如:”ff al 07 aa”分別對應不同的查詢狀
前端錯誤監控總結
idt 特定 前端 基本 span () ajax nbsp height 【要點】 1. 前端錯誤的分類 2. 錯誤的捕獲方式 3. 上報錯誤的基本原理 【總結】 1. 錯誤分類 運行時錯誤,代碼錯誤 資源加載錯誤 2.捕獲方式 代碼錯誤捕獲 t
JDK下虛擬機器效能監控以及故障分析工具
無論對於開發人員還是運維人員,給一個系統定位問題時,知識、經驗是關鍵基礎,資料是依據,工具是運用知識處理資料的手段。對於開發人員或運維人員,這裡的資料包括:執行日誌、異常日誌、GC日誌、堆轉儲快照等。適當的使用這些工具,會使我們能夠快速定位問題,提升解決問題的速度。 &nbs
Linux效能監控工具Nmon安裝使用
安裝說明 安裝環境: 安裝方式:解壓包安裝 軟體:nmon_linux_14i.tar.gz 下載地址: nmon: http://nmon.sourceforge.net/pm ... nload nmonanalyser: http:/
Java 之 檔案讀寫及效能比較總結
Java 之 檔案讀寫及效能比較總結 2014年05月12日 17:56:49 閱讀數:21765 幹Java這麼久,一直在做WEB相關的專案,一些基礎類差不多都已經忘記。經常想得撿起,但總是因為一些原因,不能如願。 其實不是沒有時間,只是有些時候疲於總結,今得空,下定決心
linux效能監控工具-(顯示系統整體資源使用情況-top命令)
顯示系統整體資源使用情況 -top命令 top命令是linux下常用的效能分析工具,能夠實時顯示系統中各個程序的資源佔用狀況: 前半部分是系統統計資訊,後半部分是程序資訊。 從左到右依次表示:系統當前時間,系統執行時間,當前登入使用者數。load average表示系統的平
[雪峰磁針石部落格]python應用效能監控工具簡介
監控簡介 監視工具捕獲,分析和顯示Web應用程式執行資訊。每個應用程式在Web堆疊的所有層都可能出現問題。監控工具通過展示幫助開發人員和運營團隊響應並修復問題。 捕獲和分析有關生產環境的資料對於主動處理Web應用程式的穩定性,效能和錯誤至關重要。 監視和日誌記錄的目的非常相似,
前端效能監控工具
本文摘自掘金小冊子《前端效能優化原理與實踐》 一、視覺化監測 1、chrome工具Performance 面板 CPU 圖示和 Summary 圖都是按照“型別”給我們提供效能資訊,而 Main 火焰圖則將粒度細化到了每一個函式的呼叫。到底是從哪個過程開始出問題、是哪個函式拖了後腿、又是哪個事件觸
C程式碼效能優化總結
轉自:https://blog.csdn.net/chenyq991/article/details/79047741 1、優化程式碼框架 個人覺得程式碼架構對效能的影響至關重要,就好骨架之於人,所以我把這個放在第一點。舉個簡單的例子: 優化前: void main() { whi
zanePerfor 一款完整,高效能,高可用的前端效能監控系統,不要錯過
HI!,你好,我是zane,zanePerfor是一款最近我開發的一個前端效能監控平臺,現在支援web瀏覽器端和微信小程式段。 我定義為一款完整,高效能,高可用的前端效能監控系統,這是未來會達到的目的,現今的架構也基本支援了高可用,高效能的部署。實際上還不夠,在很多地方還有優化的空間,我會持續的優化和升級。
Docker容器效能監控工具google/cadvisor
原文地址:https://hub.docker.com/r/google/cadvisor/ cAdvisor(Container Advisor)為容器使用者提供了對其執行容器的資源使用和效能特徵的理解。 它是一個執行守護程式,用於收集,聚合,處理和匯出有關正在執行的容器的資訊。 具體而
【Jmeter】api效能測試總結
1.前提概念 平時常用的效能測試:api效能測試+場景效能測試;今天就說一說api效能測試 2.如何進行效能測試? 需求:對某api進行效能測試,看看最大承受的併發數,分析下圖表 分析: 錯誤思路:當我們接到這個需求的時候,很多人不管三七二十一,先把介面寫起來,然後給
JVM虛擬機器效能監控與調優(JDK命令列、JConsole)
很多資料在介紹JDK命令列工具時並不是在Java8環境下,因此還在使用過時的永久區系列的引數,給一些讀者造成困難。 Java8使用Metaspace(元空間)代替永久區,對於64位平臺,為了壓縮JVM物件中的_klass指標的大小,引入了類指標壓縮空間(Compressed Class Pointer Sp
TOMCAT7併發效能優化總結
最近由於工作需要看了很多tomcat效能優化的資料,在此記錄總結一下,以備日後之需。 總結起來其實有三點: 一、tomcat啟動JVM引數調優 具體做法為在catalina.bat前面加上JAVA_OPTS引數設定 set JAVA_OPTS= -server #以伺服